7张图揭晓RocketMQ存储设计的奥妙
Posted 中间件兴趣圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了7张图揭晓RocketMQ存储设计的奥妙相关的知识,希望对你有一定的参考价值。
RocketMQ作为一款基于磁盘存储的中间件,具有无限积压能力,并提供高吞吐、低延迟的服务能力,其最核心的部分必然是它优雅的存储设计。
温馨提示:本文节选自新上市《RocketMQ技术内幕》第二版本,一个最大的改变就是在进入源码分析之前,首先通过图文的方式,提炼出RocketMQ的核心工作机制,降低源码阅读的难度,引发思考。
1、存储概述
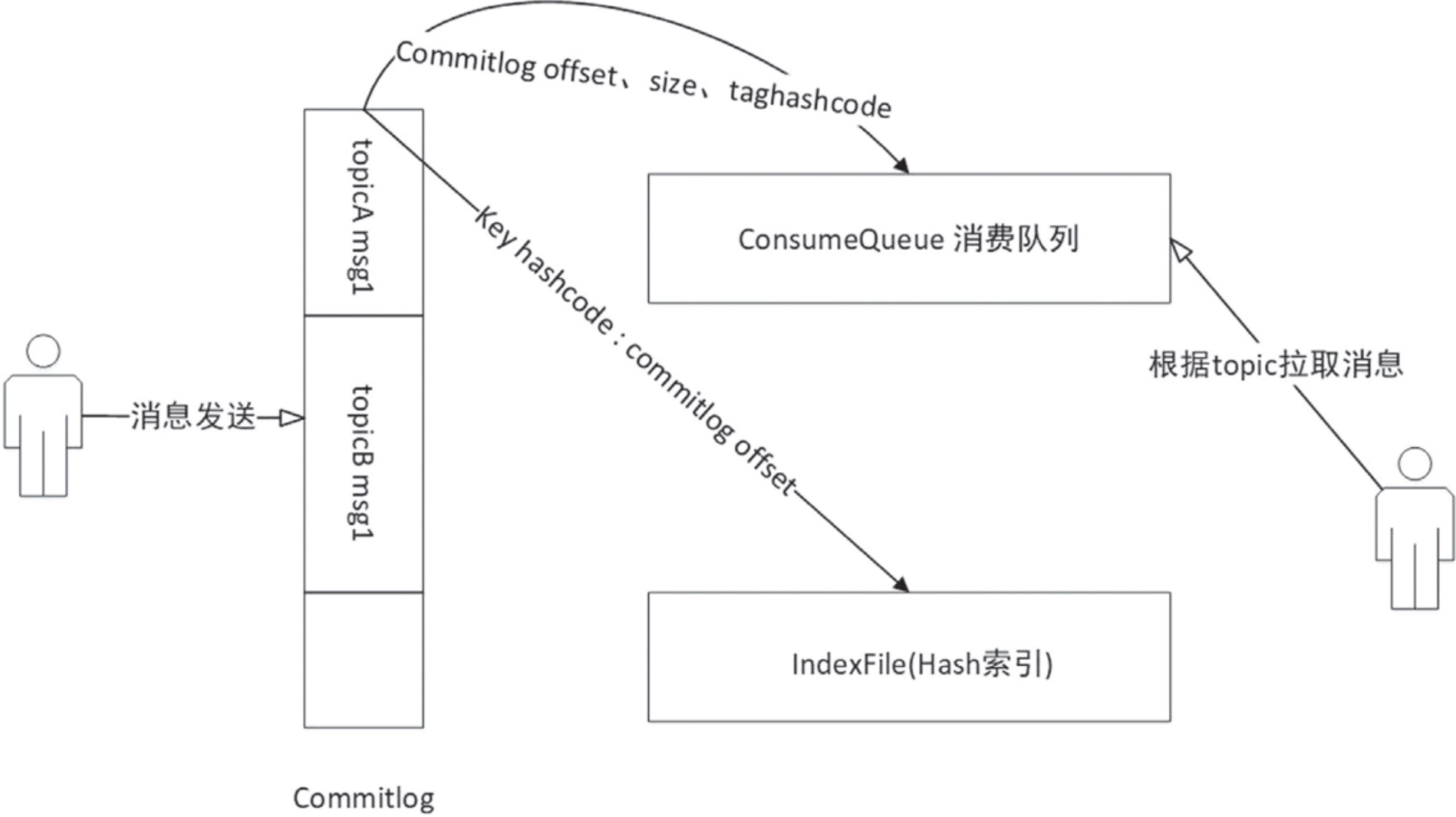
RocketMQ存储的文件主要包括Commitlog文件、ConsumeQueue文件、Index文件。
RocketMQ将所有主题的消息存储在同一个文件中,确保消息发送时按顺序写文件,尽最大能力确保消息发送的高可用性与高吞吐量。
