万亿模型训练需 1.7TB 存储,腾讯混元如何突破 GPU 极限?
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了万亿模型训练需 1.7TB 存储,腾讯混元如何突破 GPU 极限?相关的知识,希望对你有一定的参考价值。

Gartner 将生成式 AI 列为 2022 年五大影响力技术之一,MIT 科技评论也将 AI 合成数据列为 2022 年十大突破性技术之一,甚至将 Generative AI 称为是 AI 领域过去十年最具前景的进展。未来,兼具大模型和多模态模型的 AIGC 模型有望成为新的技术平台。
近来,腾讯发布的混元 AI 万亿大模型登顶权威中文测评基准 CLUE 榜并超越人类水平。
混元 AI 大模型采用腾讯太极机器学习平台自研的训练框架 AngelPTM,相比业界主流的解决方案,太极 AngelPTM 单机可容纳的模型可达 55B,20 个节点(A100-40Gx8)可容纳万亿规模模型,节省 45% 训练资源,并在此基础上训练速度提升 1 倍!

GPU受限下,以最小成本训练大模型
Transformer 模型凭借出色的表达能力在多个人工智能领域均取得了巨大成功,如计算机视觉、自然语言处理、语音处理等。与此同时,随着训练数据量和模型容量的增加,可以持续提高模型的泛化能力和通用能力,研究大模型成为近两年的趋势。如下图1所示,伴随着近年来 NLP 预训练模型规模化发展,已经从亿级发展到了万亿级参数规模。具体来说,2018 年 BERT 模型最大参数量为 340M,2019 年 GPT-2 为十亿级参数的模型。2020 年发布的百亿级规模有 T5 和 T-NLG,以及千亿参数规模的 GPT-3。在 2021 年末,Google 发布了 Switch Transformer,首次将模型规模提升至万亿。
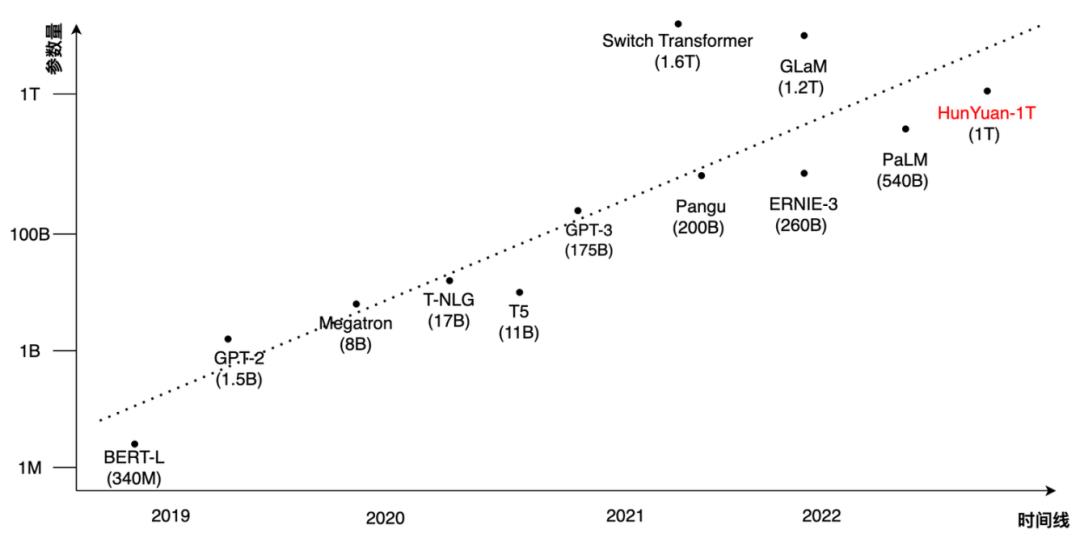
图1 近几年 NLP 预训练模型规模的发展
