Kafka超详细知识点汇总(基础篇)
Posted 大数据程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka超详细知识点汇总(基础篇)相关的知识,希望对你有一定的参考价值。
1.Kafka介绍
1.1概念
kafka是一个开源的分布式应用,是基于发布/订阅模式的消息队列,主要用于大数据领域的实时处理.通俗的理解就是一个特大号的Channel(用于存储,管理数据的),它可以把接收的数据按主题分类好摆放在货架上,并且提供 管理服务,需要用到数据的一方主动从货架上取数据.
消息队列:相当于一个容器,并且能按照一定的规则将需要处理的消息进行排序(比如按照访问时间,事情的重要性程度等).
Kafka未来的发展方向:分布式事件流平台,高性能的数据管道,流分析,数据集成和关键任务应用.
1.2Kafka提供的服务是什么
1. 提供海量数据的存储服务,并且高可靠性
2.能以高效的方式处理海量消息
3.保证数据的有序性
1.3Kafka基本架构
由生产者,broker,消费者三部分组成.
生产者:生产数据的一方
broker:负责存储,管理数据的,一个大号的channel
消费者:用数据的一方,比如flink,spark等;
其中:老版本用到组件zookeeper,存储关键信息,比如集群有哪些服务器,各服务器的角色分工等,本篇是基于kafka-zookeeper模式的介绍
由于存在网络传输,且不同框架之间配合的版本问题,之后的kafka不再依赖zookeeper,将上述的工作放在自身的框架之内完成(Kafka-Kraft模式),后续章节介绍.

1.4官网
1.5学习本节内容需要掌握的单词
单词 | 释义 | 单词 | 释义 |
broker | 经纪人 | daemon | 后台程序 |
segment | 片段 | compact | 紧凑的 |
sticky | 粘性 | millisecond | 毫秒 |
coordinator | 协调人 | offset | 偏移量 |
