Redis的基本使用(详解),Windows+Java
Posted HackShendi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis的基本使用(详解),Windows+Java相关的知识,希望对你有一定的参考价值。
Hi I’m Shendi
Redis
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
开源,NoSQL,缓存数据库,键值对结构,高性能,可持久化
Redis的连接,请求,读写,响应都是在一个线程内完成
对于使用Java的我,登陆信息、验证码等缓存信息存到缓存数据库简直不用太舒服(服务器更新就需要重启,缓存都会丢失或者需要自己格外处理)…
Windows安装Redis
Redis官方不提供windows版本,大概是因为windows商用比较少,懒得维护…
但至于到底为什么,可自行百度
官方虽然不提供,但还是有windows版本的Redis的
从Github下载:https://github.com/microsoftarchive/redis
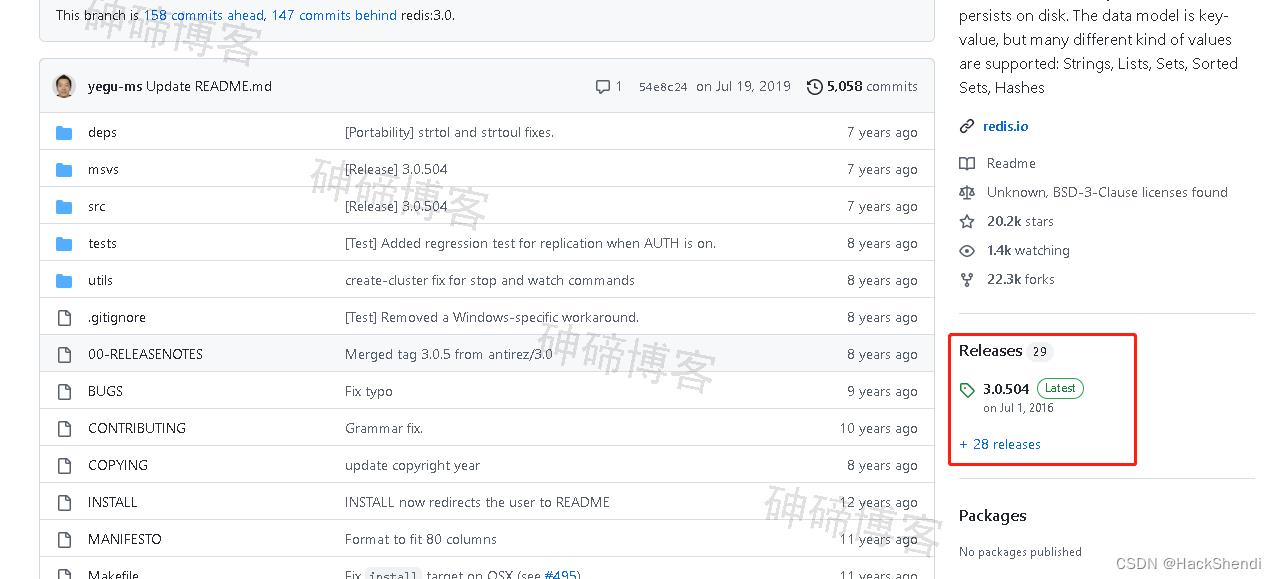
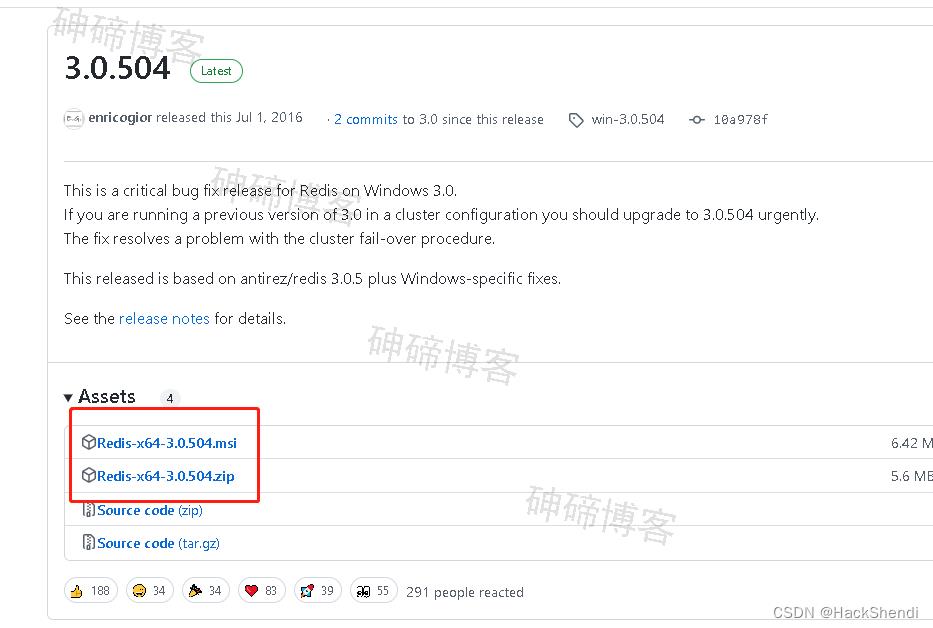
我下载的是zip格式的,解压后直接就可以用
打开cmd,进入 redis 目录,输入 redis-server 就启动redis了
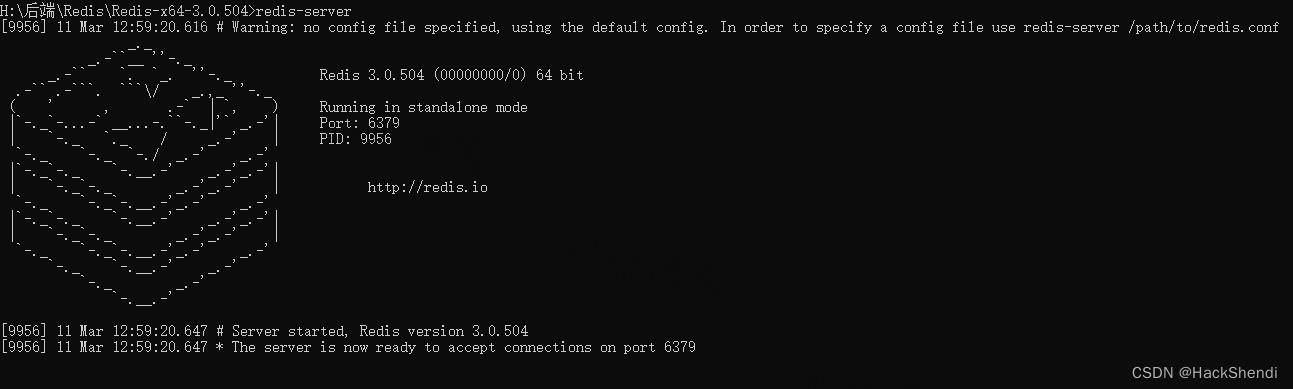
redis默认端口是6379,无法启动则检查端口是否被占用
使用配置文件启动
redis-server redis.windows.conf
注册为服务
如果有需要,可以将Redis注册成windows服务,这样就可以不用担心误关窗口导致Redis关闭
打开命令行,进入Redis文件夹,使用以下命令
# 全默认的注册服务
redis-server --service-install
# 使用指定配置文件注册服务,且记录日志等级
redis-server --service-install redis.windows.conf --loglevel verbose
执行后注册成功显示如下

使用管理员权限打开命令行(快捷键 win-x + win-a)
执行 net start redis 命令启动redis,执行 net stop redis 停止redis
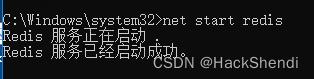
可以在服务中找到Redis服务

在redis文件夹下可执行的其他命令
#开启服务
redis-server --service-start
#关闭服务
redis-server --service-stop
#卸载服务
redis-server --service-uninstall
#服务重命名
redis-server --service-name 服务名称
使用
Redis的目录结构如下
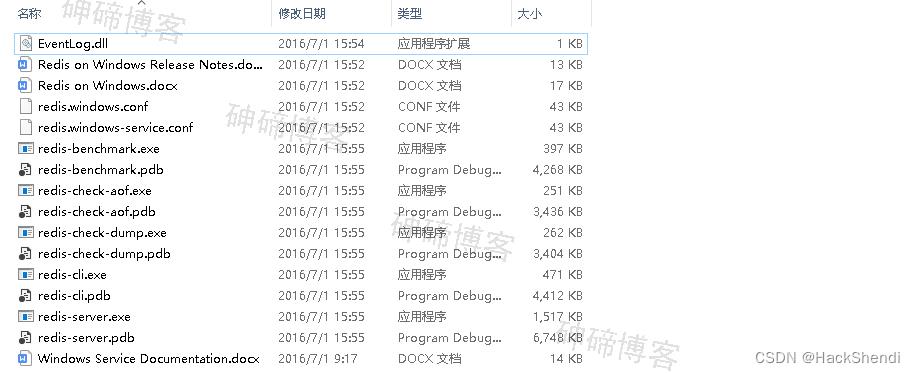
发现其中有一个 redis-cli.exe,可以理解为客户端,能进行Redis的操作
确保Redis 服务开启,默认端口6379
打开新的命令行,进入Redis目录,使用以下命令连接上Redis
