Stable Diffusion原理详解
Posted JarodYv
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Stable Diffusion原理详解相关的知识,希望对你有一定的参考价值。
Stable Diffusion原理详解
最近AI图像生成异常火爆,听说鹅厂都开始用AI图像生成做前期设定了,小厂更是直接用AI替代了原画师的岗位。这一张张丰富细腻、风格各异、以假乱真的AI生成图像,背后离不开Stable Diffusion算法。
Stable Diffusion是stability.ai开源的图像生成模型,可以说Stable Diffusion的发布将AI图像生成提高到了全新高度,其效果和影响不亚于Open AI发布ChatGPT。今天我们就一起学习一下Stable Diffusion的原理。

文章目录
图像生成的发展
在Stable Diffusion诞生之前,计算机视觉和机器学习方面最重要的突破是 GAN(Generative Adversarial Networks 生成对抗网络)。GAN让超越训练数据已有内容成为可能,从而打开了一个全新领域——现在称之为生成建模。
然而,在经历了一段蓬勃发展后,GAN开始暴露出一些瓶颈和弊病,大家倾注了很多心血努力解决对抗性方法所面临的一些瓶颈,但是鲜有突破,GAN由此进入平台期。GAN的主要问题在于:
- 图像生成缺乏多样性
- 模式崩溃
- 多模态分布学习困难
- 训练时间长
- 由于问题表述的对抗性,不容易训练
另外,还有一条基于似然(例如,马尔可夫随机场)的技术路线,尽管已经存在很久,但由于对每个问题的实施和制定都很复杂,因此未能产生重大影响。
近几年,随着算力的增长,一些过去算力无法满足的复杂算法得以实现,其中有一种方法叫“扩散模型”——一种从气体扩散的物理过程中汲取灵感并试图在多个科学领域模拟相同现象的方法。该模型在图像生成领域展现了巨大的潜力,成为今天Stable Diffusion的基础。
扩散模型
扩散模型是一种生成模型,用于生成与训练数据相似的数据。简单的说,扩散模型的工作方式是通过迭代添加高斯噪声来“破坏”训练数据,然后学习如何消除噪声来恢复数据。
一个标准扩散模型有两个主要过程:正向扩散和反向扩散。
在正向扩散阶段,通过逐渐引入噪声来破坏图像,直到图像变成完全随机的噪声。
在反向扩散阶段,使用一系列马尔可夫链逐步去除预测噪声,从高斯噪声中恢复数据1。

对于噪声的估计和去除,最常使用的是 U-Net。该神经网络的架构看起来像字母 U,由此得名。U-Net 是一个全连接卷积神经网络,这使得它对图像处理非常有用。U-Net的特点在于它能够将图像作为入口,并通过减少采样来找到该图像的低维表示,这使得它更适合处理和查找重要属性,然后通过增加采样将图像恢复回来。

具体的说,所谓去除噪声就是从时间帧 t t t 向时间帧 t − 1 t-1 t−1 的变换,其中 t t t 是 t 0 t_0 t0 (没有噪声)到 t m a x t_max tmax(完全噪声)之间的任意时间帧。变换规则为:
