自然语言处理基于句子嵌入的文本摘要算法实现
Posted 皮皮要HAPPY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理基于句子嵌入的文本摘要算法实现相关的知识,希望对你有一定的参考价值。
基于句子嵌入的文本摘要算法实现
人们在理解了文本的含义后,很容易用自己的话对文本进行总结。但在数据过多、缺乏人力和时间的情况下,自动文本摘要则显得至关重要。一般使用自动文本摘要的原因包括:
- 减少阅读时间
- 根据摘要,选择自己想研究的文档
- 提高索引的有效性
- 自动摘要算法比人工摘要算法的偏差更小
- 问答系统中的个性化摘要
- 能有效增加处理的文本数量
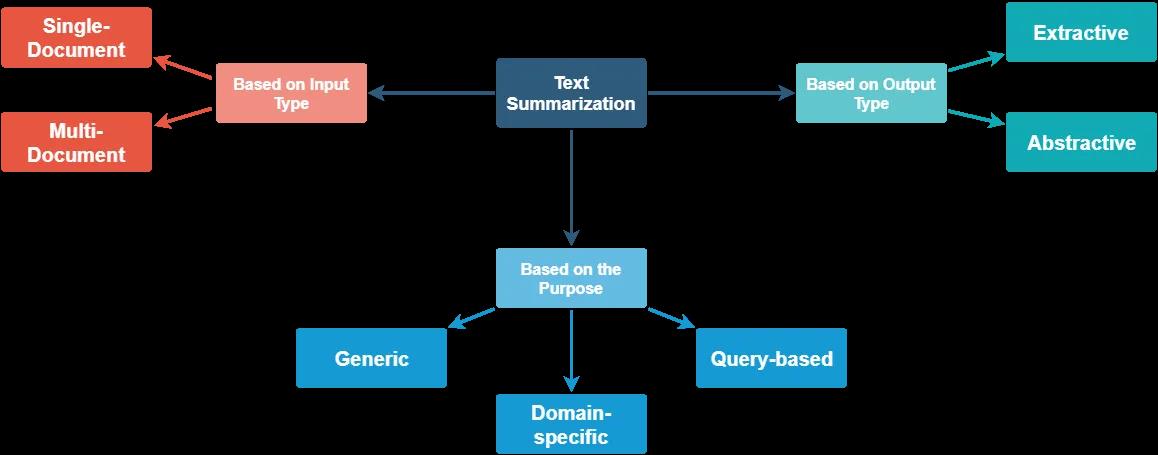
1.方法分类
- 基于输入
- 单个文档
- 多文档
- 基于目的
- 通用型。模型不对文本的所属领域或内容做出任何假设,所有输入被视为同质。目前,大部分研究的工作都是围绕这种方法展开的。
- 特定领域。模型使用特定领域的知识来形成更准确的摘要。例如,总结特定领域的研究论文、生物医学文献等。
- 基于查询。对相关问题的回答进行摘要。
- 基于输出
- 抽取。从输入文本中选择重要的句子形成摘要。目前,大多数摘要方法本质上都是抽取式的。
- 生成。模型生成短语和句子来提供更连贯的摘要。
2.Pipeline
本次任务是 对英语、丹麦语、法语等语言的电子邮件进行文本摘要。大多数公开可用的文本摘要数据集都是针对长文档的。由于长文档的结构与电子邮件的结构明显不同,因此使用监督方法训练的模型可能会出现领域适应性差的问题。因此,我们选择无监督方法来提取摘要。
本文使用的方法主要来自论文《Unsupervised Text Summarization Using Sentence Embeddings》。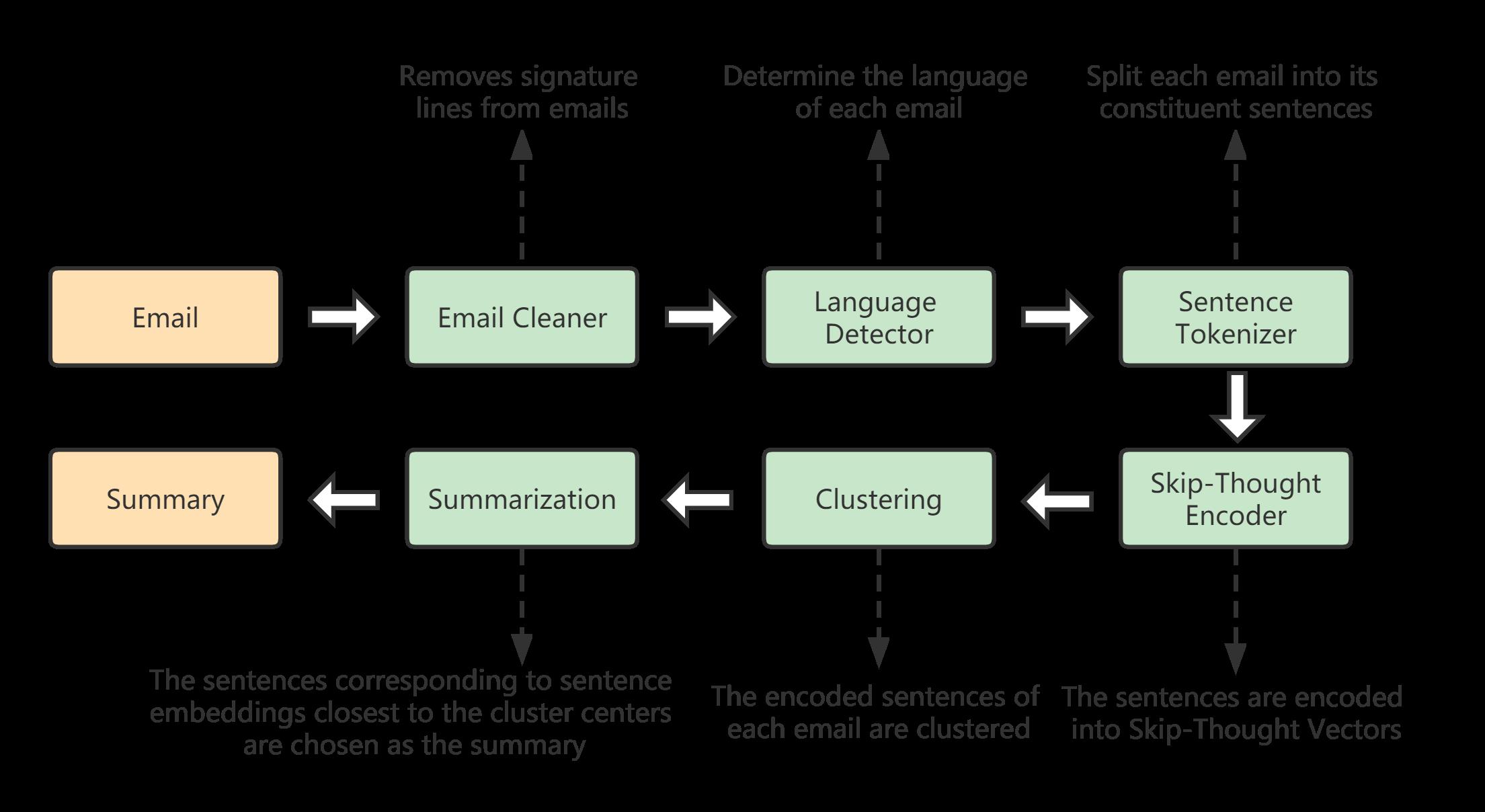
2.1 Email Cleaning
英文邮件示例:
Hi Jane,
Thank you for keeping me updated on this issue. I'm happy to hear that the issue got resolved after all and you can now use the app in its full functionality again.
Also many thanks for your suggestions. We hope to improve this feature in the future.
In case you experience any further problems with the app, please don't hesitate to contact me again.
Best regards,
John Doe
Customer Support
1600 Amphitheatre Parkway
Mountain View, CA
United States
挪威语邮件示例:
Hei
Grunnet manglende dekning på deres kort for månedlig trekk, blir dere nå overført til årlig fakturering.
I morgen vil dere motta faktura for hosting og drift av nettbutikk for perioden 05.03.2018-05.03.2019.
Ta gjerne kontakt om dere har spørsmål.
