推荐系统(029~036)
Posted Jozky86
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统(029~036)相关的知识,希望对你有一定的参考价值。
文章目录
- 推荐系统算法
推荐系统算法
基于人口统计学:数据源人口信息
协同过滤:基于行为数据

基于人口统计学的推荐算法
找相似的用户
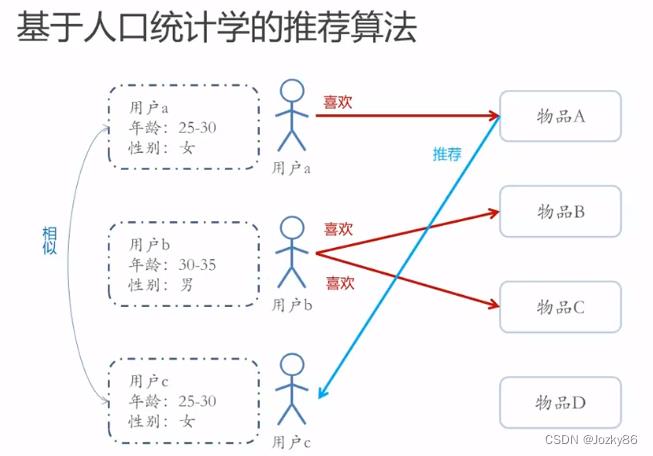
用户信息标签化的过程称为用户画像(User Profiling)

用户画像

基于内容的推荐算法
判断内容是否相似,根据物品或者内容的元数据,发现物品的相关性
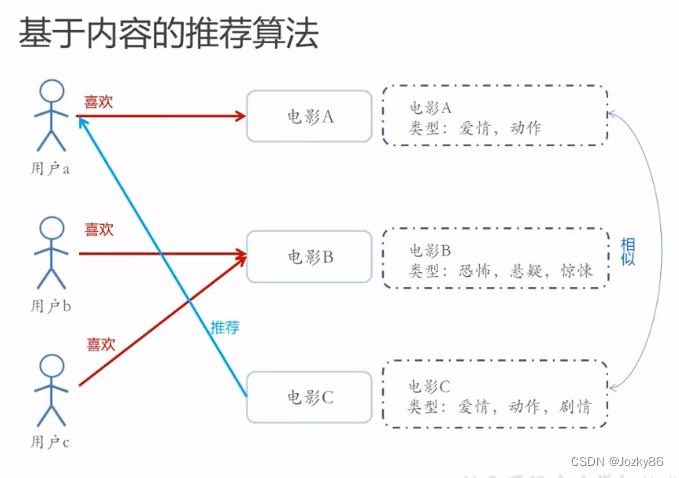
将用户(user)个人信息的特征,和物品(item)的特征相匹配

对物品的特征提取–打标签(tag)
对文本信息的特征提取–关键词

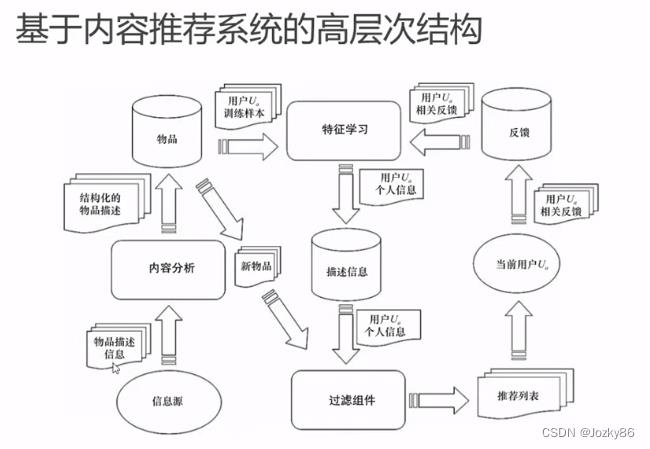
基于内容推荐系统的高层次结构
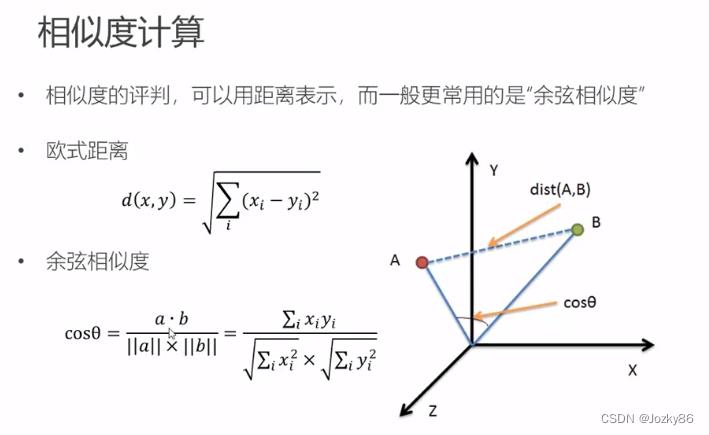
相似度计算
一般更常用的是"余弦相似度"
为什么不用距离,而用余弦相似度?
特征工程
特征:数据中心抽取出来的对结果预测有用的信息