redis-cli
如果Redis服务不在本地或者不是默认端口,则需要指定端口,使用以下命令
# -h指定地址, -p指定端口
redis-cli -h 127.0.0.1 -p 6379
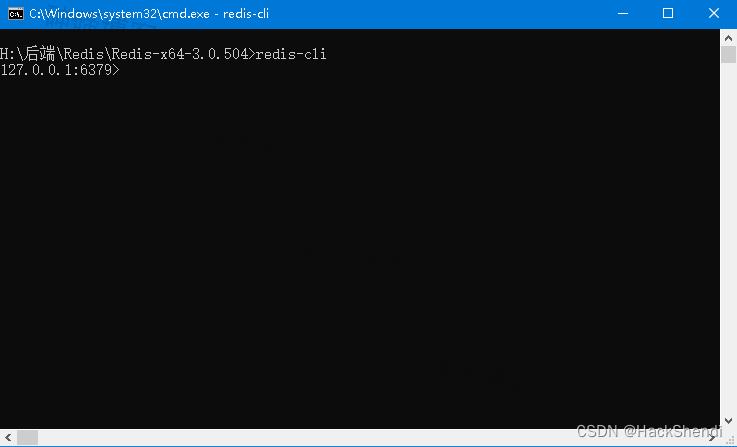
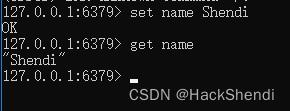
Redis是基于键值对的,使用以下命令来简单体验
# 设置键对应的值
set name Shendi
# 获取指定键对应的值
get name
# 删除指定键
del name
Redis配置
Redis 的配置文件位于 Redis 安装目录下,文件名为 redis.conf (Windows 名为 redis.windows.conf)
启动Redis,打开redis-cli,可以使用 config get * 查看所有配置内容
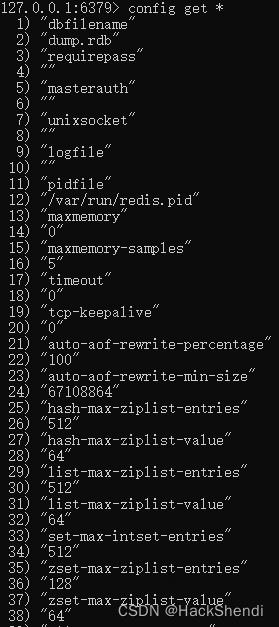
也可以通过 config get 名称 获取指定配置文件名称,例如获取端口
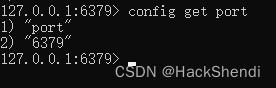
通过 config set name value 来修改配置
部分配置无法通过此方法修改,比如修改端口
例如设置客户端闲置多少秒后关闭(默认300秒)
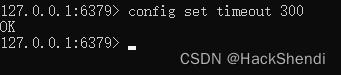
当然,也可以直接修改配置文件
配置文件大全
| 名称 | 默认值 | 描述 |
|---|---|---|
| daemonize | no | Redis 是否以守护进程的方式运行,使用 yes 启用守护进程(Windows 不支持守护线程的配置为 no ) |
| pidfile | /var/run/redis.pid | 当 Redis 以守护进程方式运行时,Redis 默认会把 pid 写入 /var/run/redis.pid 文件,可以通过 pidfile 指定 |
| port | 6379 | 端口号 |
| bind | 127.0.0.1 | 主机地址 |
| timeout | 0 | 当连接闲置多久后关闭,单位秒,如果指定为 0 ,表示关闭该功能 |
| loglevel | notice | 指定日志记录级别,Redis 总共支持四个级别:debug、verbose、notice、warning |
| logfile | 日志记录方式,默认为标准输出,如果配置 Redis 为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给 /dev/null | |
| databases | 16 | 数据库的数量,可以使用SELECT 命令在连接上指定数据库id |
| save | 默认有三个条件 save 900 1 save 300 10 save 60 10000 表示900秒内有1个更改或300秒内有10个更改或者60秒内有10000个更改时同步到数据文件 | 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合 |
| rdbcompression | yes | 指定存储至本地数据库时是否压缩数据,yes/no,Redis 采用 LZF 压缩,如果为了节省 CPU 时间,可以关闭该选项,但会导致数据库文件变的巨大 |
