《SARAS-Net: Scale and Relation Aware Siamese Network for Change Detection》论文分享
Posted 怀铭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《SARAS-Net: Scale and Relation Aware Siamese Network for Change Detection》论文分享相关的知识,希望对你有一定的参考价值。
Overview
一般融合后提取和提取后融合方法仅以相同的比例逐层计算特征的注意力。将产生许多对小变化区域的预测失误和对大的无关变化的错误警报,作者提出了两种关键方法缓解上述尺度问题:
计算增强特征的注意力不仅在图像对的减法(差分图)之前,而且在图像对的减法之后
从深层特征中逐层计算关注度,不仅在相同的尺度上,而且在交叉尺度上,以很好地检测变化区域,即使大小不同。
进而提出了三个模块:关系感知(relation-aware), 尺度感知(scale-aware)和 交叉变换器(cross-transformer)
从下图可以看出,差分图操作之前是关系感知模块;差分图操作之后是尺度感知模块和交叉变换器模块。
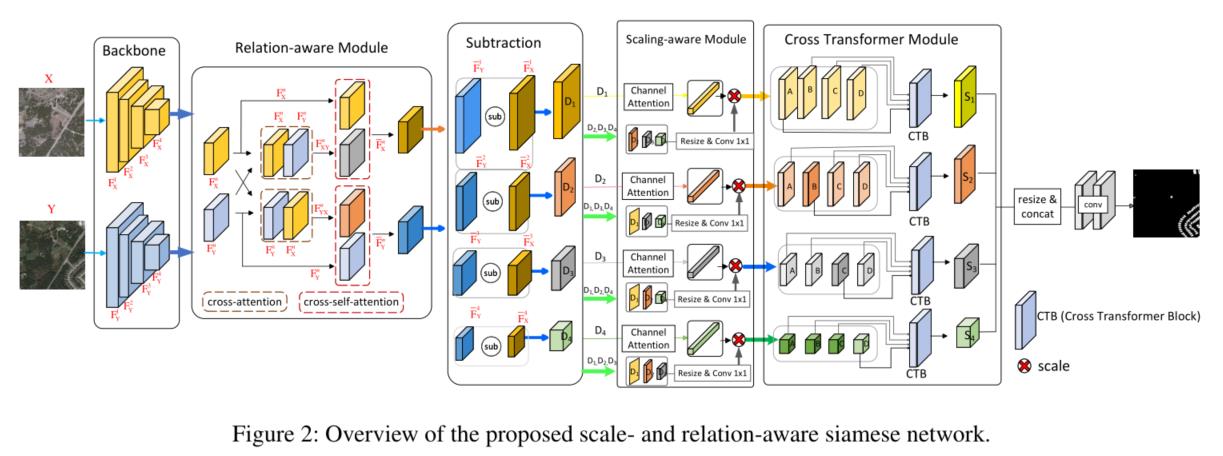
Relation-aware module
这一模块主要是为了学习到双时相之间的相互关系。使用的是Transformer中的QKV注意力机制来对Backbone中提取到的特征金字塔的每一层计算双时相遥感图像之间的相关性:
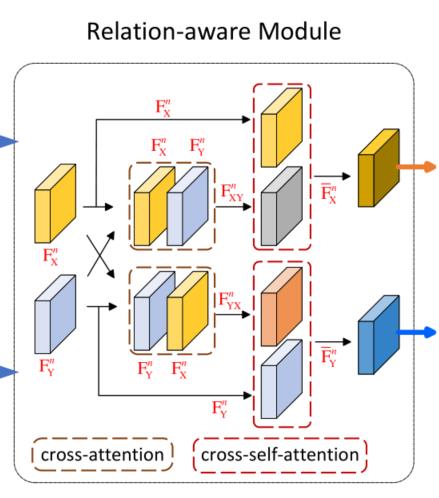
对每一个特征金字塔层进行计算相关性时,主要使用了两次注意力机制:cross-attention module和cross-self-attention module。
两者的结构相同,但输入的不同:
cross-attention module输入都为Backbone第n层输出的原始特征图 和
和
cross-self-attention module输入的和经过cross-attention module的输出和原始的或(具体是还是,和cross-attention module一致)
具体结构如下图:
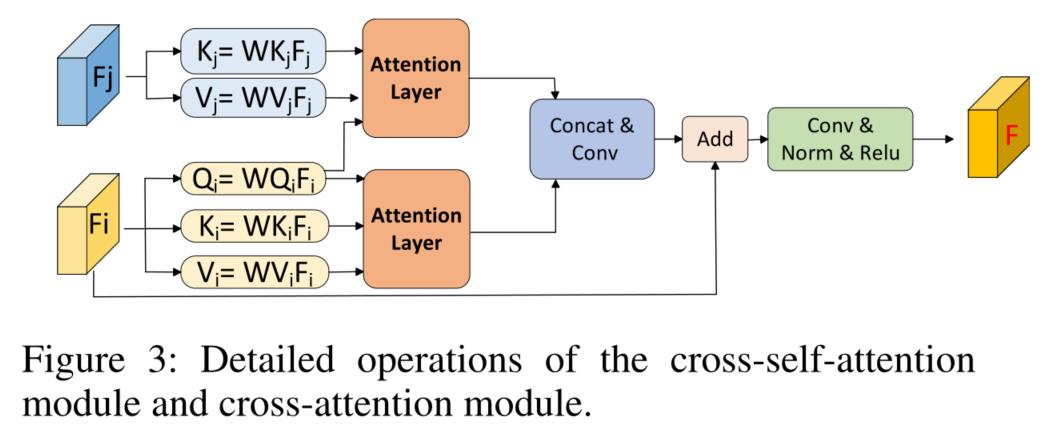
Scale-aware module
这一模块的主要目的是为下一模块(Cross transformer module)提供不同尺度的输入,同时也能够进行初步的不同尺度特征的信息交融。
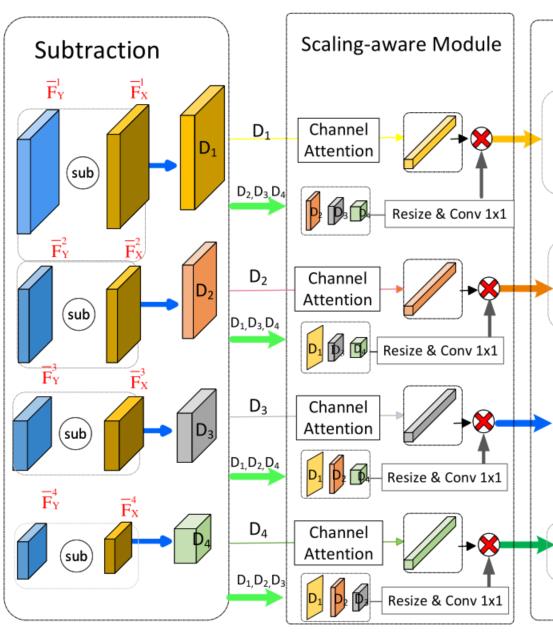
这一操作会对特征金字塔的每一差分后的特征层(后也称其为特征层)都进行一次,具体是将其余特征层的特征图resize至当前特征图的大小(通过线性插值上采样和1×1卷积),并与当前层的特征图经过global average pooling、1×1卷积和Sigmoid激活函数所得的通道注意力权重相乘。通过这一方法强调各层特征图中在当前特征图中更加关注的通道,并将转化后的所有特征图作为Cross transformer module的输入让其融合不同尺度特征图的信息。