但消息中间件一般都是基于主题的订阅与发布模式,消息消费时必须按照主题进行帅选消息,显然从Commitlog文件中按照topic去筛选消息会变得及其低效,为了提高根据主题检索消息的效率,RocketMQ引入了ConsumeQueue文件,俗成消费队列文件。
关系型数据库可以按照字段属性进行记录检索,作为一款主要面向业务开发的消息中间件,RocketMQ也提供了基于消息属性的检索能力,底层的核心设计理念是为Commitlog文件建立哈希索引,并存储在Index文件中。
在RocketMQ中顺序写入到Commitlog文件后,ConsumeQueue与Index文件都是异步构建的,其数据流向图如下:
2、存储文件组织方式
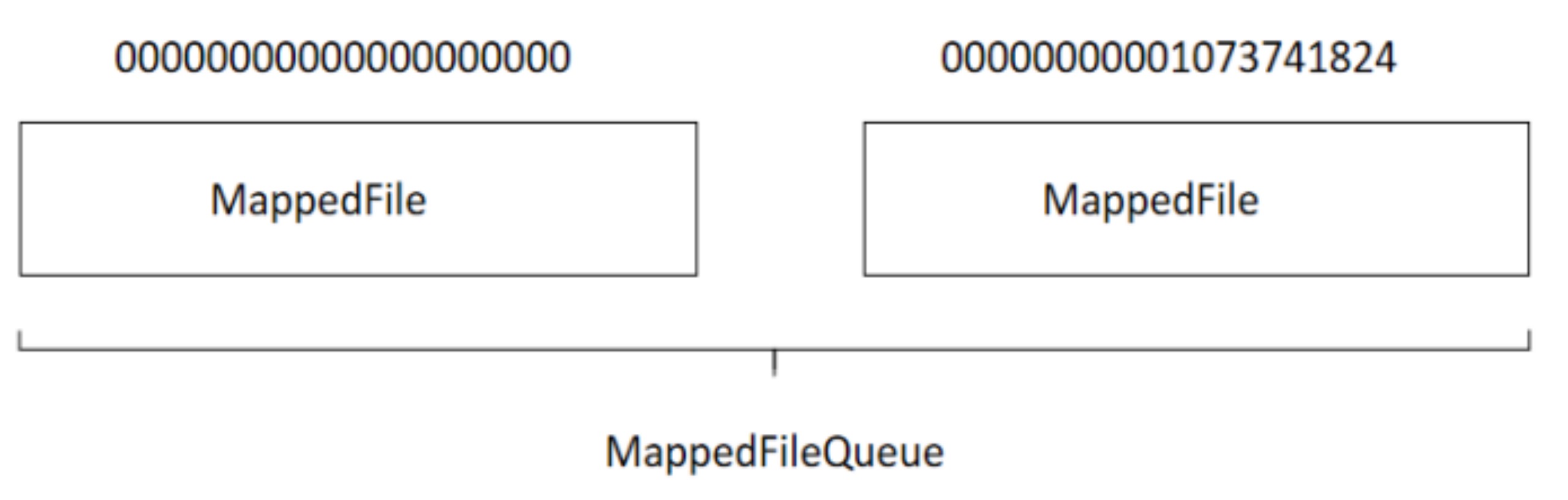
RocketMQ在消息写入过程中追求极致的磁盘顺序写。所有主题的消息全部写入一个文件,即Commitlog文件。所有消息按抵达顺序依次追加到文件中,消息一旦写入,不支持修改。Commitlog文件的具体布局如下图所示:
基于文件编程与基于内存编程有一个很大的不同是在基于内存的编程模式中我们有现成的数据结构,例如 List、HashMap,对数据的读写非常方便,那么一条一条消息存入文件Commitlog后,该如何查找呢?
