:管理和维护基于时间的信息 读书笔记
Posted dingdingfish
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了:管理和维护基于时间的信息 读书笔记相关的知识,希望对你有一定的参考价值。
本文为Oracle 19c VLDB and Partitioning Guide第5章Managing and Maintaining Time-Based Information的读书笔记。
Oracle 数据库提供了基于时间管理和维护数据的策略。
本章讨论 Oracle 数据库中的组件,这些组件可以构建基于时间管理和维护数据的策略。
尽管大多数组织长期以来一直将他们的数据存储视为最有价值的企业资产之一,但这些数据的管理和维护方式因公司而异。 最初,数据用于帮助实现运营目标、经营业务以及帮助确定公司未来的方向和成功。
然而,新的政府法规和指导方针是数据保留方式和原因的关键驱动力。 现在的法规要求组织在很长一段时间内保留和控制信息。 因此,如今信息技术 (IT) 经理正在努力满足其他目标:
- 以尽可能低的成本存储大量数据
- 满足数据保留和保护的新法规要求
- 通过基于更多数据的更好分析来增加商机
5.1 Managing Data in Oracle Database With ILM
借助信息生命周期管理 (ILM),您可以使用适用于该数据的规则和法规来管理 Oracle 数据库中的数据。
当今的信息有多种类型,例如电子邮件消息、照片或联机事务处理 (OLTP) 系统中的订单。 了解数据的类型及其使用方式后,您就会了解数据的演变和最终处置方式。
每个组织面临的一个挑战是了解其数据如何演变和增长,监控其使用如何随时间变化,并决定它应该留存多长时间,同时遵守现在适用于该数据的所有规则和法规。 信息生命周期管理 (ILM) 旨在通过流程、策略、软件和硬件的组合来解决这些问题,以便可以在数据生命周期的每个阶段使用适当的技术。
5.1.1 About Oracle Database for ILM
Oracle 数据库为实施 ILM 解决方案提供了理想的平台。
Oracle 数据库平台提供以下功能:
-
应用程序透明度
应用程序透明性在 ILM 中非常重要,因为它意味着无需自定义应用程序,并且还可以对数据进行各种更改而不会对使用该数据的应用程序产生任何影响。 数据可以在其生命周期的不同阶段轻松移动,并且可以使用数据库优化对数据的访问。 另一个重要的好处是,应用透明度提供了快速适应任何新监管要求所需的灵活性,同样不会对现有应用产生任何影响。 -
细粒度数据
Oracle 可以非常细粒度地查看数据并将相关数据分组,而存储设备只能看到字节和块。 -
低成本存储
由于要保留如此多的数据,使用低成本存储是实施 ILM 的关键因素。 由于 Oracle 可以利用多种类型的存储设备,因此可以以尽可能低的成本保存最大量的数据。 -
可执行的合规政策
当出于合规原因保留信息时,必须向监管机构表明数据是按照法规保留和管理的。 在 Oracle 数据库中,可以定义安全和审计策略,这些策略强制执行并记录对数据的所有访问。
5.1.1.1 Oracle Database Manages All Types of Data
信息生命周期管理涉及组织中的所有数据。
这些数据不仅包括结构化数据,例如 OLTP 系统中的订单或数据仓库中的销售历史,还包括非结构化数据,例如电子邮件、文档和图像。 Oracle 数据库支持使用 BLOB 和 Oracle SecureFiles 存储非结构化数据,Oracle Text 中提供了一个复杂的文档管理系统。
如果您组织中的所有信息都包含在 Oracle 数据库中,那么您可以利用数据库提供的特性和功能来管理和移动数据在其生命周期内的演变,而无需管理多种类型的数据存储 .
