Spark 初识
Posted 在奋斗的大道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark 初识相关的知识,希望对你有一定的参考价值。
1、Scala 安装
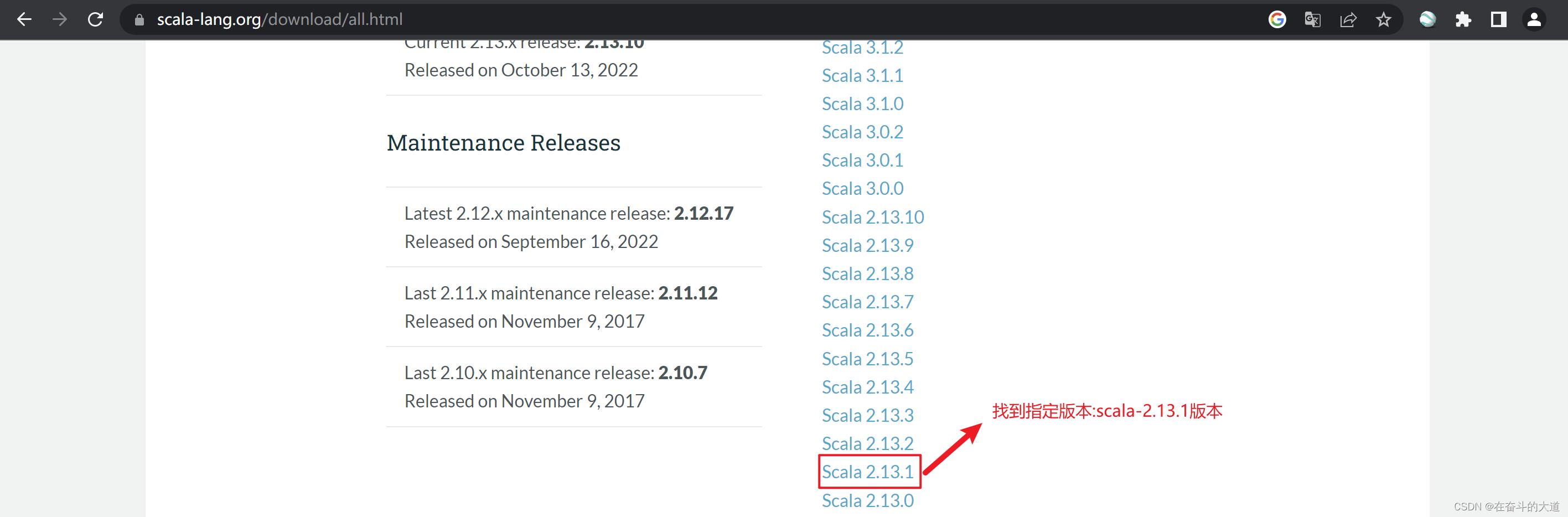
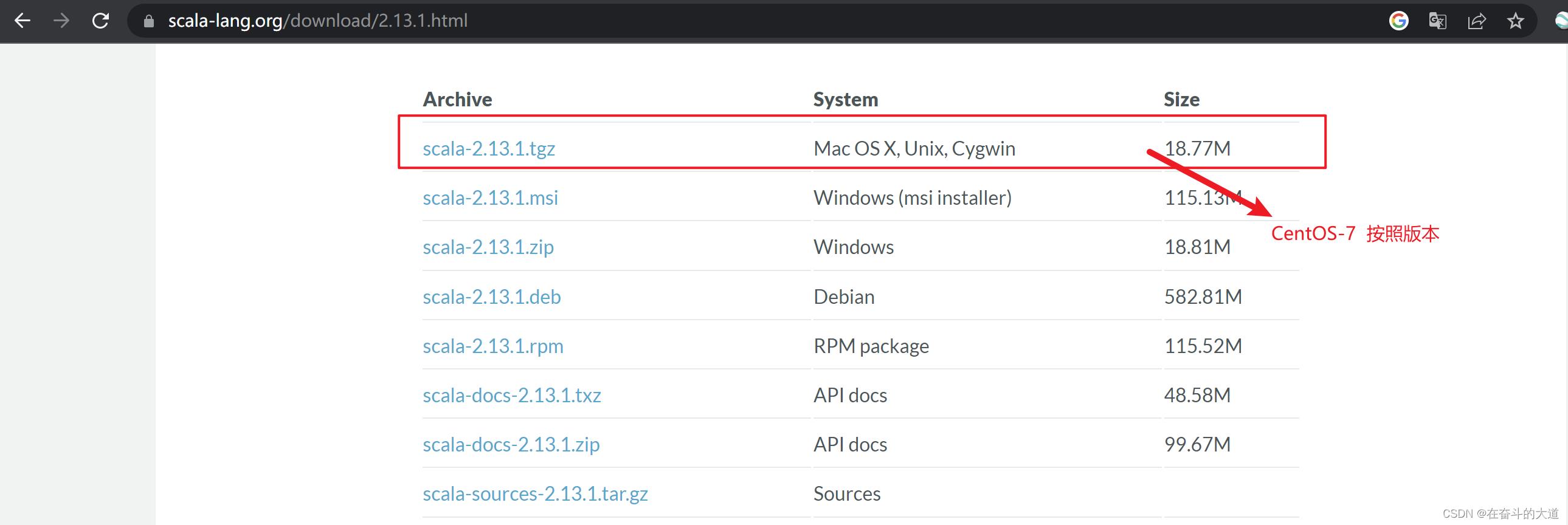
第一步:进入Scala 官网,下载scala-2.13.1 版本。Scala 官网地址
第二步:通过Mobaxtrem 将scala-2.13.1.tgz 上传CentOS-7 服务器的/usr/local 目录。
第三步:CentOS-7 安装Scala 环境,请执行如下步骤:
[root@Hadoop3-master local]# tar -zxvf scala-2.13.1.tgz
scala-2.13.1/
scala-2.13.1/lib/
scala-2.13.1/lib/scala-compiler.jar
scala-2.13.1/lib/scalap-2.13.1.jar
解压中******
[root@Hadoop3-master local]# mv scala-2.13.1 scala
[root@Hadoop3-master local]# vi /etc/profile
[root@Hadoop3-master local]# source /etc/profile编辑/etc/profile 文件,添加如下配置:
# /etc/profile
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export SQOOP_HOME=/usr/local/sqoop
export HBASE_HOME=/usr/local/hbase
export HIVE_HOME=/usr/local/hive
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SQOOP_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin:$SCALA_HOME/bin第四步:验证Scala 环境是否安装成功,执行如下指令:
[root@Hadoop3-master local]# scala -version
Scala code runner version 2.13.1 -- Copyright 2002-2019, LAMP/EPFL and Lightbend, Inc.2、Spark 伪分布式安装(单机安装)
通过Spark 官方网站下载Spark 发行包:spark-3.1.1-bin-without-hadoop.tgz并解压,然后修改环境变量和Spark配置文件即可。
第一步:进入Spark 官网,下载spark-3.1.1-bin-without-hadoop.tgz 版本。Spark 全版本下载