特征工程是在模型之前的步骤

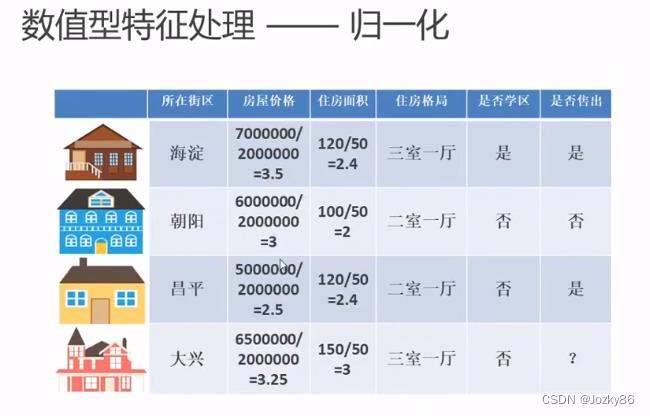
数值型特征处理
主要做法:归一化和离散化
幅度调整/归一化

离散化

对一个age特征分为多个特征,将连续值离散化
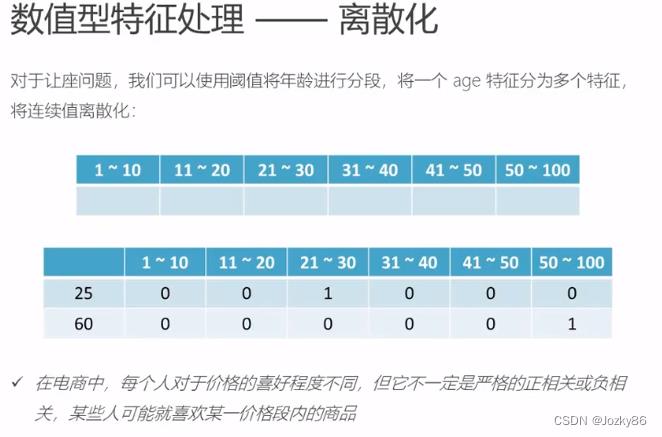
离散化的两种方式:1.等步长 2.等频

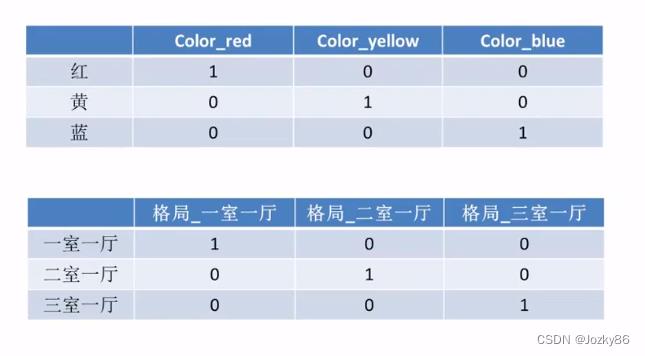
类别型特征处理
类别型数据本身无大小关系,它们之间不能有预先设定的大小关系
One-Hot编码/哑变量

