JavaScript V8引擎
Posted 伴月
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaScript V8引擎相关的知识,希望对你有一定的参考价值。
一、浏览器内核—渲染引擎
渲染,就是根据描述或者定义构建数学模型,生成图像的过程。
浏览器内核主要的作用是将页面转变成可视化/可听化的多媒体结果,通常也被称为渲染引擎。将html/CSS/javascript文本及其他相应的媒体类型资源文件转换成网页。
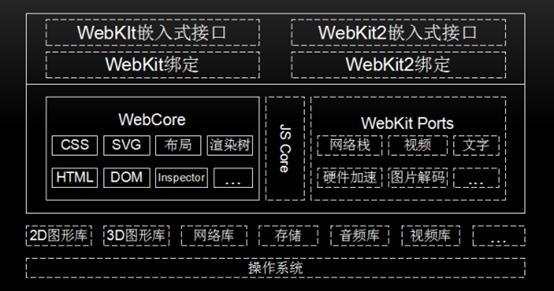
上图中实线框内模块是所有移植的共有部分,虚线框内不同的厂商可以自己实现。下面进行介绍:
WebCore 是各个浏览器使用的共享部分,包括HTML解析器、CSS解析器、DOM和SVG等。
JavaScriptCore是WebKit的默认引擎,在谷歌系列产品中被替换为V8引擎。
WebKit Ports是WebKit中的非共享部分,由于平台差异、第三方库和需求的不同等原因,不同的移植导致了WebKit不同版本行为不一致,它是不同浏览器性能和功能差异的关键部分。
WebKit嵌入式编程接口,供浏览器调用,与移植密切相关,不同的移植有不同的接口规范。
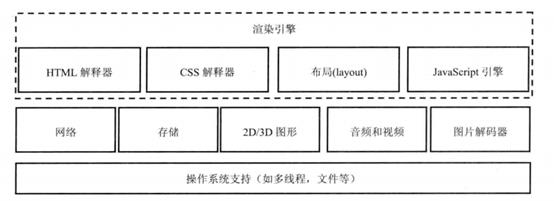
浏览器内核的层次结构,渲染引擎解析网页资源,调用第三方库进行渲染绘制。

从上面两图可以大概看出渲染引擎的内部组成和大模块。WebCore,负责解析HTML、CSS生成DOM树等渲染进程,js引擎负责解析和执行js逻辑进程。
二、JavaScript引擎
1、JS引擎与渲染引擎关系
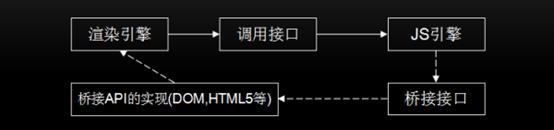
JavaScript引擎和渲染引擎的关系如上图所示。渲染引擎使用JS引擎的接口来处理逻辑代码并获取结果。JS引擎通过桥接接口访问渲染引擎中的DOM及CSSOM(性能低下)。
2、JS引擎工作流程
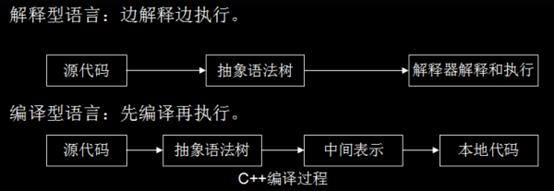
JavaScript本质上是一种解释型语言,与编译型语言不同的是它需要一遍执行一边解析,而编译型语言在执行时已经完成编译,可直接执行,有更快的执行速度(如上图所示)。
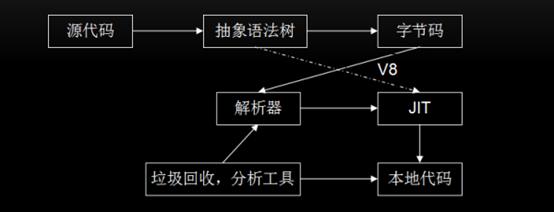
上图描述了JS代码执行的过程。具体过程先不看,一个JS引擎主要包括以下几个部分:
编译器。将源代码经过词法分析,语法分析(你不知的js待查)编译成抽象语法树,在某些引擎中还包含将抽象语法树转化成字节码。
解释器。在某些引擎中,解释器主要是接收字节码,解释执行这个字节码,同时也依赖垃圾回收机制等。
JIT工具。将字节码或者抽象语法树转换成本地代码。
垃圾回收器和分析工具(Profiler)。负责垃圾回收和收集引擎中的信息,帮助改善引擎的性能和功效。
三、V8 编译与执行
1、数据表示
Js语言中,只有基本数据类型Boolean、Number、String、Null、Undefined,其他都是对象。