retention | 保留 | policy | 策略 |
permission | 许可证 | deny | 否认,拒绝 |
replica | 副本 |
2.Kafka原理
2.1生产者消息发送流程
2.1.1发送原理

Kafka的Producer发送消息采用的是 异步发送的方式。
在消息发送的过程中,涉及到了 两个线程: main线程和 Sender线程,以及一个 线程共享变量:RecordAccumulator。
①main线程中创建了一个双端队列RecordAccumulator,将消息发送给RecordAccumulator。
②Sender线程不断从RecordAccumulator中拉取消息发送到Kafka broker。
RecordAccumulator:相当于生产者的仓库,将生产的数据暂存到这里,默认值32M
2.1.2partition分区
2.1.2.1分区优点
1. 提高并行度,生产者根据分区发送数据,消费者根据分区进行消费
2. 存储资源更加合理.通过分区将大量的数据分割成一块一块的,方便存储与管理
2.1.2.2分区策略
三种策略.
1. 可指定数据存储分区
2.没有指明但有key时,根据key的hash值与topic的分区数进行取余得到分区值
3.没有key的情况下,采用黏性分区.开始会随机选择一个分区,后面尽可能一直使用该分区.待该分区的batch已满或者已完成,再随机选择一个分区(与之前不同)
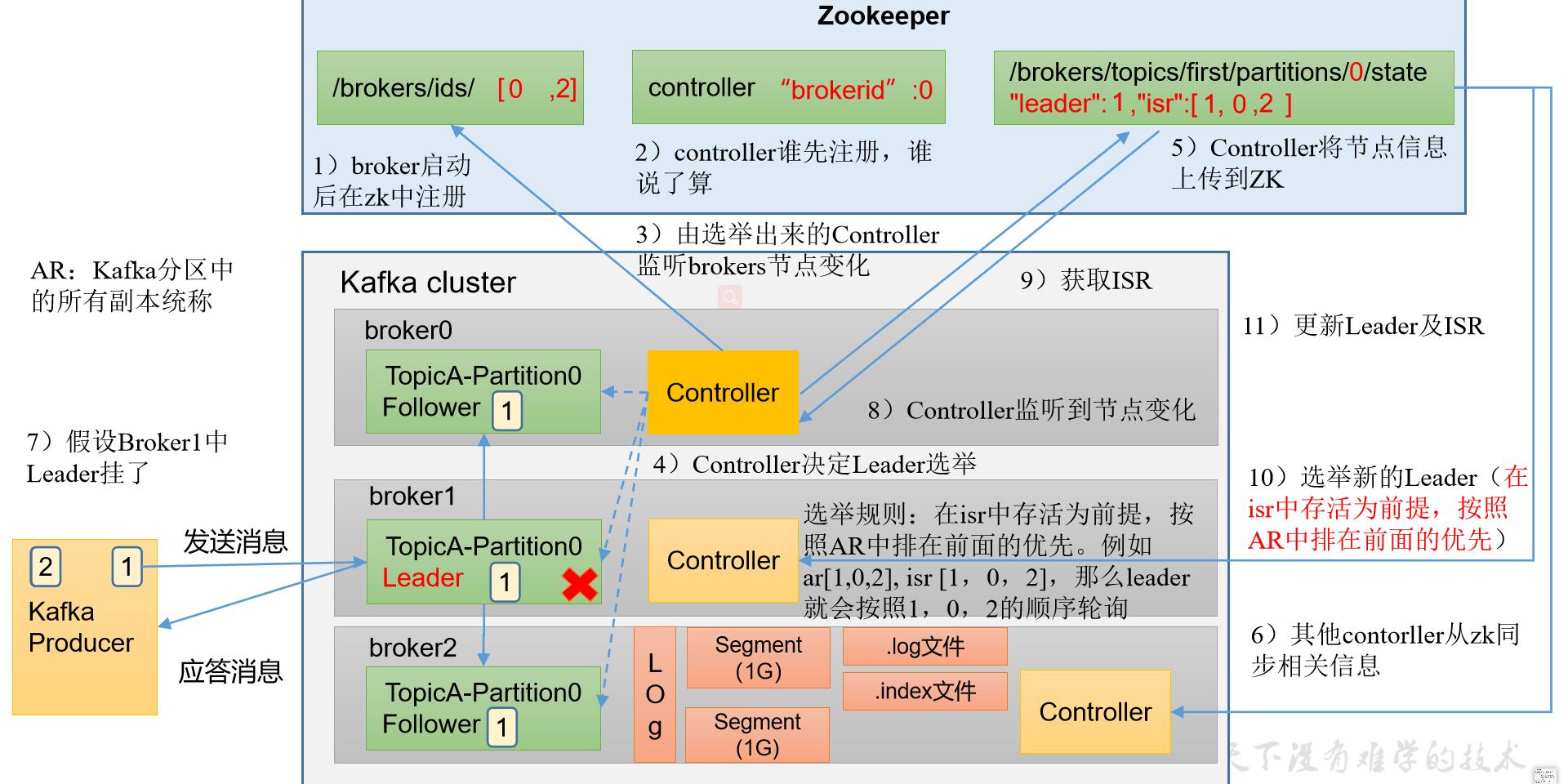
2.2 Broker 工作流程
2.2.1工作原理
2.2.2 Kafka副本
2.2.2.1副本信息
kafka副本作用 | 提高数据可靠性 |
kafka副本个数 | 默认1个,生产环境中一般配置为2个,保证数据可靠性;但是过多的副本会增加磁盘存储空间、增加网络数据传输、降低kafka效率。 |
kafka副本角色 | 副本角色分为Leader和Follower。kafka生产者只会把数据发送到Leader,follower会主动从Leader上同步数据。 |