时间型特征处理

统计型特征处理

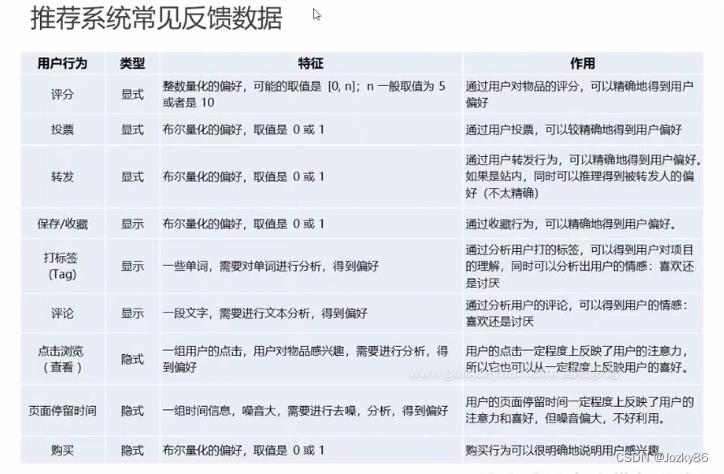
推荐系统常见反馈数据
显示反馈数据
隐式反馈数据
基于UGC的推荐
用户用标签来描述对物品的看法,所以UGC(用户生产标签)是联系用户和物品的纽带,也是反应用户兴趣的重要数据源

基于UGC简单推荐的问题

解决方法:TF-IDF
TF-IDF
词频-逆文档频率(TF-IDF)
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降
IDF相当于对热门词汇的惩罚

具体计算公式:

TF-IDF对基于UGC推荐的改进
在简单算法的基础上,直接加入对热门标签和热门物品的惩罚项

TF-IDF算法代码示例
详细见jupyter 6_tfidf代码实现
基于协同过滤的推荐算法
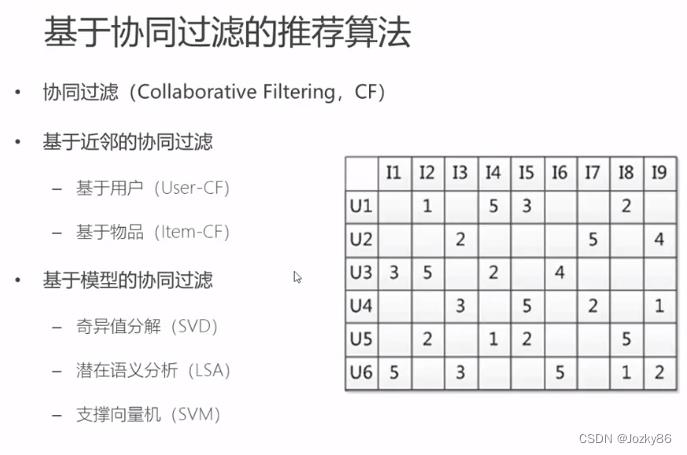
CF比CB的优点

缺点:难以处理冷启动问题
基于近邻的推荐
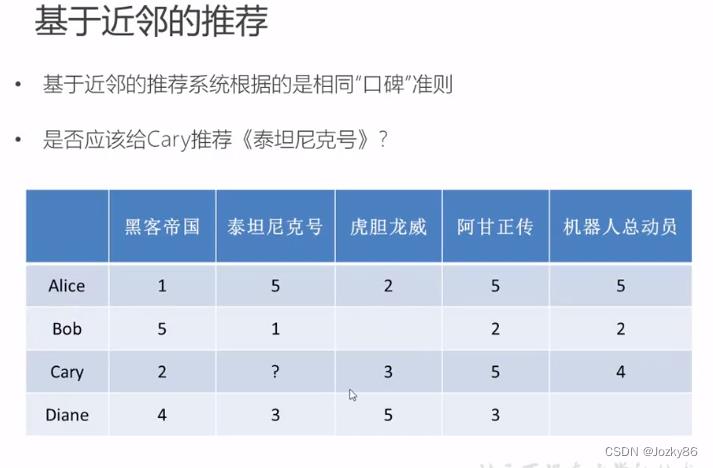
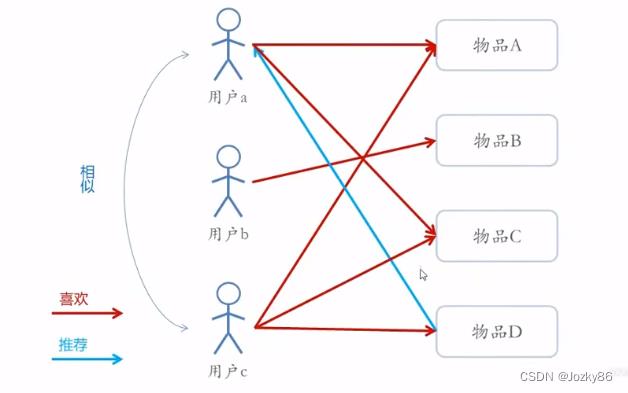
基于用户的协同过滤(User-CF)
基于人口统计学的机制只考虑用户本身的特征
基于用户的协同过滤机制是在用户的历史偏好上计算用户的相似度

