ZincSearch Java 客户端教程
Posted sp42a
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ZincSearch Java 客户端教程相关的知识,希望对你有一定的参考价值。
ZincSearch
Zinc 简单、强大,不了解的同学可以参见我之前的博客。今天我们这里谈谈 Java 环境如何集成 Zinc 客户端,跟如何使用的。
安装 Zinc
到 Github 的官方 Releases 下载:
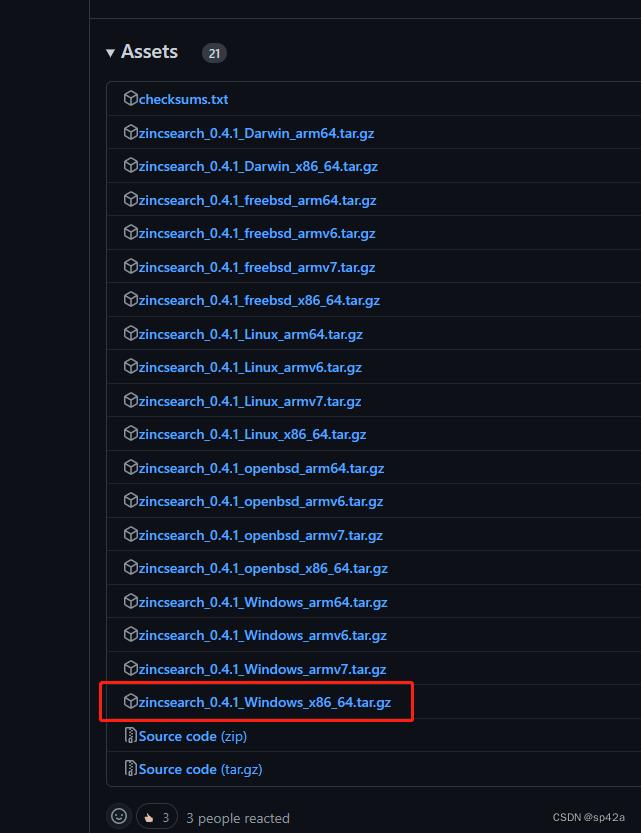
我的是 Windows 开发环境,下载 zincsearch_0.4.1_Windows_x86_64.tar.gz,解压两次。Zinc 是 Go 程序,编译后一个 .exe 文件,之前它就启动的搜索引擎以及一个 Web 服务。
第一次运行 Zinc 之前,你需要设置一下环境变量,用于设置账号跟密码。设置过一次之后,就不用再设置环境变量了。
set ZINC_FIRST_ADMIN_USER=admin
set ZINC_FIRST_ADMIN_PASSWORD=Complexpass#123
mkdir data
zinc.exe

注意 cmd 应该在管理员的权限下执行。
成功启动后,在浏览器访问 http://localhost:4080,登录后如下图所示。

Zinc 搜索概念入门
Zinc 中的 document 文档概念,对应就是数据库中的“实体”。下面我们一律称之实体。所谓搜索数据库,实质就是冗余你 DBMS 的一份数据,你 mysql/Oracle/SQLServer 有什么数据要搜索的,就怼到 Zinc 中去。自然,有了数据冗余就要涉及一致性的问题,或者说是同步的问题。当然我们采取的策略是,当业务层或者 ORM 层 CRUD 数据的时候,也同步地操作一次 Zinc 数据,通过这个客户端来完成,不用考虑额外的同步工作。
这里所谓同步的工作无非多一次的 CRUD 工作。我们来看看这个客户端能怎么完成 CRUD 的。
建立索引 index
在真正进入 SDK 之前,先说说 Zinc 的 index 概念。
Zinc 的 index,类似于数据库中的表(Table),所以建立索引也类似于我们数据库的建表(CREATE TABLE)操作,一样有名称、类型(type)等设置,当然结合搜索引擎的特性还有 index、sortable、aggregatable 等相关特性的设置字段。
Zinc 没有 SQL 这样的 DSL 操作语句,一切都是通过 HTTP 与 JSON 来交互操作。典型的一个索引定义如下 JSON Key/Value,首先有名称 name;还有设置参数 settings,不填则默认;最重要的,mappings 里面定义了每个 properties ,它相当于数据库的列定义(Column):
"name": "web",
"storage_type": "disk",
"settings": ,
"mappings":
"properties":
"@timestamp":
"type": "date",
"index": true,
"store": false,
"sortable": true,
"aggregatable": true,
"highlightable": false,
"term_positions": false
,
"_id":
"type": "keyword",
"index": true,
"store": false,
"sortable": true,
"aggregatable": true,
"highlightable": false,
"term_positions": false
,
"content":
"type": "text",
"index": true,
"store": true,
"sortable": false,
"aggregatable": true,
"highlightable": true,
"term_positions": true
,
"title":
"type": "text",
"index": true,
"store": true,
"sortable": false,
"aggregatable": false,
"highlightable": true,
"term_positions": true
建立索引是使用 Zinc 的第一步。所谓建立索引,就是将上述 JSON POST 到 Zinc 的 API 接口中去。你用 Postman/curl 等工具固然可以,用 SDK/客户端也可以。但我更推荐用服务自带的 Web UI 去创建。


