Redis常见面试题万字总结
Posted androidstarjack
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis常见面试题万字总结相关的知识,希望对你有一定的参考价值。
点击上方关注 “终端研发部”
设为“星标”,和你一起掌握更多数据库知识一、Redis的理解
Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
读写性能优异
Redis:读的速度是110000次/s,写的速度是81000次/s
数据类型丰富
Redis支持Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
原子性
支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
丰富的特性
Redis支持简易订阅通知(Pub/Sub) ,按key设置过期时间,过期后将会自动删除。
持久化
Redis支持RDB, AOF等持久化方式
二、为什么Redis 是单线程的以及为什么这么快
单线程的原因:
Redis的瓶颈不是CPU,而是网络和内存。
多线程就会存在死锁、线程上下⽂切换等问题,甚⾄会影响性能。
单线程编程容易并且更容易维护。
Redis快的原因:
1、redis完全基于内存:绝大部分请求是纯粹的内存操作,非常快速。
2、数据结构简单:redis中的数据结构是专门进行设计的。
3、采用单线程模型,避免了不必要的上下文切换和竞争条件:也不存在多线程或者多线程切换而消耗CPU, 不用考虑各种锁的问题, 不存在加锁, 释放锁的操作, 没有因为可能出现死锁而导致性能消耗
4、使用了多路IO复用模型:非阻塞IO
三、Redis的使用场景
热点数据的缓存
缓存是Redis最常见的应用场景,主要是因为Redis读写性能优异。而且逐渐有取代memcached,成为首选服务端缓存的组件。而且,Redis内部是支持事务的,在使用时候能有效保证数据的一致性。
限时业务的运用
redis中可以使用expire命令设置一个键的生存时间,到时间后redis会删除它。利用这一特性可以运用在限时的优惠活动信息、手机验证码等业务场景。
计数器相关问题
redis由于incrby命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成、具体业务还体现在比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等。
分布式锁
这个主要利用redis的setnx命令进行,setnx:”set if not exists”就是如果不存在则成功设置缓存同时返回1,否则返回0 。因为我们服务器是集群的,定时任务可能在两台机器上都会运行,所以在定时任务中首先 通过setnx设置一个lock,如果成功设置则执行,如果没有成功设置,则表明该定时任务已执行。当然结合具体业务,我们可以给这个lock加一个过期时间,比如说30分钟执行一次的定时任务,那么这个过期时间设置为小于30分钟的一个时间就可以,这个与定时任务的周期以及定时任务执行消耗时间相关。Redis分布式锁真的安全吗?
四、Redis的数据类型
expire:设置key的过期时间
persist:设置key永久有效
5种基础数据类型:String、List、Set、Zset、Hash。
三种特殊的数据类型:HyperLogLogs(基数统计), Bitmaps (位图) , geospatial (地理位置)
String(字符串):
底层数据结构:SDS即动态字符串,最大容量512M,每次最多扩容1M,是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或序列化的对象
应用场景:分布式锁、计数器(如访问次数、点赞转发数量)
常用方法:set 、get、strlen 、incr 、 decr 、setnx、setex、exists
list(双向列表):
特点:单值多键,用来存储多个有序的字符串,一个列表最多可以存储2^32-1个元素。可以实现队列和栈
底层数据结构:快表
应用场景:消息队列 、文章列表
常用方法:lpush 、lrang 、rpush 、lpop 、rpop 、llen、lindex、rpoplpush、linsert
Hash(哈希):
底层数据结构:压缩列表、哈希表。
特点:指v(值)本身又是一个键值对(k-v)结构
应用场景:缓存用户信息、购物车等。
常用方法:hset 、hget 、hkeys 、hvals 、hmset 、hmget 、hgetAll 、hlen 、hdel 、hsetnx 、hexists
set(集合):
特点:用来保存多个的字符串元素,但是不允许重复元素,元素是无序的。可以实现并集、交集、差集的操作
底层数据结构:哈希表、整数集
应用场景:抽奖、共同关注、QQ内推等。
常用方法:sadd 、smembers 、sismember 、scard 、srem 、srandmember、spop、smove、sdiff、sinter、sunion
zset(有序集合):
特点:有序不重复的集合。和 set 相⽐sorted set 增加了⼀个权重参数 score,可以根据score进行排序,但score是可以重复的,value是不可以重复的。
底层数据结构:压缩列表、跳表
应用场景:排行榜、抖音热搜
常用方法:zadd 、zrange 、zrangebyscore(按score从小到大) 、zrem 、zcard 、zcount 、zrevrange(按score从大到小)
五、Redis的持久化机制
1、RDB(snapshotting):
是Redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义快照的周期。
触发方式:触发rdb持久化的方式有2种,分别是手动触发和自动触发。
手动触发:
save命令:阻塞当前Redis服务器,直到RDB过程完成为止,对于内存 比较大的实例会造成长时间阻塞,线上环境不建议使用
bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子 进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。下面是bgsave流程图:

自动触发:
redis.conf中配置
save m n,即在m秒内有n次修改时,自动触发bgsave生成rdb文件;主从复制时,从节点要从主节点进行全量复制时也会触发bgsave操作,生成当时的快照发送到从节点;
执行debug reload命令重新加载redis时也会触发bgsave操作;
默认情况下执行shutdown命令时,如果没有开启aof持久化,那么也会触发bgsave操作;
优点:
只有一个文件 dump.rdb,方便持久化。
容灾性好,一个文件可以保存到安全的磁盘。
性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,所以是 IO 最大化。
相对于数据集大时,比 AOF 的启动效率更高。
缺点:
数据安全性低。RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候
2、AOF(append-only-file):
将Redis执行的每次写命令记录到单独的日志文件中,当重启Redis会重新将持久化的日志中文件恢复数据。AOF日志是一种写后日志,“写后”的意思是Redis是先执行命令,把数据写入内存,然后才记录日志
为什么采用写后日志?
避免额外的检查开销:Redis 在向 AOF 里面记录日志的时候,并不会先去对这些命令进行语法检查。所以,如果先记日志再执行命令的话,日志中就有可能记录了错误的命令,Redis 在使用日志恢复数据时,就可能会出错。
不会阻塞当前的写操作
但这种方式存在潜在风险:
如果命令执行完成,写日志之前宕机了,会丢失数据。
主线程写磁盘压力大,导致写盘慢,阻塞后续操作。
AOF的实现:
AOF日志记录Redis的每个写命令,步骤分为:命令追加、文件的写入和同步。
命令追加:当AOF持久化功能打开了,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器的 aof_buf 缓冲区。
文件写入和同步:关于何时将 aof_buf 缓冲区的内容写入AOF文件中,Redis提供了三种写回策略:
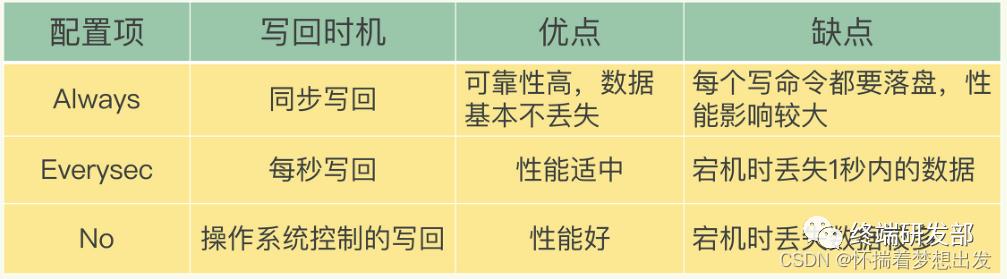
AOF的重写 :
Redis通过创建一个新的AOF文件来替换现有的AOF,新旧两个AOF文件保存的数据相同,但新AOF文件没有了冗余命令。
AOF重写会阻塞吗?