然而,GPU 硬件发展的速度难以满足 Transformer 模型规模发展的需求。如图 2 所示,近四年来,模型参数量增长了十万倍,但 GPU 的显存仅增长了 4 倍。举例来说,万亿模型的模型训练仅参数和优化器状态便需要 1.7TB 以上的存储空间,至少需要 425 张 A100(40G),这还不包括训练过程中产生的激活值所需的存储。在这样的背景下,大模型训练不仅受限于海量的算力, 更受限于巨大的存储需求。

图2 GPU 显存增长趋势
为了以最小的成本训练大模型,我们基于 ZERO 策略,将模型的参数、梯度、优化器状态以模型并行的方式切分到所有 GPU,并自研 ZeRO-Cache 框架把内存作为二级存储 offload 参数、梯度、优化器状态到 CPU 内存,同时也支持把 SSD 作为第三级存储。而为了最大化和最优化的利用内存和显存进行模型状态的缓存,我们引入了显存内存统一存储视角,将存储容量的上界由内存扩容到内存+显存总和。同时,将多流异步化做到极致,在 GPU 计算的同时进行数据 IO 和 NCCL 通信,使用异构流水线均衡设备间的负载,最大化提升整个系统的吞吐。ZeRO-Cache 将 GPU 显存、CPU 内存统一视角管理,减少了冗余存储和内存碎片,增加了内存的利用率,将机器的存储空间“压榨”到了极致。

大模型训练优化遇到的挑战
多级存储访存带宽不一致
在大模型训练中,激活值、梯度位于 GPU 中,模型的FP16/FP32参数、优化器状态位于 CPU 中甚至位于 SSD 中,模型的前向和反向在 GPU 上进行运算,而参数更新在 CPU 做运算,这就需要频繁地进行内存显存以及 SSD 之间的访问,而 GPU 访问显存带宽为 1555GB/s,显存与内存数据互传的带宽为 32GB/s,CPU 访问内存、显存和 SSD 的带宽分别为 200GB/s、32GB/s、3.5GB/s,如图 3 所示多级存储访问带宽的不一致很容易导致硬件资源闲置,如何减少硬件资源的闲置时间是大模型训练优化的一大挑战。为此,我们通过多流异步以及 PipelineOptimizer 来提高硬件利用率。