在V8中,数据的表示分成两个部分。第一个部分是数据的实际内容,它们是变长的,而且内容的类型也不一样,如String、对象等;第二部分是数据的句柄,大小是固定的,包含指向第一部分数据的指针。除了极少数的数据例如整型数据,其他的内容都是从堆中申请内存来存储,因为句柄本身能够存储整型,同时也能快速访问。
2、句柄Handle
V8需要进行垃圾回收,并需要移动这些数据内容,如果直接使用指针的话就会出问题或者需要比较大的开销。使用句柄就不存在这些问题,只需要修改句柄中的指针即可,使用者使用的还是句柄,它本身没有发生变化。
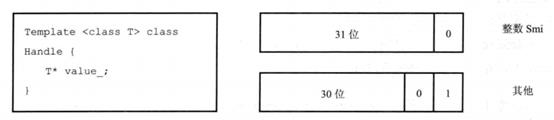
由上图可以看出,一个Handle对象的大小是4字节(32位机器)或者8字节(64位机器);不同于JavascriptCore引擎,后者是使用8个字节来表示数据的句柄。小整数(只有31位可以使用)直接在Value_中获取值,而无须从堆中分配。
因为堆中存放的对象都是4字节对齐的,所以指向它们的指针的最后两位都是00,这两位其实是不需要的。在V8中,它们被用来表示句柄中包含数据的类型。
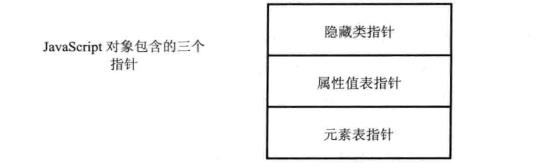
对象句柄的实现在V8中包含3个成员。第一个是隐藏类指针,为对象创建的隐藏类;第二个指向这个对象包含的属性值;第三个指向这个对象包含的元素。
3、编译过程
包括两个阶段:编译和执行。还有一个重要的特点就是延迟思想,使得很多js代码的编译直到运行时被调用才会发生(以函数单位),减少时间开销。
Js代码经过编译器,生成抽象语法树,再通过JIT全代码生成器直接生成本地代码。减少抽象树到字节码的转换时间。
生成本地代码后,为了性能考虑,通过 数据分析器 来采集一些信息,以帮助决策哪些本地代码需要优化,以生成效率更高的本地代码,这是一个逐步改进的过程。
4、优化回滚
编译器会做比较乐观和大胆的预测,就是认为这些代码比较稳定,变量类型不会发生改变,来生成高效的本地代码。当引擎发现一些变量的类型已经发生变化的时候,V8会将优化回滚到之前的一般情况。

如上,函数ABC被调用很多次之后,数据分析器认为函数内的代码的类型都已经被获知了,但是当对于unkonwn的变量发生赋值是,V8只能将代码回滚到一个通用的状态。
优化回滚是一个很费时的操作,而且会将之前优化的代码恢复到一个没有特别优化的代码,这是一个非常不高效的过程。
5、隐藏类和内嵌缓存
V8使用类和偏移位置思想,将本来需要字符串匹配来查找属性值的算法改进为,使用类似C++编译器的偏移位置的机制来实现,这就是隐藏类。
隐藏类根据对象拥有相同的属性名和属性值的情况,分为不同的组(类型)。对于相同的组,将这些属性名和对应的偏移位置保存在一个隐藏类中,组内的对象共享该信息。同时,也可以识别属性不同的对象。
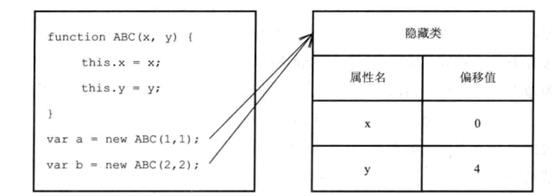
如图,使用构造函数创建了两个对象a、b。这两个对象包含相同的属性名,在V8中它们被归为同一个组,也就是隐藏类,这些属性在隐藏类中有相同的偏移值。对象a、b可以共享这个分组的信息,当访问这些对象的时候,根据隐藏类的偏移值就可以知道它们的位置并进行访问。
