jsoup抓取网页内容
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了jsoup抓取网页内容相关的知识,希望对你有一定的参考价值。
java项目有时候我们需要别人网页上的数据,怎么办?我们可以借助第三方架包jsou来实现,jsoup的中文文档,那怎么具体的实现呢?那就跟我一步一步来吧
最先肯定是要准备好这个第三方架包啦,下载地址,得到这个jar后在需要怎么做呢?别急,我们慢慢来
将jsoup.jar拷贝到项目的WebRoot—>WEB-INF—>lib文件夹
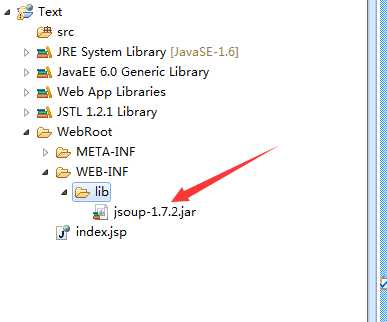 之后我们需要将这个架包引入一下哦!
之后我们需要将这个架包引入一下哦!
右键项目选择build path—>configure build path—>libraries—>add jars—>找到刚刚放入的目录下的jsoup
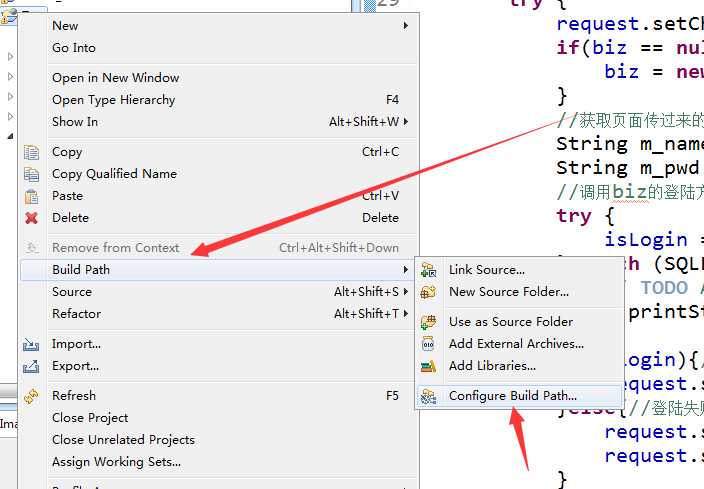
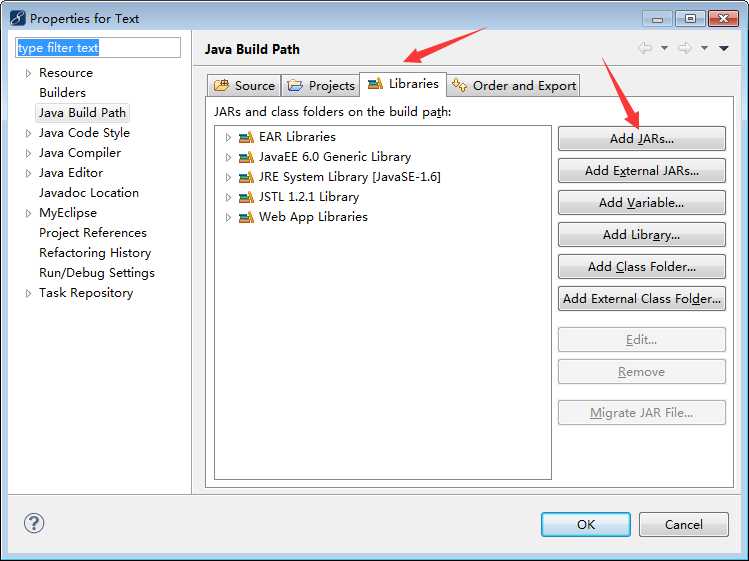
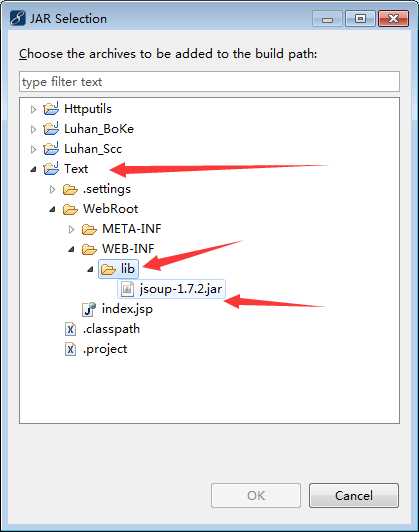
准备工作完成了,接下来就是我们的编码部分了,加油哦!