AOF重写过程是由后台进程bgrewriteaof来完成的。主线程fork出后台的bgrewriteaof子进程,fork会把主线程的内存拷贝一份给bgrewriteaof子进程,这里面就包含了数据库的最新数据。然后,bgrewriteaof子进程就可以在不影响主线程的情况下,逐一把拷贝的数据写成操作,记入重写日志。
所以aof在重写时,在fork进程时是会阻塞住主线程的。
AOF日志何时会重写?
有两个配置项控制AOF重写的触发:
auto-aof-rewrite-min-size:表示运行AOF重写时文件的最小大小,默认为64MB。
auto-aof-rewrite-percentage:这个值的计算方式是,当前aof文件大小和上一次重写后aof文件大小的差值,再除以上一次重写后aof文件大小。也就是当前aof文件比上一次重写后aof文件的增量大小,和上一次重写后aof文件大小的比值。
优点:
安全,所有写入的数据都不会丢失。
AOF文件易读,可修改。
缺点:
AOF 文件比 RDB 文件大。
恢复速度慢。
性能消耗高。
六、过期Key的删除策略
定时过期:每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。对内存很友好,但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
惰性删除:当key被访问时检查该key的过期时间,若已过期则删除;已过期未被访问的数据仍保持在内存中。可以最大化地节省CPU资源,却对内存非常不友好。
定期删除:每隔一段时间,会扫描一定数量设置了过期的key,并删除已过期的key。是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
七、内存淘汰策略
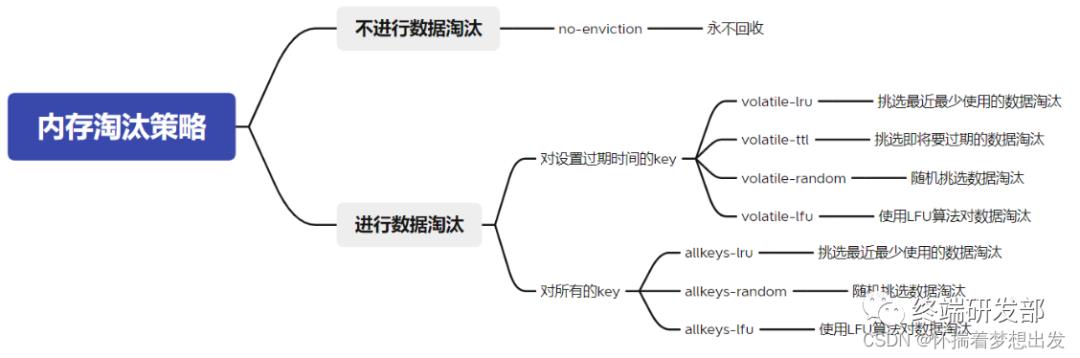
八、事务
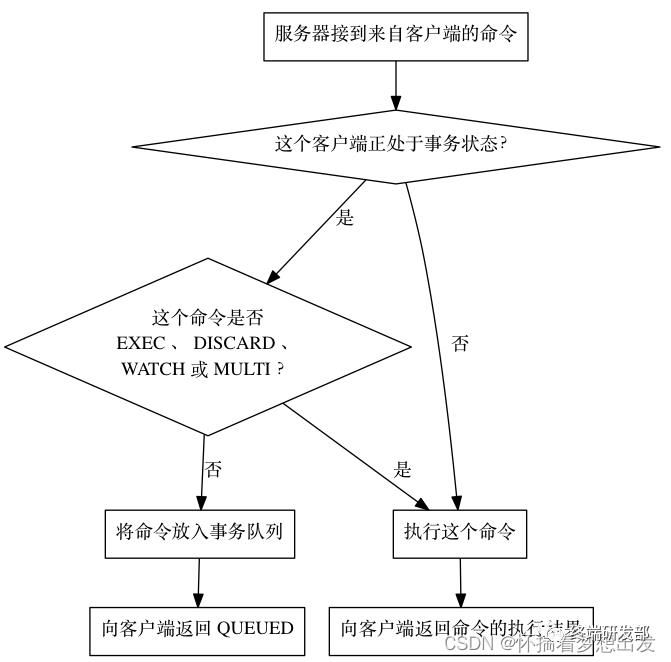
Redis 事务的本质是一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
总结说:redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
1、相关命令:
MULTI :开启事务,redis会将后续的命令逐个放入队列中,然后使用EXEC命令来原子化执行这个命令系列。
EXEC:执行事务中的所有操作命令。
DISCARD:取消事务,放弃执行事务块中的所有命令。
WATCH:监视一个或多个key,如果事务在执行前,这个key(或多个key)被其他命令修改,则事务被中断,不会执行事务中的任何命令。
UNWATCH:取消WATCH对所有key的监视。
2、执行的3个阶段:
开启:以MULTI开始一个事务
入队:将多个命令入队到事务中,接到这些命令并不会立即执行,而是放到等待执行的事务队列里面
执行:由EXEC命令触发事务
3、Redis 对 ACID的支持性理解
原子性atomicity
Redis官方文档给的理解是,Redis的事务是原子性的:所有的命令,要么全部执行,要么全部不执行。而不是完全成功。
一致性consistency
redis事务可以保证命令失败的情况下得以回滚,数据能恢复到没有执行之前的样子,是保证一致性的,除非redis进程意外终结。
隔离性Isolation
redis事务是严格遵守隔离性的,原因是redis是单进程单线程模式(v6.0之前),可以保证命令执行过程中不会被其他客户端命令打断。但是,Redis不像其它结构化数据库有隔离级别这种设计。
持久性Durability
redis事务是不保证持久性的,这是因为redis持久化策略中不管是RDB还是AOF都是异步执行的,不保证持久性是出于对性能的考虑。
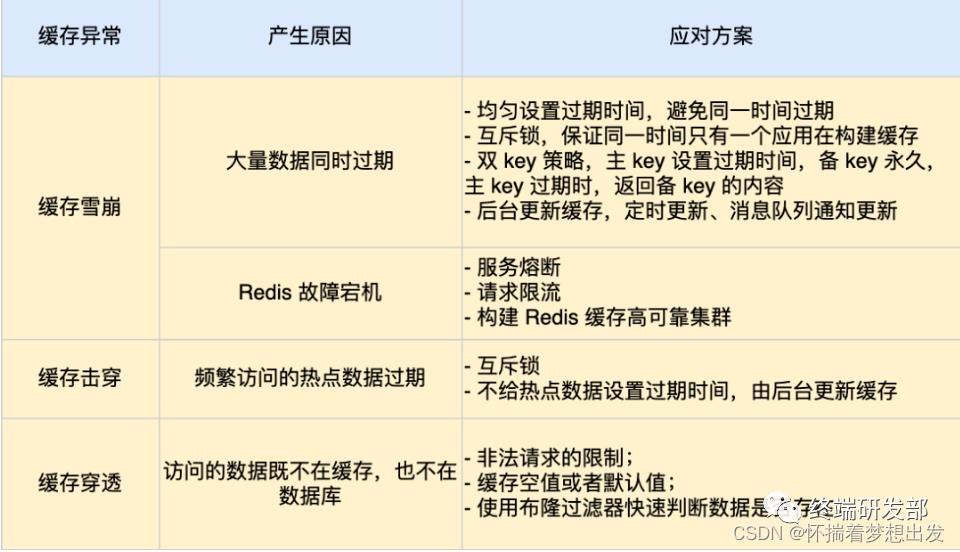
九、Redis缓存的问题和解决
1、缓存穿透
