CryoEM粒子(Particle)类型预测的数据集构建
Posted SpikeKing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CryoEM粒子(Particle)类型预测的数据集构建相关的知识,希望对你有一定的参考价值。
通过cyroSPARC的2D Class模块,将冷冻电镜粒子图像,聚类为16个类型,构建模型,验证这16个类型的视觉区分度。
冷冻电镜图像:噪声(Noise )图像 和 低通滤波(Lowpass)图像
| Sample | Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 |
|---|---|---|---|---|---|
| Lowpass |  |  |  |  |  |
| Noise |  |  |  |  |  |
聚类平均图像(噪声强度0.9):清晰(Average)图像、噪声(Noise )图像 和 低通滤波(Lowpass)图像
| Sample | Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 |
|---|---|---|---|---|---|
| Lowpass |  |  |  |  |  |
| Noise |  |  |  |  |  |
| Average |  |  | 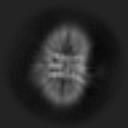 |  | 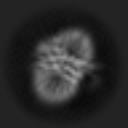 |
冷冻电镜图像
解析star和mrc文件,star是标签,mrc是原始图像。
star文件格式:
000001@extract/000000855321499642015_stack_1293_cor2_DW_particles.mrc J352/imported/000000855321499642015_stack_1293_cor2_DW.mrc 423 1246 103.775505 -0.450000 1.050000 300.000000 10000.000000 1.082500 13015.895508 12950.861328 9.064259 2.700000 0.000000 0.100000 0.000000 1 15
000002@extract/000000855321499642015_stack_1293_cor2_DW_particles.mrc J352/imported/000000855321499642015_stack_1293_cor2_DW.mrc 1821 3159 46.836731 -3.150000 1.350000 300.000000 10000.000000 1.082500 12611.307617 12546.273438 9.064259 2.700000 0.000000 0.100000 0.000000 1 16
解析单行star,将mrc图像与标签相对应:
mrc_name:000000855321499642015_stack_1293_cor2_DW_particles.mrc,mrc文件中的文件名idx:000001,mrc是3维矩阵,第1维表示多张图像,1表示编号第1个图像label:标签,2D Class的聚类标签
def parse_star_line(line, mrc_dir, max_items=19):
"""
解析star文件的行
"""
# 解析star的字段
items = line.split(" ")
if len(items) != max_items:
return
mrc_name = items[0].split("@")[1].split("/")[1] # mrc
mrc_idx = int(items[0].split("@")[0]) # idx
label = int(items[max_items - 1]) # 标签是最后一位
# 解析图像
mrc_path = os.path.join(mrc_dir, mrc_name)
mrc_arr = read_mrc(mrc_path) # mrc图像
img_r, img_n = get_particle_img(mrc_arr, mrc_idx) # 获取索引图像
return img_r, img_n, label
读取mrc文件:
def read_mrc(mrc_path):
"""
加载MRC文件
"""
mrc = mrcfile.open(mrc_path, permissive=True)
data = mrc.data
arr = np.zeros(shape=data.shape, dtype=data.dtype)
arr[:] = data[:]
return arr
获取特定索引的图像:索引从0开始,再正则化,支持设置最小值和最大值。
def norm_img(img, v_min=None, v_max=None):
"""
图像正则化
"""
if not v_min and not v_max:
v_min, v_max = np.min(img), np.max(img)
img = (img - v_min) / (v_max-v_min)
img = np.clip(img * 255, 0, 255)
return img
def get_particle_img(mrc_arr, mrc_idx, v_min=None, v_max=None):
"""
根据particle的索引提取图像,索引是从1开始
:param mrc_arr: mrc文件
:param mrc_idx: particle索引
:param v_min: 最小值
:param v_max: 最大值
:return: 图像
"""
img_r = np.squeeze(mrc_arr[mrc_idx - 1, :, :])
img_n = norm_img(img_r, v_min=v_min, v_max=v_max)
