计算机视觉算法——基于Anchor Free的目标检测网络总结
Posted Leo-Peng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机视觉算法——基于Anchor Free的目标检测网络总结相关的知识,希望对你有一定的参考价值。
计算机视觉算法——基于Anchor Free的目标检测网络总结
计算机视觉算法——基于Anchor Free的目标检测网络总结
在之前我有总结过一些目标检测网络:
计算机视觉算法——目标检测网络总结
这些方法大都是Anchor Based方法,Anchor Based方法的主要问题是:
- 检测器的性能和Anchor的Size和Aspect Ratio相关,在RetinaNet中改变Anchor能造成4%的AP的变化;
- 一般Anchor的Size和Aspect Ratio是固定的,很难处理形状变化大的目标,当发生任务迁移时,往往需要重新设计Anchor;
- 为了达到召回率,一般需要在图片中生成非常密集的Anchor Boxes。在训练时绝大部分的Anchor Boxes都会时负样本,容易造成正负样本不均的情况。
- Anchor的引入会使得网络的训练过程变得更加繁琐,想了解这一点大家可以去看看SSD的源码。
1. CornerNet
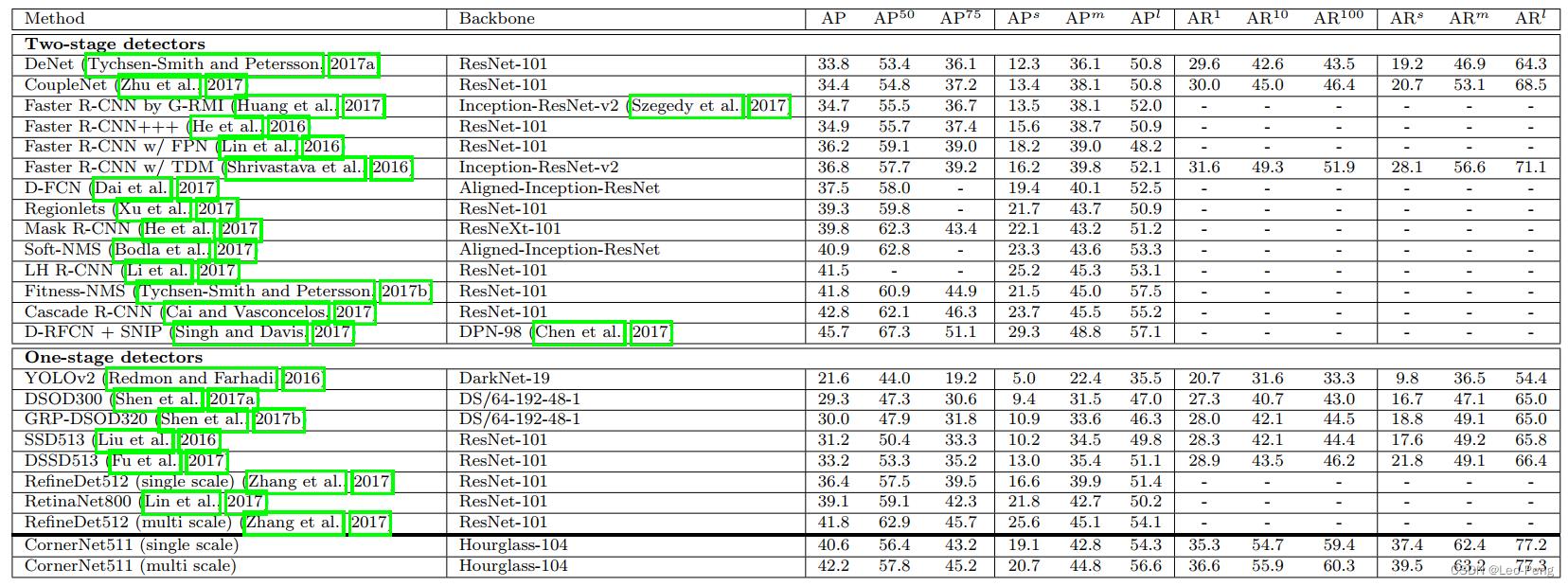
CornerNet发表于2018年ECCV,原论文名为《CornerNet: Detecting Objects as Paired Keypoints》,该论文将目标检测问题当作关键点检测问题来解决,通过检测目标框的左上角和右下角两个关键点得到预测框。从同期SOTA方法在MS COCO数据集的对比i结果看,相对于One-Stage方法精度有明显提升,但是相对于Two-Stage方法精度接近,但是该方法在推断时间上无优势:
1.1 关键知识点——网络结构及特点
网络结构如下图所示:
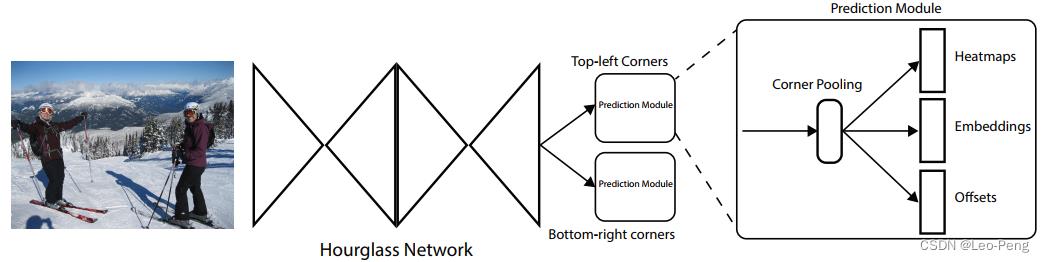
如上图所示,ConerNet模型包括三部分,首先是通过堆叠两个Hourglass Network提取图像Feature,然后就是将图像Feature分别通过Top-left Corner和Bottom-right Corner两个Prediction Modules。
Prediction Module的具体结构如下图所示:
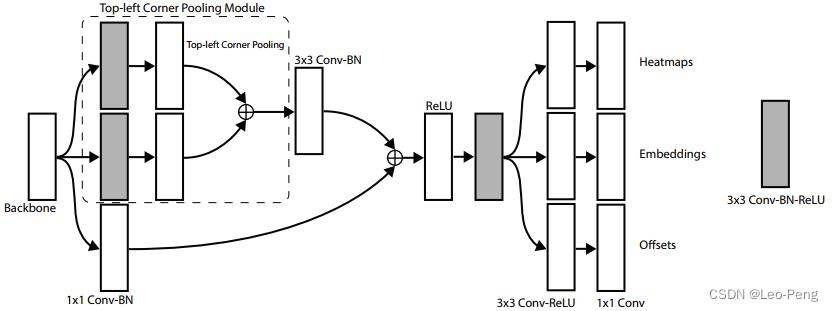
可以看出来Prediction Module整体是一个残差结构,其中Top-Left Corner Pooling Module我们稍后介绍,这里先看下Prediction Module的输出包括三部分:Heatmaps,Embeddings,Offsets。