Med vennlig hilsen
John Doe - SomeCompany.no
04756 | johndoe@somecompany.no
Husk å sjekk vårt hjelpesenter, kanskje du finner svar der: https://support.somecompany.no/
意大利语邮件示例:
Ciao John,
Grazie mille per averci contattato! Apprezziamo molto che abbiate trovato il tempo per inviarci i vostri commenti e siamo lieti che vi piaccia l'App.
Sentitevi liberi di parlare di con i vostri amici o di sostenerci lasciando una recensione nell'App Store!
Cordiali saluti,
Jane Doe
Customer Support
One Infinite Loop
Cupertino
CA 95014
电子邮件开头和结尾的称呼和签名对摘要生成任务没有任何价值。为了使模型可以执行更简单的输入,可以从电子邮件中删除这些无意义的信息。
称呼和签名因电子邮件以及语言而异,因此需要通过正则表达式进行删除。代码的简短版本如下所示(参考了 Mailgun Talon 在 GitHub 中的代码):
# clean() is a modified version of extract_signature() found in bruteforce.py in the GitHub repository linked above
cleaned_email, _ = clean(email)
lines = cleaned_email.split('\\n')
lines = [line for line in lines if line != '']
cleaned_email = ' '.join(lines)
还可以通过 talon.signature.bruteforce 实现:
from talon.signature.bruteforce import extract_signature
cleaned_email, _ = extract_signature(email)
清洗后的文本如下所示。
英文电子邮件:
Thank you for keeping me updated on this issue. I’m happy to hear that the issue got resolved after all and you can now use the app in its full functionality again. Also many thanks for your suggestions. We hope to improve this feature in the future. In case you experience any further problems with the app, please don’t hesitate to contact me again.
挪威语电子邮件:
Grunnet manglende dekning på deres kort for månedlig trekk, blir dere nå overført til årlig fakturering. I morgen vil dere motta faktura for hosting og drift av nettbutikk for perioden 05.03.2018-05.03.2019. Ta gjerne kontakt om dere har spørsmål.