return img_r, img_n
解析star文件和mrc_dir文件夹:解析star的标注文件、确定数据起始行,前面是标签说明、逐行处理样本
def parse_star_lines(star_path, mrc_dir, p_start=23, n_sample=-1):
"""
解析star文件,输出样本数组(img, label)
"""
# 解析star的标注文件
with open(star_path, 'r', errors='ignore') as f:
output = f.readlines()
star_lines = [o.strip() for o in output]
# 确定数据起始行,前面是标签说明
star_lines = star_lines[p_start:]
if n_sample > 0: # 部分采样
n_sample = min(n_sample, len(star_lines))
star_lines = star_lines[:n_sample]
print(f'[Info] star: len(star_lines)')
# 逐行处理样本
samples = []
for line in tqdm(star_lines, desc="star"):
try:
img_r, img_n, label = parse_star_line(line, mrc_dir)
except Exception as e:
print(f'[Error] err line: line, exception: e')
continue
samples.append((img_r, img_n, label))
return samples
划分数据集,train、val、test:
def split_dataset(data_lines, gap=10):
"""
分离数据集为训练和验证
"""
print(f'[Info] samples: len(data_lines), gap: gap')
random.seed(42)
random.shuffle(data_lines)
n_gap = len(data_lines) // gap
val = data_lines[:n_gap]
test = data_lines[n_gap:n_gap*2]
train = data_lines[n_gap*2:]
print(f'[Info] train: len(train), val: len(val), test: len(test)')
return train, val, test
处理原始图像:低通滤波图像,输入是原始图像(非正则化)
def process_line(idx, sample, out_dir, flag):
"""
原始图像和低通滤波图像,写入图像至相应文件夹
:param idx: 索引
:param sample: 样本,即图像和标签
:param out_dir: 输出文件夹
:param flag: train\\val\\test
:return: None
"""
label = sample[-1] # 标签
img_r = sample[0] # 噪声样本,用于低通滤波的输入
img_n = sample[1] # 正则化的噪声样本
from low_pass.lowpass_filter import lowpass_filter_for_cryoem
img_lowpass = lowpass_filter_for_cryoem(img_r) # 低通滤波图像,输入是原始图像(非正则化)
# 存储raw图像
label_dir = os.path.join(out_dir, "raw", flag, str(label))
mkdir_if_not_exist(label_dir)
cv2.imwrite(os.path.join(label_dir, f"flag_idx.png"), img_n)
# 存储lowpass图像
label_dir = os.path.join(out_dir, "lowpass", flag, str(label))
mkdir_if_not_exist(label_dir)
cv2.imwrite(os.path.join(label_dir, f"flag_idx.png"), img_lowpass)
if len(sample) == 4: # 增加1维,聚类中心图像
img_avg = sample[2]
label_dir = os.path.join(out_dir, "average", flag, str(label))
mkdir_if_not_exist(label_dir)
cv2.imwrite(os.path.join(label_dir, f"flag_idx.png"), img_avg)
if idx % 100 == 0:
print('[Info] 已处理完成: '.format(idx))
数据集创建的函数:输入样本和数据集文件夹
def process_base(samples, out_dir):
train, val, test = split_dataset(samples) # 划分数据集
# 多进程处理样本
pool = Pool(processes=40)
for idx, sample in tqdm(enumerate(train), "train"):
# DatasetProcessor.process_line(idx, sample, out_dir, "train")
pool.apply_async(DatasetProcessor.process_line, (idx, sample, out_dir, "train"))
for idx, sample in tqdm(enumerate(val), "val"):
pool.apply_async(DatasetProcessor.process_line, (idx, sample, out_dir, "val"))