因为JavaScript是动态类型语言,所以当加入代码 d.z = 2。那么b对象所对应的将是一个新的隐藏类,这样a、b将属于不同的组。
function add(a) { return a.x };
访问对象属性基本过程为:获取隐藏类的地址,根据属性名查找偏移值,计算该属性的堆内存地址。这一过程还是比较耗费时间,实际上会用到缓存机制,叫做内嵌缓存。
基本思想是将使用之前查找的结果(隐藏类和偏移值)缓存起来,再次访问时可以避免多次哈希表查找的问题。
注意:当对象内的属性值出现多个类型是,那么缓存失误的概率就会高很多。退回到之前的方式来查找哈希表。
四、V8内存分配
主要讲两点:1、内存的划分使用2、对于JS代码的垃圾回收机制
1、小内存区块Zone类
管理一系列的小块内存,这些小内存的生命周期类似,可以使用一个Zone对象。
Zone对象先对自己申请一块内存,然后管理和分配一些小内存。当一块小内存被分配之后,不能被Zone回收,只能一次性回收Zone分配的所有小内存。例如:抽象语法树的内存分配和使用,在构建之后,会生成本地代码,然后其内存被一次性全部收回,效率非常高。
但是有一个严重的缺陷,当一个过程需要很多内存,Zone将需要分配大量的内存,却又不能及时回收,会导致内存不足情况。
2、堆内存
V8使用堆来管理JavaScript使用的数据、以及生成的代码、哈希表等。为了更方便地实现垃圾回收,同很多虚拟机一样,V8将堆分成三个部分。年轻代、年老代、和大对象。
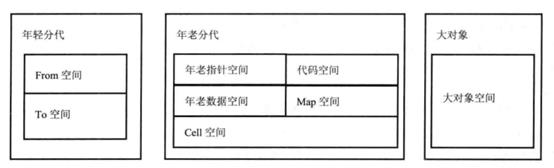
年轻分代:为新创建的对象分配内存空间,经常需要进行垃圾回收。为方便年轻分代中的内容回收,可再将年轻分代分为两半,一半用来分配,另一半在回收时负责将之前还需要保留的对象复制过来。
年老分代:根据需要将年老的对象、指针、代码等数据保存起来,较少地进行垃圾回收。
大对象:为那些需要使用较多内存对象分配内存,当然同样可能包含数据和代码等分配的内存,一个页面只分配一个对象。
当在代码中声明变量并赋值时,所使用对象的内存就分配在堆中。如果已申请的堆空闲内存不够分配新的对象,将继续申请堆内存,知道堆的大小达到V8的限制为止。
V8的内存使用限制:64位系统中约为1.4G,32位系统中约为0.7G。在浏览器页面中足够使用;在node中则会有不足,导致Node无法直接操作大内存对象,在打个node进程的情况下,无法充分利用计算机的内存资源。
内存的限制有两方面原因,防止浏览器的一个页面占用太多系统内存资源,另一方面,V8垃圾回收的效率问题。对于1.5G内存,做一次小的垃圾回收需要50毫秒以上,做一次全量的回收甚至要1秒以上,这个过程会阻塞JS线程的执行。
五、垃圾回收
V8的垃圾回收策略主要基于分代式回收机制。按对象的存活时间将内存的垃圾回收进行不同的分代,然后分别对不同的内存使用更高效的算法。
1、新生代Scavenge(清除)算法
主要采用Cheney(人名)算法。一种采用复制的方式实现的垃圾回收算法。
1、将新生代堆内存分一为二,每一部分空间称为semispace。其中一个处于使用之中的称为from空间,另一个处于闲置称为to空间。
2、当我们分配对象时,先是在From空间中进行分配。