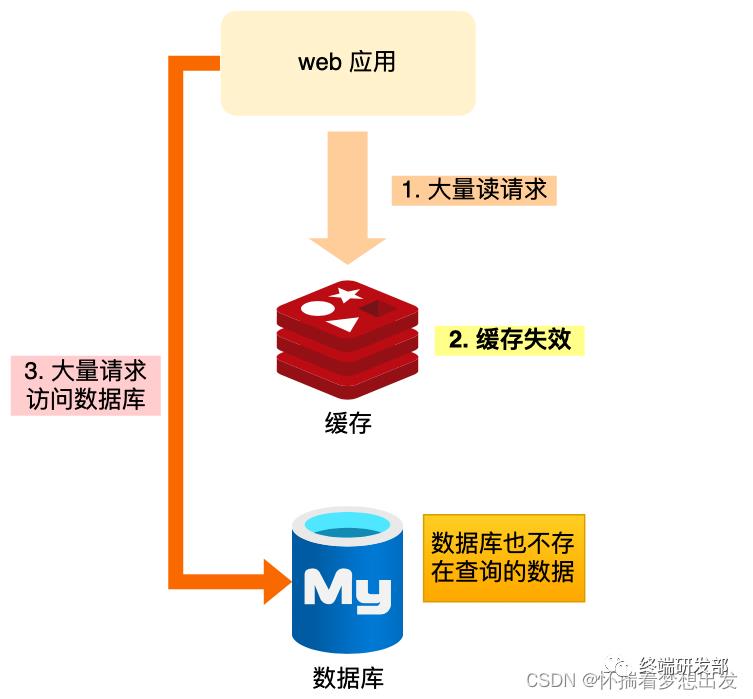
每一次请求不同的值(符合有效的值规则),并且该值是数据库不可能存在的。那么就会出现不停的访问数据库,并返回空。这样就使 redis 无效化,便是缓存穿透。
当发生缓存雪崩或击穿时,数据库中还是保存了应用要访问的数据,一旦缓存恢复相对应的数据,就可以减轻数据库的压力,而缓存穿透就不一样了。
当用户访问的数据既不在缓存中,也不在数据库中,导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,没办法构建缓存数据,来服务后续的请求。那么当短时间内有大量这样的请求到来时,数据库的压力骤增,这就是缓存穿透的问题。
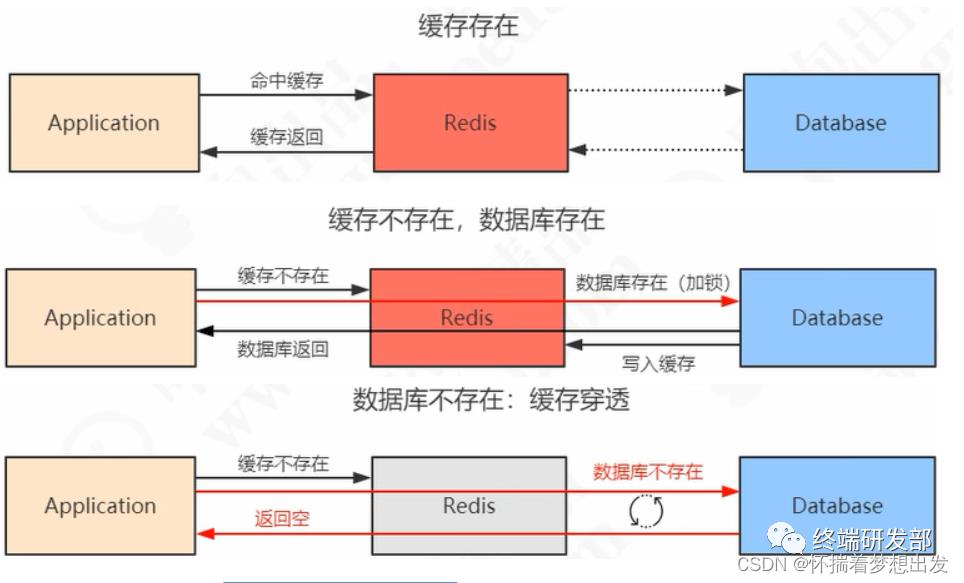
解决方案
缓存穿透的发生一般有这两种情况:
业务误操作,缓存中的数据和数据库中的数据都被误删除了,所以导致缓存和数据库中都没有数据;
黑客恶意攻击,故意大量访问某些读取不存在数据的业务;
应对缓存穿透的方案,常见的方案有三种。
1、非法请求的限制;
当有大量恶意请求访问不存在的数据的时候,也会发生缓存穿透,因此在 API 入口处我们要判断求请求参数是否合理,请求参数是否含有非法值、请求字段是否存在,如果判断出是恶意请求就直接返回错误,避免进一步访问缓存和数据库。
2、缓存空值或者默认值;
当我们线上业务发现缓存穿透的现象时,可以针对查询的数据,在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库。
3、使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在;
布隆过滤器的本质:
位数组(二进制向量)
一系列随机映射函数
布隆过滤器实现思想:
假设有一个 bit数组,里面存的只有0和1;0代表不存在,1代表存在
我们假设有 多种不同的hash算法来计算同一个值的结果,并反应在改变数组对应下标的值;
当值存入时会进行多次不同的hash算法计算,多个计算结果都反应在数组下标上,都改变为1(存在)
在判断值是否存在时,就看对应算出的多个下标是否都为1(可能存在),或者任意一个为0(绝对不存在)
2、缓存穿击
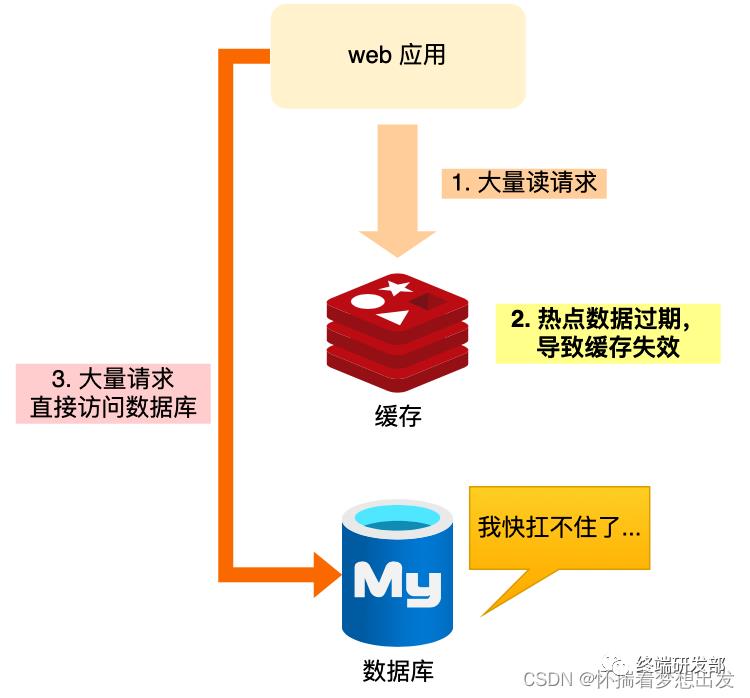
业务通常会有几个数据会被频繁地访问,比如秒杀活动,这类被频地访问的数据被称为热点数据【当前key是一个热点key**】**
如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的SQL、多次IO、多个依赖等。直接访问数据库,在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,数据库很容易就被高并发的请求冲垮,这就是缓存击穿的问题
解决方案
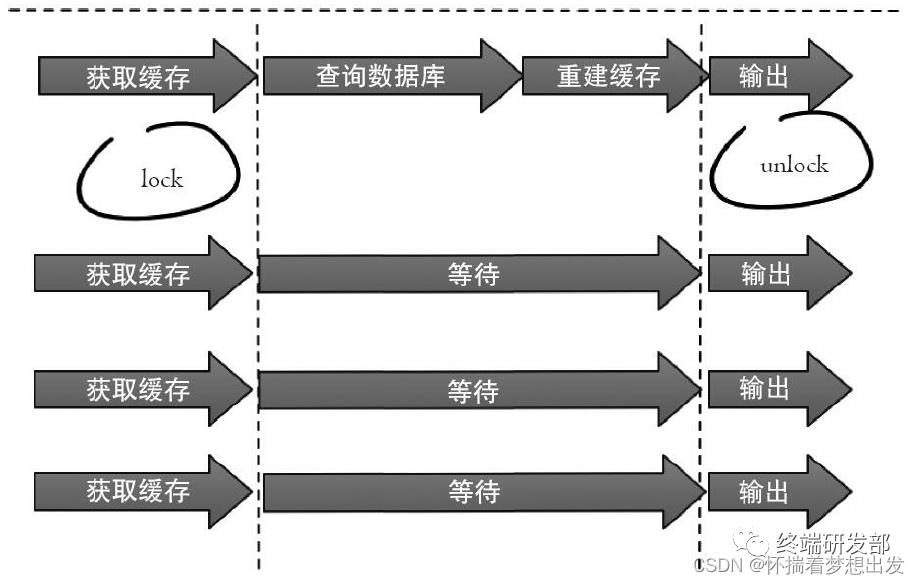
1、**互斥锁方案**
保证同一时间只允许一个线程重建缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值【set(key,value,timeout)】。
2、**永不过期**
不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间
总结对比:
分布式互斥锁:这种方案思路比较简单,但是存在一定的隐患,如果在查询数据库 + 和 重建缓存(key失效后进行了大量的计算)时间过长,也可能会存在死锁和线程池阻塞的风险,高并发情景下吞吐量会大大降低!但是这种方法能够较好地降低后端存储负载,并在一致性上做得比较好。
永远不过期:这种方案由于没有设置真正的过期时间,实际上已经不存在热点key产生的一系列危害,但是会存在数据不一致的情况,同时代码复杂度会增大。
3、缓存雪崩
