vit-pytorch实现 MobileViT注意力可视化
Posted 白十月
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了vit-pytorch实现 MobileViT注意力可视化相关的知识,希望对你有一定的参考价值。
项目链接 https://github.com/lucidrains/vit-pytorch
注意一下参数设置:
Parameters
- image_size: int.
Image size. If you have rectangular images, make sure your image size is the maximum of the width and height - patch_size: int.
Number of patches. image_size must be divisible by patch_size.
The number of patches is: n = (image_size // patch_size) ** 2 and n must be greater than 16. - num_classes: int.
Number of classes to classify. - dim: int.
Last dimension of output tensor after linear transformation nn.Linear(…, dim). - depth: int.
Number of Transformer blocks. - heads: int.
Number of heads in Multi-head Attention layer. - mlp_dim: int.
Dimension of the MLP (FeedForward) layer. - channels: int, default 3.
Number of image’s channels. - dropout: float between [0, 1], default 0…
Dropout rate. - emb_dropout: float between [0, 1], default 0.
Embedding dropout rate. - pool: string, either cls token pooling or mean pooling
image_size:表示图像大小的整数。图片应该是正方形的,并且image_size必须是宽度和高度中的最大值。
patch_size:表示补丁大小的整数。image_size必须能被 整除patch_size。补丁的数量计算为n =
(image_size // patch_size) ** 2并且n必须大于 16。 num_classes:一个整数,表示要分类的类数。
dim:一个整数,表示线性变换后输出张量的最后一维nn.Linear(…, dim)。 depth:一个整数,表示
Transformer 块的数量。 heads:一个整数,表示多头注意力层中的头数。 mlp_dim:一个整数,表示
MLP(前馈)层的维度。 channels:一个整数,表示图像中的通道数,默认值为3。 dropout:一个介于 0 和 1
之间的浮点数,代表辍学率。 emb_dropout:一个介于 0 和 1 之间的浮点数,表示嵌入丢失率。
pool:表示池化方法的字符串,可以是“cls token pooling”或“mean pooling”。
快速使用实例
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)
SimpleViT
来自原论文的一些作者的更新建议对ViT进行简化,使其能够更快更好地训练。
这些简化包括2d正弦波位置嵌入、全局平均池(无CLS标记)、无辍学、批次大小为1024而不是4096,以及使用RandAugment和MixUp增强。他们还表明,最后的简单线性并不明显比原始MLP头差。
你可以通过导入SimpleViT来使用它,如下图所示
import torch
from vit_pytorch import SimpleViT
v = SimpleViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)
可视化
Accessing Attention
If you would like to visualize the attention weights (post-softmax) for your research, just follow the procedure below
import torch
from vit_pytorch.vit import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
# import Recorder and wrap the ViT
from vit_pytorch.recorder import Recorder
v = Recorder(v)
# forward pass now returns predictions and the attention maps
img = torch.randn(1, 3, 256, 256)
preds, attns = v(img)
# there is one extra patch due to the CLS token
attns # (1, 6, 16, 65, 65) - (batch x layers x heads x patch x patch)
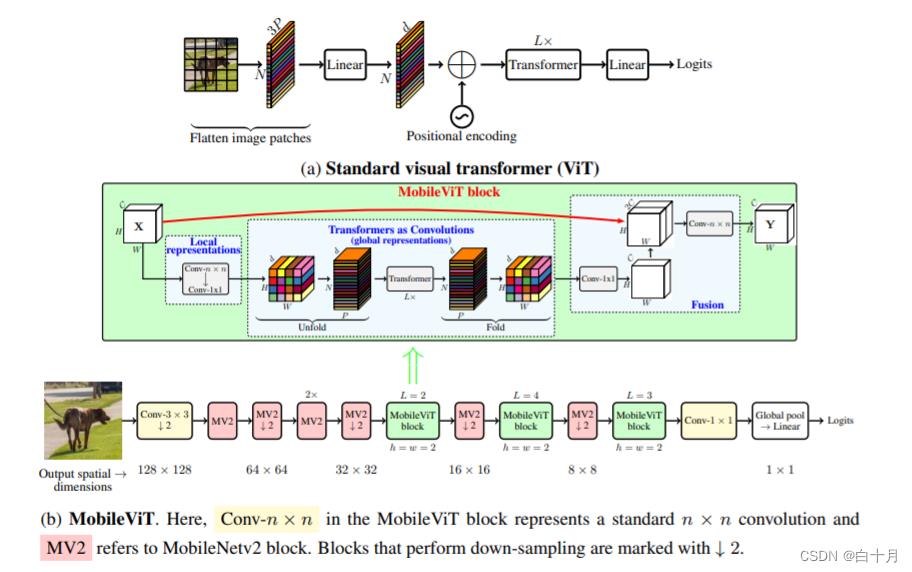
本文介绍了 MobileViT,一种用于移动设备的轻量级通用视觉转换器。MobileViT 为全球信息处理与转换器提供了不同的视角。
您可以将其与以下代码一起使用(例如 mobilevit_xs)
import torch
from vit_pytorch.mobile_vit import MobileViT
mbvit_xs = MobileViT(
image_size = (256, 256),
dims = [96, 120, 144],
channels = [16, 32, 48, 48, 64, 64, 80, 80, 96, 96, 384],
num_classes = 1000
)
img = torch.randn(1, 3, 256, 256)
pred = mbvit_xs(img) # (1, 1000)
以上是关于vit-pytorch实现 MobileViT注意力可视化的主要内容,如果未能解决你的问题,请参考以下文章
FasterNet:CVPR2023年最新的网络,基于部分卷积PConv,性能远超MobileNet,MobileVit
芒果改进YOLOv7系列:全网首发最新 ICLR2022 顶会|轻量通用的MobileViT结构Transformer,轻量级通用且移动友好的视觉转换器,高效涨点