意大利语电子邮件:
Grazie mille per averci contattato! Apprezziamo molto che abbiate trovato il tempo per inviarci i vostri commenti e siamo lieti che vi piaccia l’App. Sentitevi liberi di parlare di con i vostri amici o di sostenerci lasciando una recensione nell’App Store.
2.2 Language Detection
由于输入的电子邮件可以是任何语言,因此需要确定电子邮件使用的是哪种语言。许多 Python 库都提供的语言检测功能,例如 polyglot、langdetect 和 textblob。此处使用 langdetect,它支持
55
55
55 种不同语言的检测。
from langdetect import detect
lang = detect(cleaned_email) # lang = 'en' for an English email
2.3 Sentence Tokenization
不同语言的文本有不同的分割规则,在识别了每封电子邮件使用的语言后,我们可以利用 NLTK 将不同语言的文本分割成句子。
from nltk.tokenize import sent_tokenize
sentences = sent_tokenize(email, language = lang)
2.4 Skip-Thought Encoder
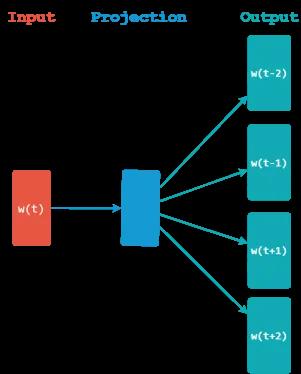
接下来需要为电子邮件中的每个句子生成固定长度的向量表示。例如 Word2Vec 方法可以为模型词汇表中的每个词提供词嵌入(一些更高级的方法还可以使用子词信息为不在模型词汇表中的词生成嵌入)。下图是 Word2Vec 模型的 Skip-Gram 训练模式。
对于句子嵌入,一种简单的方法是 对句子所包含的单词的词向量进行加权和。采用加权和是因为频繁出现的词,如 and、to 和 the 等单词所提供的关于句子的信息几乎非常少甚至没有。一些词虽然出现的次数较少,但它们是少数句子所特有的,具有更强的代表性。因此,我们假设权重与单词出现的频率成反比。
然而无监督方法并没有考虑句子中单词的顺序,这可能会影响模型精度。此处,我们选择使用维基百科转储(Wikipedia dumps)作为训练数据,以监督的方式训练一个 Skip-Thought 句子编码器。 该模型主要由两部分组成:
- 编码器网络(
Encoder Network):编码器通常是GRU-RNN,它为输入中的每个句子 S ( i ) S(i) S(i) 生成固定长度的向量表示 h ( i ) h(i) h(i)。 h ( i ) h(i) h(i) 是通过将 GRU 单元的最终隐藏状态传递给多个密集层来获得的。 - 解码器网络(
Decoder Network):解码器网络将 h ( i ) h(i) h(i) 作为输入,并尝试生成两个句子: S ( i − 1 ) S(i-1) S(i−1) 和 S ( i + 1 ) S(i+1) S(i+1),这两个句子可能分别出现在输入句子之前和之后。每个都实施单独的解码器来生成上一句和下一句,两者都是GRU-RNN。 h ( i ) h(i) h(i) 作为解码器网络的 GRU 的初始隐藏状态。
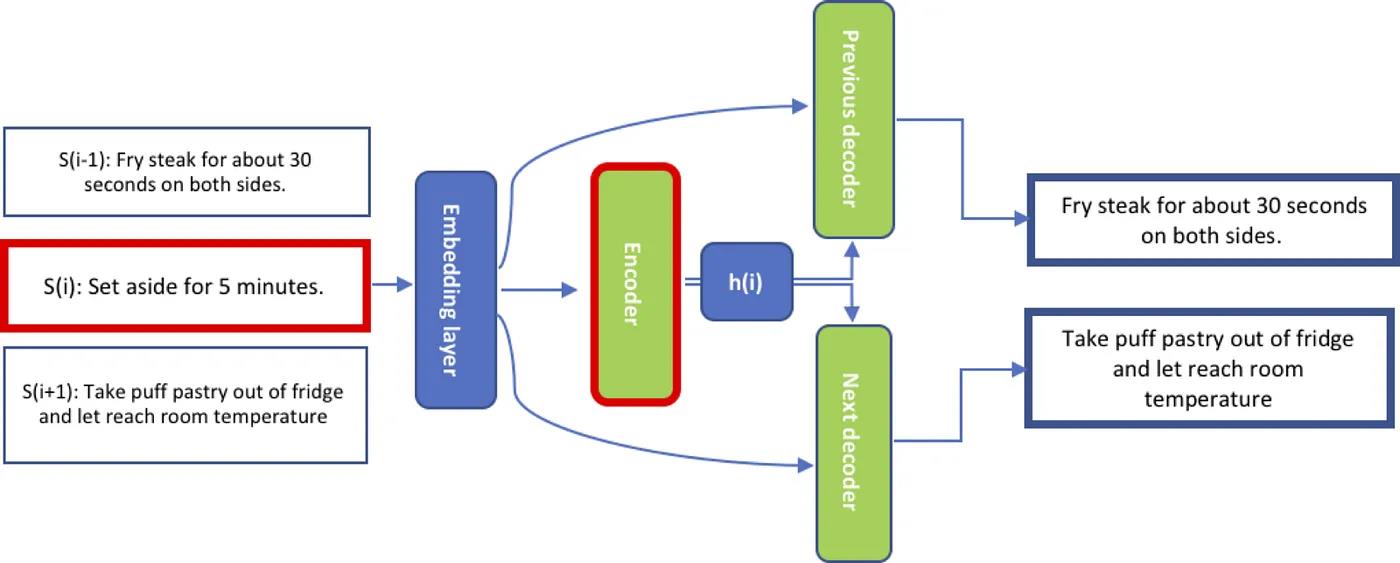