- 输入时间帧 t t t 的图像,并且在该时间帧上图像存在特定噪声;
- 使用 U-Net 预测总噪声量;
- 然后在时间帧 t t t 的图像中去除总噪声的“一部分”,得到噪声较少的时间帧 t − 1 t-1 t−1 的图像。

从数学上讲,执行此上述方法 T T T 次比尝试消除整个噪声更有意义。通过重复这个过程,噪声会逐渐被去除,我们会得到一个更“干净”的图像。比如对于带有噪声的图,我们通过在初始图像上添加完全噪声,然后再迭代地去除它来生成没有噪声的图像,效果比直接在原图上去除噪声要好。
近几年,扩散模型在图像生成任务中表现出突出的性能,并在图像合成等多个任务中取代了GAN。由于扩散模型能够保持数据的语义结构,因此不会受到模式崩溃的影响。
然而,实现扩散模型存在一些困难。因为所有马尔可夫状态都需要一直在内存中进行预测,这意味着内存中要一直保存多个大型深度网络的实例,从而导致扩散模型非常吃内存。此外,扩散模型可能会陷入图像数据中难以察觉的细粒度复杂性中,导致训练时间变得太长(几天到几个月)。矛盾的是,细粒度图像生成是扩散模型的主要优势之一,我们无法避免这个“甜蜜的烦恼”。由于扩散模型对计算要求非常高,训练需要非常大的内存和电量,这使得早前大多数研究人员无法在现实中实现该模型。
Transformer
Transformer是来自 NLP 领域的非常著名的模型方法。Transformer在语言建模和构建对话式 AI 工具方面取得了巨大成功。 在视觉应用中,Transformer 表现出了泛化和自适应的优势,这使得它们非常适合通用学习。 它们比其他技术能够更好地捕捉文本甚至图像中的语义结构。 然而,Transformers 需要大量数据,并且与其他方法相比,在许多视觉领域的性能方面也面临着平台期。
Transformer可以与扩散模型结合,通过Transformer的“词嵌入”可以将文本插入到模型中。这意味着将词Token化后,然后将这种文本表示添加到U-Net的输入(图像)中,经过每一层U-Net神经网络与图像一起进行变换。从第一次迭代开始到之后的每一次迭代都加入相同的文本,从而让文本“作为指南”生成图像,从有完整噪声的第一次迭代开始,然后进一步向下应用到整个迭代。
Stable Diffusion
扩散模型最大的问题是它的时间成本和经济成本都极其“昂贵”。Stable Diffusion的出现就是为了解决上述问题。如果我们想要生成一张 1024 × 1024 1024 \\times 1024 1024×1024 尺寸的图像,U-Net 会使用 1024 × 1024 1024 \\times 1024 1024×1024 尺寸的噪声,然后从中生成图像。这里做一步扩散的计算量就很大,更别说要循环迭代多次直到100%。一个解决方法是将大图片拆分为若干小分辨率的图片进行训练,然后再使用一个额外的神经网络来产生更大分辨率的图像(超分辨率扩散)。
2021年发布的Latent Diffusion模型给出了不一样的方法。 Latent Diffusion模型不直接在操作图像,而是在潜在空间中进行操作。通过将原始数据编码到更小的空间中,让U-Net可以在低维表示上添加和删除噪声。