5.1.1.2 Regulatory Requirements
许多组织必须在特定时间段内保留特定数据。 不遵守这些规定可能导致组织不得不支付巨额罚款。
世界各地的各种监管要求,例如美国的 Sarbanes-Oxley、HIPAA、DOD5015.2-STD 和欧盟的欧洲数据隐私指令,正在改变组织管理其数据的方式。 这些规定规定了哪些数据必须保留,是否可以更改,以及必须保留多长时间,可以是 30 年或更长时间。
这些法规经常要求确保电子数据的安全,防止未经授权的访问和更改,并且对数据的所有更改以及由谁进行的更改进行审计跟踪。 Oracle 数据库可以在不影响应用程序性能的情况下保留大量数据。 它还包含限制访问和防止未经授权更改数据所需的特性,并且可以通过 Oracle Audit Vault 和 Database Firewall 进一步增强。 Oracle 数据库还提供了加密函数,可以证明高权限用户没有故意修改数据。 使用闪回数据技术,您可以将行在其生命周期内的所有版本存储在防篡改历史存档中。
5.1.1.3 The Benefits of an Online Archive
在线存档有很多好处。
在数据的生命周期中,通常会出现一个不再定期访问并且被认为符合归档条件的时刻。 传统上,数据会从数据库中删除并存储在磁带上,您可以在磁带上以极低的成本存储大量信息。 如今,不再需要将该数据存档到磁带,而是可以将其保留在数据库中,或传输到中央在线存档数据库。 所有这些信息都可以使用每 GB 成本非常接近磁带的低成本存储设备来存储。
将所有数据保存在 Oracle 数据库中以供存档有很多好处。 最重要的好处是数据总是即时可用。 因此,时间不会浪费在查找存档数据的磁带和确定磁带是否可读以及是否仍处于可以加载到数据库中的格式上。
如果数据已经存档多年,那么可能还需要开发时间来编写程序将数据从磁带存档重新加载到数据库中。 这可能会被证明是昂贵且耗时的,尤其是在数据非常陈旧的情况下。 如果数据保留在数据库中,那么这不是问题,因为它是在线的,并且是最新的数据库格式。
将历史数据保存在数据库中不再影响备份数据库所需的时间和备份的大小。 当RMAN 用于备份数据库时,它只在备份中包含已更改的数据。 因为历史数据不太可能发生变化,所以备份过的数据就不会再备份了。
另一个需要考虑的重要因素是如何从数据库中物理删除数据,尤其是当数据要从生产系统传输到中央数据库存档时。 Oracle 提供了通过使用可传输表空间或分区在数据库之间快速移动这些数据的能力,这将数据作为一个完整的单元进行移动。
当需要从数据库中删除数据时,最快的方法是删除一组数据。 这是通过将数据保存在其自己的分区中来实现的。 可以删除分区,这是一个非常快速的操作。 但是,如果由于必须维护数据关系而无法使用此方法,则必须发出常规的 SQL 删除语句。 您不应低估发出删除语句所需的时间。
如果有从数据库中移除数据的需求,并且将来可能需要将数据返回到数据库中,那么可以考虑以可传输表空间等数据库格式移除数据,或者使用 XML Oracle 数据库以开放格式提取信息的能力。
考虑将您的数据在线归档到 Oracle 数据库中,原因如下:
- 磁盘的成本接近磁带的成本,因此您可以省去查找包含数据的磁带的时间以及恢复该数据的成本
- 数据在需要时保持在线,为您提供更快的访问以满足业务需求
- 在线数据意味着即时访问,因此监管机构因未能提供数据而被罚款的可能性较小
- 可以使用当前应用程序访问数据,因此您无需浪费资源构建新应用程序
5.1.2 Implementing ILM Using Oracle Database
使用 Oracle 数据库构建信息生命周期管理解决方案非常简单。
ILM 解决方案可以通过以下四个简单步骤完成,但如果未实施 ILM 以实现合规性,则第 4 步是可选的:
- 第 1 步:定义数据类
- 第 2 步:为数据类创建存储层
- 第 3 步:创建数据访问和迁移策略
- 第 4 步:定义和执行合规政策
5.1.2.1 Step 1: Define the Data Classes
要有效利用信息生命周期管理,请在实施信息生命周期管理解决方案之前首先检查组织中的所有数据。
查看数据后,确定以下内容:
- 什么数据是重要的,它存储在哪里,什么必须保留
- 这些数据如何在组织内流动
- 随着时间的推移,这些数据会发生什么变化以及是否仍然需要它
- 所需的数据可用性和保护程度
- 法律和业务要求的数据保留
在了解了数据的用途之后,就可以在此基础上对数据进行分类。 最常见的分类类型是按年份或日期,但其他类型也是可能的,例如按产品或隐私。 也可以使用混合分类,例如按隐私和年份分类。