给定一个包含句子序列的数据集,解码器应该逐字生成上一句和下一句。编码器-解码器(encoder-decoder)网络通过训练使句子重建损失(sentence reconstruction loss)最小化。在此过程中,编码器学习生成向量表示,编码足够的信息供解码器使用,以便它可以生成相邻的句子。这些学习到的表示使得 语义相似的句子的嵌入在向量空间中彼此更接近,因此适用于聚类。我们把电子邮件中的句子作为编码器网络的输入,以获得所需的向量表示。

此处,我们可以使用 Skip-Thoughts 论文作者 开源的代码。仅需几行代码就可以完成:
# The 'skipthoughts' module can be found at the root of the GitHub repository linked above
import skipthoughts
# You would need to download pre-trained models first
model = skipthoughts.load_model()
encoder = skipthoughts.Encoder(model)
encoded = encoder.encode(sentences)
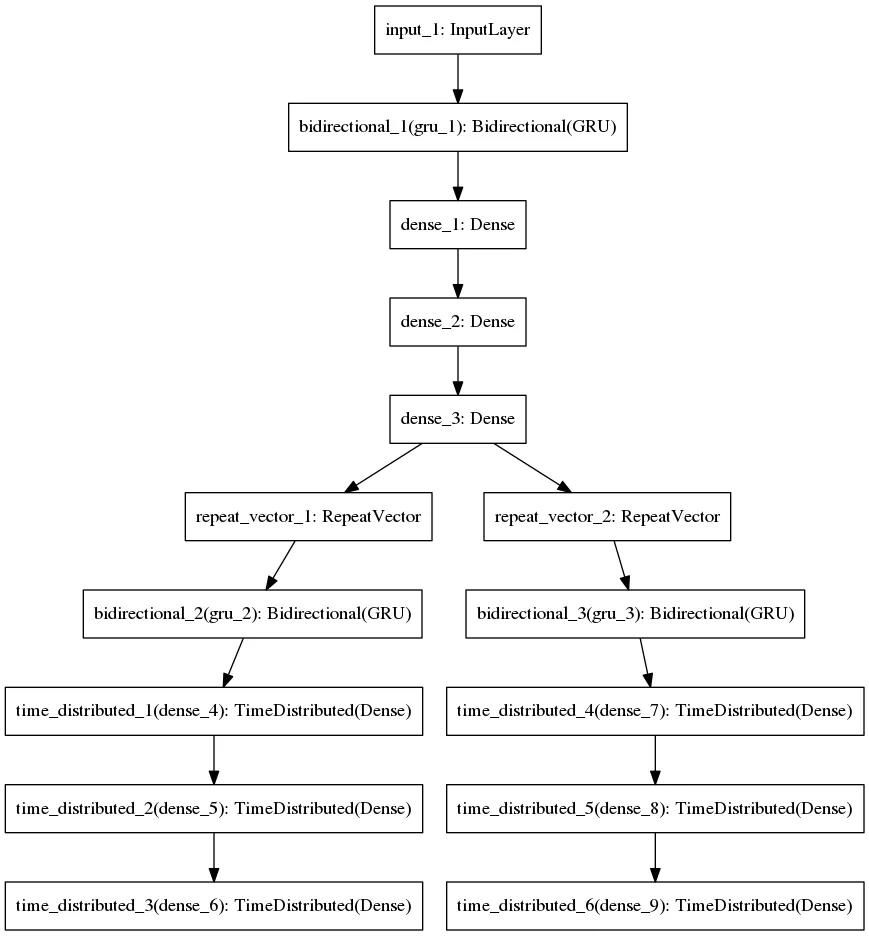
2.5 Clustering
在为电子邮件中的每个句子生成句子嵌入后,可以对这些在高维向量空间中的嵌入进行聚类。聚类的数量将等于摘要中所需的句子数量。可以将摘要中的句子数定义为电子邮件中句子总数的平方根,也可以认为它等于句子总数的 30 % 30\\% 30%。
import numpy as np
from sklearn.cluster import KMeans
n_clusters = np.ceil(len(encoded)**0.5)
kmeans = KMeans(n_clusters=n_clusters)
kmeans = kmeans.fit(encoded)
2.6 Summarization
每个聚类都可以被理解为一组语义相似的句子,其含义可以由摘要中的一个候选句子表达。候选句子是向量表示最接近聚类中心的句子。然后对每个集群对应的候选句子进行排序,以形成电子邮件的摘要。摘要中候选句子的顺序由句子在原始电子邮件中的位置决定。
from sklearn.metrics import pairwise_distances_argmin_min
avg = []
for j in range(n_clusters):
idx = np.where(kmeans.labels_ == j)[0]
avg.append(np.mean(idx))
closest, _ = pairwise_distances_argmin_min(kmeans.cluster_centers_, encoded)
ordering = sorted(range(n_clusters), key=lambda k: avg[k])
summary = ' '.join([email[closest[idx]] for idx in ordering])
最终生成的摘要结果如下所示:
英文电子邮件:
I’m happy to hear that the issue got resolved after all and you can now use the app in its full functionality again. Also many thanks for your suggestions. In case you experience any further problems with the app, please don’t hesitate to contact me again.
