不跟风 ChatGPT,Google AI 2022 年都在忙什么?
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不跟风 ChatGPT,Google AI 2022 年都在忙什么?相关的知识,希望对你有一定的参考价值。

作者 | Marian Croak 翻译&整理 | Carol
出品 | AI科技大本营
谷歌发布了2022年在AI领域取得的巨大突破,主要包括大语言模型 (LLM) 和文本生图两个领域。
相较多年前提出的“不作恶”口号,谷歌将今后发展人工智能的理念进一步提升至“负责任”上。包括负责任的AI研究、负责任的产品研究、工具和技术,以及在社会公益方面做出的贡献。

优化机器学习的系统稳定性
作为AI技术界的扛把子,机器学习仍然是最重要的算法,对谷歌来说也不例外,不仅有像Tensorflow、Keras等开发者常用框架。在包括谷歌搜索、You Tube、谷歌地图等多项业务实现中都不乏机器学习的影子。
通过多年实践,谷歌发现当机器学习系统应用于现实世界时,可能无法按照预期设想的路径运行,从而降低了实际应用中的收益。具体来看,机器学习的数款应用中,模型常常不够明确。这意味着,即使模型在训练中的表现良好,也不能保证在新的应用情境中同样稳定。毕竟在模型中的虚拟相关关系,在实际中会产生副作用,难以推而广之。
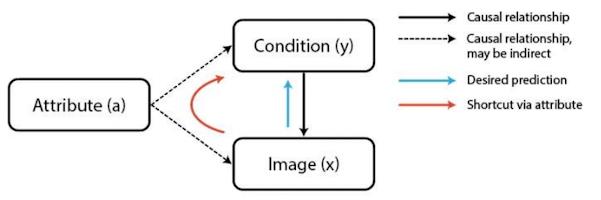
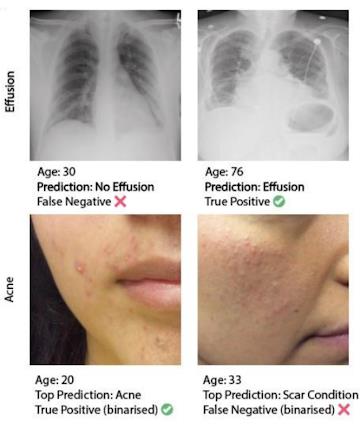
年龄因素对AI医学诊断的影响
通过调查目前机器学习研究人员的评估实践情况,针对常见的机器学习陷阱,谷歌改进了评估标准。对于导致机器学习系统缺乏稳定性,并对敏感信息过度依赖的因果“捷径”,公司对这一技术进行了优化。
同时,为了更加深入了解鲁棒性产生的原因和提出解决方案,谷歌决定进行更加深入的领域模型设计研究,其中包括机器视觉变化器的鲁棒性,研发了新的负面数据增强技术来提高鲁棒性。在自然语言处理任务中,谷歌这一年研究了不同的数据分布如何改进不同群体之间的泛化,以及集成和预训练模型如何提供帮助。
此外,谷歌机器学习工作的另一个关键部分涉及开发技术,以建立更具包容性的模型。

聚焦AI大模型对社会的影响
在产品研究的“负责任”表现上,主要聚焦于“公平”。对于一些社会中的敏感议题,图像技术往往缺少对公平的判断。当然,归根结底这一点的主要原因在于人为因素。
通过与哈佛大学教授和社会学家埃利斯·蒙克博士的合作,谷歌在皮肤颜色鉴别上发布了“蒙克肤色(MST)量表”,见下图。

为了改进视频内容审核的质量,公司开发了新的方法来协助人工评分,将注意力集中在更有可能包含违反政策的长视频片段上。
此外,谷歌同时利用过去对自然语言反事实数据增强的研究来改进安全搜索,将意外的和令人震惊的搜索结果减少 30%,尤其是与种族、性取向和性别相关的搜索。
在大模型领域,虽然相较DELL-2和ChatGPT,谷歌的GLaM、 PaLM、 Imagen略显沉寂,但依然强调其“Responsible AI ”的属性,并将其作为开发过程的一部分,创建了模型卡和数据卡,以及Responsible AI 基准,从而对大模型的应用进行社会影响力的分析。
与此同时,指令的微调会给负责任的人工智能基准带来更多改进,比如对人工数据标注进行更多以人为本的考虑,包括评分者之间产生的分歧和评分者的多样性设定。

提供更负责任的数据
出于提供更负责任数据的考虑,谷歌从数据文档、新数据集、“毒评审核”,以及社会背景数据等方面进行了优化。
在数据文档的完善上,公司扩展了模型卡和工具包,同时发布了数据卡和游戏手册。在医疗保健领域创建了“健康表”,成为国际合作“Standing Together”的基础。
基于公平性,谷歌在2022年发布了新的数据集,主要用于协助完成机器学习的公平性和对抗性测试任务。该数据集包含 590 个单词和短语,可以显示形容词、单词和短语之间的相互作用,已被证明与特定的个人和群体基于其敏感或受保护的特征的刻板关联。