通常我们为了保证缓存中的数据与数据库中的数据一致性,会给 Redis 里的数据设置过期时间,当缓存数据过期后,用户访问的数据如果不在缓存里,业务系统需要重新生成缓存,因此就会访问数据库,并将数据更新到 Redis 里,这样后续请求都可以直接命中缓存。
那么,当大量缓存数据在同一时间过期(失效)或者 Redis 故障宕机时,如果此时有大量的用户请求,都无法在 Redis 中处理,于是全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃,这就是缓存雪崩的问题。
和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
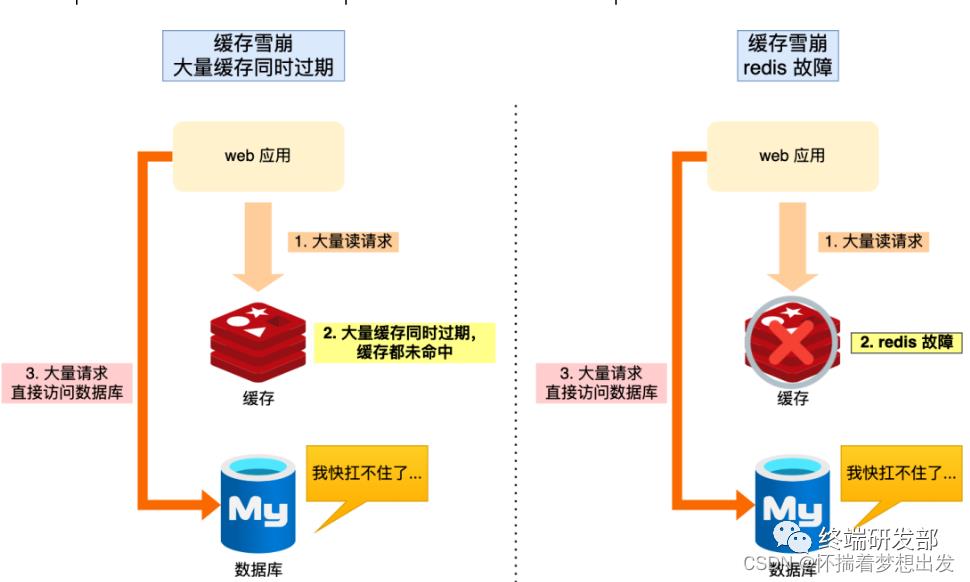
可以看到,发生缓存雪崩有两个原因:
大量数据同时过期;
Redis 故障宕机;
解决方案
1、大量数据同时过期
针对大量数据同时过期而引发的缓存雪崩问题,常见的应对方法有下面这几种:
均匀设置过期时间;
互斥锁;
双 key 策略;
后台更新缓存;
1. 均匀设置过期时间
如果要给缓存数据设置过期时间,应该避免将大量的数据设置成同一个过期时间。我们可以在对缓存数据设置过期时间时,给这些数据的过期时间加上一个随机数,这样就保证数据不会在同一时间过期。
2. 互斥锁
当业务线程在处理用户请求时,如果发现访问的数据不在 Redis 里,就加个互斥锁,保证同一时间内只有一个请求来构建缓存(从数据库读取数据,再将数据更新到 Redis 里),当缓存构建完成后,再释放锁。未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
实现互斥锁的时候,最好设置超时时间,不然第一个请求拿到了锁,然后这个请求发生了某种意外而一直阻塞,一直不释放锁,这时其他请求也一直拿不到锁,整个系统就会出现无响应的现象。
3. 双 key 策略
我们对缓存数据可以使用两个 key,一个是主 key,会设置过期时间,一个是备 key,不会设置过期,它们只是 key 不一样,但是 value 值是一样的,相当于给缓存数据做了个副本。
当业务线程访问不到「主 key 」的缓存数据时,就直接返回「备 key 」的缓存数据,然后在更新缓存的时候,同时更新「主 key 」和「备 key 」的数据。
4. 后台更新缓存
业务线程不再负责更新缓存,缓存也不设置有效期,而是让缓存“永久有效”,并将更新缓存的工作交由后台线程定时更新。
事实上,缓存数据不设置有效期,并不是意味着数据一直能在内存里,因为当系统内存紧张的时候,有些缓存数据会被“淘汰”,而在缓存被“淘汰”到下一次后台定时更新缓存的这段时间内,业务线程读取缓存失败就返回空值,业务的视角就以为是数据丢失了。
解决上面的问题的方式有两种。
第一种方式,后台线程不仅负责定时更新缓存,而且也负责频繁地检测缓存是否有效,检测到缓存失效了,原因可能是系统紧张而被淘汰的,于是就要马上从数据库读取数据,并更新到缓存。
这种方式的检测时间间隔不能太长,太长也导致用户获取的数据是一个空值而不是真正的数据,所以检测的间隔最好是毫秒级的,但是总归是有个间隔时间,用户体验一般。
第二种方式,在业务线程发现缓存数据失效后(缓存数据被淘汰),通过消息队列发送一条消息通知后台线程更新缓存,后台线程收到消息后,在更新缓存前可以判断缓存是否存在,存在就不执行更新缓存操作;不存在就读取数据库数据,并将数据加载到缓存。这种方式相比第一种方式缓存的更新会更及时,用户体验也比较好。
在业务刚上线的时候,我们最好提前把数据缓起来,而不是等待用户访问才来触发缓存构建,这就是所谓的缓存预热,后台更新缓存的机制刚好也适合干这个事情。
2、Redis 故障宕机
针对 Redis 故障宕机而引发的缓存雪崩问题,常见的应对方法有下面这几种:
服务熔断或请求限流机制;
构建 Redis 缓存高可靠集群;
1. 服务熔断或请求限流机制