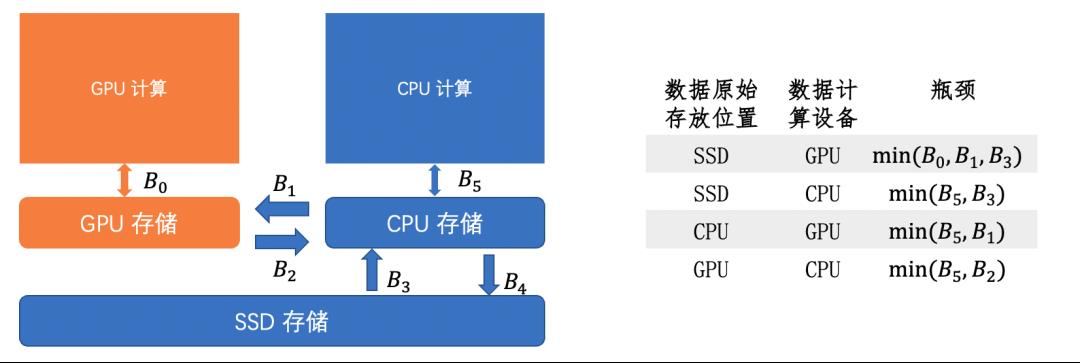
图3 多级访存带宽不一致
模型状态冗余存储
大模型训练时的模型状态存储于 CPU 中,在模型训练过程中会不断拷贝到 GPU,这就导致模型状态同时存储于 CPU 和 GPU 中,这种冗余存储是对本就捉肘见襟的单机存储空间的一种严重浪费,如何彻底去除这种冗余,对低成本训练大模型至关重要。因此,我们秉承彻底去冗余的思想引入统一视角存储管理,从根本上解决模型状态的冗余存储。
内存碎片过多
大模型拥有巨量的模型状态,单张 GPU 卡不能完全放置所有模型状态,在训练过程中模型状态被顺序在 CPU 和 GPU 之间交换,这种交换导致 GPU 显存的频繁分配和释放,此外大模型训练过程中海量的 Activation 也需要频繁分配和释放显存,显存频繁分配和释放会产生大量的显存碎片,过多的显存碎片会导致 Memory Allocator 分配效率低下以及显存浪费。为此,我们设计开发了 Contiguous Memory 显存管理器来更细致地管理显存,从而减少显存碎片率。
带宽利用率低
在大模型分布式训练中,多机之间会进行参数 all_gather、梯度 reduce_scatter 以及 MOE 层 AlltoAll 三类通信,单机内部存在模型状态 H2D、D2H 以及 SSD 和 Host 之间的数据传输。通信以及数据传输带宽利用率低是训练框架在分布式训练中最常见的问题,合并通信以及合并数据传输作为解决带宽问题的首选手段在大模型训练中同样适用,合并通信和合并数据传输预示着需要更多的内存和显存缓存,这更加剧了大模型训练的存储压力。为了平衡高带宽利用率以及低缓存,ZeRO-Cache 在多流异步的基础上,引入 chunk 机制管理模型状态通信以及数据传输,在梯度后处理时引入多buffer机制重复利用已分配缓存。