以为我CentOS-7 环境已经安装Hadoop3.1.X 环境,所以我下载的Spark 版本为:spark-3.1.1-bin-without-hadoop.tgz
第二步:通过Mobaxtrem 将spark-3.1.1-bin-without-hadoop.tgz 上传CentOS-7 服务器的/usr/local 目录。
第三步:CentOS-7 安装Spark 环境,请执行如下步骤:
[root@Hadoop3-master local]# tar -zxvf spark-3.1.1-bin-without-hadoop.tgz
spark-3.1.1-bin-without-hadoop/
spark-3.1.1-bin-without-hadoop/NOTICE
spark-3.1.1-bin-without-hadoop/kubernetes/
解压中******
[root@Hadoop3-master local]# mv spark-3.1.1-bin-without-hadoop spark
[root@Hadoop3-master local]# vi /etc/profile
[root@Hadoop3-master local]# vi /etc/profile
[root@Hadoop3-master local]# source /etc/profile编辑/etc/profile 文件,添加如下配置:
[root@Hadoop3-master bin]# cat /etc/profile
# /etc/profile
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export SQOOP_HOME=/usr/local/sqoop
export HBASE_HOME=/usr/local/hbase
export HIVE_HOME=/usr/local/hive
export SCALA_HOME=/usr/local/scala
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SQOOP_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin第四步:Spark 参数配置
切换至Spark 配置文件目录,复制模板并修改其中的配置文件workers、spark-env.sh、spark-default.conf
[root@Hadoop3-master conf]# cp workers.template workers
[root@Hadoop3-master conf]# vi workers修改workers,追加本机的主机名:Hadoop3-master
[root@Hadoop3-master conf]# cat workers
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# A Spark Worker will be started on each of the machines listed below.