基于物品的协同过滤
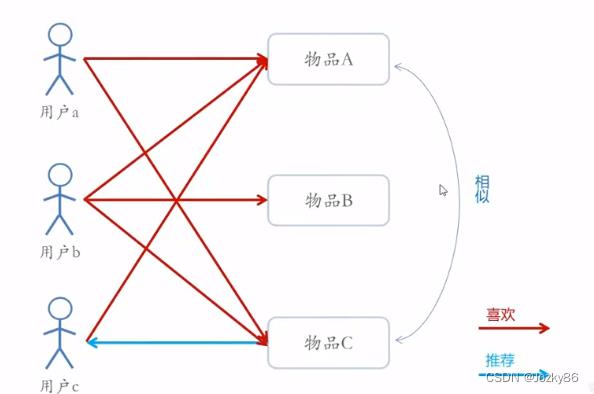
item-CF,CB,user-CF的区别
item-CF:从用户历史的偏好推断
CB:基于物品本身的属性特征信息

User-CF和Item-CF的比较
新闻推荐系统中用User-CF
物品的个数小于用户数量的–>Item-CF

协同过滤的优缺点

基于模型的协同过滤
基本思想:从行为数据中提取特征,给用户和物品同时打上“标签”

基于模型与基于近邻比较

隐语义模型(LFM)
训练模型去发掘物品的潜在特征–>隐语义模型
某些特征可能是无法直接用语言解释描述的
利用矩阵分解进行降维分析,分解后的矩阵可以代表用户和物品的隐藏特征

LFM降维方法—矩阵因子分解
k表示隐藏特征

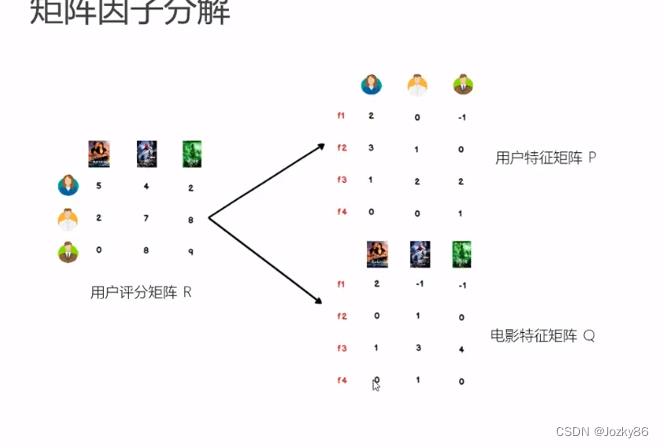
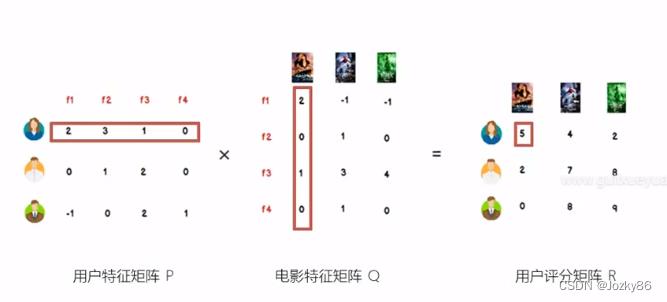
LFM的进一步理解
找到隐藏因子,可以对user和item进行关联