要区别对待数据类,数据必须在物理上分开。 最初创建信息时,通常会经常访问该信息,但随着时间的推移,可能很少有人引用它。 例如,当客户下订单时,他们会定期查看订单以查看其状态以及订单是否已发货。 订单到达后,他们可能永远不会再参考该订单。 此订单也将包含在运行以查看正在订购哪些商品的定期报告中,但随着时间的推移,不会出现在任何报告中,并且只有在有人进行涉及此的详细分析时才会在将来被引用。 例如,订单可以按财务季度 Q1、Q2、Q3 和 Q4 分类,也可以分类为历史订单。
使用这种方法的优点是,当数据按类别在行级别分组时,在本例中是订单日期,Q1 的所有订单都可以作为一个独立的单元进行管理,而Q2 的订单将驻留在不同的类中。 这可以通过使用分区来实现。 因为分区对应用程序是透明的,所以数据在物理上是分开的,但应用程序仍然可以找到所有订单。
5.1.2.1.1 Partitioning for ILM
分区涉及根据数据值物理放置数据,并且经常使用的技术是按日期对信息进行分区。
图 5-1 说明了一个场景,其中 Q1、Q2、Q3 和 Q4 的订单存储在单独的分区中,而前几年的订单存储在其他分区中。
图 5-1 将数据类分配给分区

Oracle 提供了几种不同的分区方法。 范围分区是 ILM 中一种常用的分区方法。 间隔和参考分区也特别适合在 ILM 环境中使用。
对数据进行分区有很多好处。 分区提供了一种简单的方法,可以根据数据的使用情况将数据分布在适当的存储设备上,同时仍然保持数据在线并存储在最具成本效益的设备上。 因为分区对访问数据的任何人都是透明的,所以不需要更改应用程序,因此可以随时实现分区。 当需要新分区时,只需使用 ADD PARTITION 子句添加它们,或者如果使用间隔分区,则自动创建它们。
除其他好处外,每个分区都可以有自己的本地索引。 当优化器使用分区修剪时,查询只访问相关分区而不是所有分区,从而提高查询响应时间。
5.1.2.1.2 The Lifecycle of Data
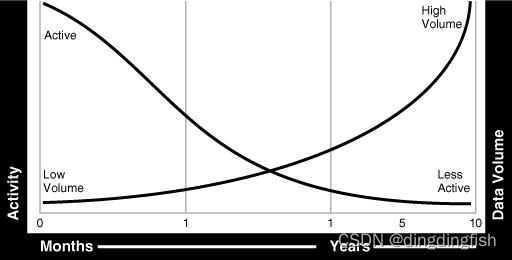
对您的数据进行分析可能会发现,最初,它的访问和更新频率非常高。 随着数据年龄的增加,其访问频率会降低到几乎可以忽略不计(如果有的话)。
大多数组织发现自己处于许多用户访问当前数据而极少数用户访问旧数据的情况,如图 5-2 所示。 数据被认为是:活跃的、不太活跃的、历史的或准备存档的。
由于保存了如此多的数据,因此在其生命周期内,数据应移动到不同的物理位置。 根据数据在其生命周期中所处的位置,它必须位于最合适的存储设备上。
图 5-2 随时间变化的数据使用情况
5.1.2.2 Step 2: Create Storage Tiers for the Data Classes
因为 Oracle 数据库可以利用许多不同的存储选项,所以实施信息生命周期管理解决方案的第二步是建立所需的存储层。
尽管您可以根据需要创建任意数量的存储层,但建议从以下层开始:
-
高性能
高性能存储层存储所有重要且经常访问的数据,例如保存我们 Q1 订单的分区。 该层在高性能存储设备上使用更小、更快的磁盘。 -
低成本
低成本存储层存储访问频率较低的数据,例如保存 Q2、Q3 和 Q4 订单的分区。 该层是使用大容量磁盘构建的,例如模块化存储阵列中的磁盘或低成本 ATA 磁盘,它们提供最大数量的廉价存储。 -
在线存档
在线存档存储层是存储所有很少访问或修改的数据的地方。 这个存储层可能非常大并且存储最大数量的数据。 您可以使用各种技术来压缩数据。 存储在 ATA 驱动器等低成本存储设备上的数据仍然在线且可用,其成本仅略高于将此信息存储在磁带上的成本,而且没有将数据归档到磁带所带来的缺点。 如果 Online Archive 存储层被标识为只读,那么就不可能更改数据,并且在初始数据库备份后不需要后续备份。 -
离线存档(可选)
脱机存档存储层是一个可选层,因为它仅在需要从数据库中删除数据并以其他格式(例如磁带上的 XML)存储时才使用。
图 5-2 说明了在一个时间间隔内如何使用数据。 使用此信息,可以确定要保留所有这些信息,需要多个存储层来保存所有数据,这还具有显着降低总存储成本的好处。
创建存储层后,在第 1 步:定义数据类中标识的数据类将使用分区在数据库内部物理实现。 这种方法提供了一种简单的方法,可以根据数据的使用情况将数据分布在适当的存储设备上,同时仍然保持数据在线和随时可用,并存储在最具成本效益的设备上。
您还可以使用 Oracle 自动存储管理 (Oracle ASM) 跨存储层管理数据。 Oracle ASM 是一种高性能、易于管理的 Oracle 数据库文件存储解决方案。 Oracle ASM 是一个卷管理器,提供专为数据库使用而设计的文件系统。 要使用 Oracle ASM,您需要为 Oracle 数据库分配分区磁盘,并优先考虑条带化和镜像。 Oracle ASM 管理磁盘空间,将 I/O 负载分配到所有可用资源以优化性能,同时消除手动 I/O 调整的需要。 例如,您可以增加数据库的磁盘大小或将部分数据库移动到新设备,而无需关闭数据库。
