大数据面试题flume篇
Posted 后季暖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据面试题flume篇相关的知识,希望对你有一定的参考价值。
目录
1.Flume 的Source,Sink,Channel 的作用?你们Source 是什么类型?
4.Source中Exec、Spooldir、Taildir的区别
1.Flume 的Source,Sink,Channel 的作用?你们Source 是什么类型?
1. 作用
(1)Source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spoolingdirectory、netcat、sequence generator、syslog、http、legacy
(2)Channel组件对采集到的数据进行缓存,可以存放在Memory 或 File 中。
(3)Sink 组件是用于把数据发送到目的地的组件,目的地包括 HDFS、Logger、avro、thrift、ipc、file、Hbase、solr、自定义。
2. 我公司采用的 Source 类型为
(1)监控后台日志:exec、spooldir、TAILDIR
(2)监控后台产生日志的端口:netcat
2.常见的source?
1)netcat tcp source:用来监听端口数据
2)exec source 监听单个追加文件
3)spooling Directory Source 监听目录下新增文件
4)Taildir Source 监听目录下新增文件以及追加文件
5)kafka source
3.Flume基础架构:
Client、Agent:一个jvm进程(由source 、channel 、sink组成)、event

4.Source中Exec、Spooldir、Taildir的区别
具体代码:Flume学习之监控端口数据(Exec、Spooldir、Taildir)心得_flume spooldir_顺其自然的济帅哈的博客-CSDN博客
1.exe:(读一个不断在追加新内容的文件,不能断点续传) 表示执行linux命令来读取文件 和 tail -F命令搭配可以检测文件 exec source 适合监控一个实时追加的文件 不能实现断点续传 如果agent挂了会把所有文件内容重新读一遍
2.spooldir source:(就是读目录下的新文件)适合同步新文件 但不适合对实时追加日志的文件监听同步 读取新文件后会标记.completed 但是这个文件无论是否有变化 都不会再读取了
3.Taildir source:(就是读目录下的文件,这些文件是不断在追加新内容的文件,可以断点续传) 适合用于监听多个实时追加的文件 Taildir source 维护了一个json格式的position File 会定期往position File更新每个文件读取到的最新的位置 因此能够进行断点续读 也就是读到的位置可以记录下来 agent重启后可以断点续读
5.Flume的参数调优
1) source 增加Source个数(使用TairDir Source时可增加FileGroups个数)
可以增加source读取数据的能力 batchSize参数决定一次性往putlist放event的个数
默认为20 适当调大可以提高搬运event到channel的性能
2)channel type:Memory channel 的性能更好 但是如果出现进程意外挂掉会丢失数据
File channel:容错性更好 但是性能会比Memory channel差 实际生产时选Memory channel多一点
我们也可以用file channel时dataDir配置多个不同盘的目录来提高性能
3)sink 增加sink的个数 可以增加sink消费event的能力 不过过多的sink会占用系统资源 造成不必要的系统资源浪费 batchSize参数决定一次批量从takelist读取的event条数 适当调大可以提高sink从channel搬出event的性能
6. Flume 采集数据会丢失吗?
根据 Flume 的架构原理,Flume 是不可能丢失数据的,其内部有完善的事务机制,Source 到 Channel 是事务性的,Channel 到 Sink 是事务性的,因此这两个环节不会出现数据的丢失,唯一可能丢失数据的情况是 Channel 采用 memoryChannel,agent 宕机导致数据丢失,或者 Channel 存储数据已满,导致 Source 不再写入,未写入的数据丢失。
Flume 不会丢失数据,但是有可能造成数据的重复,例如数据已经成功由 Sink 发出,但是没有接收到响应,Sink 会再次发送数据,此时可能会导致数据的重复。
7.Flume事务
FLume事务包括Put事务和Take事务。Flume事务保证了数据在Source - Channel,以及Channel - Sink,这两个阶段传输时不会丢失,一旦事务中所有的事件全部传递到 Channel 且提交成功,那么 Soucrce 就将该文件标记为完成。同理,事务以类似的方式处理从 Channel 到 Sink 的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。需要注意的是,Take事务可能导致数据重复。
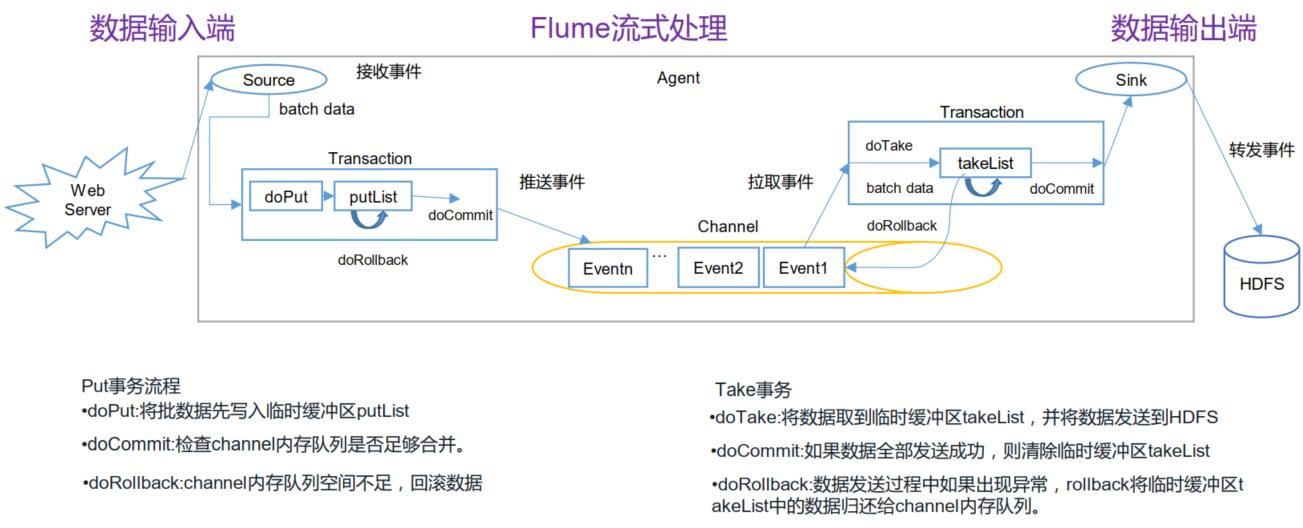 如果发送过程中出现异常,回滚,将takeList中的全部event归还给Channel。这个操作可能导致数据重复,如果已经写入一半的event到了HDFS,但是回滚时会向channel归还整个takeList中的event,后续再次开启事务向HDFS写入这批event时候,就出现了数据重复。
如果发送过程中出现异常,回滚,将takeList中的全部event归还给Channel。这个操作可能导致数据重复,如果已经写入一半的event到了HDFS,但是回滚时会向channel归还整个takeList中的event,后续再次开启事务向HDFS写入这批event时候,就出现了数据重复。
Hadoop:大数据常见面试题 Hadoop篇(1)_hadoop面试_后季暖的博客-CSDN博客
Spark:大数据面试题Spark篇(1)_后季暖的博客-CSDN博客
以上是关于大数据面试题flume篇的主要内容,如果未能解决你的问题,请参考以下文章