正如关系型数据会为每一条数据引入一个ID字段,在基于文件编程的模型中,也会为一条消息引入一个身份标志:消息物理偏移量,即消息存储在文件的起始位置。
正是有了物理偏移量的概念,Commitlog的文件名命名也是极具技巧性,使用了存储在该文件的第一条消息在整个Commitlog文件组中的偏移量来命名,例如第一个 Commitlog文件为 0000000000000000000,第二个文件为00000000001073741824,然后依次类推。
这样做的好处是给出任意一个消息的物理偏移量,例如消息偏移量为 73741824,可以通过二分法进行查找,快速定位这个文件在第一个文件中,然后用消息的物理偏移量减去该文件的名称所得到的差值,就是在该文件中的绝对地址。
Commitlog文件的设计理念是追求极致的消息写,但我们知道消息消费模型是基于主题的订阅机制,即一个消费组是消费特定主题的消息。如果根据主题从commitlog文件中检索消息,我们会发现这绝不是一个好主意,只能从文件的第一条消息逐条检索,其性能可想而知,故为了解决基于topic的消息检索问题,RocketMQ引入了consumequeue文件,consumequeue的结构如下图所示。

ConsumeQueue文件是消息消费队列文件,是Commitlog文件基于Topic的索引文件,主要用于消费者根据Topic消费消息,其组织方式为/topic/queue,同一个队列中存在多个文件。
Consumequeue的设计极具技巧,每个条目长度固定(8字节commitlog物理偏移量、4字节消息长度、8字节tag hashcode)。
这里不是存储tag的原始字符串,而选择存储hashcode,目的就是确保每个条目的长度固定,可以使用访问类似数组下标的方式快速定位条目,极大地提高了ConsumeQueue文件的读取性能。