- Heatmaps用于预测角点的位置,输出的是 C C C个Channel的Feature, C C C指的是分类的类别个数(不包括背景类别)
- Embeddings用于对Corner进行分组,Heatmap上检测个角点如何判断是否属于同一个物体呢?就是通过Embeddings输出之间的距离来找到角点之间的对应关系,我看源码这里Embedings输出的是Channel数为1的Feature。
- Offsets用于对预测角点位置进行精修。输出的是Channel数为2的Feature,如下公式所示: o k = ( x k n − ⌊ x k n ⌋ , y k n − ⌊ y k n ⌋ ) \\boldsymbolo_k=\\left(\\fracx_kn-\\left\\lfloor\\fracx_kn\\right\\rfloor, \\fracy_kn-\\left\\lfloor\\fracy_kn\\right\\rfloor\\right) ok=(nxk−⌊nxk⌋,nyk−⌊nyk⌋)我们通过Heatmaps输出的位置还原到原始分辨率后肯定是一个取整后的位置 ( ⌊ x n ⌋ , ⌊ y n ⌋ ) \\left(\\left\\lfloor\\fracxn\\right\\rfloor,\\left\\lfloor\\fracyn\\right\\rfloor\\right) (⌊nx⌋,⌊ny⌋),为了恢复原始分辨率的精度,网络就会输出这样一个修正量 o k \\boldsymbolo_k ok
此外,在上图中还有一个Top-left Corner Pooling Module操作,该操作公式如下:
t
i
j
=
max
(
f
t
i
j
,
t
(
i
+
1
)
j
)
if
i
<
H
f
t
H
j
otherwise
t_i j=\\left\\\\beginarraycc \\max \\left(f_t_i j, t_(i+1) j\\right) & \\text if i<H \\\\ f_t_H j & \\text otherwise \\endarray\\right.
tij=max(ftij,t(i+1)j)ftHj if i<H otherwise
l
i
j
=
max
(
f
l
i
j
,
l
i
(
j
+
1
)
)
if
j
<
W
f
l
i
W
otherwise
l_i j=\\left\\\\beginarraycc \\max \\left(f_l_i j, l_i(j+1)\\right) & \\text if j<W \\\\ f_l_i W & \\text otherwise \\endarray\\right.
