Elasticsearch:分析器中的 character filter 介绍
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:分析器中的 character filter 介绍相关的知识,希望对你有一定的参考价值。
Character filter,也即字符过滤器用于在将字符流传递给分词器(tokenizer)之前对其进行预处理。字符过滤器将原始文本作为字符流接收,并可以通过添加、删除或更改字符来转换流。 例如,字符过滤器可用于将印度-阿拉伯数字 (٠ ١٢٣٤٥٦٧٨ ٩ ) 转换为对应的阿拉伯-拉丁数字 (0123456789),或从流中去除 <b> 等 html 元素。
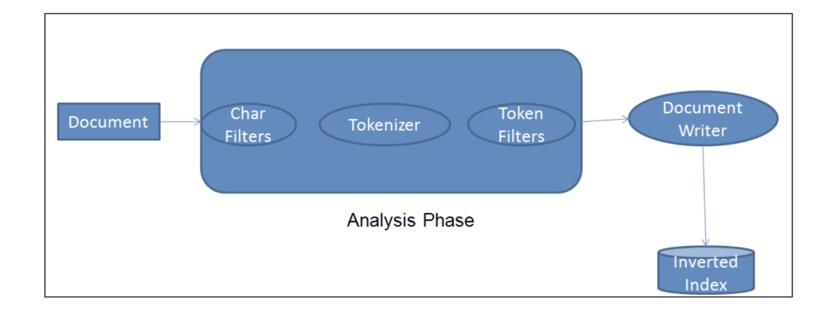
当用户搜索答案时,期望他们不会使用标点符号或特殊字符进行搜索。 例如,用户很可能会搜索 “cant find my keys”(没有标点符号)而不是 “can't find my keys!!!”。 同样,用户不应搜索字符串 “<h1>Where is my cheese?</h1>”(带有 HTML 标记)。 我们甚至不希望用户使用 <operation>callMe</operation> 等 XML 标记进行搜索。 搜索条件不需要被不需要的字符污染。 而且,有时,我们不希望用户使用符号进行搜索:α 代替 alpha 或 β 代替 beta,等等。
基于这些假设,我们可以使用字符过滤器分析和清理传入的文本。 字符过滤器有助于从输入流中清除不需要的字符。 尽管它们是可选的,但如果使用它们,它们将构成分析器模块中的第一个组件。
分析器可以由零个或多个字符过滤器组成。 字符过滤器执行以下特定功能:
- 从输入流中删除不需要的字符。 例如,如果传入文本具有 “<h1>where is Beijing?</h1>” 之类的 HTML 标记,则需要删除 <h1> 标记。
- 添加或替换现有流中的其他字符。 如果输入字段有一组 0 和 1,那么我们可能希望分别用 false 和 true 替换它们。 如果输入流有字符 β,我们可以将它映射到单词 beta 并索引该字段。
Elasticsearch 提供了三个字符过滤器,我们将在下一节中看到它们的实际应用。它们可以为我们构建自己的定制分析器所使用。
开箱即用的 character filters
Elasticsearch 有许多内置的字符过滤器,可用于构建自定义分析器。
html_strip 字符过滤器去除像 <b> 这样的 HTML 元素并解码像 & 这样的 HTML 实体。
Mapping 字符过滤器用指定的替换替换任何出现的指定字符串。
pattern_replace 字符过滤器用指定的替换替换与正则表达式匹配的任何字符。
HTML strip (hmtl_strip) filter
顾名思义,此过滤器会从输入字段中去除不需要的 HTML 标记。 例如,当值为 <h1>Where is my cheese?</h1> 的输入字段被 HTML strip (html_strip) 字符过滤器处理时,<h1> 标签被清除,留下 “Where is my cheese? ”。 请注意,此过滤器不会触及单词的标点符号或大小写。 我们可以使用 _analyze API 测试 html_strip 字符,如以下清单所示:
POST _analyze
"text":"<h1>Where is my cheese?</h1>",
"tokenizer": "standard",
"char_filter": ["html_strip"]
上面命令返回的结果为:
"tokens": [
"token": "Where",
"start_offset": 4,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 0
,
"token": "is",
"start_offset": 10,
"end_offset": 12,
"type": "<ALPHANUM>",
"position": 1
,
"token": "my",
"start_offset": 13,
"end_offset": 15,
"type": "<ALPHANUM>",
"position": 2
,
"token": "cheese",
"start_offset": 16,
"end_offset": 22,
"type": "<ALPHANUM>",
"position": 3
]
从上面的输出中,我们可以看出来 <h1> 及 </h1> 这样的 tag 在分词中不见了。字符过滤器只是从输入字段中剥离 <h1> 标签,以生成 “Where”、“is”、“my”、“Cheese” 标记。 但是,可能需要避免为某些 HTML 标记解析输入字段; 例如,业务需求可能是从句子中去除 <h1> 标签,但保留预格式化 (<pre>) 标签。 例如,