localhost
Hadoop3-master[root@Hadoop3-master conf]# cp spark-env.sh.template spark-env.sh
[root@Hadoop3-master conf]# vi spark-env.sh修改spark-env.sh,追加如下内容:
export JAVA_HOME=/usr/local/jdk
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_HOST=Hadoop3-master
export SPARK_PID_DIR=/usr/local/spark/data/pid
export SPARK_LOCAL_DIRS=/usr/local/spark/data/spark_shuffle
export SPARK_EXECUTOR_MEMORY=1G
export SPARK_WORKER_MEMORY=4G修改spark-default.conf, 追加如下内容:
spark.master spark://Hadoop3-master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://Hadoop3-master:9000/eventLog
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 1g温馨提示:在配置文件中使用hdfs://Hadoop3-master:9000/eventLog 用来存放日志,我们需要手动创建这个目录。请执行如下指令:
[root@Hadoop3-master conf]# hadoop fs -mkdir /eventLog
[root@Hadoop3-master conf]# hadoop fs -ls /
Found 5 items
drwxr-xr-x - root supergroup 0 2023-03-02 11:25 /bhase
drwxr-xr-x - root supergroup 0 2023-03-04 22:57 /eventLog
drwxr-xr-x - root supergroup 0 2023-03-01 17:17 /sqoop
drwx-wx-wx - root supergroup 0 2023-03-02 17:26 /tmp
drwxr-xr-x - root supergroup 0 2023-03-01 14:51 /user第五步:测试Spark
在启动Spark之前,必须先启动Hadoop
[root@Hadoop3-master sbin]# start-all.sh
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Starting namenodes on [Hadoop3-master]
上一次登录:六 3月 4 21:37:57 CST 2023pts/0 上
Hadoop3-master: namenode is running as process 3189. Stop it first and ensure /tmp/hadoop-root-namenode.pid file is empty before retry.
Starting datanodes
上一次登录:六 3月 4 23:06:20 CST 2023pts/0 上
localhost: datanode is running as process 3347. Stop it first and ensure /tmp/hadoop-root-datanode.pid file is empty before retry.
Starting secondary namenodes [Hadoop3-master]
上一次登录:六 3月 4 23:06:21 CST 2023pts/0 上
Hadoop3-master: secondarynamenode is running as process 3604. Stop it first and ensure /tmp/hadoop-root-secondarynamenode.pid file is empty before retry.
Starting resourcemanager
上一次登录:六 3月 4 23:06:22 CST 2023pts/0 上
resourcemanager is running as process 3964. Stop it first and ensure /tmp/hadoop-root-resourcemanager.pid file is empty before retry.
Starting nodemanagers
上一次登录:六 3月 4 23:06:26 CST 2023pts/0 上
[root@Hadoop3-master sbin]# jps
3347 DataNode
3604 SecondaryNameNode
3189 NameNode
36280 Jps
3964 ResourceManager切换至Spark安装目录下的/sbin, 执行start-all.sh
[root@Hadoop3-master sbin]# /usr/local/spark/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-Hadoop3-master.out
localhost: mv: 无法获取"/usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-Hadoop3-master.out.1" 的文件状态(stat): 没有那个文件或目录
localhost: mv: 无法将"/usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-Hadoop3-master.out" 移动至"/usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-Hadoop3-master.out.1": 没有那个文件或目录
Hadoop3-master: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-Hadoop3-master.out
localhost: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-Hadoop3-master.out
[root@Hadoop3-master sbin]# jps
69760 Worker
68867 ResourceManager
56695 Worker
68118 NameNode
70024 Jps
68269 DataNode
69549 Master
68540 SecondaryNameNode
69759 Worker通过Jps指令,可以看到Spark 创建的Master 和Worker 两个进程。
温馨提示:由于本文Hadoop和Spark 都是使用伪分布式部署,且都配置全局环境变量(/etc/profile),因此在执行相关指令时,建议使用全路径。
第六步:验证Spark
验证Spark程序在本机是否安装成功,有以下几种方式:
执行Spark-Shell 指令
切换至Spark 安装目录下的/bin, 执行打开Shell 窗口指令.
[root@Hadoop3-master bin]# spark-shell
23/03/05 00:02:00 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://Hadoop3-master:4040
Spark context available as 'sc' (master = spark://Hadoop3-master:7077, app id = app-20230305000209-0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\\ \\/ _ \\/ _ `/ __/ '_/
/___/ .__/\\_,_/_/ /_/\\_\\ version 3.1.1
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_333)
Type in expressions to have them evaluated.