潜在空间(Lantent Space)
潜在空间简单的说是对压缩数据的表示。所谓压缩指的是用比原始表示更小的数位来编码信息的过程。比如我们用一个颜色通道(黑白灰)来表示原来由RGB三原色构成的图片,此时每个像素点的颜色向量由3维变成了1维度。维度降低会丢失一部分信息,然而在某些情况下,降维不是件坏事。通过降维我们可以过滤掉一些不太重要的信息你,只保留最重要的信息。
假设我们像通过全连接的卷积神经网络训练一个图像分类模型。当我们说模型在学习时,我们的意思是它在学习神经网络每一层的特定属性,比如边缘、角度、形状等……每当模型使用数据(已经存在的图像)学习时,都会将图像的尺寸先减小再恢复到原始尺寸。最后,模型使用解码器从压缩数据中重建图像,同时学习之前的所有相关信息。因此,空间变小,以便提取和保留最重要的属性。这就是潜在空间适用于扩散模型的原因。


Latent Diffusion
“潜在扩散模型”(Latent Diffusion Model)将GAN的感知能力、扩散模型的细节保存能力和Transformer的语义能力三者结合,创造出比上述所有模型更稳健和高效的生成模型。与其他方法相比,Latent Diffusion不仅节省了内存,而且生成的图像保持了多样性和高细节度,同时图像还保留了数据的语义结构。
任何生成性学习方法都有两个主要阶段:感知压缩和语义压缩。
感知压缩
在感知压缩学习阶段,学习方法必须去除高频细节将数据封装到抽象表示中。此步骤对构建一个稳定、鲁棒的环境表示是必要的。GAN 擅长感知压缩,通过将高维冗余数据从像素空间投影到潜在空间的超空间来实现这一点。潜在空间中的潜在向量是原始像素图像的压缩形式,可以有效地代替原始图像。
更具体地说,用自动编码器 (Auto Encoder) 结构捕获感知压缩。 自动编码器中的编码器将高维数据投影到潜在空间,解码器从潜在空间恢复图像。

#### 语义压缩
在学习的第二阶段,图像生成方法必须能够捕获数据中存在的语义结构。 这种概念和语义结构提供了图像中各种对象的上下文和相互关系的保存。 Transformer擅长捕捉文本和图像中的语义结构。 Transformer的泛化能力和扩散模型的细节保存能力相结合,提供了两全其美的方法,并提供了一种生成细粒度的高度细节图像的方法,同时保留图像中的语义结构。
感知损失
潜在扩散模型中的自动编码器通过将数据投影到潜在空间来捕获数据的感知结构。论文作者使用一种特殊的损失函数来训练这种称为“感知损失”的自动编码器。该损失函数确保重建限制在图像流形内,并减少使用像素空间损失(例如 L1/L2 损失)时出现的模糊。
扩散损失
扩散模型通过从正态分布变量中逐步去除噪声来学习数据分布。换句话说,扩散模型使用长度为 T T T 的反向马尔可夫链。这也意味着扩散模型可以建模为时间步长为 t = 1 , … , T t =1,\\dots,T t=1,…,T 的一系列“T”去噪自动编码器。由下方公式中的 ϵ θ \\epsilon_\\theta ϵθ表示:
L D M = E x , ϵ ∼ N ( 0 , 1 ) , t [ ∣ ∣ ϵ − ϵ θ ( x t , t ) ∣ ∣ 2 2 ] (1) L_DM = \\mathbbE_x, \\epsilon \\sim \\mathcalN(0, 1), t \\Big\\lbrack||\\epsilon-\\epsilon_\\theta(x_t, t)||_2^2\\Big\\rbrack \\tag1 LDM=Ex,ϵ∼N(0,1),t[∣∣ϵ−ϵθ(xt,t)∣∣22](1)
公式(1)给出了扩散模型的损失函数。在潜在扩散模型中,损失函数取决于潜在向量而不是像素空间。我们将像素空间元素 x x x替换成潜在向量 ε ( x ) \\varepsilon(x) ε(x),将t时间的状态 x t x_t xt替换为去噪U-Net在时间t的潜在状态 z t z_t zt,即可得到潜在扩散模型的损失函数,见公式(2):
L L D M : = E ε ( x ) , ϵ ∼ N ( 0 , 1 ) , t [ ∣ ∣ ϵ − ϵ θ ( z t , t ) ∣ ∣ 2 2 ] (2) L_LDM := \\mathbbE_\\varepsilon(x), \\epsilon\\sim \\mathcalN(0, 1), t \\Big\\lbrack||\\epsilon-\\epsilon_\\theta(z_t, t)||_2^2\\Big\\rbrack \\tag2 LLDM:=Eε(x),ϵ∼N(0,1),t[∣∣ϵ−ϵθ(zt,t)∣∣22](2)
将公式(2)写成条件损失函数,得到公式(3):
L L D M : = E ε ( x ) , y , ϵ ∼ N ( 0 , 1 ) , t [ ∣ ∣ ϵ − ϵ θ ( z t , t ) , τ θ ( y ) ∣ ∣ 2 2 ] (3) L_LDM := \\mathbbE_\\varepsilon(x), y, \\epsilon\\sim \\mathcalN(0, 1), t \\Big\\lbrack||\\epsilon-\\epsilon_\\theta(z_t, t),\\tau_\\theta(y)||_2^2 \\Big\\rbrack \\tag3 LLDM:=Eε(x),y,ϵ∼N(0,1),t[∣∣ϵ−ϵθ(zt,t),τθ(y)∣∣22](3)
其中 τ θ ( y ) \\tau_\\theta(y) τθ(y)是条件 y y y下的领域专用编码器(比如Transformer)。
条件扩散
扩散模型是依赖于先验的条件模型。在图像生成任务中,先验通常是文本、图像或语义图。为了获得先验的潜在表示,需要使用转换器(例如 CLIP)将文本/图像嵌入到潜在向量 τ \\tau τ中。因此,最终的损失函数不仅取决于原始图像的潜在空间,还取决于条件的潜在嵌入。
注意力机制
潜在扩散模型的主干是具有稀疏连接的 U-Net 自动编码器,提供交叉注意力机制2。Transformer 网络将条件文本/图像编码为潜在嵌入,后者又通过交叉注意力层映射到 U-Net 的中间层。这个交叉注意力层实现了注意力 ( Q , K , V ) = s o f t m a x ( Q K T / d ) V (Q,K,V) = softmax(QKT/\\sqrtd) V (Q,K,V)=softmax(QKT/d)V,其中 Q、K 和 V 是可学习的投影矩阵