丹麦语电子邮件:
Grunnet manglende dekning på deres kort for månedlig trekk, blir dere nå overført til årlig fakturering. I morgen vil dere motta faktura for hosting og drift av nettbutikk for perioden 05.03.2018-05.03.2019. Ta gjerne kontakt om dere har spørsmål.
意大利语电子邮件:
Apprezziamo molto che abbiate trovato il tempo per inviarci i vostri commenti e siamo lieti che vi piaccia l’App. Sentitevi liberi di parlare di con i vostri amici o di sostenerci lasciando una recensione nell’App Store.
3.训练过程
预训练模型可用于编码英语句子。对于丹麦语句子,必须自己训练 Skip-Thought 模型。数据取自丹麦语维基百科转储(Danish Wikipedia dumps)。此处使用 WikiExtractor 解析维基百科转储,虽然它不是最好的工具,但它是免费的,并且可以在合理的时间内完成这项工作。
由此生成的训练数据包括来自维基百科文章的
2
,
712
,
935
2,712,935
2,712,935 个丹麦语句子。训练过程还需要预先训练好的 Word2Vec 词向量。此处使用的是
F
a
c
e
b
o
o
k
Facebook
Facebook 的
F
a
s
t
T
e
x
t
FastText
FastText 的预训练词向量。预训练模型的词汇量为
312
,
956
312,956
312,956 个单词。这些词向量也是在丹麦语维基百科上进行训练的,因此词汇外的词非常少见。
下面是该模块的简化版本,它仅支持英文电子邮件,但实现了上述所有步骤,效果非常好。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
Module for E-mail Summarization
*****************************************************************************
Input Parameters:
emails: A list of strings containing the emails
Returns:
summary: A list of strings containing the summaries.
*****************************************************************************
"""
# ***************************************************************************
import numpy as np
from talon.signature.bruteforce import extract_signature
from langdetect import detect
from nltk.tokenize import sent_tokenize
import skipthoughts
from sklearn.cluster import KMeans
from sklearn.metrics import pairwise_distances_argmin_min
# ***************************************************************************
def preprocess(emails):
"""
Performs preprocessing operations such as:
1. Removing signature lines (only English emails are supported)
2. Removing new line characters.
"""
n_emails = len(emails)
for i in range(n_emails):
email = emails[i]
email, _ = extract_signature(email)
lines = email.split('\\n')
for j in reversed(range(len(lines))):
lines[j] = lines[j].strip()
if lines[j] == '':
lines.pop(j)
emails[i] = ' '.join(lines)
def split_sentences(emails):
"""
Splits the emails into individual sentences
"""
n_emails = len(emails)
for i in range(n_emails):
email = emails[i]
sentences = sent_tokenize(email)
for j in reversed(range(len(sentences))):
sent = sentences[j]
sentences[j] = sent.strip()
if sent == '':
sentences.pop(j)
emails[i] = sentences
def skipthought_encode(emails):
"""
Obtains sentence embeddings for each sentence in the emails
"""
enc_emails = [None]*len(emails)
cum_sum_sentences = [0]
sent_count = 0
for email in emails:
sent_count += len(email)
cum_sum_sentences.append(sent_count)
all_sentences = [sent for email in emails for sent in email]
print('Loading pre-trained models...')
model = skipthoughts.load_model()
encoder = skipthoughts.Encoder(model)
print('Encoding sentences...')