3、垃圾回收时,检查from空间内的存活对象,一是否经历过清除回收,二to空间是否已经使用了25%(保证新分配有足够的空间)。
. 4、将这些存活对象复制到to空间中。非存活对象占用的空间将会被释放。
5、完成复制后,from空间与to空间角色发生对换。
注:实际使用的堆内存是新生代中的两个semispace空间大小,和老生代所用内存大小之和。
如何判断对象是否存活呢?作用域?是一套存储和查询变量的规则。这套规则决定了内存里对象能否访问。
特点:
清除算法是典型的牺牲空间换取时间的算法,无法大规模地应用到所有回收中,却非常适合应用在新生代生命周期短的变量。
2、Mark-Sweep老生代标记清除
1、 标记阶段遍历堆中的所有对象,并标记活着的对象
2、 清除阶段,只清除没有被标记的对象。
最大的问题是,在进行一次标记清除之后会出现不连续的状态。这种内存碎片会对后续的内存分配造成问题。很可能需要分配一个大对象时,所有的碎片空间都无法完成,就会提前触发垃圾回收,而这次全量回收是不必要的。
3、Mark-Compact老生代标记整理
在标记清除的基础上发展而来,在整理的过程中
1、 将活着的对象往一段移动
2、 移动完成后,直接清理掉边界外的内存
4、Incremental Marking增量标记
垃圾回收的过程都需要将应用逻辑暂停下来。
为了降低全量回收带来的停顿时间,在标记阶段,将原本一口气要完成的动作改为增量标记。垃圾回收与应用逻辑交替执行到标记阶段完成。最大停顿时间较少的1/6左右.
后续还引入了延迟清理与增量整理,让清理和整理动作也变成增量式的。
六、高效内存使用
1、作用域
函数在每次被调用时会创建对应的作用域(自身的执行环境,和变量对象),作用域中声明的局部变量分配在改作用域中。执行结束后,作用域销毁,做死亡标记,在下次垃圾回收时被释放。
变量的主动释放,解除引用关系:
如果变量是全局变量,由于全局作用域需要直到进程退出才能释放,导致引用的对象常驻内存(老生代)。可以通过delete来删除引用关系,或者将变量重新赋值。但是在V8中通过delete删除对象的属性有可能干扰V8的优化。
闭包:
当函数执行结束,但作用域(变量对象)仍需要被引用时,其变量对象不能被标记失效,占用的内存空间不会得到清除释放。除非不再有引用,才会逐步释放。
在正常的js执行中,无法立即回收的内存有闭包和全局变量这两种情况。要避免这些变量无限制地增加,导致老生代中的对象增多,甚至内存泄漏。
2、内存泄漏
实质:应当回收的对象出现意外,而没有被回收,变成了常驻在老生代中的对象。
通常,造成内存泄漏的原因有如下:
1、 缓存
缓存无限制增长,长期存在于老生代,占据大量内存。
策略:对缓存增加数量和有效期限制。
使用Redis等进程外缓存,不占用V8缓存限制,进程间可以共享缓存。
2、 队列消费不及时
Js可以通过队列(数组对象)来完成许多特殊的需求。在消费者—生产者模型中经常充当中间产物。当消费速度低于生成速度时,将会形成堆积。
如:日志记录,采用低效率的数据库写入时,可能会是写入事件堆积。
策略:使用高效的消费方式。监控队列的长度。
3、 作用域得不到释放
大量闭包的使用,要注意释放作用域。
以上是关于JavaScript V8引擎的主要内容,如果未能解决你的问题,请参考以下文章