<h1>Where is my cheese?</h1><pre>We are human beings that lookout for cheese constantly!</pre>幸运的是有一个方法。 我们可以配置 html_strip 过滤器来添加一个额外的 escaped_tags 数组,其中包含不需要被解析的标签列表。 让我们看看它的实际效果。 第一步是使用所需的自定义分析器创建索引,如下面的清单所示。
PUT index_with_html_strip_filter
"settings":
"analysis":
"analyzer":
"custom_html_strip_filter_analyzer":
"tokenizer":"keyword",
"char_filter":["my_html_strip_filter"]
,
"char_filter":
"my_html_strip_filter":
"type":"html_strip",
"escaped_tags":["pre"]
我们刚刚使用由 html_strip 字符过滤器组成的自定义分析器创建了一个索引。 显着的区别在于 html_strip 字符在此示例中被扩展为使用 escaped_tags 选项,因此由 <pre> 标签组成的字段将保持不变。 要对此进行测试,请运行以下清单中的代码,这证明了这一点。
POST index_with_html_strip_filter/_analyze
"text": "<h1>Hello,</h1> <pre>I am xiaoguo</pre>",
"analyzer": "custom_html_strip_filter_analyzer"
上面命令返回的结果为:
"tokens": [
"token": """
Hello,
<pre>I am xiaoguo</pre>""",
"start_offset": 0,
"end_offset": 39,
"type": "word",
"position": 0
]
此代码保留带有 <pre> 标记的单词,去除 <h1> 标记。
Mapping character filter
Mapping 字符过滤器的唯一工作是匹配一个键并将其替换为一个值。 正如我们在之前将希腊字母转换为英语单词的示例中看到的那样,Mapping 过滤器解析符号并将它们替换为单词:α 为 alpha,β 为 beta,等等。在我之前的文章 “Elasticsearch: analyzer” 有一个例子讲述如何把 X-Game 替换为 XGame。
我们可以测试映射字符过滤器。 例如,以下清单中的 CN 在使用 mapping 过滤器解析时将替换为 “中国”。
POST _analyze
"text": "I am from CN",
"char_filter": [
"type": "mapping",
"mappings": [
"CN => 中国"
]
]
上面的命令返回的结果为:
"tokens": [
"token": "I am from 中国",
"start_offset": 0,
"end_offset": 12,
"type": "word",
"position": 0
]
如果我们想创建一个带有配置的 Mapping 字符过滤器的自定义分析器,我们应该遵循相同的过程来创建一个带有分析器设置和所需过滤器的索引。 此代码示例显示自定义关键字分析器以附加字符映射过滤器的过程:
PUT index_with_mapping_char_filter
"settings":
"analysis":
"analyzer":
"my_social_abbreviations_analyzer":
"tokenizer": "keyword",
"char_filter": [
"my_social_abbreviations"
]
,
"char_filter":
"my_social_abbreviations":
"type": "mapping",
"mappings": [
"LOL => laughing out loud",
"BRB => be right back",
"OMG => oh my god"
]
我们现在已经创建了一个带有自定义分析器设置的索引,在字符过滤器中提供了一堆映射。 现在我们有了带有自定义分析器的索引,我们可以按照相同的过程使用 _analyze API 对其进行测试,如下面的清单所示:
POST index_with_mapping_char_filter/_analyze
"text": "LOL",
"analyzer": "my_social_abbreviations_analyzer"
上面的命令输出:
"tokens": [