太极 AngelPTM 概览
太极 AngelPTM 的设计目标是依托太极机器学习平台,为 NLP、CV 和多模态、AICG 等多类预训练任务提供一站式服务。其主要由高性能训练框架、通用加速组件和基础模型仓库组成,如图 4 所示。

图4 AngelPTM
高性能训练框架:包含大模型训练框架 ZeRO-Cache,高性能 MOE 组件,以及 3D 并行和自动流水并行策略。
通用加速组件:包含可减少显存并提高精度的异构 Adafactor 优化器,可稳定 MOE 半精度训练 loss 的 Z_loss 组件,选择性重计算组件和降低通信代价的 PowerSGD 组件。
基础模型仓库:
包含 T5、BERT、GPT 以及 Transformer 等基础模型。
ZeRO-Cache 优化策略
ZeRO-Cache 是一款超大规模模型训练的利器,如图5所示,其通过统一视角去管理内存和显存,在去除模型状态冗余的同时扩大单个机器的可用存储空间上限,通过 Contiguous Memory 显存管理器管理模型参数的显存分配/释放进而减少显存碎片,通过多流均衡各个硬件资源的负载,通过引入 SSD 进一步扩展单机模型容量。
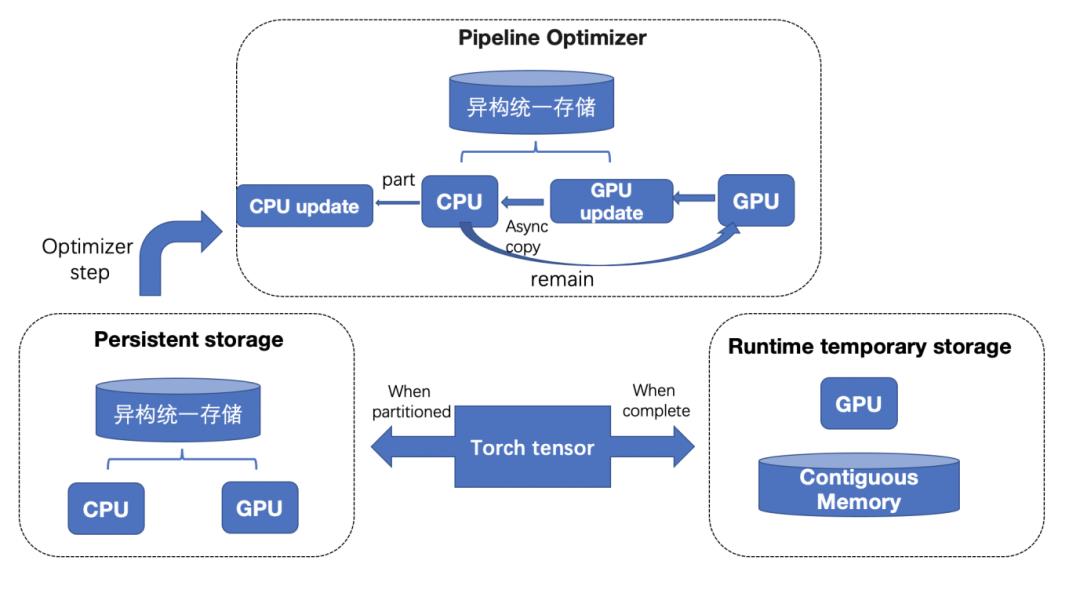
图5 ZeRO-Cache概图
统一视角存储管理
大模型训练时模型状态都位于 CPU 内存中,在训练时会拷贝到 GPU 显存,这就导致模型状态的冗余存储(CPU 和 GPU 同时存在一份),此外大模型的训练中会用到大量的 pin memory,pin memory 的使用会提升性能,但同时也会导致物理内存的大量浪费,如何科学合理的使用 pin memory 是 ZeRO-Cache 着重要解决的问题。
本着极致化去冗余的理念,我们引入了 chunk 对内存和显存进行管理,保证所有模型状态只存储一份,通常模型会存储在内存 or 显存上,ZeRO-Cache 引入异构统一存储,采用内存和显存共同作为存储空间,击破了异构存储的壁垒,极大扩充了模型存储可用空间,如图 6 左图所示。
