如何加速大模型开发?技术方案拆解来了:昇思MindSpore技术一览
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何加速大模型开发?技术方案拆解来了:昇思MindSpore技术一览相关的知识,希望对你有一定的参考价值。
随着ChatGPT爆火出圈,狂飙之势从22年底持续到23年初,与以往的技术突破不同的是,此次的大模型不仅被技术界关注,而且备受投资界、产业界和大众消费者的追捧,使它成为历史上最快月活过亿的现象级应用,继而引发全球科技巨头的AI竞赛。
大模型的高智能化离不开对模型的大规模预训练,这背后需要强大的AI框架作底层支持。面对动辄千亿级参数的大模型,如何使能广大开发者和用户进行开发,在当前大模型研究分秒必争之时弯道超车?且让我们顺着大模型技术的方案拆解,一探昇思MindSpore AI框架的技术能力。
预训练大模型的开发之路
大规模预训练——GPT3与鹏程.盘古
2020年,OpenAI祭出了远超同期所有预训练模型的大杀器GPT3。凭借着1750亿参数量,300B Token的预训练,GPT3展现出非常强悍的自然语言处理能力,包括:
文本生成:根据Prompt来续写(补全)句子。
上下文学习(In-context Learning): 遵循给定任务的几个示例,然后为新的测试用例生成解决方案。
世界知识(World Knowledge): 包括事实性知识和常识。
此时与GPT3同量级的大规模预训练语言模型仍是国内外难以逾越的大山。2021年4月,基于昇思MindSpore AI框架的多维度自动混合并行能力,以鹏城实验室为首的联合科研团队在大规模AI算力平台鹏城云脑II上,训练出业界首个2000亿参数、以中文为核心的预训练生成语言模型鹏程.盘古。联合团队从开源开放数据集、common crawl网页数据、电子书等收集了近80TB原始数据,搭建了面向大型语料库预处理的分布式集群,通过数据清洗过滤、去重、质量评估等处理流程,构建了一个约1.1TB大小的高质量中文语料数据集,经统计Token数量约为250B规模。
凭借着与GPT3相同量级的参数量,鹏程.盘古预训练模型拥有不逊于GPT3的上下文学习和世界知识能力。
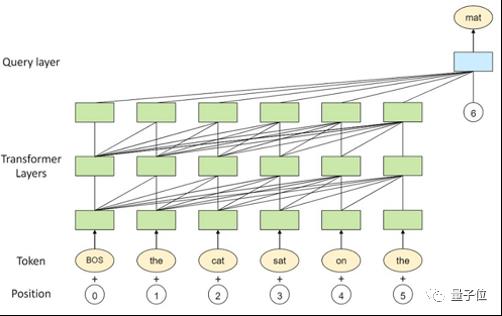
△图1 鹏程.盘古模型架构
利用昇思MindSpore AI框架的自动并行能力,开发者只需一行代码就能实现模型自动切分、分布式并行计算,省却大量复杂设计,在大集群上高效训练千亿至万亿参数模型。关于昇思MindSpore的自动并行能力,这里先按下不表,让我们继续看下一个技术要素。
思维链的必经之路——Code预训练
思维链(Chain of Thoughs,即链式思维推理)是大模型能够拥有拟人化对话能力的关键。在GPT3之后,思维链能力开始被认为是通过few shot learning进行激发,后续有“lets think step by step”的zero shot prompt进一步触发了该能力。但是此时的大模型仍旧仅限于在各类数据集上呈现弱思维链能力。
直到代码数据的预训练模型出现并融入到自然语言预训练模型中,大模型的思维链接能力跃上新的台阶。下图是OpenAI从GPT3以来的演进路线图。左侧的分支是代码大模型的持续演进,一直到code-davinci-002将LM和Code训练进行融合,再加入instruct tuning,最终催生出耳熟能详的ChatGPT。
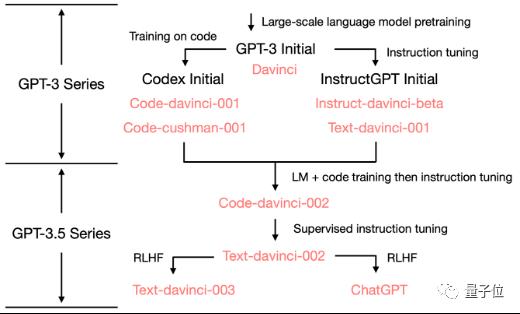
△图2 ChatGPT演进路线
