json&pickle模块
Posted 小咖啡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了json&pickle模块相关的知识,希望对你有一定的参考价值。
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值
1 import json 2 x="[null,true,false,1]" 3 print(eval(x)) #报错,无法解析null类型,而json就可以 4 print(json.loads(x))
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
为什么要序列化?
1:持久保存状态
需知一个软件/程序的执行就在处理一系列状态的变化,在编程语言中,\'状态\'会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
2:跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
如何序列化之json和pickle:
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
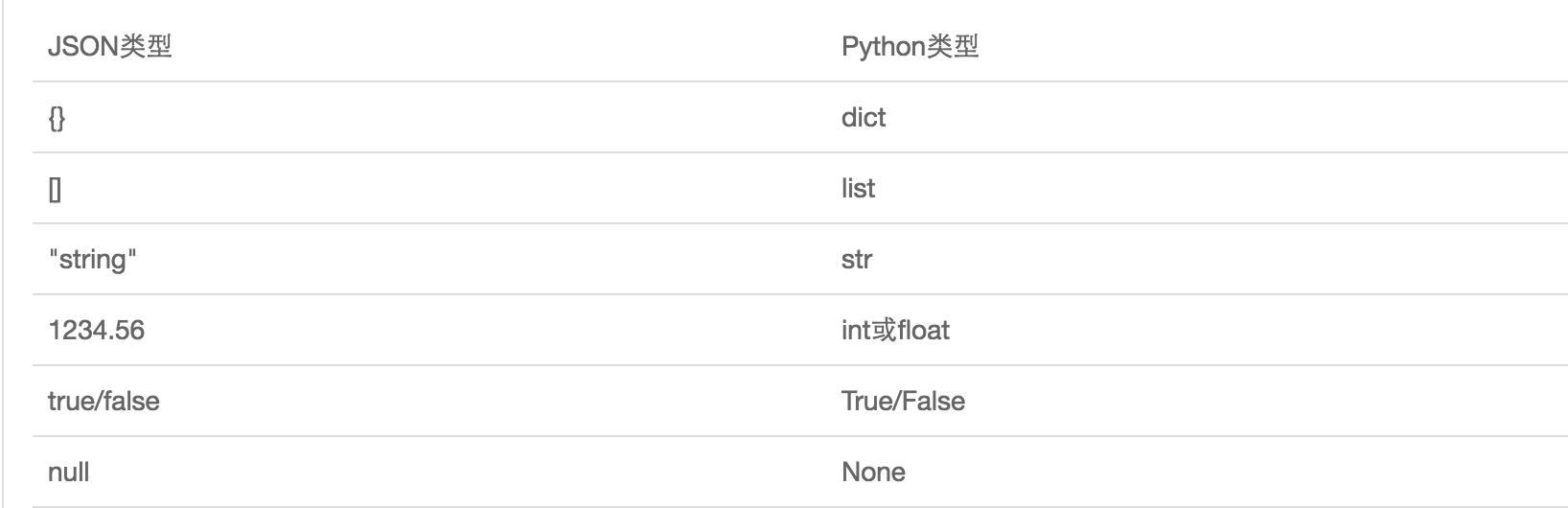
JSON表示的对象就是标准的javascript语言的对象,JSON和Python内置的数据类型对应如下:

import json dic={\'name\':\'alvin\',\'age\':23,\'sex\':\'male\'} print(type(dic))#<class \'dict\'> j=json.dumps(dic) print(type(j))#<class \'str\'> f=open(\'序列化对象\',\'w\') f.write(j) #-------------------等价于json.dump(dic,f) f.close() #-----------------------------反序列化<br> import json f=open(\'序列化对象\') data=json.loads(f.read())# 等价于data=json.load(f)
import json #dct="{\'1\':111}"#json 不认单引号 #dct=str({"1":111})#报错,因为生成的数据还是单引号:{\'one\': 1} dct=\'{"1":"111"}\' print(json.loads(dct)) #conclusion: # 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
pickle

import pickle dic={\'name\':\'alvin\',\'age\':23,\'sex\':\'male\'} print(type(dic))#<class \'dict\'> j=pickle.dumps(dic) print(type(j))#<class \'bytes\'> f=open(\'序列化对象_pickle\',\'wb\')#注意是w是写入str,wb是写入bytes,j是\'bytes\' f.write(j) #-------------------等价于pickle.dump(dic,f) f.close() #-------------------------反序列化 import pickle f=open(\'序列化对象_pickle\',\'rb\') data=pickle.loads(f.read())# 等价于data=pickle.load(f) print(data[\'age\'])
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
以上是关于json&pickle模块的主要内容,如果未能解决你的问题,请参考以下文章