试想一下,消息消费者根据topic、消息消费进度(consumeuqe逻辑偏移量),即第几个Consumeque条目,这样的消费进度去访问消息的方法为使用逻辑偏移量logicOffset * 20即可找到该条目的起始偏移量(consumequeue文件中的偏移量),然后读取该偏移量后20个字节即得到一个条目,无须遍历consumequeue文件。
RocketMQ与Kafka相比具有一个强大的优势,就是支持按消息属性检索消息,引入consumequeue文件解决了基于topic查找的问题,但如果想基于消息的某一个属性查找消息,consumequeue文件就无能为力了。
RocketMQ引入了Index索引文件,实现基于文件的哈希索引。IndexFile的文件存储结构如下图所示:
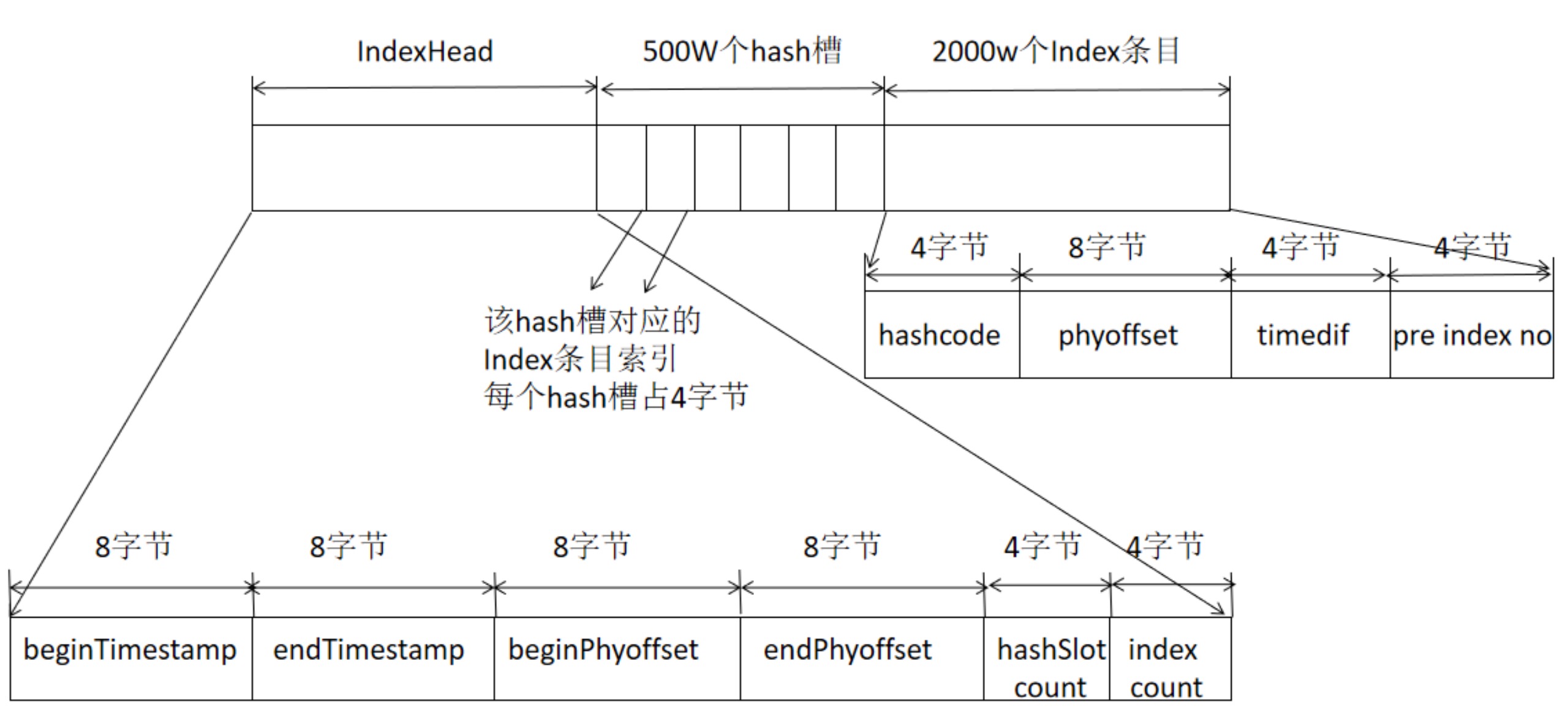
IndexFile文件基于物理磁盘文件实现Hash索引。其文件由40字节的文件头、500万个哈希槽,每个哈希槽4个字节,最后由2000万个Index条目,每个条目由20个字节构成,分别为4字节索引key的hashcode、8字节消息物理偏移量、4字节时间戳、4字节的前一个Index条目(哈希冲突的链表结构)。
即建立了索引Key的hashcode与物理偏移量的映射关系,根据key先快速定义到commitlog文件,关于Hash索引具体到工作机制,可以参考笔直《RocketMQ技术内幕》第二版4.5.3节的详细介绍。
3、顺序写
基于磁盘的读写,提高其写入性能的另外一个设计原理是磁盘顺序写。
磁盘顺序写广泛用在基于文件的存储模型中,大家不妨思考一下 mysql Redo 日志的引入目的,我们知道在 MySQL InnoDB 的存储引擎中,会有一个内存 Pool,用来缓存磁盘的文件块,当更新语句将数据修改后,会首先在内存中进行修改,然后将变更写入到 redo 文件(刷写到磁盘),然后定时将InnoDB内存池中的数据刷写到磁盘。
