如何用Python爬取数据?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用Python爬取数据?相关的知识,希望对你有一定的参考价值。
方法/步骤
在做爬取数据之前,你需要下载安装两个东西,一个是urllib,另外一个是python-docx。
请点击输入图片描述
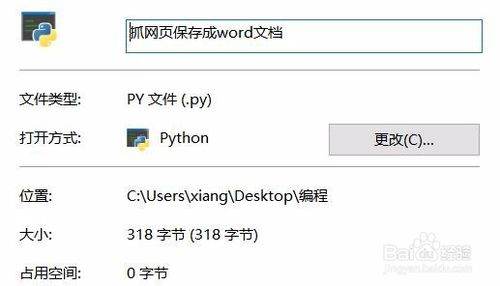
然后在python的编辑器中输入import选项,提供这两个库的服务
请点击输入图片描述
urllib主要负责抓取网页的数据,单纯的抓取网页数据其实很简单,输入如图所示的命令,后面带链接即可。

请点击输入图片描述
抓取下来了,还不算,必须要进行读取,否则无效。

请点击输入图片描述
5
接下来就是抓码了,不转码是完成不了保存的,将读取的函数read转码。再随便标记一个比如XA。

请点击输入图片描述
6
最后再输入三句,第一句的意思是新建一个空白的word文档。
第二句的意思是在文档中添加正文段落,将变量XA抓取下来的东西导进去。
第三句的意思是保存文档docx,名字在括号里面。
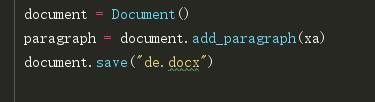
请点击输入图片描述
7
这个爬下来的是源代码,如果还需要筛选的话需要自己去添加各种正则表达式。
简单爬虫不难,无非发起http访问,取得网页的源代码文本,从源代码文本中抽取信息。
首先要自己会写代码。
学习爬虫可以从下面一些知识点入手学习。
1、http相关知识。
2、浏览器拦截、抓包。
3、python2 中编码知识,python
3 中bytes 和str类型转换。
4、抓取javascript 动态生成的内容。
5、模拟post、get,header等6、cookie处理,登录。
7、代理访问。
8、多线程访问、python 3 asyncio 异步。
9、正则表达式、xpath等。。。。
10、scrapy requests等第三方库的使用。 参考技术B 别折腾了,不打算往爬虫方向发展的话没必要自己学,爬虫所需要的技术非常广泛、且对深度都有一定要求,不存在“快速学会”的情况。所有那些吹快速学会爬虫的培训班都是扯淡,那些课程学完后的水平连傻瓜式爬虫工具都不如,有啥意义?再说了,你们写论文、做研究又不会需要什么很大量、很高频、很实时的数据,那些傻瓜式爬虫工具完全足够了,点几下就能出数据。
以上是关于如何用Python爬取数据?的主要内容,如果未能解决你的问题,请参考以下文章