5.1.2.2.1 Assigning Classes to Storage Tiers
定义存储层后,可以将步骤 1 中确定的数据类(分区)分配给适当的存储层。
这种分配提供了一种简单的方法,可以根据数据的使用情况将数据分布在适当的存储设备上,使数据保持在线和可用,并存储在最具成本效益的设备上。 在图 5-3 中,识别为活跃、不活跃、历史或准备归档的数据分别分配到高性能层、低成本存储层、在线归档存储层和离线归档。 使用这种方法,不需要更改应用程序,因为数据仍然可见。
图 5-3 数据生命周期

5.1.2.2.2 The Costs Savings of Using Tiered Storage
实施 ILM 策略的好处之一是使用多层存储可以节省成本。
假设要存储 3 TB 的数据,其中 200 GB 用于高性能,800 GB 用于低成本,2 TB 用于在线存档。 假设高性能层的每 GB 成本为 72 美元,低成本层为 14 美元,在线存档层为 7 美元。
表 5-1 说明了使用分层存储可能节省的成本,而不是将所有数据存储在一类存储上。 如您所见,成本节省非常可观,如果数据适用于 OLTP 和 HCC 数据库压缩,则可以进一步节省成本。
表 5-1 使用分层存储节省的成本
| 存储层 | 全部用使用高性能磁盘 | 多个存储层 | 多个存储层+压缩 |
|---|---|---|---|
| 高性能 (200 GB) | $14,400 | $14,400 | $14,400 |
| 低成本 (800 GB) | $57,600 | $11,200 | $11,200 |
| 在线存档 (2 TB) | $144,000 | $14,000 | $5,600 |
| 每列总计 | $216,000 | $39,600 | $31,200 |
5.1.2.3 Step 3: Create Data Access and Migration Policies
实施信息生命周期管理解决方案的第三步是确保只有授权用户才能访问数据并指定如何在其生命周期内移动数据。
随着数据老化,有多种技术可以在存储层之间迁移数据。
5.1.2.3.1 Controlling Access to Data
数据的安全性是信息生命周期管理的另一个非常重要的部分,因为对数据的访问权限可能会在其生命周期内发生变化。
此外,可能存在对如何访问数据提出严格要求的监管要求。
可以使用数据库特性保护 Oracle 数据库中的数据,例如:
- 数据库安全
- 视图
- 虚拟专用数据库(VPD)
虚拟专用数据库 (VPD) 定义了对数据库的非常细粒度的访问级别。 安全策略确定可以查看哪些行以及可见的列。 可以定义多个策略,以便不同的用户和应用程序看到相同数据的不同视图。 例如,大多数用户可以看到 Q1、Q2、Q3 和 Q4 的信息,而只有授权用户才能查看历史数据。
安全策略在数据库级别定义,并透明地应用于所有数据库用户。 这种方法的好处是它为访问数据提供了一个安全和受控的环境,该环境不能被覆盖并且可以在不需要任何应用程序更改的情况下实施。 此外,可以定义只读表空间,以确保数据不会更改。
5.1.2.3.2 Moving Data using Partitioning
在其生命周期中,数据必须移动,分区是一种可以使用的技术。
移动数据可能由于以下原因而发生:
- 为了性能,只有有限数量的订单保存在高性能磁盘上
- 数据不再被频繁访问并且正在使用有价值的高性能存储,并且必须移动到低成本存储设备
- 法律要求信息在给定的时间间隔内始终可用,并且必须以尽可能低的成本安全保存
可以通过多种方式在 Oracle 数据库中物理移动数据以利用不同的存储层。 例如,如果对数据进行分区,则可以将包含 Q2 订单的分区从高性能存储层在线移动到低成本存储层。 因为数据是在数据库中移动的,所以它可以物理移动,而不会影响需要它的应用程序或对普通用户造成中断。
有时必须移动单个数据项,而不是一组数据。 例如,假设数据根据隐私级别进行了分类,并且一份以前保密的报告现在要向公众公开。 如果分类从秘密变为公共并且数据根据其隐私分类进行分区,则该行将自动移动到包含公共数据的分区。
每当数据从其原始来源移动时,确保所选过程符合任何法规要求非常重要,例如,数据不能被更改、防止未经授权的访问、易于读取以及存储在批准的位置。
5.1.2.4 Step 4: Define and Enforce Compliance Policies
信息生命周期管理解决方案的第四步是创建合规策略。
当数据分散且分散时,必须在每个数据位置定义和执行合规性策略,这很容易导致合规性策略被忽视。 但是,使用 Oracle 数据库提供一个中央位置来存储数据意味着可以非常轻松地执行合规性策略,因为它们都是从一个中央位置进行管理和执行的。