2022年9月,清华大学团队基于昇思MindSpore 1.7研发了CodeGeeX代码预训练大模型,并使用鹏城实验室的大规模AI算力平台(鹏城云脑II)进行训练。CodeGeeX的训练语料由两部分组成:第一部分是开源代码数据集,The Pile与CodeParrot;第二部分是补充数据,直接从GitHub开源仓库中爬取Python、Java、C++代码。整个代码语料含有23种编程语言、总计1587亿个标识符(不含填充符)。
在开发与训练过程中,清华大学与昇思MindSpore团队深度合作,实现了一系列算子融合优化,包括单元素算子融合、层归一化算子融合、FastGelu与矩阵乘法融合、批量矩阵乘法与加法融合等, 为训练速度带来了显著提升。
撬动人类的智慧——RLHF与PPO
ChatGPT令人震惊的能力在于其能够真正拟人化地进行对话,生成内容更加符合人类的认知和价值观。在大模型已经具备充足的世界知识、上下文学习能力和思维链能力的情况下,虽然可以在各大NLP数据集持续刷榜,但是仍旧存在一个问题——与人类的表达习惯差异巨大。而ChatGPT的前身InstructGPT,向我们展示了人类反馈加入模型训练的循环当中,所能呈现的巨大改变,那就是RLHF(Reinforcement Learning from Human Feedback,即使用人类反馈强化学习)。
RLHF技术主要分为如下4个步骤:
1) 无监督预训练: 预训练一个语言模型如GPT-3。
2) 有监督的微调:生成一组Prompt,以及对每个Prompt的人类反馈。即一个由对组成的训练数据集。然后对预训练的模型进行微调。
3) 训练“人类反馈”的奖励模型:建立一个奖励模型,对预训练语言模型输出进行评分。首先给定一组Prompt,机器生成对这些指令的Answer,并由人类对其质量进行评分或排名。使用这个数据集来训练一个奖励模型,为任何对输出一个质量分数。
4) 训练一个基于奖励模型进行优化的强化学习策略。
下图是RLHF的核心PPO算法的示意图:
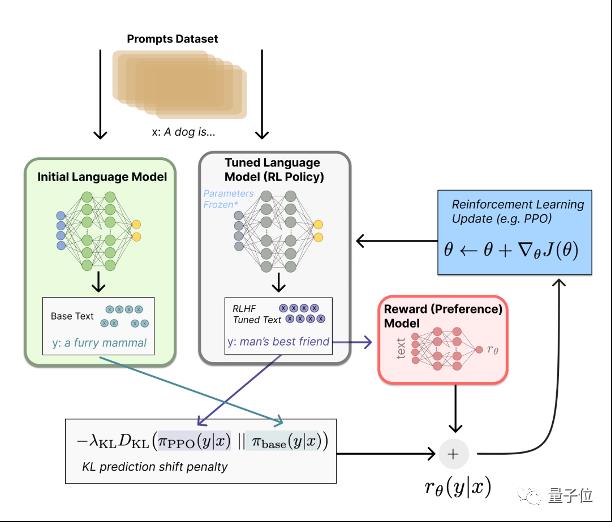
△图3 PPO算法逻辑
针对RLHF所需的强化学习算法,昇思MindSpore进行了布局,发布MindSpore Reinforcement Learning套件,为编写强化学习算法提供了简洁的API抽象,将算法与部署和调度解耦;将强化学习算法转换为一系列编译后的计算图,然后由昇思MindSpore AI框架在昇腾AI处理器、CPU、GPU上高效运行。目前MindSpore Reinforcement Learning套件提供下述能力:
1) 提供丰富的强化学习算法:当前已支持15+经典强化学习算法,涵盖Model-free/Model-based/Offline-RL/Imitation Learning,单智能体/多智能体,连续/离散动作空间,Episodic/Non-Episodic等算法;接入Mujoco、MPE、StarCraft2、DeepMind Control等常用模拟环境。
2) 专注高性能训练:通过计算图和ReplayBuffer加速、异步环境并行和高性能领域组件,已支持算法的平均吞吐率相比主流框架提升120%。
3) 支持大规模分式训练:通过将强化学习算法分割成多个数据流片段(Fragmented Dataflow Graphs),并映射到异构设备上高效执行,对比业界主流框架实现了3~5倍的性能提升。
昇思MindSpore使能大模型历程
随着AI技术的发展,预训练大模型成为世界各科技强国竞争的焦点。预训练大模型率先在自然语言处理领域取得突破性的进展,并迅速拓展到涉及图像、视频、图形、语言等跨媒体推理的各类任务和大量的商业应用之中,展现了巨大的发展潜力。在过去的几年,产业界基于昇思MindSpore先后发布了一系列有影响力的大模型,下图为这些大模型的训练时间轴。