因为 Redis 故障宕机而导致缓存雪崩问题时,我们可以启动服务熔断机制,暂停业务应用对缓存服务的访问,直接返回错误,不用再继续访问数据库,从而降低对数据库的访问压力,保证数据库系统的正常运行,然后等到 Redis 恢复正常后,再允许业务应用访问缓存服务。
服务熔断机制是保护数据库的正常允许,但是暂停了业务应用访问缓存服系统,全部业务都无法正常工作
为了减少对业务的影响,我们可以启用请求限流机制,只将少部分请求发送到数据库进行处理,再多的请求就在入口直接拒绝服务,等到 Redis 恢复正常并把缓存预热完后,再解除请求限流的机制。
2. 构建 Redis 缓存高可靠集群
服务熔断或请求限流机制是缓存雪崩发生后的应对方案,我们最好通过主从节点的方式构建 Redis 缓存高可靠集群。
如果 Redis 缓存的主节点故障宕机,从节点可以切换成为主节点,继续提供缓存服务,避免了由于 Redis 故障宕机而导致的缓存雪崩问题。
十、Redis的集群
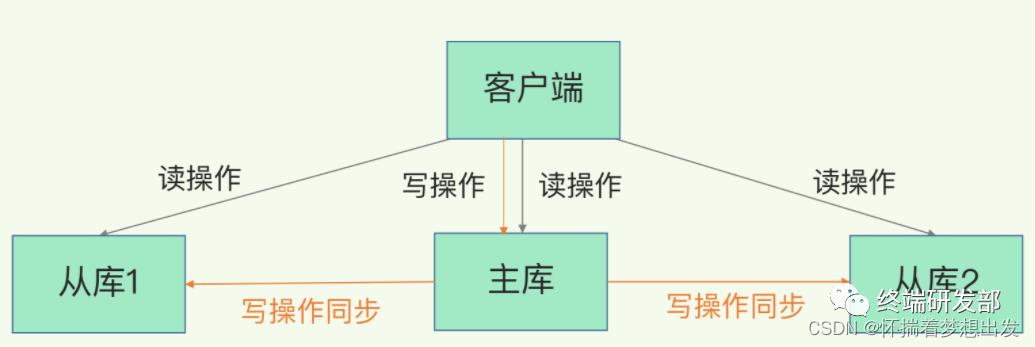
1、主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
作用:
数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务,分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
主从库之间采用的是读写分离的方式。
读操作:主库、从库都可以接收;
写操作:首先到主库执行,然后,主库将写操作同步给从库
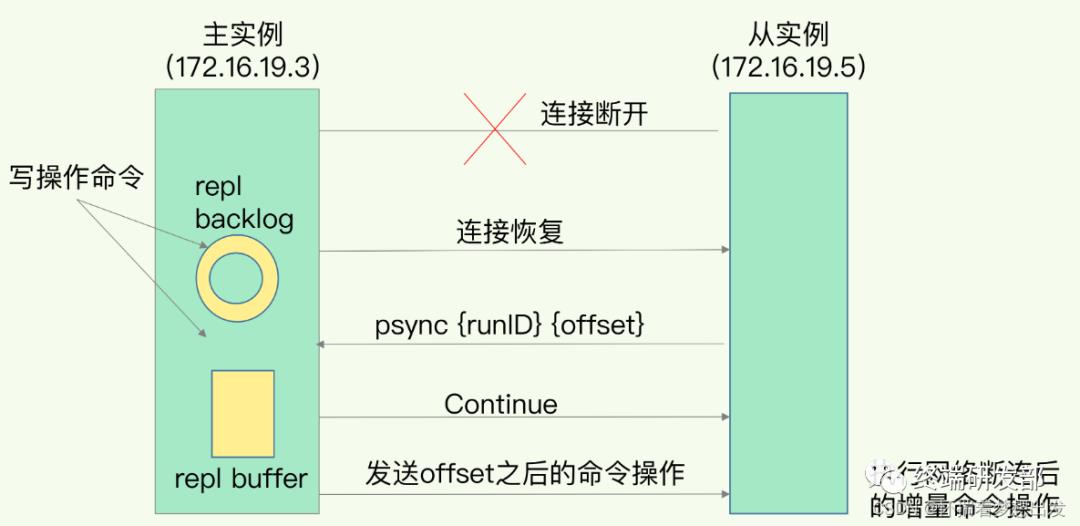
全量(同步)复制:比如第一次同步时
增量(同步)复制:只会把主从库网络断连期间主库收到的命令,同步给从库
Redis 全量复制的三个阶段:

第一阶段:主从库间建立连接、协商同步的过程,主要是为全量复制做准备。在这一步,从库和主库建立起连接,并告诉主库即将进行同步,主库确认回复后,主从库间就可以开始同步了。
具体来说,从库给主库发送 psync 命令,表示要进行数据同步,主库根据这个命令的参数来启动复制。psync 命令包含了主库的 runID 和复制进度 offset 两个参数。runID,是每个 Redis 实例启动时都会自动生成的一个随机 ID,用来唯一标记这个实例。当从库和主库第一次复制时,因为不知道主库的 runID,所以将 runID 设为“?”。offset,此时设为 -1,表示第一次复制。主库收到 psync 命令后,会用 FULLRESYNC 响应命令带上两个参数:主库 runID 和主库目前的复制进度 offset,返回给从库。从库收到响应后,会记录下这两个参数。这里有个地方需要注意,FULLRESYNC 响应表示第一次复制采用的全量复制,也就是说,主库会把当前所有的数据都复制给从库。
第二阶段:主库将所有数据同步给从库。从库收到数据后,在本地完成数据加载。这个过程依赖于内存快照生成的 RDB 文件。
具体来说,主库执行 bgsave 命令,生成 RDB 文件,接着将文件发给从库。从库接收到 RDB 文件后,会先清空当前数据库,然后加载 RDB 文件。这是因为从库在通过 replicaof 命令开始和主库同步前,可能保存了其他数据。为了避免之前数据的影响,从库需要先把当前数据库清空。在主库将数据同步给从库的过程中,主库不会被阻塞,仍然可以正常接收请求。否则,Redis 的服务就被中断了。但是,这些请求中的写操作并没有记录到刚刚生成的 RDB 文件中。为了保证主从库的数据一致性,主库会在内存中用专门的 replication buffer,记录 RDB 文件生成后收到的所有写操作。
第三个阶段:主库会把第二阶段执行过程中新收到的写命令,再发送给从库。具体的操作是,当主库完成 RDB 文件发送后,就会把此时 replication buffer 中的修改操作发给从库,从库再重新执行这些操作。这样一来,主从库就实现同步了。
Redis 增量复制的流程:
Redis 为什么主从全量复制使用RDB而不使用AOF?