| dbfilename | dump.rdb | 本地数据库文件名 |
| dir | ./ | 本地数据库存放目录 |
| slaveof | 设置当本机为 slave 服务时,设置 master 服务的 IP 地址及端口,在 Redis 启动时,它会自动从 master 进行数据同步 | |
| masterauth | 当 master 服务设置了密码保护时,slave 服务连接 master 的密码 | |
| requirepass | 无密码 | 设置 Redis 密码,如果配置了密码,客户端在连接后 需要通过执行 AUTH 密码 才能使用 |
| maxclients | 10000 | 设置同一时间最大客户端连接数,Redis 可以同时打开的客户端连接数为 Redis 进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当连接数到达限制时,Redis 会关闭新的连接并向客户端返回 max number of clients reached 错误信息 |
| maxmemory | 0 | 指定 Redis 最大内存限制,Redis 在启动时会把数据加载到内存中,达到最大内存后,Redis 会先尝试清除已到期或即将到期的 Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis 新的 vm 机制,会把 Key 存放内存,Value 会存放在 swap 区 为0则不做限制,单位字节,以下书写方式均可以 1024、1024KB、1024MB、1GB |
| appendonly | no | 是否在每次更新操作后进行日志记录,Redis 在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis 本身同步数据文件是按上面 save 条件来同步的,所以有的数据会在一段时间内只存在于内存中。yes/no |
| appendfilename | appendonly.aof | 指定更新日志文件名 |
| appendfsync | everysec | 指定更新日志条件 no(根据操作系统,Linux默认30秒) always(总是写入磁盘,最多就丢一条数据,慢,但安全) everysec(折中方案,每秒写入磁盘,最多丢失一秒的数据) |
| vm-enabled | no | 是否启用虚拟内存机制,默认值为 no |
| vm-swap-file | /tmp/redis.swap | 虚拟内存文件路径,不可多个 Redis 实例共享 |
| vm-max-memory | 0 | 将所有大于 vm-max-memory 的数据存入虚拟内存,无论 vm-max-memory 设置多小,所有索引数据都是内存存储的(Redis 的索引数据 就是 keys),也就是说,当 vm-max-memory 设置为 0 的时候,其实是所有 value 都存在于磁盘 |