Type :help for more information.
scala> exit
<console>:24: error: not found: value exit
exit
^
scala> exit;
<console>:24: error: not found: value exit
exit;
^
scala> quit
<console>:24: error: not found: value quit
quit
^
scala> :quit运行Spark自带示例程序
切换至Spark 安装目录下/bin 目录,执行自带示例程序SparkPi
[root@Hadoop3-master bin]# run-example SparkPi
23/03/05 00:01:23 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
23/03/05 00:01:26 WARN SparkContext: The jar file:/usr/local/spark/examples/jars/spark-examples_2.12-3.1.1.jar has been added already. Overwriting of added jars is not supported in the current version.
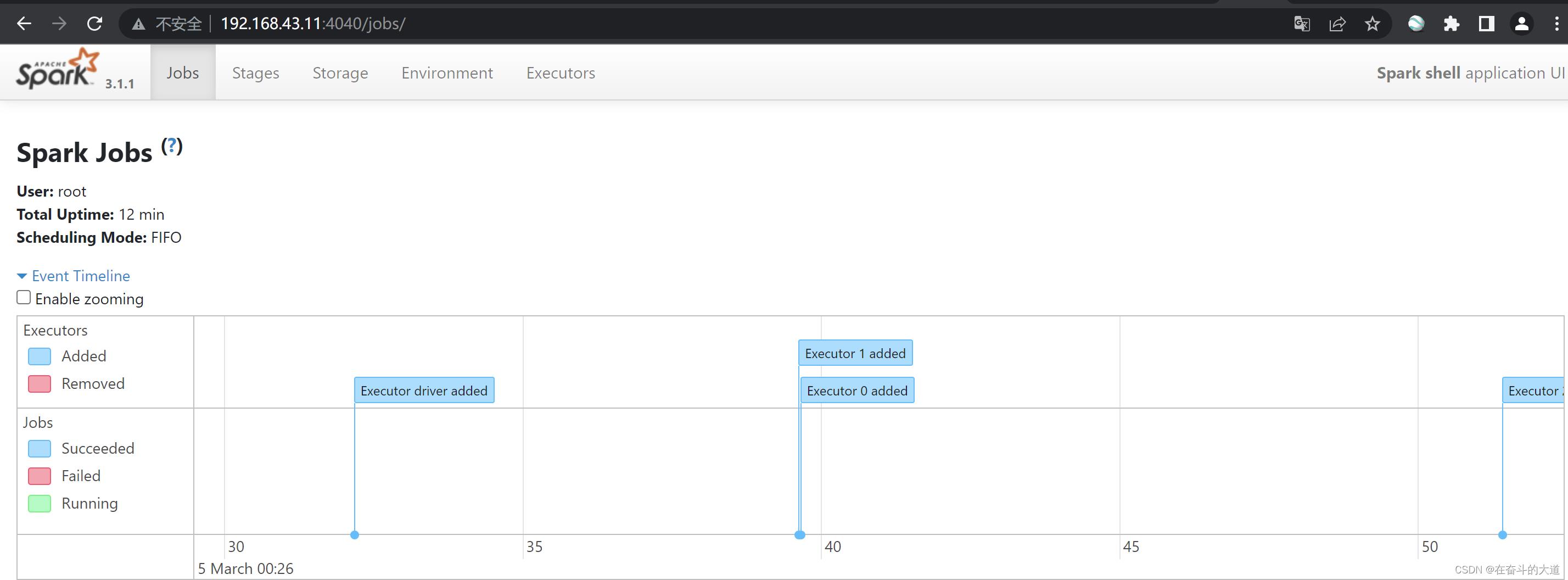
Pi is roughly 3.1422557112785565查看Spark管理控制台
浏览器打开:http://192.168.43.11:4040/8080 查看Spark运行状态信息。
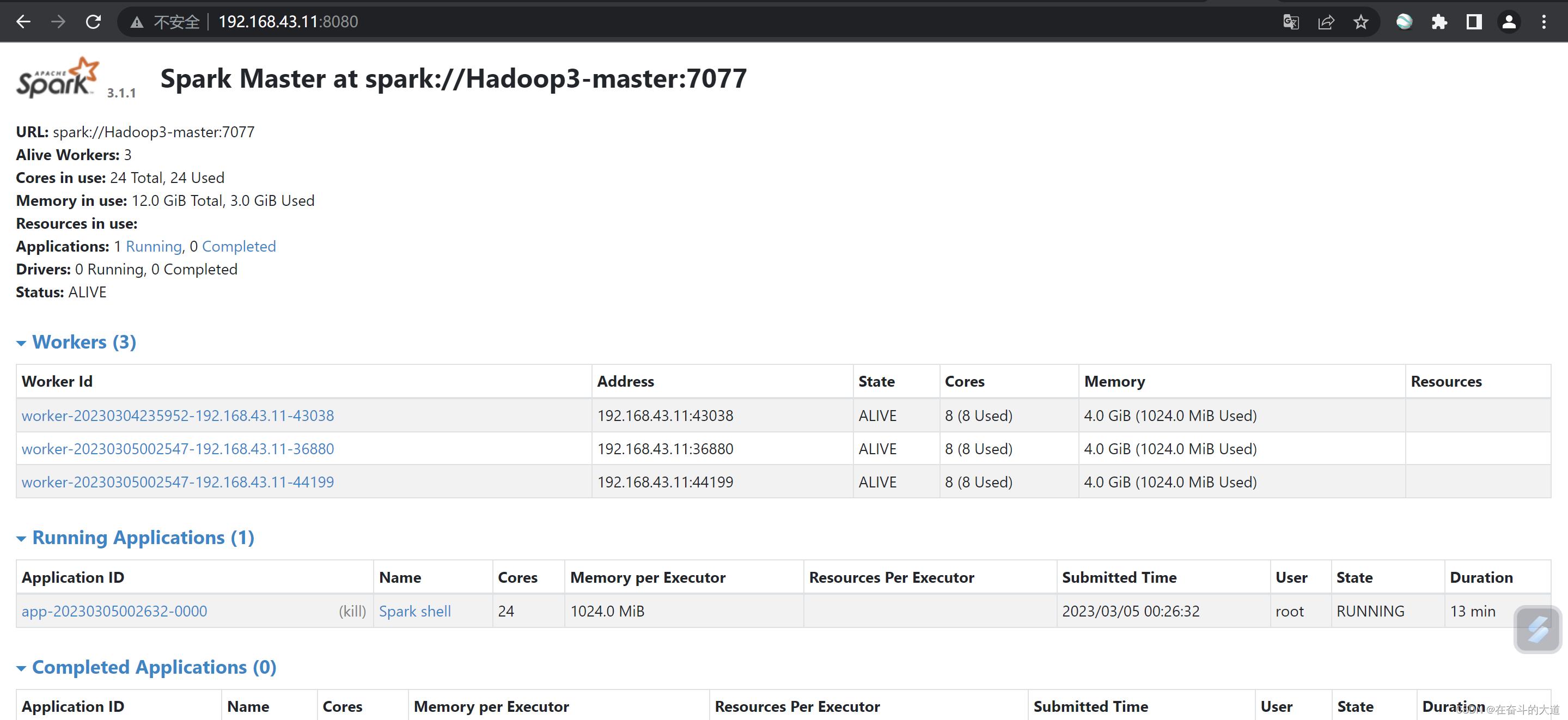
3、Spark 安装遇到问题总结
问题一:执行spark-shell 打开窗口执行,提示如下错误信息
[root@Hadoop3-master jars]# spark-shell
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/fs/FSDataInputStream
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
at java.lang.Class.privateGetMethodRecursive(Class.java:3048)
at java.lang.Class.getMethod0(Class.java:3018)
at java.lang.Class.getMethod(Class.java:1784)