文本-图像合成
在 Python 实现中,我们可以使用使用 LDM v4 的最新官方实现来生成图像。 在文本到图像的合成中,潜在扩散模型使用预训练的 CLIP 模型3,该模型为文本和图像等多种模态提供基于Transformer的通用嵌入。 然后将Transformer模型的输出输入到称为“diffusers”的潜在扩散模型Python API,同时还可以设置一些参数(例如,扩散步数、随机数种子、图像大小等)。
图像-图像合成
相同的方法同样适用于图像到图像的合成,不同的是需要输入样本图像作为参考图像。生成的图像在语义和视觉上与作为参考给出的图像相似。这个过程在概念上类似于基于样式的 GAN 模型,但它在保留图像的语义结构方面做得更好。
整体架构
上面介绍了潜在扩散模型的各个主要技术部分,下面我们将它们合成一个整理,看一下潜在扩散模型的完整工作流程。
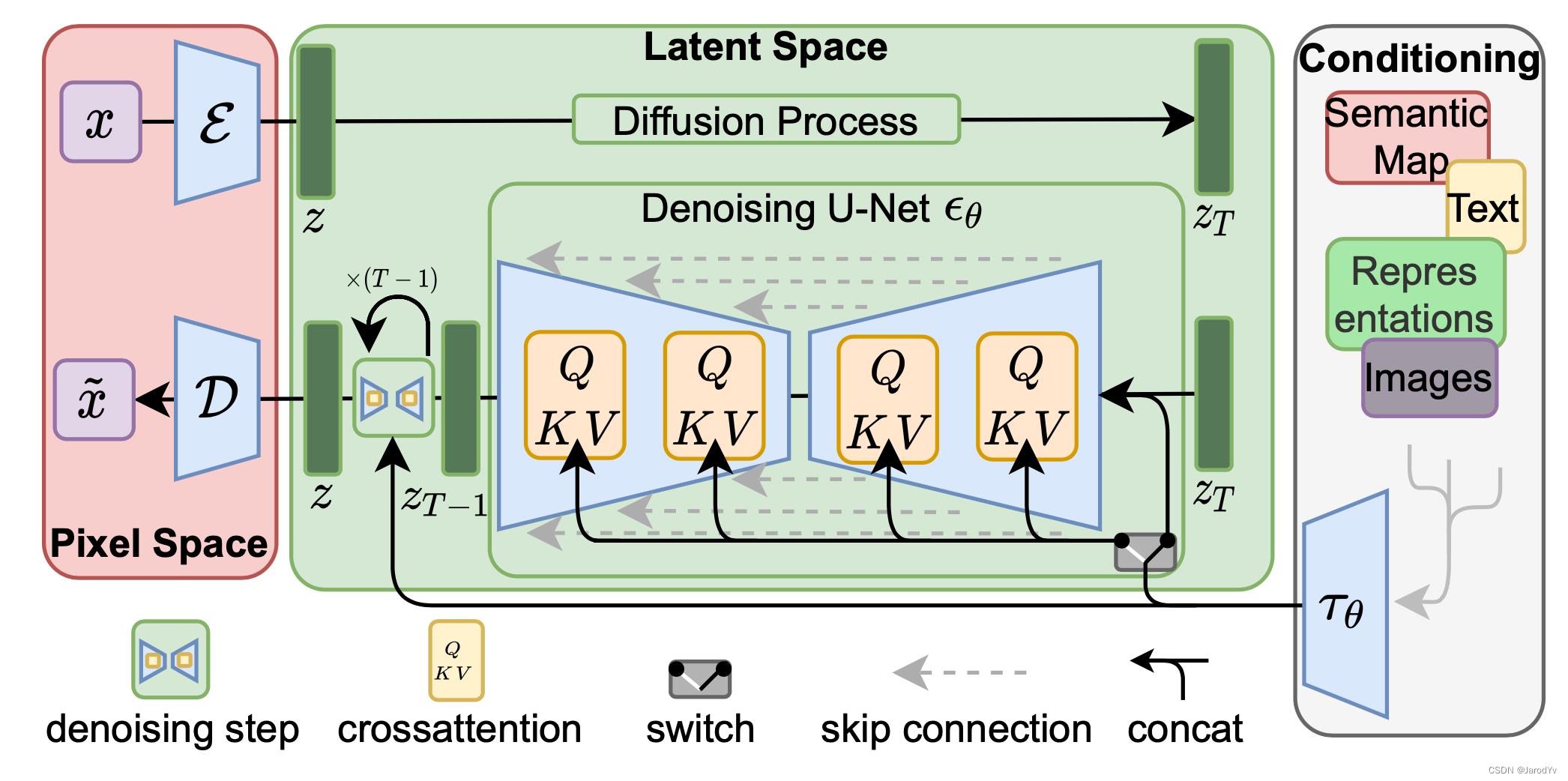
上图中 x x x 表示输入图像, x ~ \\tildex x~ 表示生成的图像; ε \\varepsilon ε 是编码器, D \\calD D 是解码器,二者共同构成了感知压缩; z z z 是潜在向量; z T z_T zT 是增加噪声后的潜在向量; τ θ \\tau_\\theta τθ 是文本/图像的编码器(比如Transformer或CLIP),实现了语义压缩。
总结
本文向大家介绍了图像生成领域最前沿的Stable Diffusion模型。本质上Stable Diffusion属于潜在扩散模型(Latent Diffusion Model)。潜在扩散模型在生成细节丰富的不同背景的高分辨率图像方面非常稳健,同时还保留了图像的语义结构。 因此,潜在扩散模型是图像生成即深度学习领域的一项重大进步。 Stable Diffusion只是将潜在扩散模型应用于高分辨率图像,同时使用 CLIP 作为文本编码器。
说了这么多理论,想必大家已经迫不及待跃跃欲试了。别着急,后面我会手把手教大家搭建Stable Diffusion本地环境,让大家可以亲手体验Stable Diffusion的威力。

Jonathan Ho, Ajay Jain, Pieter Abbeel, “Denoising Diffusion Probabilistic Models”, 2020 ↩︎
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, “Attention Is All You Need”, 2017 ↩︎
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever, “Learning Transferable Visual Models From Natural Language Supervision”, 2021 ↩︎
以上是关于Stable Diffusion原理详解的主要内容,如果未能解决你的问题,请参考以下文章