昨天我们分析了今日头条搜索得到的信息,一直对图集感兴趣的我还是选择将所有的图片下载下来。
我们继续讲一下如何通过各个图集的url得到每个图集下面的照片。
分析图集的组成
【插入图片,某个图集的页面】
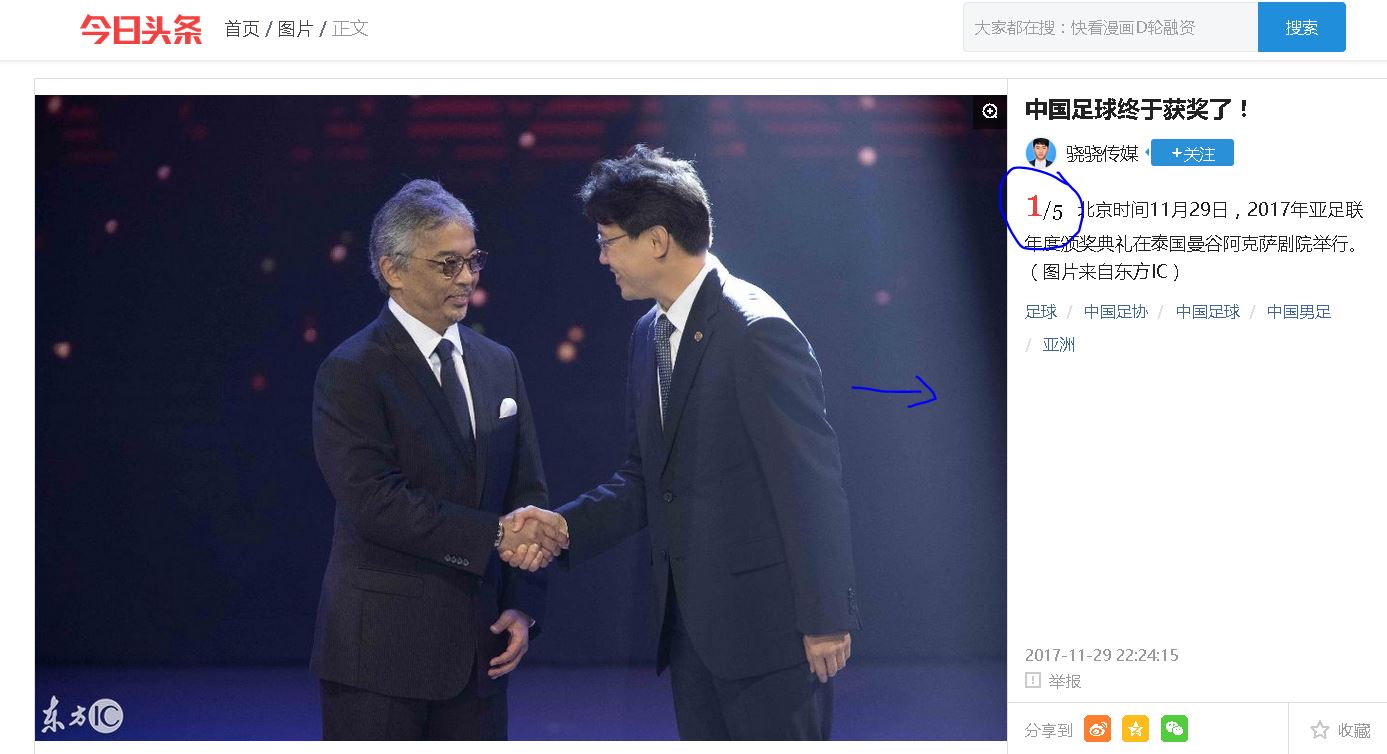
我们看上面的这个图片,右面的1/5可以看出,这个图集有5张图片,在图片上右侧点击的话,会打开下一张图片。
我们来看一下这些图片的url在哪里?
分析图集的源代码
【插入图片,图集页的XHR信息】

我们先看一下XHR,返回的仍然是一些json信息,但是每个json里面的内容都不是我们需要的图片的url。
而是一些评论、广告等信息。
那么这些图片的url在哪里呢?