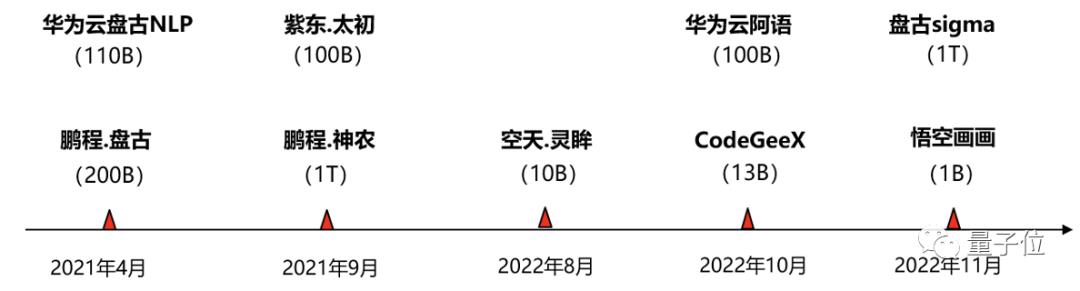
△图4 昇思MindSpore大模型历程
上图模型结构涉及Transformer Encoder、Transformer Decoder、MOE、乃至Clip与Diffusion,均基于昇思MindSpore AI框架训练。
昇思MindSpore具备丰富的并行能力,能轻松完成4096卡集群、万亿参数规模的训练任务,因此支撑了国内多个领域首发大模型的训练,这些大模型涉及知识问答、知识检索、知识推理、阅读理解、文本/视觉/语音多模态、生物制药、遥感、代码生成等。
大模型的底座——昇思MindSpore的分布式并行能力
在梳理完ChatGPT的技术方案和昇思MindSpore的大模型历程之后,我们再深入展开昇思MindSpore AI框架支撑一众大模型的核心——分布式并行能力。
分布式训练
昇思MindSpore支持当前主流的分布式训练范式并开发了一套自动混合并行解决方案,提供以下关键技术:
1)数据切片预处理:对训练数据进行任意维度切片后再导入到设备进行训练;
2)算子级并行:对正向网络中的每个算子都独立建模,每个算子可以拥有不同的切分策略;
3)优化器并行:将数据并行的参数副本切分到多个设备上,以节省内存占用;
4)Pipeline并行:将神经网络中的计算图切分成多个阶段(Stage),再把阶段映射到不同的设备上,使得不同设备去计算神经网络的不同部分;
5)MOE并行:为每个专家分配专门的计算任务,不同的专家可以托管在不同的设备上;
6)多副本并行:在一个迭代步骤中,将一个训练batch拆分成多个micro-batch,将模型并行通信与计算进行并发;
7)异构并行:将算子分配到异构硬件上执行,充分利用硬件资源,提升整体训练吞吐量;
8)正向重计算:在正向计算时,不保存占用大量内存的中间输出结果,而是保存占用少量内存的输入;而在反向计算时,根据输入重新计算正向输出,从而大大削减正向计算累积的内存峰值;
9)全局内存复用:对计算图进行静态编译寻优得到最优内存复用策略;
相较于业界的深度学习框架或分布式并行框架,昇思MindSpore在分布式关键技术上,支持能力范围广、自动化程度高、易用性好,具备如下优势:
1)支持的模型类型更丰富(Transformer、超分图像、推荐等),通用性更强,而像业界Megatron框架则是面向Transformer定制的框架;
2)相同算力和网络下,丰富的并行策略可实现更大的计算通信比,性能更优(相同硬件平台(V100、A100),性能超越Megatron 15%);
3)并行策略丰富,无需手动切分,大模型开发和调优效率优于业界;
分布式推理
相较于训练,推理对计算性能的要求更高。如何在集群上实现高效快速的大模型推理,是目前各种框架研究的一个重点和难点。为了解决上述问题,昇思MindSpore提出了分布式推理+增量推理的解决方案,使用数据并行、模型并行、流水并行等多维度混合并在大集群上面进行推理。此外,由于Transformer Decoder类自回归语言模型,在传统的推理模式下存在很多重复计算,昇思MindSpore提供的增量推理能力能够省掉这些重复计算,增强推理效率。
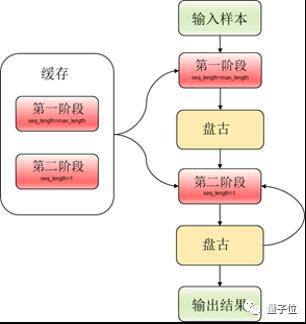
△图5 增量推理流程图
如上图所示,第一阶段将使用完整输入推理,保存当前字(词)对应的向量。在第二阶段,输入仅为上一步推理得到的字(词),然后将本步推理得到的向量与保存下来的前序向量拼接,作为本步推理的完整向量,得到本步的输出字(词)。重复以上两个阶段。
极简易用的大模型训练——大模型套件