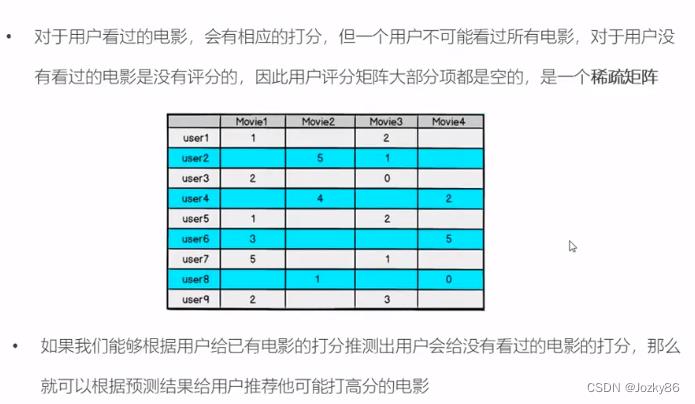
矩阵因子分解
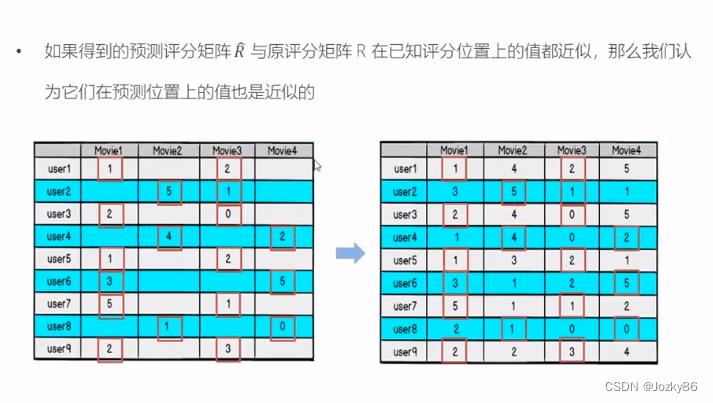
根据P和Q的乘积R不再是稀疏的,之前R中没有的项也可以由P、Q的乘积算出,这就得到一个预测评分矩阵
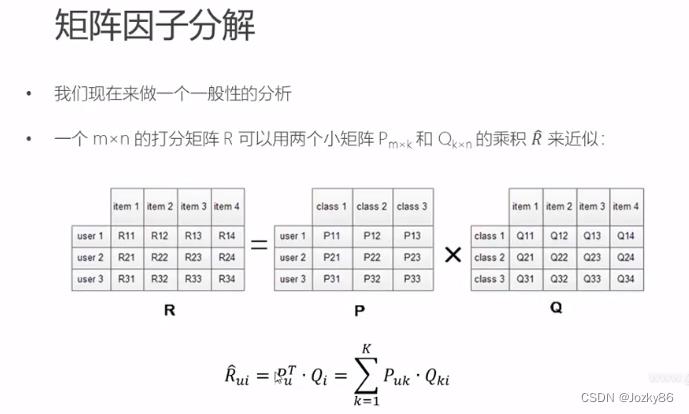
如果得到的预测矩阵R与原评分矩阵R在已知评分位置上的值都近似,那么我们认为他们在预测位置上的值也是近似的
模型的求解----损失函数

模型的求解算法——ALS
交替最小二乘法(ALS)
基本思想:先固定Q,把P当作变量,通过损失函数最小化求出P,这就是一个经典的最小二乘问题;再反过来固定P,求Q

ALS算法具体过程如下:

ALS的公式推导:

自变量是Pu


梯度下降算法

LFM梯度下降算法代码实现
详细代码见 7_LFM梯度下降代码实现
# 给定超参数
K = 5
max_iter = 5000
alpha = 0.0002
lamda = 0.004
# 核心算法
def LFM_grad_desc( R, K=2, max_iter=1000, alpha=0.0001, lamda=0.002 ):
# 基本维度参数定义
M = len(R)
N = len(R[0])
# P,Q初始值,随机生成
P = np.random.rand(M, K)
Q = np.random.rand(N, K)
Q = Q.T #转置
# 开始迭代
for step in range(max_iter):
# 对所有的用户u、物品i做遍历,对应的特征向量Pu、Qi梯度下降
for u in range(M):
for i in range(N):
# 对于每一个大于0的评分,求出预测评分误差
if R[u][i] > 0:
eui = np.dot( P[u,:], Q[:,i] ) - R[u][i]
# 代入公式,按照梯度下降算法更新当前的Pu、Qi
for k in range(K):
P[u][k] = P[u][k] - alpha * ( 2 * eui * Q[k][i] + 2 * lamda * P[u][k] )
Q[k][i] = Q[k][i] - alpha * ( 2 * eui * P[u][k] + 2 * lamda * Q[k][i] )
# u、i遍历完成,所有特征向量更新完成,可以得到P、Q,可以计算预测评分矩阵
predR = np.dot( P, Q )
# 计算当前损失函数
cost = 0
for u in range(M):
for i in range(N):
if R[u][i] > 0:
cost += ( np.dot( P[u,:], Q[:,i] ) - R[u][i] ) ** 2
# 加上正则化项
for k in range(K):
cost += lamda * ( P[u][k] ** 2 + Q[k][i] ** 2 )
if cost < 0.0001:
break
return P, Q.T, cost
以上是关于推荐系统(029~036)的主要内容,如果未能解决你的问题,请参考以下文章