我们再看一下html的源代码。
【插入图片,图集源代码】
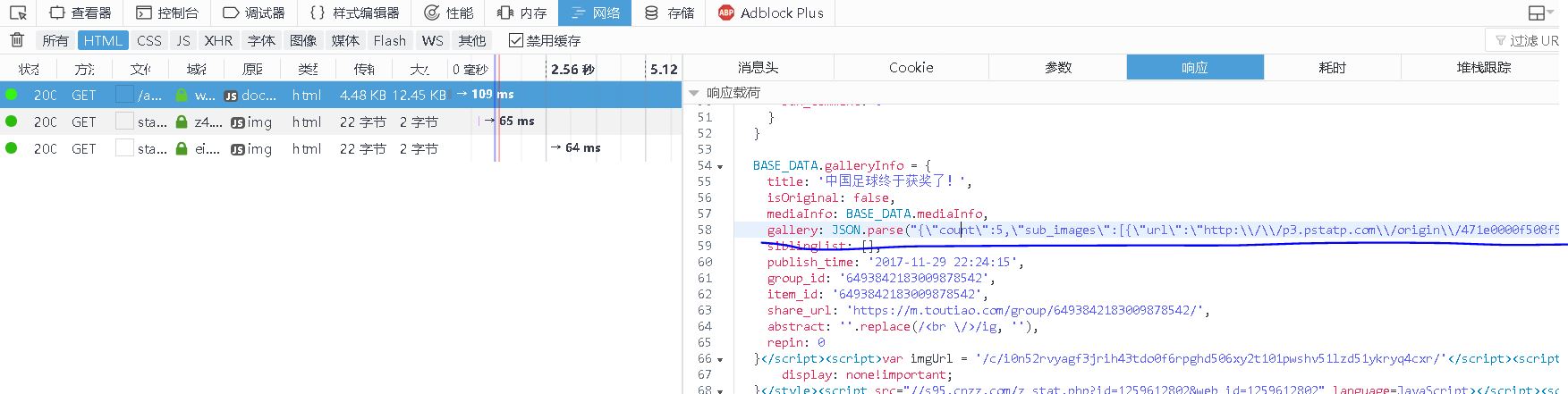
我们在响应内容中竟然发现了一个gallery,里面包含了5张图片的url。
既然在响应中可以找到内容,我们就可以使用requests的get方法来请求到这些响应,但是如何将每张图片的url提取出来?
从响应中提取URL
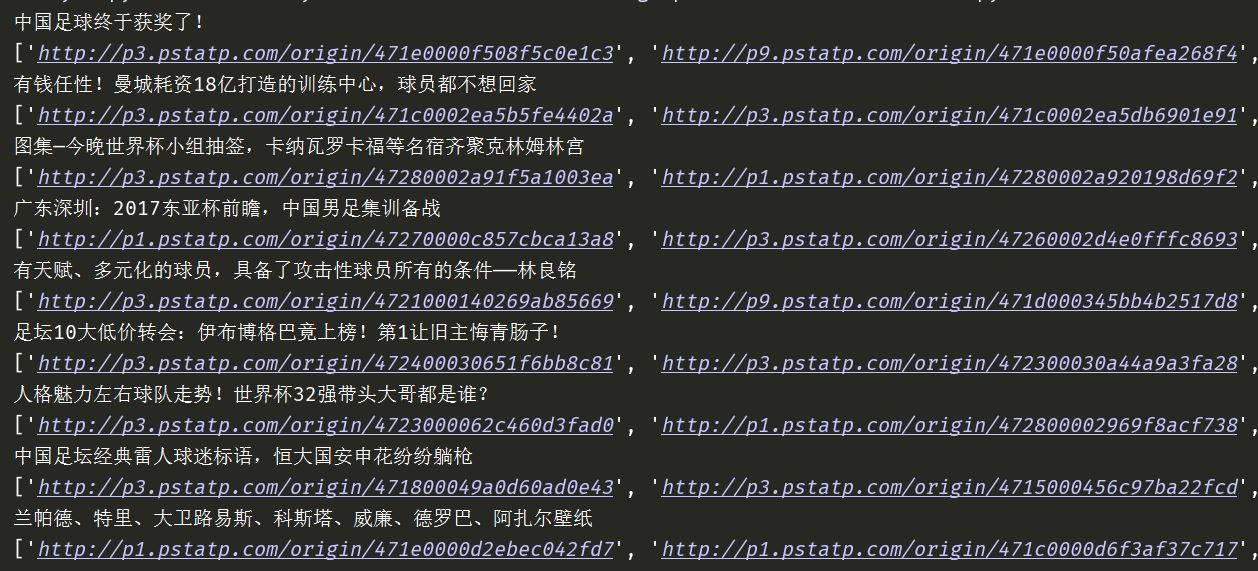
【插入图片,gallery内容】

我们仔细看一下,gallery里面,使用json.parse命令,将一个json字符串转换成了对象。里面包含了url信息,但是挺难提取出来。
尤其是在url中存在很多\\,相信很多读者都搞不清楚了。我们简单讲解一下:
要匹配字符串中1个反斜杠\\怎么写正则表达式?"\\",这样可以吗?我们经过尝试,出现异常了。因为在正则表达式中,"\\"就是一个反斜杠,对于正则表达式解析式来说,就是一个转义字符,后面啥匹配内容没有,自然报错。我们应该用四个反斜杠"\\\\"这样就可以了。
代码如下:
import re
re_str_patt = "\\\\"#这里指的是要匹配一个反斜杠
reObj = re.compile(re_str_patt)
str_test = "abc\\cd\\hh"#这里的意思是abc\\cd\\hh
print reObj.findall(str_test)
输出:[\'\\\', \'\\\']
如果我们使用r,也就是原生字符串,举个例子;
import re
re_str_patt = r"\\\\"#匹配"\\"
reObj = re.compile(re_str_patt)
str_test = "abc\\cd\\hh"#abc\\cd\\hh
print reObj.findall(str_test)
输出:[]#啥也没找到。
所以各位读者应该能感觉到,我还是想使用re正则来把url匹配出来的。
当然,图集的title我们也要获取,这时尝试用beautifulsoup来解析吧,省得忘记用法。
3、获取图集页的源代码
def get_page_detail(url):
try:
response = requests.get(url)
if response.status_code==200:
return response.text
else:
return None
