如何爬取网站上的某一信息?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何爬取网站上的某一信息?相关的知识,希望对你有一定的参考价值。
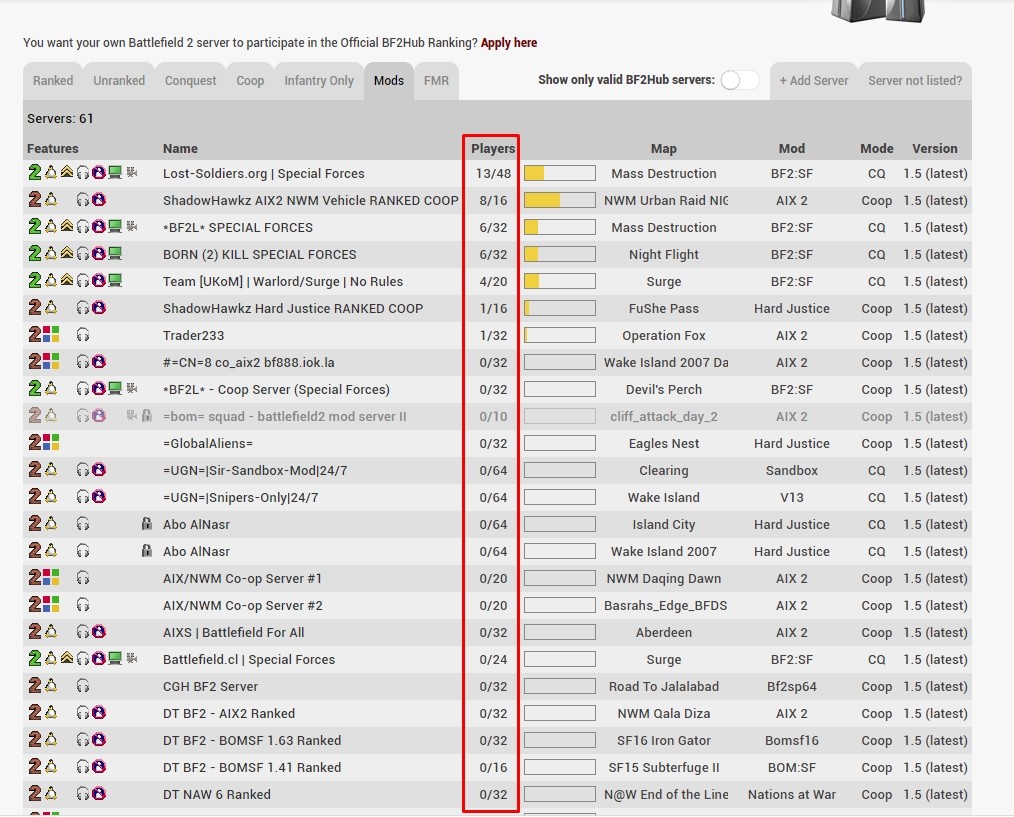
这是要爬取的网址: https://www.bf2hub.com/servers/mods/其中要爬取的信息如图所示,是一些游戏服务器的在线人数信息。我想定时(比如每隔30分钟)采集一次信息,自动进行。最后得出这个服务器的日在线人数变化。有没有比较简单的方法?
一、开放API的网站
一个网站如果开放了API,那么就可以直接GET到它的json数据。有三种方法可以判断一个网站是否开放了API。
1、在站内寻找API入口;
2、用搜索引擎搜索“某网站API”;
3、抓包。有的网站虽然用到了ajax,但是通过抓包还是能够获取XHR里的json数据的(可用抓包工具抓包,也可以通过浏览器按F12抓包:F12-Network-F5刷新)。
二、不开放API的网站
1、如果网站是静态页面,那么可以用requests库发送请求,再通过html解析库(lxml、parsel等)来解析响应的text;解析库强烈推荐parsel,不仅语法和css选择器类似,而且速度也挺快,Scrapy用的就是它。
2、如果网站是动态页面,可以先用selenium来渲染JS,再用HTML解析库来解析driver的page_source。 参考技术A 你可以使用爬虫spider,也可以自己用python或者golang写一个抓取脚本,之后加入定时任务,设置每30分钟执行一次即可。对一个页面的数据抓取,并进行解析,还是非常简单的。本回答被提问者采纳 参考技术B 最简单的就是用爬虫
以上是关于如何爬取网站上的某一信息?的主要内容,如果未能解决你的问题,请参考以下文章