for idx, sample in tqdm(enumerate(test), "test"):
pool.apply_async(DatasetProcessor.process_line, (idx, sample, out_dir, "test"))
pool.close()
pool.join()
print(f'[Info] 全部处理完成: out_dir')
构建冷冻电镜粒子图像数据集:
- 构建cryoEM数据集,参数是:star文件,mrc粒子图像文件夹,out_dir输出文件夹
- 解析Particle样本 -> 划分数据集 -> 多进程处理样本
def process_from_star(star_path, mrc_dir, out_dir, is_mini=False):
"""
构建cryoEM的star数据集,参数是:star文件,mrc粒子图像文件夹,out_dir输出文件夹
"""
print(f'[Info] star_path: star_path')
print(f'[Info] mrc_dir: mrc_dir')
print(f'[Info] out_dir: out_dir')
mkdir_if_not_exist(out_dir)
if is_mini:
n_sample = 200 # mini样本数量
else:
n_sample = -1
# 解析Particle样本
samples = parse_star_lines(star_path, mrc_dir, p_start=23, n_sample=n_sample)
DatasetProcessor.process_base(samples, out_dir)
聚类平均图像
解析MRC图像函数:获取Particle图像的最小、最大值,归一化,存储于输出文件夹
def mrc_parser(mrc_path):
"""
读取MRC文件,获取Particle图像的最小、最大值,归一化,存储于输出文件夹
:param mrc_path: MRC文件
:return: None
"""
arr = read_mrc(mrc_path)
i_min, i_max = np.min(arr), np.max(arr)
imgs_r, imgs_n = [], []
for i in tqdm(range(arr.shape[0]), desc="particles"):
img_r, img_n = get_particle_img(arr, i+1, i_min, i_max)
imgs_r.append(img_r)
imgs_n.append(img_n)
return imgs_r, imgs_n
旋转粒子函数:
def rotate_particle(img, angle, out_wh=None):
"""
旋转粒子粒子图像,填充背景像素
:param img: 待旋转的图像
:param angle: 旋转角度,来源于_rlnAnglePsi,顺时针旋转
:param out_wh: 输出尺寸
:return: 旋转之后的图像
"""
bkg_val = int(np.argmax(np.bincount(img.flatten()))) # 背景像素,用于填充
# 旋转图像
img = ndimage.rotate(img, 360-angle, reshape=False, cval=bkg_val)
# 截取图像中心
if out_wh:
img = cv2.resize(img, out_wh)
return img
添加噪声函数:
def add_noise_to_particle(img, noise=0.90, out_size=(128, 128)):
"""
添加随机噪声至粒子图像
"""
img = cv2.resize(img, out_size)
h, w = img.shape[:2]
img_noise = (np.random.rand(h, w) * 255).astype(np.uint8)
img = cv2.addWeighted(img, 1 - noise, img_noise, noise, gamma=0)
return img
构建数据集:
- 噪声图像、低通滤波图像、聚类平均图像
- 加载聚类平均图像 -> 旋转图像 -> 添加噪声 -> 构建数据集
def process_from_average(avg_path, out_dir, is_mini=False):
"""
根据聚类中心构建数据集
"""
mkdir_if_not_exist(out_dir)
imgs_r, imgs_n = mrc_parser(avg_path) # 加载图像
# 不同角度的样本数据
samples = []
for label, (img_r, img_n) in tqdm(enumerate(zip(imgs_r, imgs_n))):
for i in range(360):
img_n_out = rotate_particle(img_n, i, out_wh=(128, 128))
img_n_noise = add_noise_to_particle(img_n_out, noise=0.9)
# 增加avg图像
samples.append((img_n_noise, img_n_noise, img_n_out, label))
if is_mini: # 是否mini数据集
random.seed(42)
random.shuffle(samples)
samples = samples[:200] # mini采样数量
DatasetProcessor.process_base(samples, out_dir)
以上是关于CryoEM粒子(Particle)类型预测的数据集构建的主要内容,如果未能解决你的问题,请参考以下文章
unity5.1 particle systems怎么控制粒子速度
Unity学习——粒子系统(Particle System)