1、RDB文件内容是经过压缩的二进制数据(不同数据类型数据做了针对性优化),文件很小。而AOF文件记录的是每一次写操作的命令,写操作越多文件会变得很大,其中还包括很多对同一个key的多次冗余操作。在主从全量数据同步时,传输RDB文件可以尽量降低对主库机器网络带宽的消耗,从库在加载RDB文件时,一是文件小,读取整个文件的速度会很快,二是因为RDB文件存储的都是二进制数据,从库直接按照RDB协议解析还原数据即可,速度会非常快,而AOF需要依次重放每个写命令,这个过程会经历冗长的处理逻辑,恢复速度相比RDB会慢得多,所以使用RDB进行主从全量复制的成本最低。
2、假设要使用AOF做全量复制,意味着必须打开AOF功能,打开AOF就要选择文件刷盘的策略,选择不当会严重影响Redis性能。而RDB只有在需要定时备份和主从全量复制数据时才会触发生成一次快照。而在很多丢失数据不敏感的业务场景,其实是不需要开启AOF的。
Redis 为什么还会有从库的从库的设计?
一次全量复制中,对于主库来说,需要完成两个耗时的操作:生成 RDB 文件和传输 RDB 文件。
如果从库数量很多,而且都要和主库进行全量复制的话,就会导致主库忙于 fork 子进程生成 RDB 文件,进行数据全量复制。fork 这个操作会阻塞主线程处理正常请求,从而导致主库响应应用程序的请求速度变慢。此外,传输 RDB 文件也会占用主库的网络带宽,同样会给主库的资源使用带来压力。那么,有没有好的解决方法可以分担主库压力呢?
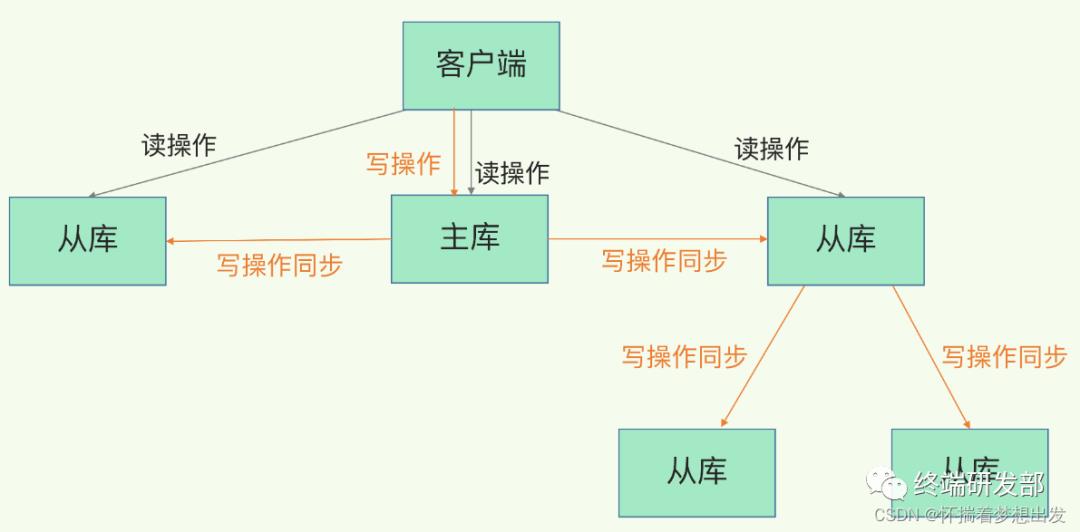
其实是有的,这就是“主 - 从 - 从”模式。
在刚才介绍的主从库模式中,所有的从库都是和主库连接,所有的全量复制也都是和主库进行的。现在,我们可以通过“主 - 从 - 从”模式将主库生成 RDB 和传输 RDB 的压力,以级联的方式分散到从库上。
简单来说,我们在部署主从集群的时候,可以手动选择一个从库(比如选择内存资源配置较高的从库),用于级联其他的从库。然后,我们可以再选择一些从库(例如三分之一的从库),在这些从库上执行如下命令,让它们和刚才所选的从库,建立起主从关系。
replicaof 所选从库的IP 6379这样一来,这些从库就会知道,在进行同步时,不用再和主库进行交互了,只要和级联的从库进行写操作同步就行了,这就可以减轻主库上的压力,如下图所示:
2、Redis哨兵机制
哨兵的核心功能是主节点的自动故障转移。下图是一个典型的哨兵集群监控的逻辑图:
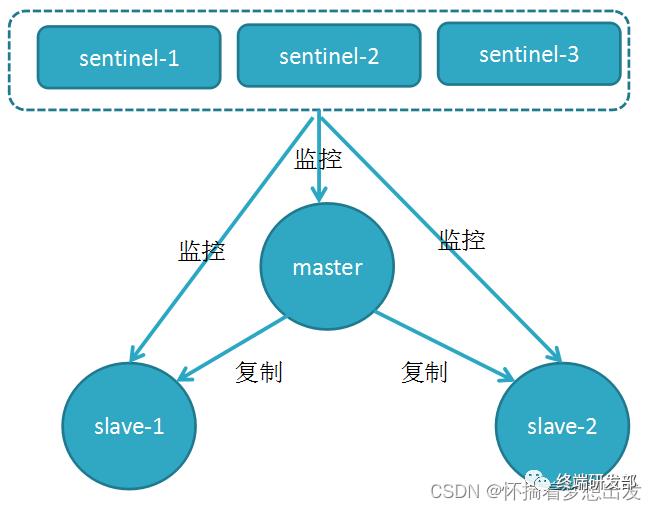
哨兵的作用:
监控(Monitoring):哨兵会不断地检查主节点和从节点是否运作正常。
自动故障转移(Automatic failover):当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
配置提供者(Configuration provider):客户端在初始化时,通过连接哨兵来获得当前Redis服务的主节点地址。
通知(Notification):哨兵可以将故障转移的结果发送给客户端。
其中,监控和自动故障转移功能,使得哨兵可以及时发现主节点故障并完成转移;而配置提供者和通知功能,则需要在与客户端的交互中才能体现。
十一、Redis实现分布式锁
方式一:可能会导致锁一直没有释放
//加锁:如果键存在则不操作,否则操作
Boolean setIfAbsent(K, V );
setnx(K,V);
//释放锁:
Boolean delete(K);
del(K);方式二:可能出现上完锁后,服务器异常,不能设置过期时间(redis的命令不是原子操作)
//加锁:如果键存在则不操作,否则操作
Boolean setIfAbsent(K, V );
setnx(K,V);
//设置过期时间
Boolean expire(K key, final long timeout, final TimeUnit unit)
expire(K,Time);//单位:毫秒
//释放锁:
Boolean delete(K);
del(K);方式四:上锁同时设置过期时间;可能会发生锁误删除。
//加锁并设置过期时间
Boolean setIfAbsent(K key, V value, long timeout, TimeUnit unit);
setex(K,Time,V);//单位:毫秒
//释放锁:
Boolean delete(K);
del(K);方式五:上锁同时设置过期时间;将值设置为uuid,在进行释放锁时,先判断当前的uuid和要释放锁的uuid,若一致进行释放,否则不释放。
//1.进入方案
String requestId = IdWorker.getIdStr();
Boolean ret = redisTemplate.opsForValue().setIfAbsent( "key",requestId,5L,TimeUnit.SECONDS);
//2.判断为true 表示加锁成功,false标识锁已经存在
if(ret)
//3.执行业务
//4.执行结束
Object o = redisTemplate.opsForValue().get(key);
if(o !=null)
if(requestId.equals((String)o))
redisTemplate.delete(key);
else
//5.做异常容错处理
Long expire = redisTemplate.opsForValue().getOperations().getExpire(key);
if(expire !=null && expire.intValue()<0)
redisTemplate.delete(key);
//6.日志打印该模块未执行任务!