| vm-page-size | 32 | Redis swap 文件分成了很多的 page,一个对象可以保存在多个 page 上面,但一个 page 上不能被多个对象共享,vm-page-size 是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page 大小最好设置为 32 或者 64bytes;如果存储很大大对象,则可以使用更大的 page,如果不确定,就使用默认值 |
| vm-pages | 134217728 | 设置 swap 文件中的 page 数量,由于页表(一种表示页面空闲或使用的 bitmap)是在放在内存中的,,在磁盘上每 8 个 pages 将消耗 1byte 的内存 |
| vm-max-threads | 4 | 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4 |
| glueoutputbuf | yes | 设置在向客户端应答时,是否把较小的包合并为一个包发送 |
通用命令
| 名称 | 描述 | 示例 |
|---|---|---|
| keys | 获取符合要求的所有key,生产环境一般不使用 | keys * |
| dbsize | 获取当前键值对的数量 | dbsize |
| exists | 是否存在指定key | exists name |
| del | 删除指定key | del name |
| type | 获取key的类型 | type name |
| rename | 给key重命名 | rename name newName |
| expire | 为key设置过期时间,单位秒 | expire name 3 |
| ttl | 查看key的剩余时间,-1代表不过期,-2已过期或不存在 | ttl name |
| select | 选择使用哪个数据库,配置文件设置默认有16个数据库,从0开始,默认为0 | select 1 |
数据类型
| 类型 | 简介 | 特性 | 场景 |
|---|---|---|---|
| String(字符串) | 二进制安全 | 可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M | |
| Hash(字典) | 键值对集合,即编程语言中的Map类型 | 适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) | 存储、读取、修改用户属性 |
| List(列表) | 链表(双向链表) | 增删快,提供了操作某一段元素的API | 最新消息排行等功能(比如朋友圈的时间线) 消息队列 |
| Set(集合) | 哈希表实现,元素不重复 | 添加、删除,查找的复杂度都是O(1) 为集合提供了求交集、并集、差集等操作 | 共同好友 利用唯一性,统计访问网站的所有独立ip 好友推荐时,根据tag求交集,大于某个阈值就可以推荐 |
| Sorted Set(有序集合) | 将Set中的元素增加一个权重参数score,元素按score有序排列 | 数据插入集合时,已经进行天然排序 | 排行榜 带权重的消息队列 |
String
是Redis最基本的类型,最大能存储 512MB
| 名称 | 描述 | 示例 |
|---|---|---|
| get | 获取key的值 | get name |
| set | 设置键值对 | set name “shendi” |
| mget | 批量获取,原子性 | mget name web |