kafka中的AR | 是所有副本的统称(Assigned Repllicas),AR = ISR + OSR ISR:表示和Leader保持同步(默认30s)的follower集合。 OSR:表示Follower与Leader副本同步时,延迟过多的副本。 |
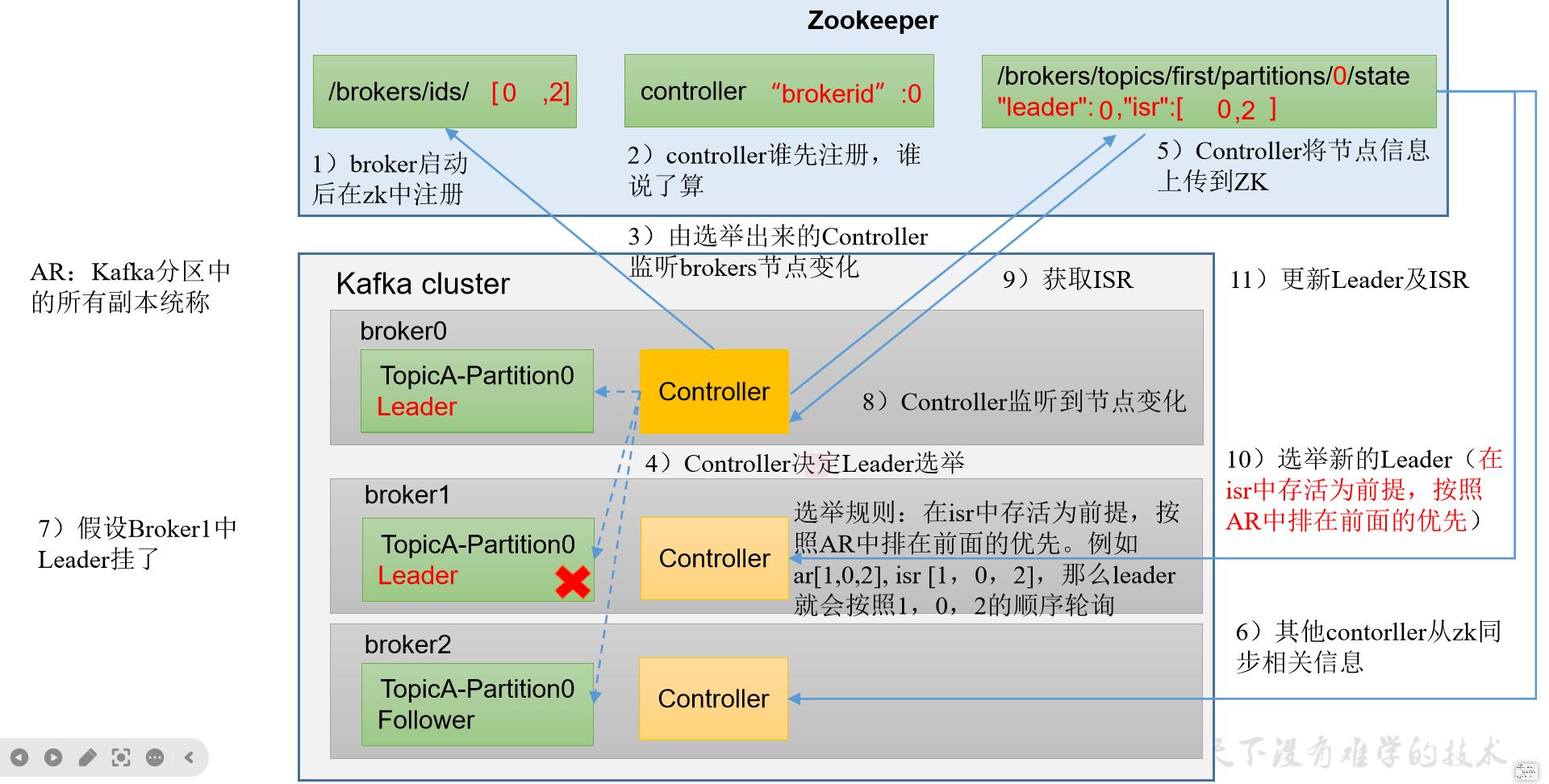
2.2.2.2leader选举
kafka集群中有一个broker的Controller会被选举为Controller Leader,负责管理集群broker的上下线、所有的topic的分区副本分配和Leader选举等工作。Controller的信息同步工作是依赖于Zookeeper的。
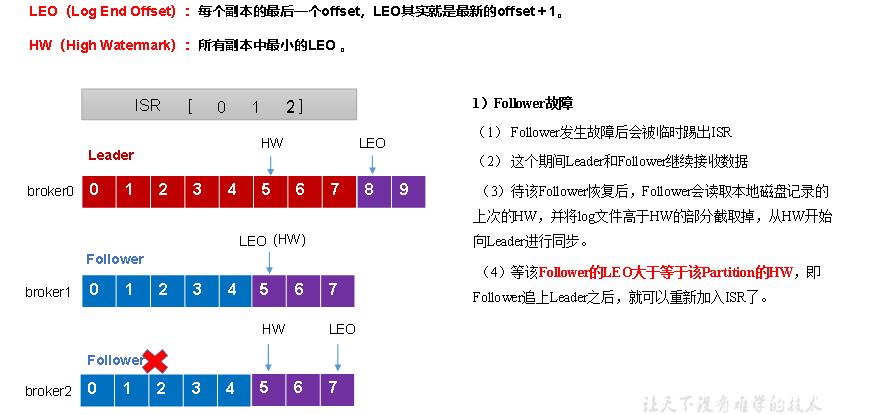
2.2.3 leader和 follower故障处理细节
follower故障处理细节
leader故障处理细节
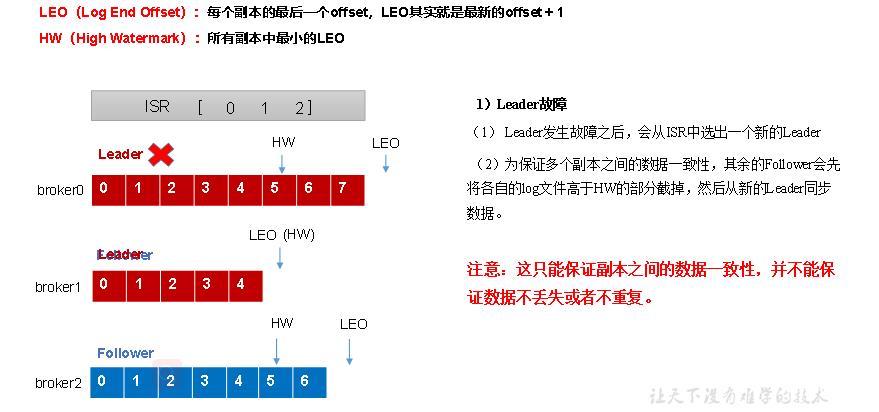
总结:
LEO:指的是每个副本最大的offset;
HW:指的是消费者能见到的最大的offset,ISR队列中最小的LEO。
(1)follower故障
follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。等该 follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
(2)leader故障
leader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件 高于HW的部分截掉,然后从新的leader同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
2.2.4文件存储
2.2.4.1文件存储机制