log.info("模块:"+MODULE+",定时任务已在执行!");
十二、缓存和数据库双写不一致问题
1、缓存和数据库一致性定义:
缓存中有数据,且和数据库数据一致;
缓存中无数据,数据库数据是最新的。
那么不符合这两种情况就属于缓存和数据库不一致的问题了。
当客户端发送一个数据修改的请求,我们不仅要修改数据库,还要一并操作(修改/删除)缓存。对数据库和缓存的操作又存在一个顺序的问题:到底是先操作数据库还是先操作缓存。
下面我们以客户端向 mysql 中删改数据为例来分析数据不一致的情况。
先不考虑并发问题,正常情况下,无论谁先谁后,都可以让两者保持一致,但现在我们需要重点考虑异常情况。
此时应用既要修改数据库也要修改缓存(删除和修改的影响是类似的,方便起见,下面只描述修改操作)的数据。
这里有两种场景我们分别来看下:
先修改缓存,再修改数据库
先修改数据库,再修改缓存
我们假设应用先修改缓存,再修改数据库。如果缓存修改成功,但是数据库操作失败,那么,应用再访问数据时,缓存中的值是正确的,但是一旦缓存中「数据失效」或者「缓存宕机」,然后,应用再访问数据库,此时数据库中的值为旧值,应用就访问到旧值了。
如果我们先更新数据库,再更新缓存中的值,是不是就可以解决这个问题呢?我们继续分析。
如果应用先完成了数据库的更新,但是,在更新缓存时失败了。那么,数据库中的值是新值,而缓存中的是旧值,这肯定是不一致的。
这个时候,如果有其他的并发请求来访问数据,按照正常的访问流程,就会先在缓存中查询,此时,就会读到旧值了。
好了,到这里,我们可以看到,在操作数据库和更新缓存值的过程中,无论这两个操作的执行顺序谁先谁后,只要「第二步的操作」失败了,就会导致客户端读取到旧值。
我们继续分析,除了「第二步操作失败」的问题,还有什么场景会影响数据一致性:并发问题。
2、并发引发的一致性问题:
先更新数据库,后更新缓存
假设我们采用「先更新数据库,后更新缓存」的方案,并且在两步都可以成功执行的前提下,如果存在并发,情况会是怎样的呢?
有线程 A 和线程 B 两个线程,需要更新「同一条」数据 x,可能会发生这样的场景:
线程 A 更新数据库(x = 1)
线程 B 更新数据库(x = 2)
线程 B 更新缓存(x = 2)
线程 A 更新缓存(x = 1)
最后我们发现,数据库中的 x 是2,而缓存中是1。显然是不一致的。
另外这种场景一般是不推荐使用的。因为某些业务因素,最后写到缓存中的值并不是和数据库是一致的,可能需要一系列计算得出的,最后才把这个值写到缓存中;如果此时有大量的对数据库进行写数据的请求,但是读请求并不多,那么此时如果每次写请求都更新一下缓存,那么性能损耗是非常大的。
比如现在数据库中 x = 1,此时我们有 10 个请求对其每次加一的操作。但是这期间并没有读操作进来,如果用了先更新数据库的办法,那么此时就会有10个请求对缓存进行更新,会有大量的冷数据产生。
至于「先更新缓存,后更新数据库」这种情况和上述问题的是一致的,我们就不在继续讨论。
不管是先修改缓存还是后修改缓存,这样不仅对缓存的利用率不高,还浪费了机器性能。所以此时我们需要考虑另外一种方案:删除缓存。
先删除缓存,后更新数据库
假设有两个线程:线程A(更新 x ),线程B(读取 x )。可能会发生如下场景:
线程 A 先删除缓存中的 x ,然后去数据库进行更新操作;
线程 B 此时来读取 x,发现数据不在缓存,查询数据库并补录到缓存中;
而此时线程 A 的事务还未提交。
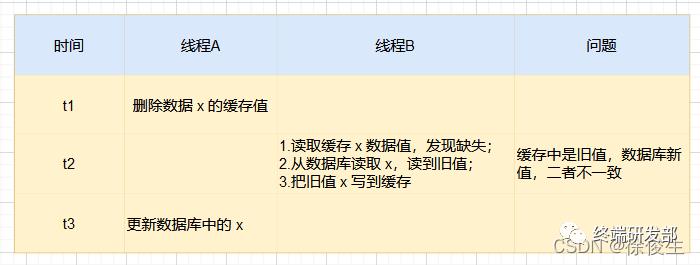
这个时候「先删除缓存,后更新数据库」仍会产生数据库与缓存的不一致问题。
先更新数据库,后删除缓存
我们还用两个线程:线程 A(更新 x ),线程B(读取 x )举例。
线程 A 要把数据 x 的值从 1更新为 2,首先先成功更新了数据库;
线程 B 需要读取 x 的值,但线程 A 还没有把新的值更新到缓存中;
这个时候线程 B 读到的还是旧数据 1;
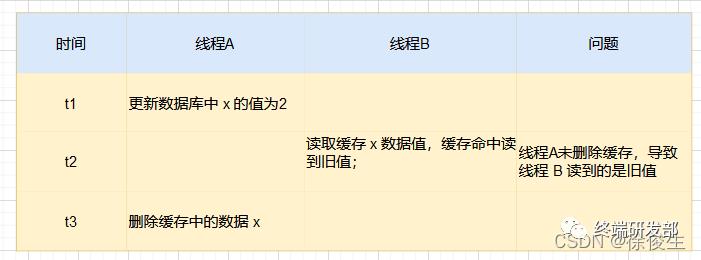
不过,这种情况发生的概率很小,线程 A 会很快删除缓存中值。这样一来,其他线程再次读取时,就会发生缓存缺失,进而从数据库中读取最新值。所以,这种情况对业务的影响较小。
由此,我们可以采用这种方案,来尽量避免数据库和缓存在并发情况下的一致性问题。
下面,我们继续分析「第二步操作失败」,我们该如何处理?
3、如何保证双写一致性
如何保证「第二步操作失败」的双写一致?