enc_sentences = encoder.encode(all_sentences, verbose=False)
for i in range(len(emails)):
begin = cum_sum_sentences[i]
end = cum_sum_sentences[i+1]
enc_emails[i] = enc_sentences[begin:end]
return enc_emails
def summarize(emails):
"""
Performs summarization of emails
"""
n_emails = len(emails)
summary = [None]*n_emails
print('Preprecesing...')
preprocess(emails)
print('Splitting into sentences...')
split_sentences(emails)
print('Starting to encode...')
enc_emails = skipthought_encode(emails)
print('Encoding Finished')
for i in range(n_emails):
enc_email = enc_emails[i]
n_clusters = int(np.ceil(len(enc_email)**0.5))
kmeans = KMeans(n_clusters=n_clusters, random_state=0)
kmeans = kmeans.fit(enc_email)
avg = []
closest = []
for j in range(n_clusters):
idx = np.where(kmeans.labels_ == j)[0]
avg.append(np.mean(idx))
closest, _ = pairwise_distances_argmin_min(kmeans.cluster_centers_,\\
enc_email)
ordering = sorted(range(n_clusters), key=lambda k: avg[k])
summary[i] = ' '.join([emails[i][closest[idx]] for idx in ordering])
print('Clustering Finished')
return summary
4.结果
当邮件中包含多个句子时,此种摘要方法效果较好。对于三句话的邮件,摘要可能是由两句话组成,但三个句子传达的意义可能完全不同,省略掉任何一个句子的信息都是不合适的。基于此,提取法通常并不适合短文本摘要。监督式 Seq2Seq 模型更适合这项任务。
使用 Skip-Thought 方法进行向量化的一个缺点是模型可能需要训练很长时间。尽管在训练
2
−
3
2-3
2−3 天后获得了可接受的结果,但 Skip-Thought 模型在丹麦语语料上训练了大约一周。该模型是按句子长度归一化的,所以成本在迭代期间波动很大。
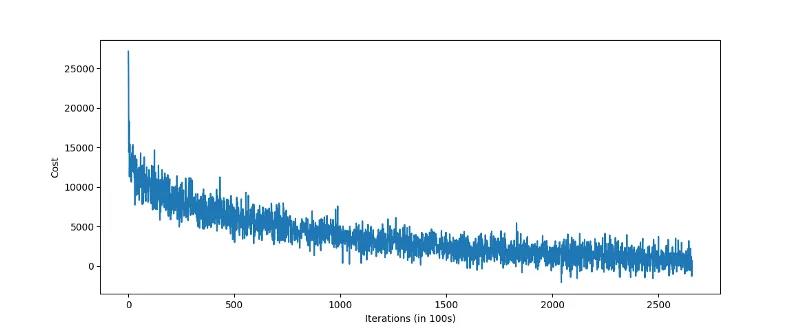
可以查看数据集中最相似的句子,了解 Skip-Thoughts 模型的效果。
例 1 1 1:
I can assure you that our developers are already aware of the issue and are trying to solve it as soon as possible.I have already forwarded your problem report to our developers and they will now investigate this issue with the login page in further detail in order to detect the source of this problem.
例 2 2 2:
I am very sorry to hear that.We sincerely apologize for the inconvenience caused.
例 3 3 3:
Therefore, I would kindly ask you to tell me which operating system you are using the app on.Can you specify which device you are using as well as the android or ios version it currently has installed?
5.优化
通过增加模型的复杂性可以进行一些相关的改进:
Quick-Thought Vectors是Skip-Thoughts方法的最新进展,可以显著减少训练时间并提高性能。Skip-Thought编码表示的维数为 4800 4800 4800。由于维数灾难,这些高维向量不适合聚类。在使用Autoencoder或LSTM-Autoencoder进行聚类之前,可以进行降维。- 可以通过训练解码器网络来实现 生成摘要,而不是提取摘要。解码器网络可以将聚类中心的编码表示转换回自然语言表示的句子。这样的解码器可以通过
Skip-Thoughts编码器生成的数据进行训练。但是,如果我们希望解码器生成合理且语法正确的句子,则需要对解码器进行非常仔细的超参调整和架构决策。
以上是关于自然语言处理基于句子嵌入的文本摘要算法实现的主要内容,如果未能解决你的问题,请参考以下文章