2.2.4.2 index文件和log文件详解

offset是偏移量
position是偏移量对应的物理磁盘的位置
2.3消费者工作流程
2.3.1消费者总体工作流程
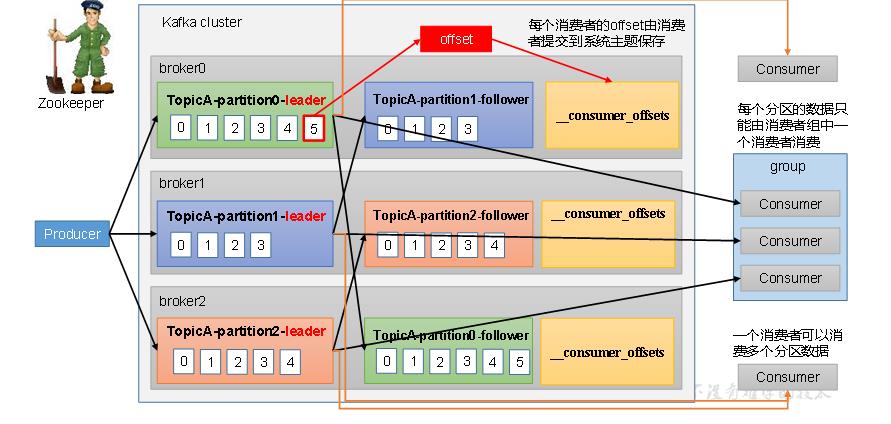
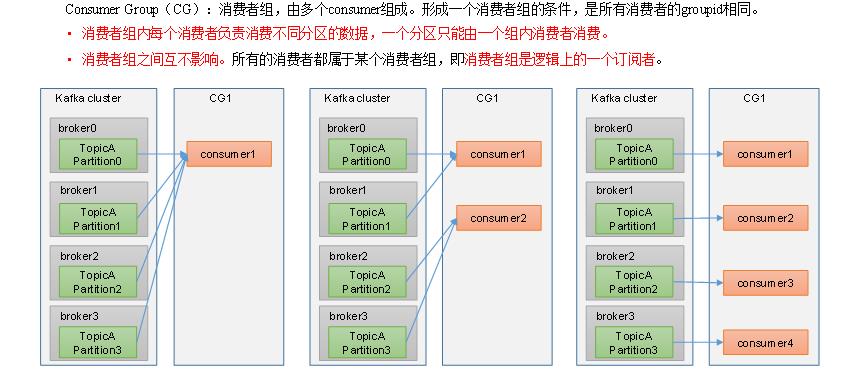
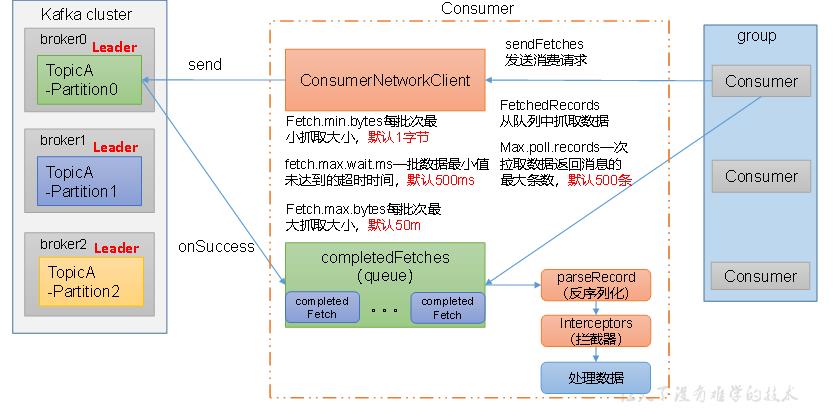
2.3.2补充
1.消费者组内的数据不能消费同一个分区, 为了避免数据重复
2.消费者组之间消费互不影响.
3.Kafka实操
3.1kafka集群 启动/关闭 步骤
先启后停:先启动zookeeper,后启动kafka,同样先停止kafka,再停止zookeeper
3.2Kafka组件开启步骤
思路:先定义broker主题数及分区数----数据往哪儿存
其次:开启生产者,录入数据或者API操作也可(后面讲) -----生产数据
最后:开启消费者,-----消费者消费数据
3.3操作行命令
3.3.1 broker命令行
kafka的安装这里不再进行介绍, 以下的操作到安装kafka的家目录下进行操作:
查看主题命令行的参数: bin/kafka-console-producer.sh
参数 | 描述 |
--bootstrap-server | 连接kafka Broker主机名称和端口号 |
--topic | 操作的topic名称 |
--create | 创建主题 |
--delete | 删除主题 |
--alter | 修改主题 |
--list | 查看所有主题 |
--describe | 查看主题详细描述 |
--partitions | 设置主题分区数 |
--replication-factor | 设置主题分区副本 |
--config | 更新系统默认的配置 |