前面我们分析到,无论是「更新缓存」还是「删除缓存」,只要第二步发生失败,那么就会导致数据库和缓存不一致。
这里的关键在于如何保证第二步执行成功。
首先,介绍一种方法:「基于消息队列的重试机制」。
基于消息队列的重试机制
具体来说,就是把操作缓存,或者操作数据库的请求暂存到队列中。通过消费队列来重新处理这些请求。
流程如下:
请求 A 先对数据库进行更新操作;
在对 Redis 进行删除操作的时候发现删除失败;
此时将 对 Redis 的删除操作 作为消息体发送到消息队列中;
系统接收到消息队列发送的消息,再次对 Redis 进行删除操作。
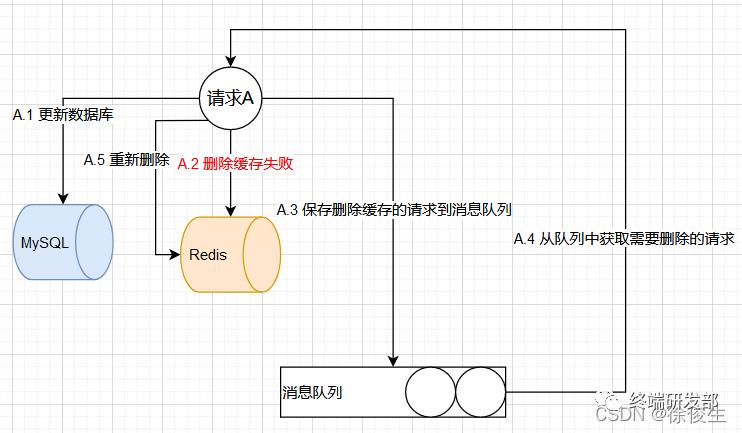 消息队列的两个特性满足了我们重试的需求:
消息队列的两个特性满足了我们重试的需求:
保证可靠性:写到队列中的消息,成功消费之前不会丢失(重启项目也不担心);
保证消息成功投递:下游从队列拉取消息,成功消费后才会删除消息,否则还会继续投递消息给消费者(符合我们重试的场景)。
引入队列带来的问题:
业务代码造成大量的侵入,同时增加了维护成本;
写队列时也会存在失败的问题。
对于这两个问题,第一个,我们在项目中一般都会用到消息队列,维护成本并没有新增很多。而且对于同时写队列和缓存都失败的概率还是很小的。
如果是实在不想在应用中使用队列重试的,目前也有比较流行的解决方案:订阅数据库变更日志,再操作缓存。我们对 MySQL 数据库进行更新操作后,在 binlog 日志中我们都能够找到相应的操作,那么我们可以订阅 MySQL 数据库的 binlog 日志对缓存进行操作。
订阅变更日志,目前也有了比较成熟的开源中间件,例如阿里的 canal。
大概流程如下:
系统修改数据库,生成 binlog 日志;
canal 订阅这个日志,获取具体的操作数据,投递给消息队列;
通过消息队列,删除缓存中的数据。
总结:推荐采用「先更新数据库,再删除缓存」方案,并配合「消息队列」或「订阅变更日志」的方式来保证数据库和缓存一致性。
4、如何保证并发场景下的数据一致性
我们前面分析,在并发场景下,「先删除缓存,再更新数据库」,由于存在网络延迟等,可能会存在数据不一致问题。我再把上面的图贴过来。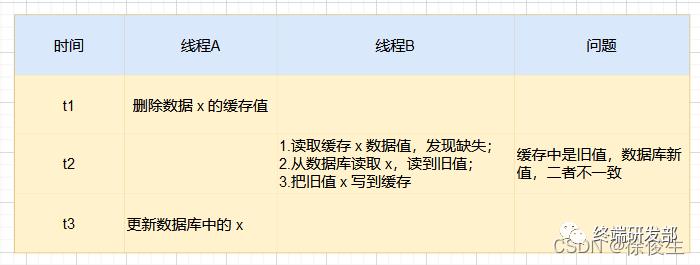
这个问题的核心在于:缓存都被种了「旧值」。
解决这种问题,最有效的办法就是,把缓存删掉。但是,不能立即删,而是需要「延迟删」,这就是业界给出的方案:缓存延迟双删策略。

在线程 A 更新完数据库值以后,我们可以让它先 sleep 一小段时间,再进行一次缓存删除操作。
之所以要加上 sleep 的这段时间,就是为了让线程 B 能够先从数据库读取数据,再把缺失的数据写入缓存,然后,线程 A 再进行删除。
但问题来了,这个「延迟删除」缓存,延迟时间到底设置要多久呢?
线程 A sleep 的时间,就需要大于线程 B 读取数据再写入缓存的时间。这需要在实际业务运行时估算。
除此之外,其实还有一种场景也会出现不一致问题:如果数据库采用读写分离架构,主从同步之间也会有时间差,也可能会导致不一致:
线程 A 更新主库 x = 2(原值 x = 1);
线程 A 删除缓存;
线程 B 查询缓存,没有命中,查询「从库」得到旧值(从库 x = 1);
从库「同步」完成(主从库 x = 2);
线程 B 将「旧值」写入缓存(x = 1)。
最终缓存中的 x 是旧值 1,而主从库最终值是新值 2。发生了数据不一致问题。
针对该问题的解决办法是,对于线程 B 的这种查询操作,可以强制将其指向主库进行查询,也可以使用上述「延迟删除」策略解决。
采用这种方案,也只是尽可能保证一致性而已,极端情况下,还是有可能发生不一致。
所以实际使用中,还是建议采用「先更新数据库,再删除缓存」的方案,同时,要尽可能地保证「主从复制」不要有太大延迟,降低出问题的概率。
5、总结
系统引入缓存提高应用性能问题
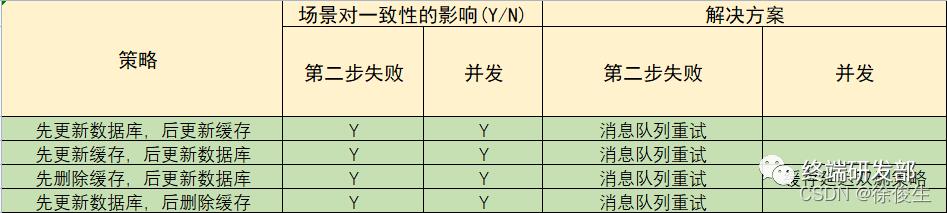
引入缓存后,需要考虑缓存和数据库双写一致性问题,可选的方案有:「更新数据库 + 更新缓存」、「更新数据库 + 删除缓存」
不管哪种方案,只要第二步操作失败,都无法保证数据的一致性,针对这类问题,可以通过消息队列重试解决
「更新数据库 + 更新缓存」方案,在「并发」场景下无法保证缓存和数据一致性,且存在「缓存资源浪费」和「机器性能浪费」的情况发生,一般不建议使用
在「更新数据库 + 删除缓存」的方案中,「先删除缓存,再更新数据库」在「并发」场景下依旧有数据不一致问题,解决方案是「延迟双删」,但这个延迟时间很难评估,所以推荐用「先更新数据库,再删除缓存」的方案
在「先更新数据库,再删除缓存」方案下,为了保证两步都成功执行,需配合「消息队列」或「订阅变更日志」的方案来做,本质是通过「重试」的方式保证数据一致性
在「先更新数据库,再删除缓存」方案下,「读写分离 + 主从库延迟」也会导致缓存和数据库不一致,缓解此问题的方案是「强制读主库」或者「延迟双删」,凭借经验发送「延迟消息」到队列中,延迟删除缓存,同时也要控制主从库延迟,尽可能降低不一致发生的概率。
作者:怀揣着梦想出发
链接:https://blog.csdn.net/m0_59347746/article/details/125866201

回复 【idea激活】即可获得idea的激活方式
回复 【Java】获取java相关的视频教程和资料
回复 【SpringCloud】获取SpringCloud相关多的学习资料
回复 【python】获取全套0基础Python知识手册
回复 【2020】获取2020java相关面试题教程
回复 【加群】即可加入终端研发部相关的技术交流群
阅读更多
用 Spring 的 BeanUtils 前,建议你先了解这几个坑!
在华为鸿蒙 OS 上尝鲜,我的第一个“hello world”,起飞!
一款vue编写的功能强大的swagger-ui,有点秀(附开源地址)
相信自己,没有做不到的,只有想不到的
在这里获得的不仅仅是技术!


喜欢就给个“在看”
以上是关于Redis常见面试题万字总结的主要内容,如果未能解决你的问题,请参考以下文章