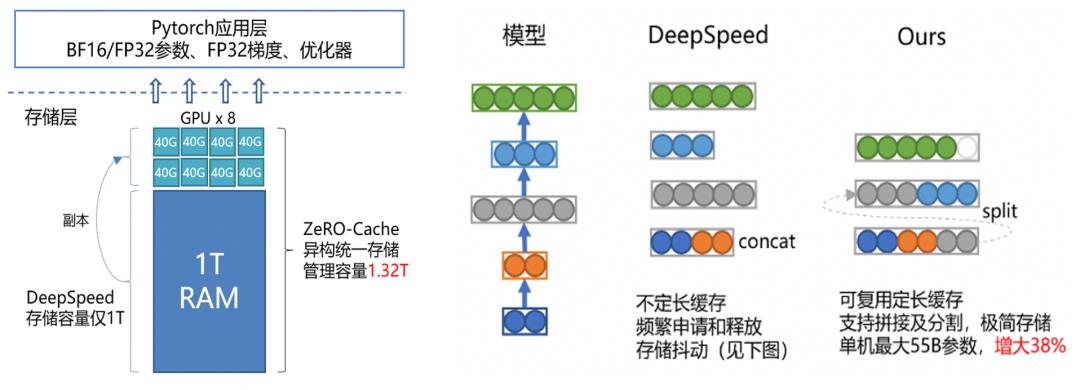
图6 统一视觉存储管理
在 CPU 时原生 Tensor 的底层存储机制对于实际占用的内存空间利用率极不稳定,对此问题我们实现了 Tensor 底层分片存储的机制,在极大的扩展了单机可用存储空间的同时,避免了不必要的 pin memory 存储浪费,使得单机可负载的模型上限获得了极大提升,如图6右图所示。
ZeRO-Cache 显存管理器
PyTorch 自带的显存管理器可以 Cache 几乎所有显存进行二次快速分配,在显存压力不大的情况下这种显存分配方式可以达到性能最优,但是对于超大规模参数的模型,导致显存压力剧增,且由于参数梯度频繁的显存分配导致显存碎片明显增多,PyTorch Allocator 尝试分配显存失败的次数增加,导致训练性能急剧下降。
为此,ZeRO-Cache 引入了一个 Contiguous Memory 显存管理器,如图 7 所示,其在 PyTorch Allocator 之上进行二次显存分配管理,模型训练过程中参数需要的显存的分配和释放都由 Contiguous Memory 统一管理,在实际的大模型的训练中其相比不使用 Contiguous Memory 显存分配效率以及碎片有显著提升,模型训练速度有质的飞越。

图7 ZeRO-Cache 显存管理器
PipelineOptimizer
ZeRO-Infinity 利用 GPU 或者 CPU 更新模型的参数,特别是针对大模型,只可以通过 CPU 来更新参数,由于 CPU 更新参数的速度相比 GPU 更新参数有数十倍的差距,且参数更新几乎可以占到整个模型训练时间的一半,在 CPU 更新参数的时候 GPU 空闲且显存闲置,造成资源的极大浪费。