# 查看当前服务器中的所有topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list
# 创建一个主题名为first的topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --replication-factor 3 --partitions 1 --topic first
# 修改分区数(注意:分区数只能增加,不能减少)
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 33.3.2生产者命令行
查看命令行生产者的参数: bin/kafka-console-producer.sh
参数 | 描述 |
--bootstrap-server | 连接kafka Broker主机名称和端口号 |
--topic | 操作的topic名称 |
启动生产者,生产消息
bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
>hello world
>laotie 6663.3.3消费者命令行
查看命令行消费者的参数:bin/kafka-console-consumer.sh
参数 | 描述 |
--bootstrap-server | 连接kafka Broker主机名称和端口号 |
--topic | 操作的topic名称 |
--from-beginning | 从头开始消费 |
--group | 指定消费者组名称 |
消费消息
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first📊📊📊文本为学习之余,梳理的知识点,有初学的小伙伴可以慢慢研究,有疑惑的地方可在下方留言,欢迎大家随时交流.
📊📊📊如果有喜欢的小伙伴,欢迎点赞,收藏及留言,谢谢你们😘~
📊📊📊如有错误之处,请随时指正!!!

以上是关于Kafka超详细知识点汇总(基础篇)的主要内容,如果未能解决你的问题,请参考以下文章
超详细:这份全网首发的Kafka技术手册,从基础到实战一应俱全