| mset | 批量设置,原子性 | mset name “Shendi” web “sdpro.top” |
| incr | 自增指定键对应的值,整数才有效 | incr age |
| incrby | 自增指定大小 | incrby age 10 |
| decr | 自减指定键对应的值,整数才有效 | decr age |
| decrby | 自减指定大小 | decrby age 10 |
| incrbyfloat | 增加指定浮点数 | incrbyfloat scope 66.5 |
| setnx | 存在则不设置 | setnx name “Shendi” |
| set…xx | 存在则设置 | set name “Shendi” xx |
| getset | 设置并返回旧值 | getset name “hackshendi” |
| append | 在值后面追加值 | append name “-ok” |
| strlen | 字符串长度 | strlen name |
| getrange | 指定范围的内容 | getrange name 0 10 |
| setrange | 设置指定范围的内容 | setrange name 0 “Shendi” |
| setex | 设置一个会过期的值,单位秒 | setex tmp 3 “tmp” |
| set…ex…nx | 不存在则设置值,且设置过期时间,分布式锁的实现方式 | set name “Shendi” ex 3 nx |
Hash
键值对的集合,可以理解为Map,每个 hash 可以存储 2^32 -1 键值对(40多亿)
| 名称 | 描述 | 示例 |
|---|---|---|
| hset | 设置字典内指定键的值 | hset info name “Shendi” |
| hsetnx | 当字典内指定键不存在时设置 | hsetnx info name “Shendi” |
| hmset | 批量设置 | hmset info name “Shendi” web “sdpro.top” |
| hget | 获取字典指定键的值 | hget info name |
| hmget | 批量获取 | hmget info name web |
| hgetall | 获取字典的所有键 | hgetall info |
| hdel | 删除字典内指定键 | hdel info web |
| hexists | 判断是否存在 | hexists info web |
| hlen | 获取字典内的存储数量 | hlen info |
| hvals | 返回字典的所有value | hvals info |
| hkeys | 返回字典的所有key | hkeys info |
| hincrby | 给指定值增加数,可以为负数 | hincrby info age 2 |
| hincrbyfloat | 给指定值增加指定的小数 | hincrbyfloat info scope 12.1 |
List
字符串列表,通过链表实现,增删快,查慢,可以理解为LinkedList
最多可存储 2^32 - 1 元素 (4294967295, 每个列表可存储40多亿)
| 名称 | 描述 | 示例 |