at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:650)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:632)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FSDataInputStream
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)造成此问题原因:Spark从1.4版本以后,Spark编译时都没有将hadoop的classpath编译进去,所以必须在spark-env.sh中指定hadoop中的所有jar包
解决方法:在spark-env.sh中添加一条配置信息,将hadoop的classpath引入, $HADOOP_HOME根据自己的情况而定,直接写绝对路径也行,我这里选择直接写成全路径方式;
export export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)问题二:执行Spark-shell 打开窗口命令,提示如下错误信息
[root@Hadoop3-master conf]# spark-shell
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/log4j/spi/Filter
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)
at java.lang.Class.privateGetMethodRecursive(Class.java:3048)
at java.lang.Class.getMethod0(Class.java:3018)
at java.lang.Class.getMethod(Class.java:1784)
at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:650)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:632)
Caused by: java.lang.ClassNotFoundException: org.apache.log4j.spi.Filter
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
... 7 more造成此错误原因:缺失log4j-1.2.17.jar 包
解决办法:
从mavne resp 仓库下载log4j 最新jar 包log4j-1.2.17.jar 上传至/usr/local/spark/jars/ 目录。
知识拓展:hadoop、hive、spark 对应版本关系
以上是关于Spark 初识的主要内容,如果未能解决你的问题,请参考以下文章