在定义合规策略时,请考虑以下方面:
- 数据保留
- 不变性
- 隐私
- 审计
- 过期
5.1.2.4.1 Data Retention
保留策略描述了如何保留数据、必须保留多长时间以及数据生命周期结束后会发生什么。
保留政策的一个例子是记录必须以其原始形式存储,不允许修改,必须保留七年,然后可以删除。 使用 Oracle 数据库安全性,可以确保数据保持不变,并且只有授权的进程才能在适当的时间删除数据。 还可以通过 ILM Assistant 中的生命周期定义来定义保留策略。
5.1.2.4.2 Immutability
不变性涉及向外部方证明数据是完整的且未被修改。
Oracle 数据库可以生成密码或数字签名并保留在数据库内部或外部,以表明数据未被更改。
5.1.2.4.3 Privacy
Oracle 数据库提供了多种方法来确保数据隐私。
可以使用虚拟专用数据库 (VPD) 定义的安全策略严格控制对数据的访问。 此外,可以对各个列进行加密,这样任何查看原始数据的人都看不到其内容。
5.1.2.4.4 Auditing
Oracle 数据库可以跟踪对数据的所有访问和更改。
这些审计功能可以在表级别或通过细粒度审计来定义,细粒度审计指定了何时生成审计记录的标准。 使用 Oracle Audit Vault and Database Firewall 可以进一步增强审计。
5.1.2.4.5 Expiration
最终,数据可能会因业务或监管原因而过期,并且必须从数据库中删除。
Oracle 数据库可以通过简单地删除包含要删除的信息的分区来非常快速和高效地删除数据。
5.2 Implementing an ILM Strategy With Heat Map and ADO
要为数据库中的数据移动实施信息生命周期管理 (ILM) 策略,您可以使用热图和自动数据优化 (ADO) 功能。
注意:Oracle Database 12c 第 2 版多租户环境支持热图和 ADO。这两个功能都是12c以后才支持的。
5.2.1 Using Heat Map
要实施您的 ILM 策略,您可以使用 Oracle 数据库中的热图来跟踪数据访问和修改。
热图提供段级别的数据访问跟踪以及段和行级别的数据修改跟踪。 您可以使用 HEAT_MAP 初始化参数启用此功能。
热图数据可以辅助自动数据优化(ADO)使用ADO策略管理In-Memory列存储(IM列存储)的内容。 使用包括列统计数据和其他相关统计数据的热图数据,IM 列存储可以确定何时快满(在内存压力下)。 如果确定几乎已满,如果有更频繁访问的段将受益于 IM 列存储中的填充,则可以驱逐非活动段。
5.2.1.1 Enabling and Disabling Heat Map
您可以使用 HEAT_MAP 子句通过 ALTER SYSTEM 或 ALTER SESSION 语句在系统或会话级别启用和禁用热图跟踪。
例如,以下 SQL 语句为数据库实例启用热图跟踪。
ALTER SYSTEM SET HEAT_MAP = ON;
启用热图后,内存中的活动跟踪模块会跟踪所有访问。 不跟踪 SYSTEM 和 SYSAUX 表空间中的对象。
以下 SQL 语句禁用热图跟踪。
ALTER SYSTEM SET HEAT_MAP = OFF;
禁用热图时,内存中活动跟踪模块不会跟踪访问。 HEAT_MAP 初始化参数的默认值为 OFF。
HEAT_MAP 初始化参数还启用和禁用自动数据优化 (ADO)。 对于 ADO,必须在系统级别启用热图。
5.2.1.2 Displaying Heat Map Tracking Data With Views
使用 V$、ALL、DBA* 和 USER* 热图视图查看热图跟踪数据。
示例 5-1 显示了热图视图提供的信息示例。 V$HEAT_MAP_SEGMENT 视图显示实时段访问信息。 ALL_、DBA_ 和 USER_HEAT_MAP_SEGMENT 视图显示用户可见的所有段的最新段访问时间。 ALL_、DBA_ 和 USER_HEAT_MAP_SEG_HISTOGRAM 视图显示用户可见的所有段的段访问信息。 DBA_HEATMAP_TOP_OBJECTS 视图显示最活跃对象的热图信息。 DBA_HEATMAP_TOP_TABLESPACES 视图显示最活跃表空间的热图信息。
示例 5-1 热图视图
/* enable heat map tracking if necessary*/
SELECT SUBSTR(OBJECT_NAME,1,20), SUBSTR(SUBOBJECT_NAME,1,20), TRACK_TIME, SEGMENT_WRITE,
FULL_SCAN, LOOKUP_SCAN FROM V$HEAT_MAP_SEGMENT;