Cross transformer module
这一模块的主要作用是以当前层为主融合上一模块输入的各尺度特征图之间的信息。
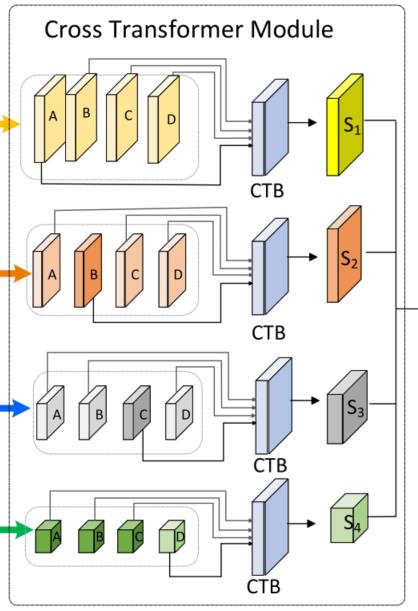
利用的也是QKV注意力机制,给定当前特征图 ,我们训练三个矩阵
,我们训练三个矩阵 、
、 、
、 ,将其分别映射到查询
,将其分别映射到查询 、关键字
、关键字 和值
和值 。类似地,给定
。类似地,给定 、
、 和
和 ,我们可以训练线性矩阵分别获得
,我们可以训练线性矩阵分别获得 、
、 、
、 、
、 、
、 、
、 。然后,基于,我们可以在m=a,b,c,d的情况下训练它与所有关键字
。然后,基于,我们可以在m=a,b,c,d的情况下训练它与所有关键字 之间的交叉尺度关注度
之间的交叉尺度关注度 :
:
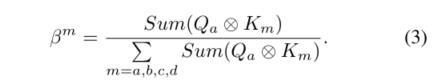
然后利用 和当前特征图(残差连接)得到输出:
和当前特征图(残差连接)得到输出:
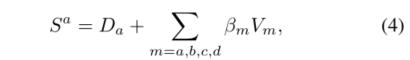
Output and Loss
将Cross transformer module的输出 除了最浅层的(size最大的)都通过线性插值上采样至最浅层的大小再concat后送入至3×3卷积中得到最后的与输入图像相同大小的分割结果P(也即分类器G:
除了最浅层的(size最大的)都通过线性插值上采样至最浅层的大小再concat后送入至3×3卷积中得到最后的与输入图像相同大小的分割结果P(也即分类器G: )
)
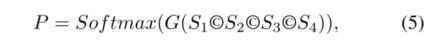
损失使用的是经典的二值交叉熵损失:
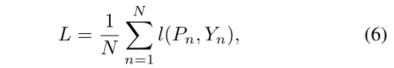
其中:
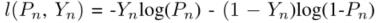
结语
算法具体流程:

源代码作者开源至:https://github.com/f64051041/SARAS-Net
以上是关于《SARAS-Net: Scale and Relation Aware Siamese Network for Change Detection》论文分享的主要内容,如果未能解决你的问题,请参考以下文章
easy-thumbnails:在缩略图别名中使用 scale_and_crop 图像处理器
Node.js: Extend and Maintain Applications + large scale
Opencv c++Template/Pattern Matching Scale and Rotation invariant
How Hulu Uses InfluxDB and Kafka to Scale to Over 1 Million Metrics a Second
Robotics Education and Research at Scale - A Remotely Accessible Robotics Development Platform
UT-Austin大学在Image search and large-scale retrieval方面的一系列papers