except Exception:
print(\'请求索引页出错!\')
return None
很简单,使用requests很容易就得到了源代码。
4、获取某个图集的所有图片url
def parse_page_detail(html):
soup=BeautifulSoup(html,\'lxml\')
title=soup.select(\'title\')[0].get_text()
print(title)
images_pattern=re.compile(r\'url\\\\":\\\\"(.*?)\\\\"}],\\\\"uri\')#url\\":\\"(url)\\"}],\\uri
items=re.findall(images_pattern,html)
result=[]
for item in items:
new_item=\'\'.join(item.split(\'\\\\\'))#将匹配出来的字符串中的所有\\都去除掉
#result.append(new_item)
http_pattern=re.compile(r\'(http.*?)","width\')#匹配所有正常的url地址
a_items=re.findall(http_pattern,new_item)
result.append(a_items[0])#取第一个url即可。
print(result)
return result
主要的难度在于解析上。上面的代码单纯看的话,很难懂,希望大家能动手尝试一下,看看每一步都输出什么样的结果。
这里就不展开讲解了。
5、运行
def main(offset):
html=get_page_index(offset)
for url in parse_page_index(html):
content=get_page_detail(url)
parse_page_detail(content)
if __name__==\'__main__\':
# p=Pool()
# p.map(main,[i*20 for i in range(3)])
for i in range(3):
main(i*20)
【插入图片,图片结果】
这次没有用多进程来操作,结果慢了很多。。。
昨天和今天的讲解,主要内容还是在于如何对Ajax加载的内容进行分析,如何获取json数据。图片的下载前面我们已经有过实战案例了,这里就不在重复写代码了。
希望大家有所收获。
