转载请注明出处!
原文链接:http://blog.csdn.net/zgyulongfei/article/details/7909006
有时候由于种种原因,我们需要采集某个网站的数据,但由于不同网站对数据的显示方式略有不同!
本文就用Java给大家演示如何抓取网站的数据:(1)抓取原网页数据;(2)抓取网页javascript返回的数据。
一、抓取原网页。
这个例子我们准备从http://ip.chinaz.com上抓取ip查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,就可以看到网页显示的结果:

第二步:查看网页源码,我们看到源码中有这么一段:

从这里可以看出,查询的结果,是重新请求一个网页之后显示的。
再看看查询之后的网页地址:
也就是说,我们只要访问形如这样的网址,就可以得到ip查询的结果,接下来看代码:
- public void capturehtml(String ip) throws Exception {
- String strURL = "http://ip.chinaz.com/?IP=" + ip;
- URL url = new URL(strURL);
- HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
- InputStreamReader input = new InputStreamReader(httpConn
- .getInputStream(), "utf-8");
- BufferedReader bufReader = new BufferedReader(input);
- String line = "";
- StringBuilder contentBuf = new StringBuilder();
- while ((line = bufReader.readLine()) != null) {
- contentBuf.append(line);
- }
- String buf = contentBuf.toString();
- int beginIx = buf.indexOf("查询结果[");
- int endIx = buf.indexOf("上面四项依次显示的是");
- String result = buf.substring(beginIx, endIx);
- System.out.println("captureHtml()的结果:\n" + result);
- }
使用HttpURLConnection连接网站,用bufReader保存网页返回的数据,然后通过自定义的一个解析方式将结果显示出来。
这里我只是随便的解析了一下,要解析的非常准确的话自己需再处理。
解析结果如下:
captureHtml()的结果:
查询结果[1]: 111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市 移动</strong><br />
二、抓取网页JavaScript返回的结果。
有时候网站为了保护自己的数据,并没有把数据直接放在网页源码中返回,而是采用异步的方式,用JS返回数据,这样可以避免搜索引擎等工具对网站数据的抓取。
首先看一下这个网页:
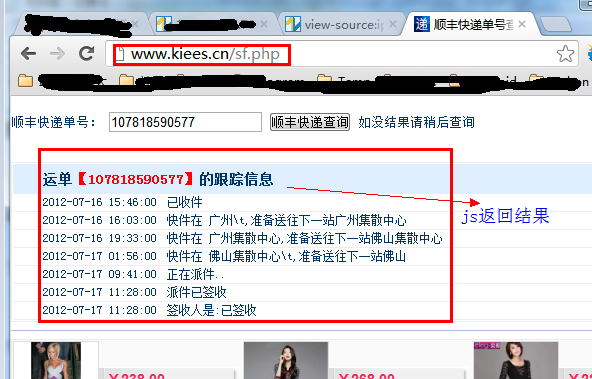
用第一种方式查看该网页的源码,却没有发现该运单的跟踪信息,因为它是通过JS的方式获取结果的。
但有时候我们很需要获取到JS的数据,这个时候要怎么办呢?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以截获Http的交互内容,我们通过这个工具来达到我们的目的。
首先点击Start按钮之后,它就开始监听网页的交互行为了。
我们打开网页:http://www.kiees.cn/sf.php ,可以看到HTTP Analyzer列出了所有该网页的请求数据以及结果:
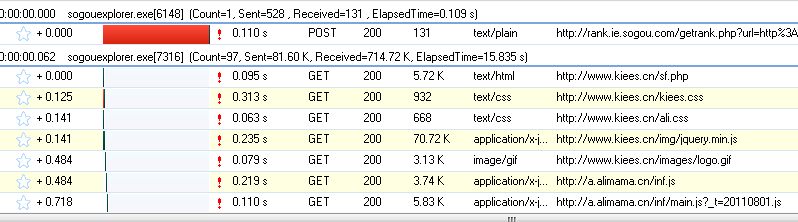
为了更方便的查看JS的结果,我们先清空这些数据,然后再网页中输入快递单号:107818590577,点击查询按钮,然后查看HTTP Analyzer的结果:

这个就是点击查询按钮之后,HTTP Analyzer的结果,我们继续查看:
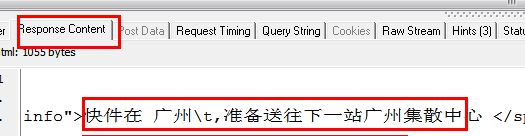
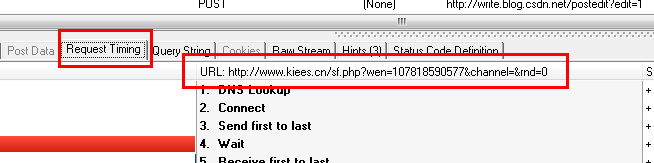
从上面两幅图中可以看出,HTTP Analyzer可以截获JS返回的数据,并在Response Content中显示,同时可以看到JS请求的网页地址。
既然如此,我们只要分析HTTP Analyzer的结果,然后模拟JS的行为就可获取到数据,即我们只要访问JS请求的网页地址来获取数据,当然前提是这些数据是没有经过加密的,我们记下JS请求的URL:http://www.kiees.cn/sf.php?wen=107818590577&channel=&rnd=0
然后让程序去请求这个网页的结果即可!
下面是代码:
- public void captureJavascript(String postid) throws Exception {
- String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
- + "&channel=&rnd=0";
- URL url = new URL(strURL);
- HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
- InputStreamReader input = new InputStreamReader(httpConn
- .getInputStream(), "utf-8");
- BufferedReader bufReader = new BufferedReader(input);
- String line = "";
- StringBuilder contentBuf = new StringBuilder();
- while ((line = bufReader.readLine()) != null) {
- contentBuf.append(line);
- }
- System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
- }
看到了吧,抓取JS的方式和前面抓取原网页的代码一模一样,我们只不过做了一个分析JS的过程。
下面是程序执行的结果:
captureJavascript()的结果:
<div class="results"><div id="ali-itu-wl-result" class="ali-itu-wl-result"><h2 class="logisTitle">运单<span class="mail-no">【107818590577】</span>的跟踪信息</h2><div class="trace_result"><ul><li><span class="time">2012-07-16 15:46:00</span><span class="info">已收件 </span></li><li><span class="time">2012-07-16 16:03:00</span><span class="info">快件在 广州\t,准备送往下一站广州集散中心 </span></li><li><span class="time">2012-07-16 19:33:00</span><span class="info">快件在 广州集散中心,准备送往下一站佛山集散中心 </span></li><li><span class="time">2012-07-17 01:56:00</span><span class="info">快件在 佛山集散中心\t,准备送往下一站佛山 </span></li><li><span class="time">2012-07-17 09:41:00</span><span class="info">正在派件.. </span></li><li><span class="time">2012-07-17 11:28:00</span><span class="info">派件已签收 </span></li><li><span class="time">2012-07-17 11:28:00</span><span class="info">签收人是:已签收 </span></li></ul><div></div></div></div> </div>
这些数据就是JS返回的结果了,我们的目的达到了!
希望本文能够对需要的朋友有一点帮助,需要程序源码的,请点击这里下载!http://download.csdn.net/download/zgyulongfei/4526567