|---|---|---|
| lpush | 从左入栈,可批量 | lpush webs “sdpro.top” “shendi.blog.csdn.net” |
| rpush | 同上,从右入栈 | |
| lpop | 从左出栈 | lpop webs |
| rpop | 同上,从右出栈 | |
| lindex | 获取指定索引的元素,O(n) | lindex webs 1 |
| lrange | 获取指定范围的元素,O(n) | lrange webs 0 1(获取了两个元素) |
| linsert | 在指定元素的前面或者后面插入元素 | linsert webs before “shendi.blog.csdn.net” “tool.sdpro.top” linsert webs after “tool.sdpro.top” “sdpro.top/blog/” 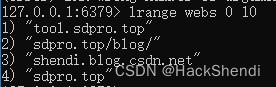 |
| lrem | 删除指定个数的值,0是删除全部 | lrem webs 1 “sdpro.top/blog/” |
| lset | 更新指定索引的值 | lset webs 1 “baidu.com” |
| llen | 列表的元素数量 | llen webs |
| blpop | 移出第一个元素,没有则阻塞指定时间直至超时或有元素为止,0为一直阻塞,单位秒 | blpop webs 10 |
| brpop | 同上,移出最后一个元素,可以用来实现生产者消费者 |
Set
字符串的无序不可重复集合,可以理解为HashSet
最大成员数 2^32 - 1 元素 (4294967295, 每个集合可存储40多亿个成员)
| 名称 | 描述 | 示例 |
|---|---|---|
| sadd | 添加元素 | sadd dbs “redis” |
| sismember | 判断指定元素是否在集合中 | sismember dbs “redis” |
| srandmember | 随机获取指定个数的元素 | srandmember dbs 2 |
| spop | 随机移除并返回集合中的一个元素 | spop dbs |
| smembers | 获取指定集合的所有元素,O(n) | smembers dbs |
| scard | 获取集合元素个数 | scard dbs |
| sinter | 获取集合之间的交集(多个集合相同部分) | sinter dbs1 dbs2 |
| sdiff | 获取集合之间的差集(多个集合不同的部分) | sdiff dbs1 dbs2 |
| sunion | 获取集合之间的并集(多个集合的所有元素) | sunion dbs1 dbs2 |
ZSet
与set类似,但是有序的,且每个元素都会关联一个double类型的分数,通过此分数来进行从小到大的排序,使用跳表实现
元素是唯一的,但分数是可以重复的
| 名称 | 描述 | 示例 |
|---|---|---|
| zadd | 添加元素(key score value) | zadd money 0 10 |
| zrem | 删除指定元素 | zrem money 10 |
| zscore | 获取指定元素的分数 | zscore money 10 |