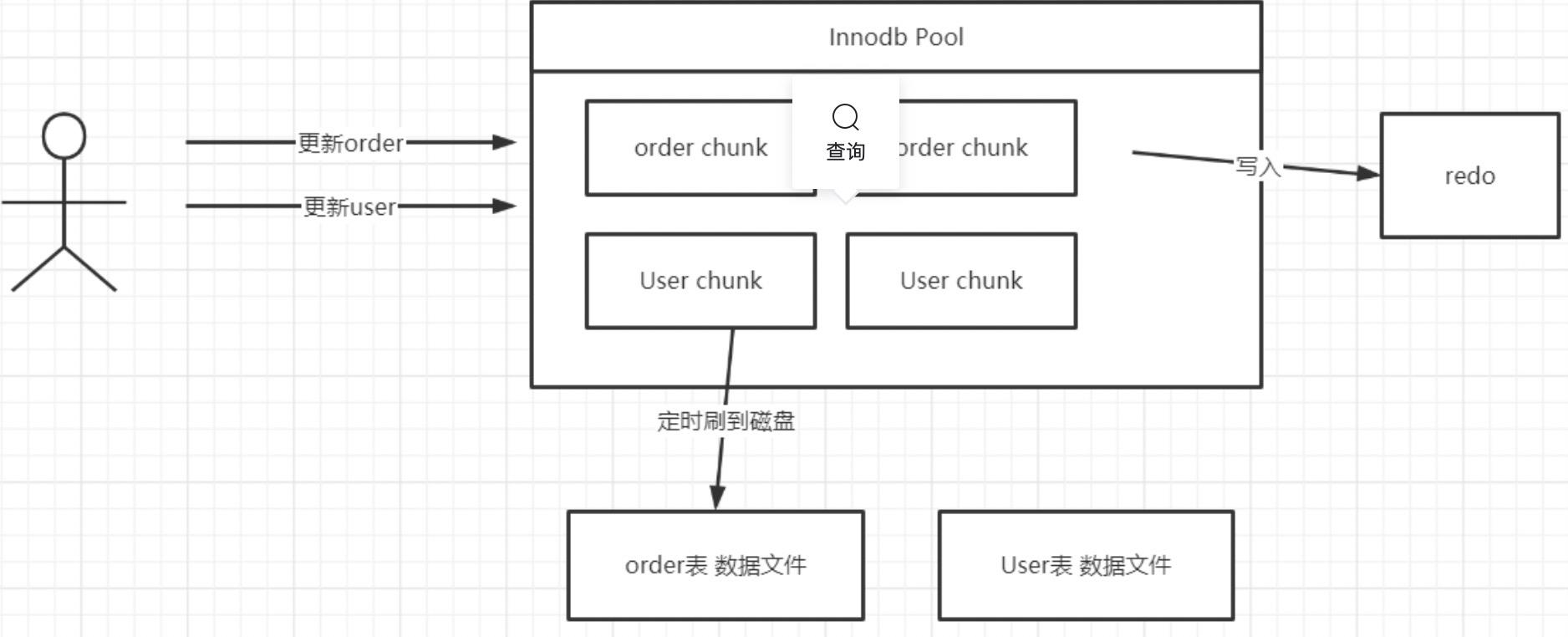
为什么不一有数据变更,就直接更新到指定的数据文件中呢?以MySQL InnoDB中一个库存在上千张,每一个张的数据会使用单独的文件存储,如果每一个表的数据发生变更,就刷写到磁盘,就会存在大量的随机写入,性能无法得到提升,故引入一个redo文件,顺序写redo文件,从表面上多了一步刷盘操作,但由于是顺序写,相比随机写,带来的性能提升是非常显著的。
4、内存映射机制
虽然基于磁盘的顺序写可以极大提高IO的写效率,但如果基于文件的存储采用常规的JAVA文件操作API,例如 FileOutputStream等,其性能提升会很有限,RocketMQ引入了内存映射,将磁盘文件映射到内存中,以操作内存的方式操作磁盘,性能又提升了一个档次。
在JAVA中可通过FileChannel的map方法创建内存映射文件。
在Linux服务器中由该方法创建的文件使用的就是操作系统的pagecache,即页缓存。
Linux操作系统中的内存使用策略时会尽可能地利用机器的物理内存,并常驻内存中,就是所谓的页缓存。在操作系统的内存不够的情况下,采用缓存置换算法,例如LRU将不常用的页缓存回收,即操作系统会自动管理这部分内存。
如果RocketMQ Broker进程异常退出,存储在页缓存中的数据并不会丢失,操作系统会定时将页缓存中的数据持久化到磁盘,做到数据安全可靠。不过如果是机器断电等异常情况,存储在页缓存中的数据就有可能丢失。
5、灵活多变的刷盘策略
有了顺序写和内存映射的加持,RocketMQ的写入性能得到了极大的保证,但凡事都有利弊,引入了内存映射和页缓存机制,消息会先写入到页缓存,此时消息并没有真正持久化到磁盘。那么broker收到客户端的消息发送后,是存储到页缓存中就直接返回成功,还是要持久化到磁盘中才返回成功呢?