为了审核有毒的评论,谷歌发布了一个包含10000个帖子组成的数据集,通过海量的逻辑推演,识别一个评论如何由其他评论挑起“毒性”。
通过使用实验性社会语境存储库(SCR) ,公司支持Perspective团队对与民族等类别有关的术语提供辅助的身份和内涵背景数据,同时提供多种语言。这类辅助社会背景数据可以帮助增强和平衡数据集,以显著减少意外偏差,并应用于广泛使用的 Perspective API毒性模型中。

推出LIT和CLP,构建安全和稳定的开发环境
学习可解释性工具 (LIT)的更新是谷歌AI的一项突破。开发更安全模型的重要前提是拥有调试和理解它们的工具,这是LIT诞生的重要原因。作为可视化的机器学习开源平台,LIT可以支持图表和表格工具。该工具已在谷歌自家广泛应用于模型调试、模型审查发布、公平性问题识别和数据集清理等业务中。如今,它可以实现比之前多10倍的可视化数据,支持多达百万的数据点。

当输入中引用的敏感属性被删除或替换时,ML模型有时容易推翻预测。例如,在毒性分类器中,“我是男人”和“我是女同性恋”等示例可能会错误地产生不同的输出。

为了让开源社区的用户能够解决机器学习模型中产生的意外偏差,谷歌推出了一个新的库——Counterfactual Logit Pairing (CLP),可以提高模型在偏差扰动下的稳健性。

人工智能的社会效益仍然是重要议题
此外,谷歌人工智能也在不同社会领域产出效益,表现在服务可及性、健康和媒体等领域。
在服务的可及性上,表现在个性化人工智能语言模型的推出(Project Relate),可以让不同国家、不同标准语音的使用者实现更加流畅的沟通。
与此同时,谷歌和亚马逊、苹果、Meta、微软等公司的研究合作,建立了大型受损语音数据集,供研发人员使用,从而推动无障碍应用的研究和产品的开发。
在AI助力健康研究方面,通过技术改善临床风险评分的可解释性,更好地预测慢性疾病的残疾评分,从而实现早期治疗和护理。
为了在 AI 开发和评估中纳入多元化的文化背景和声音,谷歌加强了基于社区的研究工作,重点关注代表性较低或可能经历 AI 不公平结果的特定社区。这项工作正在推进对不公平性别偏见的更准确评估,以便其技术评估减轻对具有酷儿和非二元身份的人的伤害。
此外,在文化的包容性方面,谷歌也充分考虑了跨文化的重要性,建立能够进行文化评估的数据和技术。

从探索人类技术边界到道德化人工智能
多年之前,谷歌被外界所熟知的除了谷歌搜索、YouTube,还有X实验室。尽管其机密程度堪比CIA,但登月计划、WiFi热气球、智能机器人、量子计算机、纳米粒子等技术创意让产业界叹为观止。创始人拉里·佩奇“走在人类探索科技边界最前沿”的论断也听上去信心满满。
然而,随着将波士顿动力卖给软银,谷歌似乎在探索科技边界这件事上越来越默然,而是将目光更加聚焦在技术理论的研究和更多的伦理思考上。在本次发布的2022年AI进展中,即使是对技术本身的讨论也处处不离社会责任。
当面对ChatGPT掀起的大模型风暴时,公司CEO皮查伊也深感震撼,让部分团队转变方向,致力于AI产品研发,教导谷歌团队需要重点解决ChatGPT在公司搜索引擎中的危害。
虽然也有LaMDA、BERT和MUMAI等语言模型可供部署,但谷歌骨子里对聊天机器人会产生偏见和诽谤的担忧让他们的动作踟躇不前。当然,这一担忧并非空穴来风,前段时间Meta推出的Galactica就在48小时内被骂下架。
GoogleAI负责人JeffDean对于是否跟大语言模型这趟风时表示:“尽管Google拥有生产AI的技术和能力,但必须以‘更传统的方式’而不是‘从小处做起’来做决策。”
“更加传统的方式”是否意味着“闷声憋大招”?对此,谷歌没有明确表态。只是在2023年的AI规划中表示:以负责任和合乎道德的方式构建机器学习模型和产品是我们的核心重点和核心承诺。
参考链接
https://ai.googleblog.com/2023/01/google-research-2022-beyond-responsible.html#Theme1


☞雷军:小米 13 暂无做半代升级版本计划;微软放宽 Bing 搜索引擎使用限制;.NET 8 发布首个预览版本|极客头条
☞百度2022全年营收1236.75亿元,净利润同比增长10%,计划将多项主流业务与文心一言整合
☞Linus Torvalds 怒怼:不要提交没有注释的请求以上是关于不跟风 ChatGPT,Google AI 2022 年都在忙什么?的主要内容,如果未能解决你的问题,请参考以下文章
ChatGPT冷观察:没有大模型的土壤,开不出ChatBot的花
Google Bard VS ChatGPT:哪个是更好的AI聊天机器人?
挑战 Google 搜索?OpenAI 发布最强 AI 对话系统 ChatGPT