| zincrby | 给指定元素增加指定的分数(key score value) | zincrby money 1 10 |
| zrange | 获取指定索引范围的元素,加上withscores则获取分数 | zrange money 0 5 zrange money 0 5 withscores |
| zrangebyscore | 同上,获取指定分数范围的元素 | |
| zcard | 获取集合长度 | zcard money |
Java使用Redis
引入依赖
需要引入 jedis.jar 包
可以在阿里云仓库下载
https://developer.aliyun.com/mvn/search
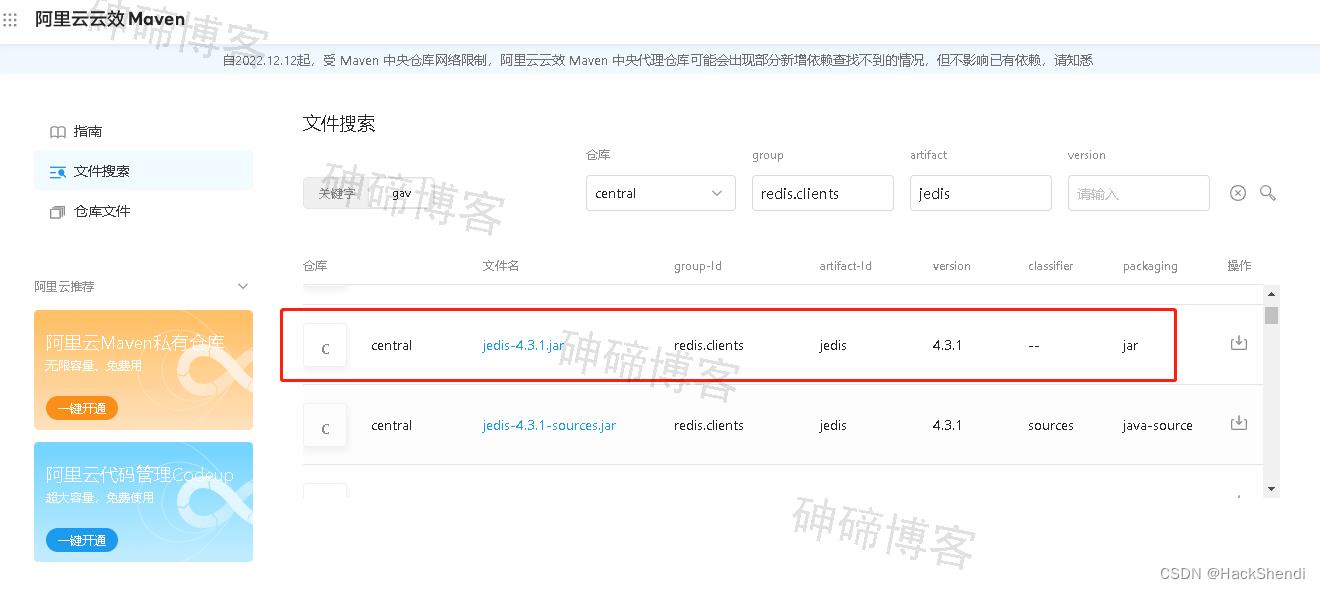
Maven则加入以下依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.3.1</version>
</dependency>
连接Redis服务器
通过 new Jedis 就可以连接Redis服务器
import redis.clients.jedis.Jedis;
public class Test
public static void main(String[] args)
// 连接Redis服务器
Jedis jedis = new Jedis("localhost", 6379);
// 指定密码,Redis没有设置密码则忽略
// jedis.auth("admin");
// 查看服务是否运行,响应pong
System.out.println(jedis.ping());
// 关闭连接
jedis.close();
简单使用
创建了连接后通过连接去执行相应的操作,在Java中,函数名称与命令名称基本上相似的,通过IDE的代码补全可以轻松的使用
例如选择第三个数据库,存入一个列表,然后查询输出结果
import java.util.List;
import redis.clients.jedis.Jedis;
public class Test
public static void main(String[] args)
String key = "webs";
Jedis jedis = new Jedis("localhost", 6379);
// 选择第三个数据库
jedis.select(2);
// 添加列表,返回添加成功的个数
long okNum = jedis.lpush(key, "sdpro.top", "tool.sdpro.top", "shendi.blog.csdn.net");
System.out.println("添加个数: " +okNum);
// 获取数量,再通过范围获取元素
long llen = jedis.llen(key);
// lrange起始和截止都是以0作为初始下标,例如llen返回3,但lrange(0,2)就可以获取所有数据
List<String> list = jedis.lrange(key, 0, llen);
System.out.println(list);
jedis.close();

END
以上是关于Redis的基本使用(详解),Windows+Java的主要内容,如果未能解决你的问题,请参考以下文章