lij=max(flij,li(j+1))fliW if j<W otherwise 其实就是取水平和竖直最大值,最后求和,具体的案例下图所示:
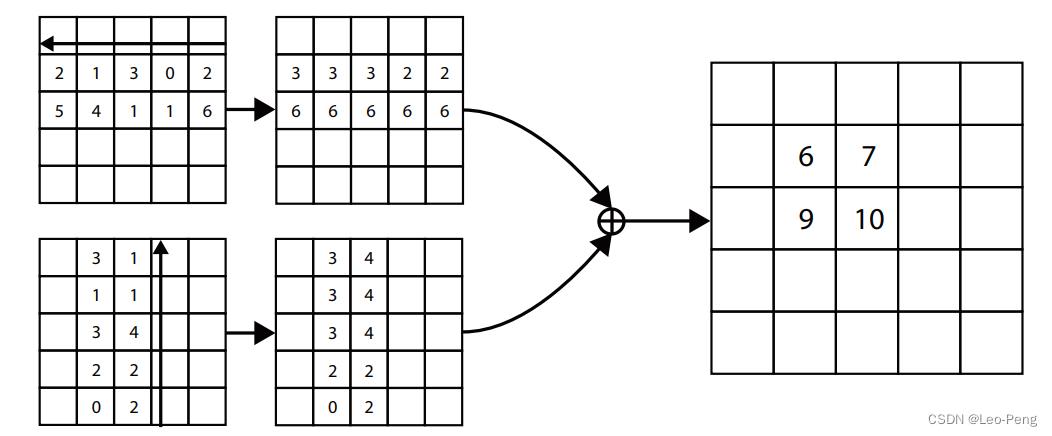
论文认为Corner Pooling之所以有效,是因为(1)目标定位框的中心难以确定,和边界框的四条边相关,但是每个顶点只与边界框的两条边相关,所以Corner跟他容易获取;(2)顶点更有效提供离散边界空间,作者做了Corner Pooling的实验如下:

1.2 关键知识点——正负样本匹配
对于每个角点,只有一个正样本,其余的都是负样本。但是为了保证样本均衡,作者在角点半径范围内区域会加大对负样本的惩罚力度。实际怎么做呢?
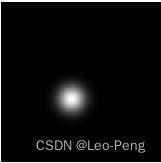
在构建Heatmaps Groundtruth时,如果不加任何惩罚,那么正样本处应该就为1,而负样本处为0;而加上惩罚后就是在角点半径范围内构建一个
e
−
x
2
+
y
2
2
σ
2
e^-\\fracx^2+y^22 \\sigma^2
e−2σ2x2+y2的高斯分布,该
σ
\\sigma
σ可以是个固定值,可以与物体大小相关,总而言之是越靠近角点的地方越接近于1,越远离角点的地方越接近于0。如下图所示:
作者做了负样本惩罚的消融实验如下:
注意,这里还是只有角点一个正样本,在计算
L
pull
L_\\text pull
Lpull 、
L
push
L_\\text push
Lpush 和
L
o
f
f
L_o f f
Loff时还是只在角点处计算。
1.3 关键知识点——损失计算
Corner损失函数定义如下:
L
=
L
det
+
α
L
pull
+
β
L
push
+
γ
L
o
f
f
L=L_\\text det +\\alpha L_\\text pull +\\beta L_\\text push +\\gamma L_o f f
L=Ldet +αLpull +βLpush +γLoff其中
L
det
L_\\text det
Ldet 是Heatmaps的Loss,采用的是Focal Loss,准确地说,是针对Heatmaps改进的Focal Loss,公式如下所示:
L
det
=
−
1
N
∑
c
=
1
C
∑
i
=
1
H
∑
j
=
1
W
(
1
−
p
c
i
j
)
α
log
(
p
c
i
j
)
if
y
c
i
j
=
1
(
1
−
y
c
i
j
)
β
(
p
c
i
j
)
α
log
(
1
−
p
c
i
j
)
otherwise
L_\\text det =\\frac-1N \\sum_c=1^C \\sum_i=1^H \\sum_j=1^W\\left\\\\beginarraycc \\left(1-p_c i j\\right)^\\alpha \\log \\left(p_c i j\\right) & \\text if y_c i j=1 \\\\ \\left(1-y_c i j\\right)^\\beta\\left(p_c i j\\right)^\\alpha \\log \\left(1-p_c i j\\right) & \\text otherwise \\endarray\\right.
Ldet =N−1c=1∑Ci=1∑Hj=1∑W(1−p