在现有的大模型开发过程中,用户经常会发现SOTA基础模型代码非模块化从而影响进一步的创新开发。不仅如此,用户在模型实现中,经常找不到对应的SOTA模型以及相应的下游任务,从而加长了开发周期,影响论文或项目的进度。为了解决这些痛点,基于昇思MindSpore的大模型套件——MindSpore Transformers应声而出。
MindSpore Transformers是基于昇思MindSpore的深度学习大模型开发套件,其目标是构建一个大模型训练、微调、评估、推理、部署的全流程开发套件。套件覆盖了CV、NLP等AIGC的热门领域,提供模型生命周期中的全流程快速开发能力,支持开箱即用,并具有四个特点:
MindSpore Transformers中提供了非常丰富的预置模型,包含了当下典型的预训练大模型(Bert、T5、VIT等),涵盖当下CV、NLP等AIGC的热门领域。同时,套件也包含了丰富的下游微调任务,精度与SOTA基本持平。
MindSpore Transformers中提供了统一的开发范式。套件开放了Trainer、pipeline等特性接口,实现模块化、配置化的开发,大大提高典型模型(尤其是基于transformer结构的网络)的开发效率。模型部署方面, 套件支持昇腾AI基础软硬件平台,提供了一键云上部署接口。
MindSpore Transformers提供了统一的对外接口。在现有版本中,套件和业界流行的Huggingface 接口保持一致,用户可以一键切换,从而极大地降低代码迁移的成本。
MindSpore Transformers套件天然包含昇思MindSpore AI框架自身优势,包含多维度并行(模型并行、流水线并行、优化器并行、多副本并行等)、图算融合等能力,可以在模型训练时有效地提升内存使用效率和速度,帮助用户快速训练百亿、千亿甚至是万亿级别的模型。
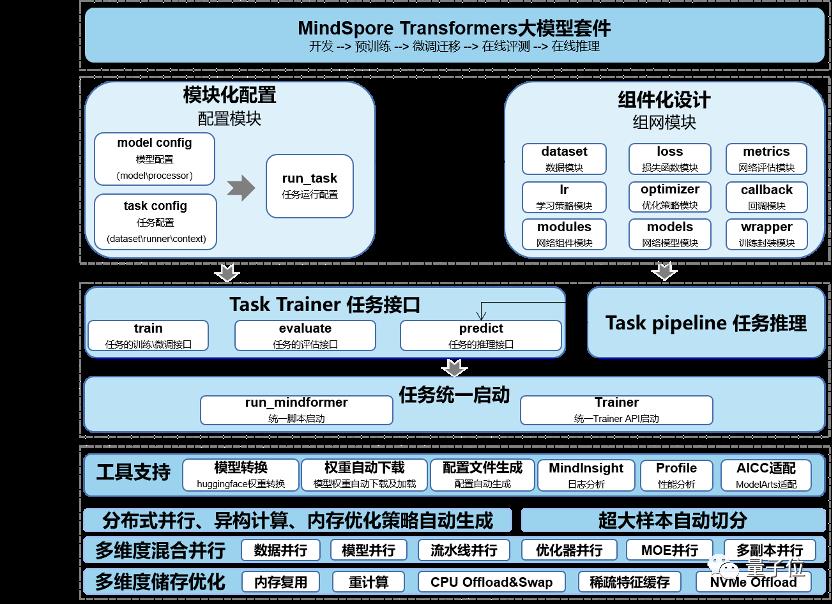
△图6 MindSpore Transformers 架构图
通过以上技术拆解和案例可以看出,昇思MindSpore发展至今,已经具备了支持大模型开发所需的各项核心技术,同时提供了一整套高效、易用的大模型使能套件,形成了端到端的使能大模型开发能力。昇思MindSpore AI框架为助力大模型创新、繁荣AI产业生态铺就了一条信心之路。

△图7 昇思MindSpore原生支持大模型的能力优势
欢迎使用昇思MindSporeAI框架:
https://mindspore.cn/
https://gitee.com/mindspore/mindformers
引用:
[1]Zeng W, Ren X, Su T, et al. Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation[J]. arXiv preprint arXiv:2104.12369
[2]https://yaofu.notion.site/GPT-3-5-360081d91ec245f29029d37b54573756
[3]https://huggingface.co/blog/rlhf
[4] https://aijishu.com/a/1060000000222564
[5]https://gitee.com/mindspore/mindformers/wikis/%E7%89%B9%E6%80%A7%E8%AE%BE%E8%AE%A1%E6%96%87%E6%A1%A3
以上是关于如何加速大模型开发?技术方案拆解来了:昇思MindSpore技术一览的主要内容,如果未能解决你的问题,请参考以下文章
三位学霸博士生,攻克昇腾AI创新大赛昇思赛道五道量子计算赛题
开源ChatGPT要来了;软件2.0智能革命;GLMDiffusion模型大加速