SUBSTR(OBJECT_NAME,1 SUBSTR(SUBOBJECT_NAM TRACK_TIM SEG FUL LOO
-------------------- -------------------- --------- --- --- ---
SALES SALES_Q1_1998 01-NOV-12 NO NO NO
SALES SALES_Q3_1998 01-NOV-12 NO NO NO
SALES SALES_Q2_2000 01-NOV-12 NO NO NO
SALES SALES_Q3_1999 01-NOV-12 NO NO NO
SALES SALES_Q2_1998 01-NOV-12 NO NO NO
SALES SALES_Q2_1999 01-NOV-12 NO NO NO
SALES SALES_Q4_2001 01-NOV-12 NO NO NO
SALES SALES_Q1_1999 01-NOV-12 NO NO NO
SALES SALES_Q4_1998 01-NOV-12 NO NO NO
SALES SALES_Q1_2000 01-NOV-12 NO NO NO
SALES SALES_Q1_2001 01-NOV-12 NO NO NO
SALES SALES_Q2_2001 01-NOV-12 NO NO NO
SALES SALES_Q3_2000 01-NOV-12 NO NO NO
SALES SALES_Q4_2000 01-NOV-12 NO NO NO
EMPLOYEES 01-NOV-12 NO NO NO
...
SELECT SUBSTR(OBJECT_NAME,1,20), SUBSTR(SUBOBJECT_NAME,1,20), SEGMENT_WRITE_TIME,
SEGMENT_READ_TIME, FULL_SCAN, LOOKUP_SCAN FROM USER_HEAT_MAP_SEGMENT;
SUBSTR(OBJECT_NAME,1 SUBSTR(SUBOBJECT_NAM SEGMENT_W SEGMENT_R FULL_SCAN LOOKUP_SC
-------------------- -------------------- --------- --------- --------- ---------
SALES SALES_Q1_1998 30-OCT-12 01-NOV-12
SALES SALES_Q1_1998 30-OCT-12 01-NOV-12
SALES SALES_Q1_1998 30-OCT-12 01-NOV-12
SALES SALES_Q1_1998 30-OCT-12 01-NOV-12
SALES SALES_Q1_1998 30-OCT-12 01-NOV-12
SALES SALES_Q1_1998 30-OCT-12 01-NOV-12
...
SELECT SUBSTR(OBJECT_NAME,1,20), SUBSTR(SUBOBJECT_NAME,1,20), TRACK_TIME, SEGMENT_WRITE, FULL_SCAN,
LOOKUP_SCAN FROM USER_HEAT_MAP_SEG_HISTOGRAM;
SUBSTR(OBJECT_NAME,1 SUBSTR(SUBOBJECT_NAM TRACK_TIM SEG FUL LOO
-------------------- -------------------- --------- --- --- ---
SALES SALES_Q1_1998 31-OCT-12 NO NO YES
SALES SALES_Q1_1998 01-NOV-12 NO NO YES
SALES SALES_Q1_1998 30-OCT-12 NO YES YES
SALES SALES_Q2_1998 01-NOV-12 NO NO YES
SALES SALES_Q2_1998 31-OCT-12 NO NO YES
SALES SALES_Q2_1998 30-OCT-12 NO YES YES
SALES SALES_Q3_1998 01-NOV-12 NO NO YES
SALES SALES_Q3_1998 30-OCT-12 NO YES YES
SALES SALES_Q3_1998 31-OCT-12 NO NO YES
SALES SALES_Q4_1998 01-NOV-12 NO NO YES
SALES SALES_Q4_1998 31-OCT-12 NO NO YES
SALES SALES_Q4_1998 30-OCT-12 NO YES YES
SALES SALES_Q1_1999 01-NOV-12 NO NO YES
SALES SALES_Q1_1999 31-OCT-12 NO NO YES
...