既然是抓取网页的内容那肯定首要有被抓的网站的地址,这里就以我其中一篇博客为准吧http://www.cnblogs.com/luhan/p/5953387.html
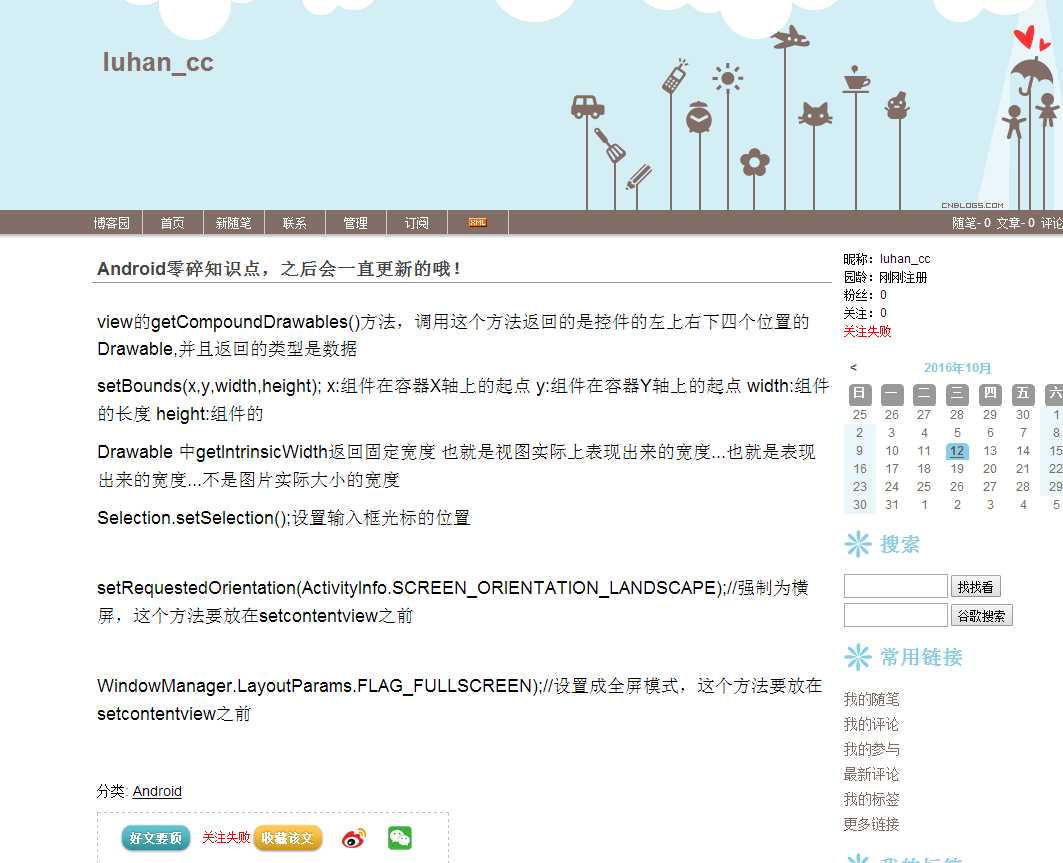 这个是我这篇文章的截图,比如我要抓取android零碎知识点,之后会一直更新哦这一段文字
这个是我这篇文章的截图,比如我要抓取android零碎知识点,之后会一直更新哦这一段文字
//获取整个网站的根节点,也就是html开头部分一直到结束,这里get方式,post方式是一样的
Document document = Jsoup.connect(url).get();
//输出一下我们会看到整个字符串如下
System.out.println(document);
这里只是截图了一部分
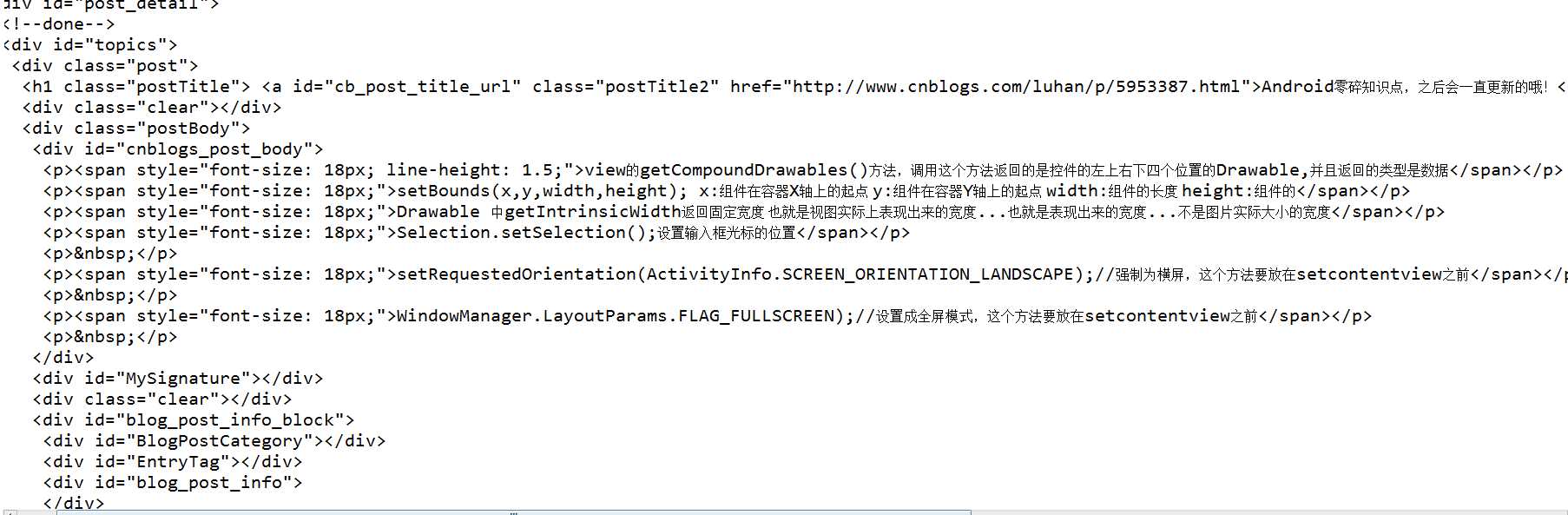
我们会看到我们需要抓的那一段文字在a标签包裹在,而且还有一个重要的就是id=cb_post_title_url,看过文档的应该知道,jsoup里面有getElementById这个方法,其实跟js里面获取元素是一样的,这里我们就可以用
getElementById的方法来获取这个a标签,获取到后我们就可以获取里面的内容了不是吗?而正好jsou也给我们提供了这样的一个方法text()方法,就是获取标签的文本内容,记得是文本而不是html形式的
如下我们通过getElementById这个方法来获取到我们想要的a标签
Element a = document.getElementById("cb_post_title_url");
这时候我们输出的内容如下
System.out.println(a.text());
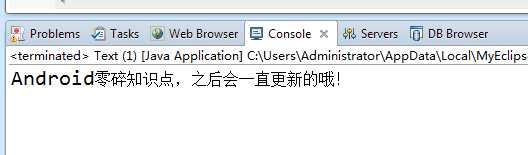
是不是得到了我们想要的了?当然啦,这只是jsoup的最简单的抓取而已,如果需要获取到的是个列表形式的啊,jsoup也一样可以的,我们都知道id是唯一的,不可以重复的,所以我们通过id获取到的只能是一行标签