"token": "laughing out loud",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
]
文本结果为“token”:“laughing out loud”,这表明 “LOL” 已替换为完整形式 “laughing out loud”。
在实际的使用中,如果我们的 mapping 列表比较长,而且放在命令中不容易维护。我们可以在 Elasticsearch 的安装目录下的 config 子目录下创建一个叫做 analysis 的目录。
$ pwd
/Users/liuxg/elastic/elasticsearch-8.6.1/config
$ mkdir analysis
$ cd analysis我们在这个目录下创建一个叫做 mappings.txt 的文件:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.6.1/config
$ mkdir analysis
$ cd analysis
$ vi mappings.txt
$ cat analysis/mappings.txt
LOL => laughing out loud
BRB => be right back
OMG => oh my god我们修改之前的命令如下:
PUT index_with_mapping_char_filter_file
"settings":
"analysis":
"analyzer":
"my_social_abbreviations_analyzer":
"tokenizer": "keyword",
"char_filter": [
"my_social_abbreviations"
]
,
"char_filter":
"my_social_abbreviations":
"type": "mapping",
"mappings_path": "analysis/mappings.txt"
注意:mappings_path 是包含 key => value 映射的文件的路径。此路径必须是绝对路径或相对于 config 位置的路径,并且文件必须是 UTF-8 编码的。 文件中的每个映射必须用换行符分隔。必须指定 mappings_path 或 mappings 参数。
运行上面的命令,我们将得到一样的结果。
Pattern replace character filter
pattern_replace 字符过滤器,顾名思义,当字段与正则表达式(regex)匹配时,将字符替换为新字符。 按照与映射过滤器相同的代码模式,让我们使用与模式替换字符过滤器关联的分析器创建一个索引。 以下清单中的代码正是这样做的。
PUT index_with_pattern_replace_filter
"settings":
"analysis":
"analyzer":
"my_pattern_replace_analyzer":
"tokenizer":"keyword",
"char_filter":["pattern_replace_filter"]
,
"char_filter":
"pattern_replace_filter":
"type":"pattern_replace",
"pattern":"_",
"replacement":"-"
此示例中的代码演示了一种机制,用于定义和开发带有 pattern_replace 字符过滤器的自定义分析器。 在这里,我们尝试匹配和替换我们的输入字段,将下划线 (_) 字符替换为破折号 (-)。 如果你按照以下代码清单所示测试分析器,我们会看到输出 “Apple-Boy-Cat” 将所有下划线替换为破折号。
POST index_with_pattern_replace_filter/_analyze
"text": "Apple_Boy_Cat",
"analyzer": "my_pattern_replace_analyzer"
上面的代码输出位:
"tokens": [
"token": "Apple-Boy-Cat",
"start_offset": 0,
"end_offset": 13,
"type": "word",
"position": 0
]
在我的另外一篇文章 “Elasticsearch:分词器中的 normalizer 使用案例” 中,我有展示如何使用 pattern_replace 过滤器来提取输入字符中的部分字符串。
在清理句子并清除不需要的字符的同时,仍然需要根据定界符、模式和其他标准将句子拆分为单独的分词。 该工作由分词器组件承担。请详细阅读另外一篇文章 “Elasticsearch: analyzer”。
以上是关于Elasticsearch:分析器中的 character filter 介绍的主要内容,如果未能解决你的问题,请参考以下文章