SELECT SUBSTR(OWNER,1,20), SUBSTR(OBJECT_NAME,1,20), OBJECT_TYPE, SUBSTR(TABLESPACE_NAME,1,20),
SEGMENT_COUNT FROM DBA_HEATMAP_TOP_OBJECTS ORDER BY SEGMENT_COUNT DESC;
SUBSTR(OWNER,1,20) SUBSTR(OBJECT_NAME,1 OBJECT_TYPE SUBSTR(TABLESPACE_NA SEGMENT_COUNT
-------------------- -------------------- ------------------ -------------------- -------------
SH SALES TABLE EXAMPLE 96
SH COSTS TABLE EXAMPLE 48
PM ONLINE_MEDIA TABLE EXAMPLE 22
OE PURCHASEORDER TABLE EXAMPLE 18
PM PRINT_MEDIA TABLE EXAMPLE 15
OE CUSTOMERS TABLE EXAMPLE 10
OE WAREHOUSES TABLE EXAMPLE 9
HR EMPLOYEES TABLE EXAMPLE 7
OE LINEITEM_TABLE TABLE EXAMPLE 6
IX STREAMS_QUEUE_TABLE TABLE EXAMPLE 6
SH FWEEK_PSCAT_SALES_MV TABLE EXAMPLE 5
SH CUSTOMERS TABLE EXAMPLE 5
HR LOCATIONS TABLE EXAMPLE 5
HR JOB_HISTORY TABLE EXAMPLE 5
SH PRODUCTS TABLE EXAMPLE 5
...
SELECT SUBSTR(TABLESPACE_NAME,1,20), SEGMENT_COUNT
FROM DBA_HEATMAP_TOP_TABLESPACES ORDER BY SEGMENT_COUNT DESC;
SUBSTR(TABLESPACE_NA SEGMENT_COUNT
-------------------- -------------
EXAMPLE 351
USERS 11
SELECT COUNT(*) FROM DBA_HEATMAP_TOP_OBJECTS;
COUNT(*)
----------
64
SELECT COUNT(*) FROM DBA_HEATMAP_TOP_TABLESPACES;
COUNT(*)
----------
2
5.2.1.3 Managing Heat Map Data With DBMS_HEAT_MAP Subprograms
DBMS_HEAT_MAP 包为使用 DBMS_HEAT_MAP 子程序显示热图数据提供了额外的灵活性。
DBMS_HEAT_MAP 包括一组 API,这些 API 将热图外部化在不同存储级别,例如块、范围、段、对象和表空间; 第二组 API 外部化由顶级表空间的后台进程具体化的热图。
示例 5-2 显示了使用 DBMS_HEAT_MAP 包子程序的示例。
示例 5-2 使用 DBMS_HEAT_MAP 包子程序
SELECT SUBSTR(segment_name,1,10) Segment, min_writetime, min_ftstime
FROM TABLE(DBMS_HEAT_MAP.OBJECT_HEAT_MAP('SH','SALES'));
SELECT SUBSTR(tablespace_name,1,16) Tblspace, min_writetime, min_ftstime
FROM TABLE(DBMS_HEAT_MAP.TABLESPACE_HEAT_MAP('EXAMPLE'));
SELECT relative_fno, block_id, blocks, TO_CHAR(min_writetime, 'mm-dd-yy hh-mi-ss') Mintime,
TO_CHAR(max_writetime, 'mm-dd-yy hh-mi-ss') Maxtime,
TO_CHAR(avg_writetime, 'mm-dd-yy hh-mi-ss') Avgtime
FROM TABLE(DBMS_HEAT_MAP.EXTENT_HEAT_MAP('SH','SALES')) WHERE ROWNUM < 10;
SELECT SUBSTR(owner,1,10) Owner, SUBSTR(segment_name,1,10) Segment,
SUBSTR(partition_name,1,16) Partition, SUBSTR(tablespace_name,1,16) Tblspace,
segment_type, segment_size FROM TABLE(DBMS_HEAT_MAP.OBJECT_HEAT_MAP('SH','SALES'));
OWNER SEGMENT PARTITION TBLSPACE SEGMENT_TYPE SEGMENT_SIZE
---------- ---------- ---------------- ---------------- -------------------- ------------
SH SALES SALES_Q1_1998 EXAMPLE TABLE PARTITION 8388608
SH SALES SALES_Q2_1998 EXAMPLE TABLE PARTITION 8388608
SH SALES SALES_Q3_1998 EXAMPLE TABLE PARTITION 8388608
SH SALES SALES_Q4_1998 EXAMPLE TABLE PARTITION 8388608
SH SALES SALES_Q1_1999 EXAMPLE TABLE PARTITION 8388608
...