如图 8 所示,ZeRO-Cache 会在模型参数算出梯度之后开始 Cache 模型的优化器状态到 GPU 显存,并在参数更新的时候异步 Host 和 Device 之间的模型状态数据传输,同时支持 CPU 和 GPU 同时更新参数。ZeRO-Cache pipeline 了模型状态 H2D、参数更新、模型状态 D2H,最大化地利用硬件资源,避免硬件资源闲置。
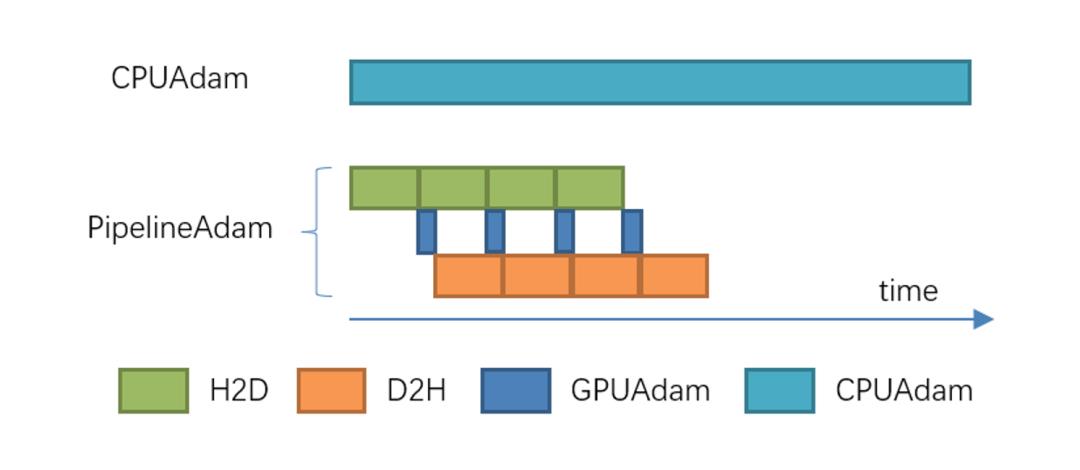
图8 PipelineAdam
此外,我们自研了异构 Adafactor 优化器,如图 9 所示,支持 CPU 和 GPU 同时进行参数的更新,其可以减少 33% 的模型状态存储空间,同时可提高模型训练精度。
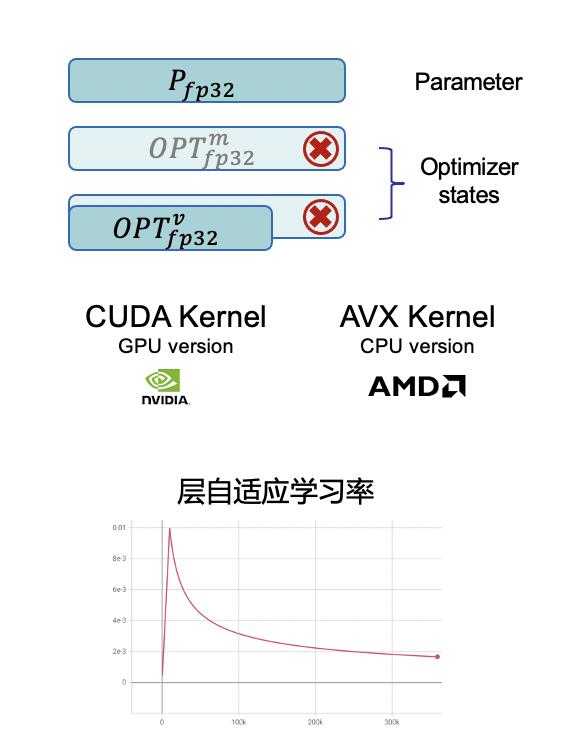
图9 异构Adafactor
多流异步化
大模型训练过程中有大量的计算和通信,包括 GPU 计算、H2D 和 D2H 单机通信、NCCL 多机通信等,涉及的硬件有 GPU、CPU、PCIE 等。如图 10 所示,ZeRO-Cache 为了最大化地利用硬件,多流异步化 GPU 计算、H2D 和D2H 单机通信、NCCL 多机通信,参数预取采用用时同步机制,梯度后处理采用多 buffer 机制,优化器状态拷贝采用多流机制。

图10 多流计算通信
ZeRO-Cache SSD 框架
为了更加低成本地扩展模型参数,如图11所示,ZeRO-Cache 进一步引入了 SSD 作为三级存储,针对 GPU 高计算吞吐、高通信带宽和 SSD 低 PCIE 带宽之间的 GAP,ZeRO-Cache 放置所有 fp16 参数和梯度到内存中,让 foward 和 backward 的计算不受 SSD 低带宽影响,同时通过对优化器状态做半精度压缩来缓解 SSD 读写对性能的影响。
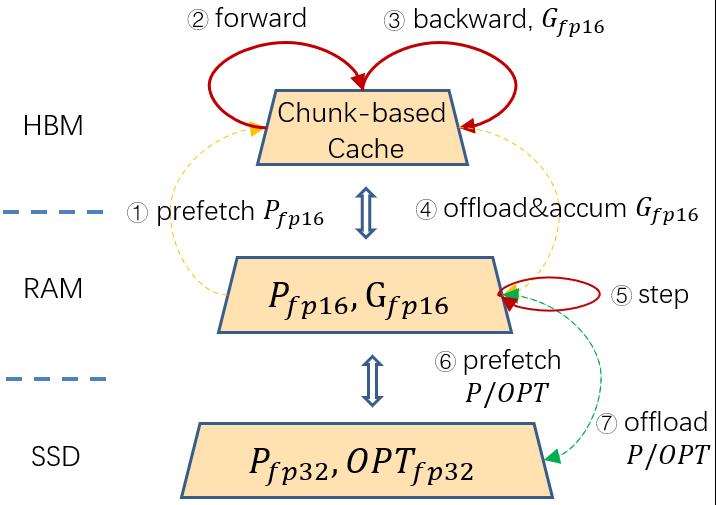
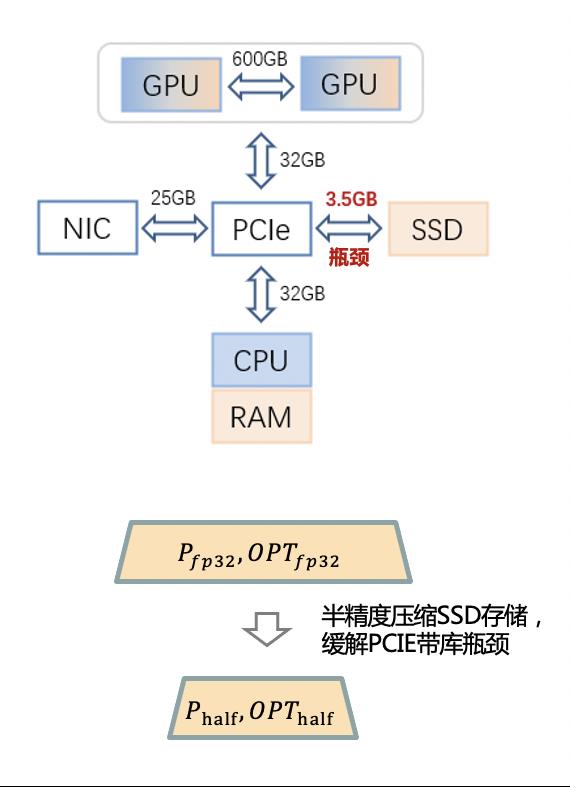
图11 ZeRO-Cache SSD框架
实验效果