但是一般列表比如ul-li我们就可以用getElementsByTag这个方法,通过标签名获取,然后再通过for循环的方式一个一个的去抓就完事啦,接下来附上代码
package com.luhan.text;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class Text {
private static final String url = "http://www.cnblogs.com/luhan/p/5953387.html";
public static void main(String[] args) {
try {
//获取整个网站的根节点,也就是html开头部分一直到结束
Document document = Jsoup.connect(url).post();
Element a = document.getElementById("cb_post_title_url");
System.out.println(a.text());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
jsoup里面的方法我就不一一介绍啦,不懂的小伙伴可以去看jsoup的中文文档哦,我就说说比较重要的方法吧
Jsoup.connect(url).post();获取网页的跟目录
getElementById通过id来获取
getElementsByClass通过class来获取
getElementsByTag通过标签名称来获取
text()获取标签的文本,再次强调一下是文本
html()获取标签里面的所有字符串包括html标签
attr(attributeKey)获取属性里面的值,参数是属性名称
注意
jsoup获取网页的根目录可能跟源代码不一样,所以需要小伙伴们细心哦
至此jsoup抓取网页的数据就告一段落啦,说的不太好,欢迎大家多指点,这个我用java控制台的,javaweb以及Android用法是一样的,先要导入框架,然后调用方法就ok了
以上是关于jsoup抓取网页内容的主要内容,如果未能解决你的问题,请参考以下文章