这是一个“艰难”的抉择,是在性能与消息可靠性方面进行权衡。为此,RocketMQ提供了多种策略:同步刷盘、异步刷盘。
5.1 同步刷盘
同步刷盘在RocketMQ的实现中成为组提交,并不是每一条消息都必须刷盘。其设计理念如图所示:
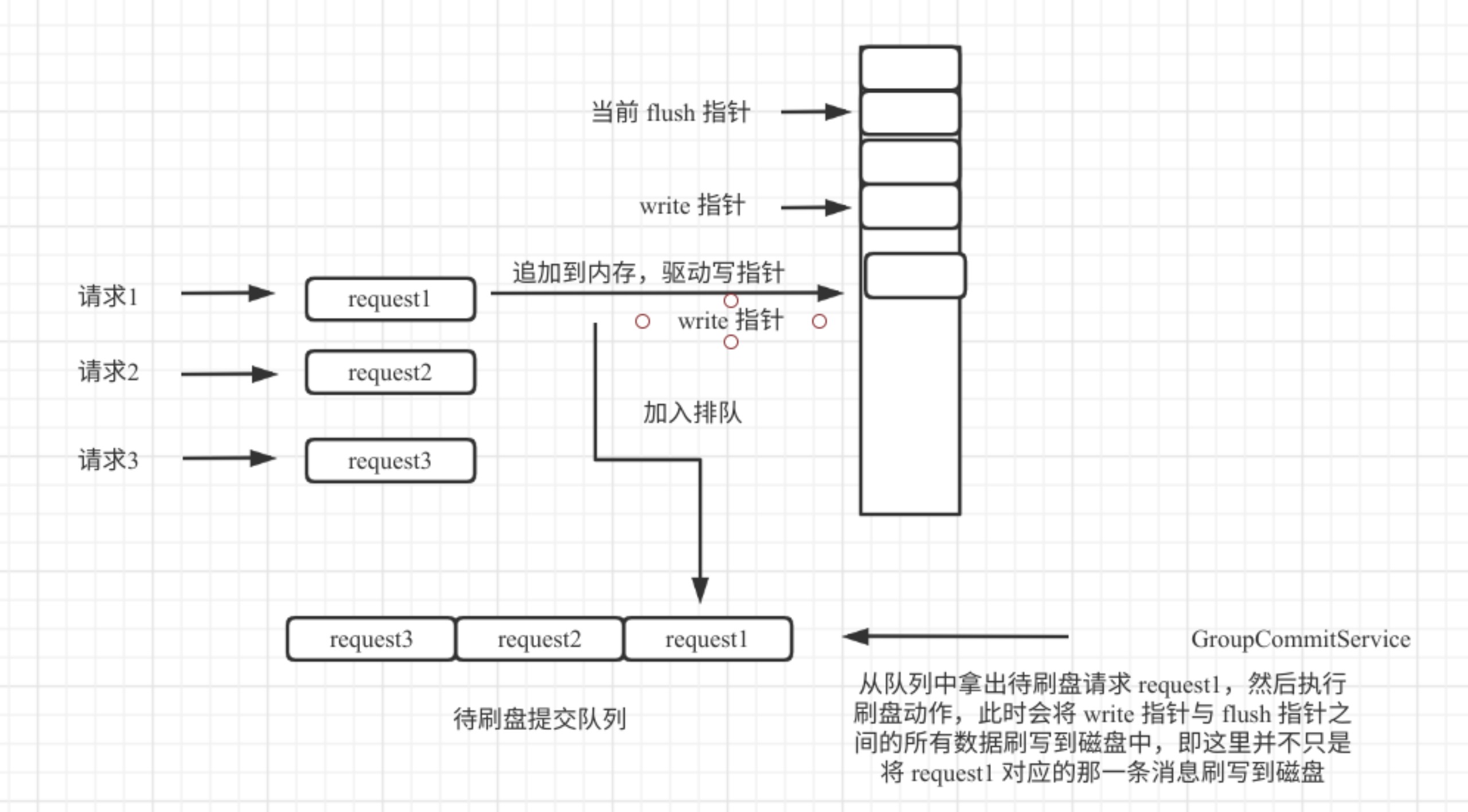
采用同步刷盘,每一个线程将数据追到到内存后,并向刷盘线程提交刷盘请求,然后会阻塞;刷盘线程从任务队列中获取一个任务,然后触发一次刷盘,但并不只刷与请求相关的消息,而是会直接将内存中待刷盘的所有消息一次批量刷盘,然后就可以唤醒一组请求线程,实现组刷盘。
5.2 异步刷盘
同步刷盘的优点是能保证消息不丢失,即向客户端返回成功就代表这条消息已被持久化到磁盘,即消息非常可靠,但这是以牺牲写入响应延迟性能为代价的,由于RocketMQ的消息是先写入 pagecache,故消息丢失的可能性较小,如果能容忍一定几率的消息丢失,可以考虑使用异步刷盘。
异步刷盘指的是broker将消息存储到pagecache后就立即返回成功,然后开启一个异步线程定时执行FileChannel的forece方法,将内存中的数据定时刷写到磁盘,默认间隔为500ms。
6、内存级读写分离
RocketMQ为了降低pagecache的使用压力引入了transientStorePoolEnable机制,即内存级别的读写分离机制。