当前非常抱歉的是,我们的 Java SDK 暂时未对接 index 接口。故看官您还需自己到 Web UI 去创建 index。
使用 Java SDK
要求 Java1.8+。
Maven 依赖
请通过 Maven 引入本客户端。
<dependency>
<groupId>com.ajaxjs</groupId>
<artifactId>aj-zincsearch-sdk</artifactId>
<version>1.0</version>
</dependency>
我们的这个客户端很少依赖,除了自己写的一个工具库之外,还依赖 spring-core 的一些工具方法。注意这是 spring 的 core,不是全集,并不大。一般大家都用 Spring,所以默认选用了。如果你实在不想依赖 Spring,请告诉我,——去掉 Spring core 依赖问题也不大。
初始化设置
DocumentService docService = new DocumentService();
docService.setApi("http://localhost:4080");
docService.setUser("admin");
docService.setPassword("Complexpass#123");
源码
我们肯定是开源的,源码在:https://gitee.com/sp42_admin/ajaxjs/tree/master/aj-zincsearch-sdk。如有不足,请多提宝贵意见!
增删改查 CRUD
创建实体
创建实体,那么实体究竟是什么呢?——对于我们这个客户端而言,允许接收两种格式的实体:Map 和 Java Bean。这是 Java 编程里面最为常见的数据格式,分别对应的类型是:Map<String, Object> 和 Object。最后实体均化作 JSON 传给 Zinc。
Zinc 创建一个实体,可以指定 id 的,也可以不指定,让 Zinc 生成随机字符作为 id。一般情况我们都是指定好实体的 id。这样有个好处便是,Zinc 搜索出来结果了,可以通过 id 返回给你的业务系统,晓得你系统内的所对应的实体如何。
一般而言,一个 index 里面的 id 应该保持唯一不重复,否则重复 id 都不晓得该取哪个结果。
我们客户端封装好的创建实体方法如下几个,位于 DocumentService 类。
/**
* 创建实体
*
* @param target index 名称
* @param bean Java 实体 Bean
* @return
*/
public ZincResponse create(String target, Object bean);
/**
* 创建实体
*
* @param target index 名称
* @param doc Java 实体 Map
* @return
*/
public ZincResponse create(String target, Map<String, Object> doc);
/**
* 创建实体
*
* @param target index 名称
* @param bean Java 实体 Bean
* @param id 实体 id
* @return
*/
public ZincResponse create(String target, Object bean, Serializable id);
/**
* 创建实体
*
* @param target index 名称
* @param bean Java 实体 Map
* @param id 实体 id
* @return
*/
public ZincResponse create(String target, Map<String, Object> doc, Serializable id);
调用例子如下:
Map<String, Object> doc = ListUtils.hashMap("title", "AIGC带你看来自“天涯海角”的新种子");
doc.put("content", "央视新闻《开局之年“hui”蓝图》系列微视频,用AI视角,带您看两会。\\r\\n" + "\\r\\n"
+ "目前,中国的水果产量稳居世界第一,国人的“果盘子”琳琅满目,瓜果飘香。而作为全球第一的肉类生产和消费大国,近十多年来,全国居民牛羊肉消费量也持续提升。未来的水果产业和牛羊养殖业什么样?让我们跟随AIGC,感受从田间走到舌尖的“新科技”。");
ZincResponse resp =docService.create(target, doc);
assertNotNull(resp);
resp = docService.create(target, doc, 2l);
assertNotNull(resp);
返回结果
既然是 HTTP API 请求,自然就有响应。我们是怎么封装响应结果的呢?很简单,基础封装 Bean,然后具体结果还是放在一个 Map 里面,请见 ZincResponse 类结构:
/**
* Zinc API 返回的结果
*
* @author Frank Cheung sp42@qq.com
*
*/
@Data
public class ZincResponse
/**
* 正常返回结果的信息
*/
private String message;
/**
* 是否返回异常
*/
private Boolean hasError;
/**
* 异常信息
*/
private String errMsg;
/**
* 原始返回的 JSON
*/
private Map<String, Object> rawResult;
主要是调用 getHasError() 辨别成功与否;具体返回信息在 Map<String, Object> rawResult 里面,请用户针对具体的信息获取想要的内容,我们就不多封装了。
实体的更新
与创建不同,你必须指定实体之 id 来进行更新,——显然,如果没传,Zinc 哪知道修改哪个实体。
更新同样支持 Map<String, Object> 和 Java Bean 两种格式。
/**
* 更新实体
*
* @param target index 名称
* @param bean Java 实体 Bean
* @param id 实体 id
* @return
*/
public ZincResponse update(String target, Object bean, Serializable id);
/**
* 更新实体
*
* @param target index 名称
* @param bean Java 实体 Map
* @param id 实体 id
* @return
*/
public ZincResponse update(String target, Map<String, Object> doc, Serializable id);
调用例子如下:
Map<String, Object> doc = ListUtils.hashMap("title", "222222222AIGC带你看来自“天涯海角”的新种子");
doc.put("content", "央视新闻《开局之年“hui”蓝图》系列微视频,用AI视角,带您看两会。\\r\\n" + "\\r\\n"
+ "目前,中国的水果产量稳居世界第一,国人的“果盘子”琳琅满目,瓜果飘香。而作为全球第一的肉类生产和消费大国,近十多年来,全国居民牛羊肉消费量也持续提升。未来的水果产业和牛羊养殖业什么样?让我们跟随AIGC,感受从田间走到舌尖的“新科技”。");
docService.update(target, doc, 2l);
注意,每次更新必须是“全量更新”,例如一则新闻有 title 和 content 字段,用户只修改了标题 title,content 内容不变,你还是要传 content 字段的。否则 Zinc 只保存了 title,content 就丢失了。所以你必须在 JSON 提交完整的实体数据,在 Update 的操作中。
实体的删除
删除很简单。
/**
* 删除实体
*
* @param target index 名称
* @param id 实体 id
* @return
*/
public ZincResponse delete(String target, Serializable id) ;
调用例子如下:
ZincResponse resp = docService.delete(target, 2l);
assertNotNull(resp);
批量操作
TODO
搜索 Search
TODO
以上是关于ZincSearch Java 客户端教程的主要内容,如果未能解决你的问题,请参考以下文章