5.2.2 Using Automatic Data Optimization
要实施您的 ILM 策略,您可以使用自动数据优化 (ADO) 来自动压缩和移动数据库中不同存储层之间的数据。
该功能包括能够创建为每一层指定不同压缩级别的策略,以及控制何时发生数据移动。
要使用自动数据优化,您必须在系统级别启用热图。 您可以使用 HEAT_MAP 初始化参数启用此功能。
5.2.2.1 Managing Policies for Automatic Data Optimization
在使用 SQL 语句创建和更改表时,您可以在行、段和表空间粒度级别为 ADO 指定策略。 此外,ADO 策略可以对索引执行操作。
通过为 ADO 指定策略,您可以在数据库中的不同存储层之间自动进行数据移动。 这些策略还使您能够为每个层指定不同的压缩级别,并控制何时发生数据移动。
表的 ADO 策略
SQL CREATE 和 ALTER TABLE 语句的 ILM 子句使您能够创建、删除、启用或禁用 ADO 策略。 ILM 策略子句确定压缩或存储分层策略并包含其他子句,例如 AFTER 和 ON 子句以指定策略操作应发生的条件。 创建表时,可以为 ADO 添加新策略。 您可以更改该表以添加更多策略或启用、禁用或删除现有策略。 您可以将策略添加到整个表或表的分区。 将 ADO 策略添加到表或表的分区时,您只能为 AFTER 子句指定一种条件类型。 ILM ADO 策略被赋予一个系统生成的名称,例如 P1、P2 等等到 Pn。
段级策略仅执行一次。 策略成功执行后,将被禁用并且不会再次评估。 但是,您可以再次明确启用该策略。 行级别策略继续执行,并且在成功执行后不会被禁用。
可以使用关键字 GROUP、ROW 或 SEGMENT 为一组相关对象或在段或行的级别指定 ADO 策略的范围。
可应用于组策略的默认压缩映射是:
- 堆表上的 COMPRESS ADVANCED 映射到索引的标准压缩和 LOB 段的 LOW。
- 堆表上的 COMPRESS FOR QUERY LOW/QUERY HIGH 映射到索引的标准压缩和 LOB 段的 MEDIUM。
- 堆表上的 COMPRESS FOR ARCHIVE LOW/ARCHIVE HIGH 映射到索引的标准压缩和 LOB 段的 HIGH。
简而言之,对于索引都是标准压缩,对于LOB段则不同压缩级。
无法更改压缩映射。 GROUP 只能应用于段级别策略。 存储分层策略仅适用于段级别,不能在行级别指定。
In-Memory Column Store的ADO策略
自动数据优化 (ADO) 支持具有 INMEMORY、INMEMORY MECOMPRESS 和 NO INMEMORY 策略类型的内存列存储(IM 列存储)。
- 要在内存列存储中启用对象填充,请在 ADD POLICY 子句中包含 INMEMORY。
- 要提高 IM 列存储中对象的压缩级别,请在 ADD POLICY 子句中包含 INMEMORY MEMCOMPRESS。
- 要显式逐出从 IM 列存储中获益最少的对象,请在 ADD POLICY 子句中包含 NO INMEMORY。 例如:
以下是使用 NO INMEMORY 子句从 IM 列存储中逐出对象的示例。
ALTER TABLE sales_2015 ILM ADD POLICY NO INMEMORY
AFTER 7 DAYS OF NO ACCESS;
带有 In-Memory Column Store 子句的 ADO 策略只能是段级策略。 USER/DBA_ILMDATAMOVEMENTPOLICIES 和 V$HEAT_MAP_SEGMENT 视图包括有关内存列存储的 ADO 策略的信息。
定制的ADO策略
您可以使用 ON PL/SQL_function 选项自定义策略,该选项提供了确定何时执行策略的能力。 ON PL/SQL_function 选项仅适用于段级策略。 例如:
CREATE OR REPLACE FUNCTION my_custom_ado_rules (objn IN NUMBER) RETURN BOOLEAN;
ALTER TABLE sales_custom ILM ADD POLICY COMPRESS ADVANCED SEGMENT
ON my_custom_ado_rules;
5.2.2.2 Creating a Table With an ILM ADO Policy
将 ILM ADD POLICY 子句与 CREATE TABLE 语句结合使用,以创建具有 ILM ADO 策略的表。
示例 5-3 中的 SQL 语句创建一个表并添加一个 ILM 策略。
示例 5-3 使用 ILM ADO 策略创建表
/* Create an example table with an ILM ADO policy */
CREATE TABLE sales_ado
(PROD_ID NUMBER NOT NULL,
CUST_ID NUMBER NOT NULL,
TIME_ID DATE NOT NULL,
CHANNEL_ID NUMBER NOT NULL,
PROMO_ID NUMBER NOT NULL,
QUANTITY_SOLD NUMBER(10,2) NOT NULL,
AMOUNT_SOLD NUMBER(10,2) NOT NULL )
PARTITION BY RANGE (time_id)
( PARTITION sales_q1_2012 VALUES LESS THAN (TO_DATE('01-APR-2012','dd-MON-yyyy')),
PARTITION sales_q2_2012 VALUES LESS THAN (TO_DATE('01-JUL-2012','dd-MON-yyyy')以上是关于:管理和维护基于时间的信息 读书笔记的主要内容,如果未能解决你的问题,请参考以下文章