本小节基于 A100 GPU(40G) 集群和 1.6T ETH RDMA 网络环境对比评测目前业界比较主流的几个大模型框架在不同规模模型上的性能表现,包括首次提出 ZeRO 理念的框架A、可高效扩展并训练 Transformer 模型的框架 B,以及集成高效并行化技术的框架 C。秉承降低成本、提高训练效率的理念,我们以最少的资源去呈现 ZeRO-Cache 的高性能和大模型能力,环境配置为 4 台 1T 内存,96 核 CPU 机器,每台机器有 8 张 A100 GPU(40G),模型具体配置如表1,测试均采用真实训练数据,序列长度为 512,主要对比测试 TFLOPs/s,具体性能数据如图 12 所示。
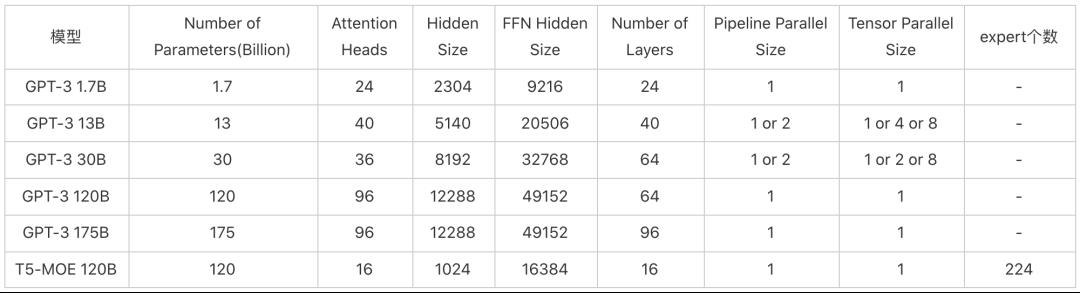
表1 模型配置
实验数据
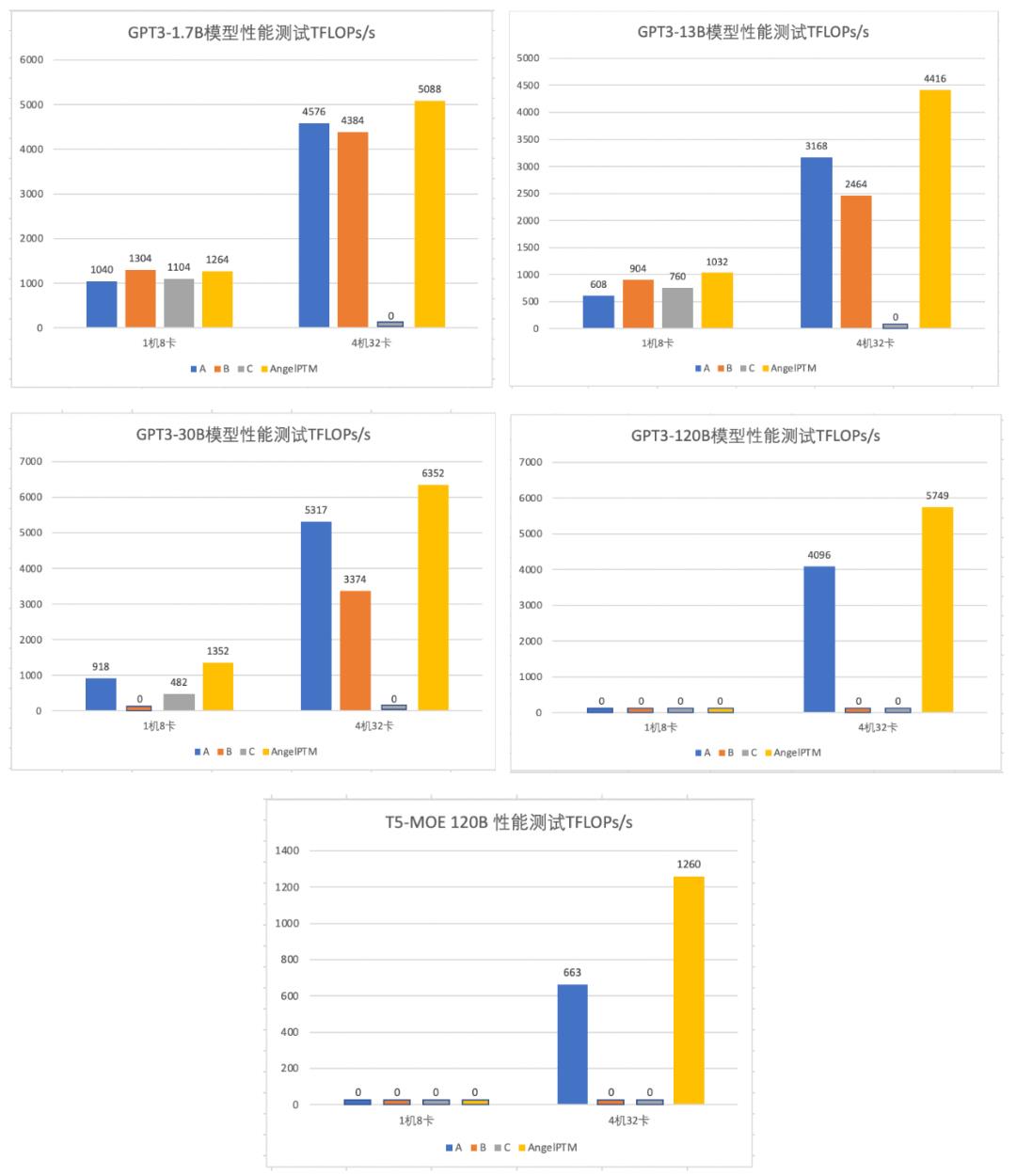
图12 各框架不同规模模型性能对比
图表说明:图中数值 0 表示该规模模型不能在当前资源下运行,而 C 框架因官方缺乏多机训练文档,多次测试失败,暂且以 0 表示其性能数据。各个框架的测试性能数据均以 Batch Size 打满 GPU 为准。
实验数据表明虽然在 1.7B 小模型上 ZeRO-Cache 单机略差于 B 框架(ZeRO-Cache 前向和反向计算中需要进行参数的预取,而 B 框架无需此操作),但是在其他规模模型上无论单机、多机性能均优于其他框架,我们以 13B 模型为例来说明各个框架对比A框架的性能提升,以 Tflops/s 进行计算,具体见表2。此外,在 GPT3-175B 大模型上,ZeRO-Cache 仅仅只需要 32 张卡便可进行模型的训练,而其他三个框架均无法在这么少的资源下进行训练。
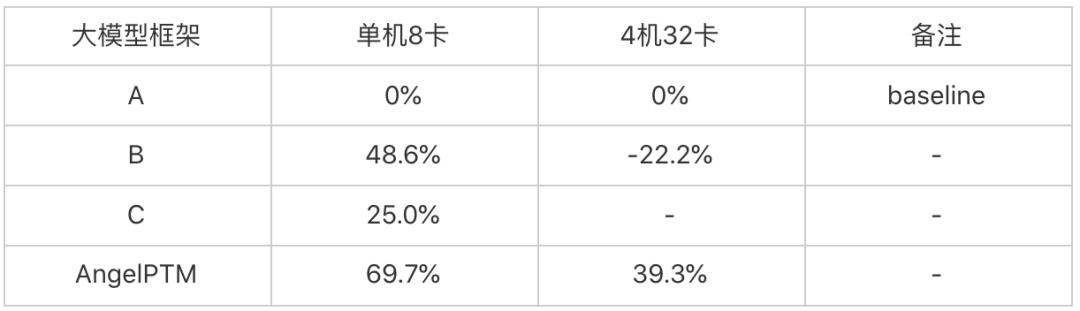
表2 13B模型各个框架性能对比

结语
AngelPTM 秉承降低成本提高训练效率的理念开发了 ZeRO-Cache 框架,通过高效利用硬件资源提高了单机模型上限和训练效率,相比业界其他大模型框架,ZeRO-Cache 可以用更少的资源训练更大的模型,在极致资源使用情况下取得更高的速度。
参考文献
[1] 腾讯发布万亿大模型训练方法:最快256卡1天训完万亿NLP大模型
[2] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding https://arxiv.org/abs/1810.04805
[3]Language Models are Unsupervised Multitask Learners https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
[4]Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer [1910.10683] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
[5]T-NLG Turing-NLG: A 17-billion-parameter language model by Microsoft - Microsoft Research
[6]Language Models are Few-Shot Learners [2005.14165] Language Models are Few-Shot Learners
[7]Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity https://arxiv.org/abs/2101.03961


☞没有这些,别妄谈做 ChatGPT 了
☞被“误解”的游戏开发者
☞刚自愿降薪 40% 的库克,要被“踢出”苹果董事会了?以上是关于万亿模型训练需 1.7TB 存储,腾讯混元如何突破 GPU 极限?的主要内容,如果未能解决你的问题,请参考以下文章