默认情况下RocketMQ将消息写入pagecache,消息消费时从pagecache中读取,这样在高并发时pagecache的压力会比较大,容易出现瞬时broker busy,故RocketMQ还引入了transientStorePoolEnable,将消息先写入堆外内存并立即返回,然后异步将堆外内存中的数据提交到pagecache,再异步刷盘到磁盘中。其工作机制如下图所示:

消息在消费读取时不会尝试从堆外内存中读,而是从pagecache中读取,这样就形成了内存级别的读写分离,即消息写入时主要面对堆外内存,而读消息时主要面对pagecache。
该方案的优点是消息是直接写入堆外内存,然后异步写入pagecache。相比每条消息追加直接写入pagechae,其最大的优势是将消息写入pagecache操作批量化。
该方案的缺点是如果由于某些意外操作导致Broker进程异常退出,那么存储在堆外内存的数据会丢失,但如果是放入pagecache,broker异常退出并不会丢失消息。
本文就介绍到这里了,也欢迎大家关注我的公众号,加我微信dingwpmz,共同探讨交流。
以上是关于7张图揭晓RocketMQ存储设计的奥妙的主要内容,如果未能解决你的问题,请参考以下文章
Alibaba中间件技术系列「RocketMQ技术专题」系统服务底层原理以及高性能存储设计分析
精华推荐 | 深入浅出RocketMQ原理及实战「性能原理挖掘系列」透彻剖析贯穿RocketMQ的系统服务底层原理以及高性能存储设计挖掘深入
精华推荐 | 深入浅出RocketMQ原理及实战「性能原理挖掘系列」透彻剖析贯穿RocketMQ的系统服务底层原理以及高性能存储设计挖掘深入