目标检测SSD基本思想和网络结构以及论文补充
Posted Jul7_LYY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测SSD基本思想和网络结构以及论文补充相关的知识,希望对你有一定的参考价值。
论文题目:Single Shot MultiBox Detector
论文链接:论文链接
文章目录
一、SSD的引入

1.SSD的创新点
Faster-RCNN存在的问题:1.对小目标检测效果很差 2.模型大,检测速度较慢
1.SSD,YOLOV3和FasterRCNN的RPN都使用了全卷积神经网络
2.一共有6个特征预测层,不同检测层有不同大小的滑动窗口,能够检测到不同大小的目标。低层预测小目标,高层预测大目标。(多尺度检测)
3.设置了多种宽高比的anchor(不同特征预测层也有所不同,看下文)
4.使用了数据增强(对原图有放大缩小)
2.SSD的缺点及优化
1.主要缺点:SSD对小目标的检测效果一般,作者认为小目标在高层没有足够的信息。
对小目标检测的改进可以从下面几个方面考虑:
1. 增大输入尺寸
2. 使用更低的特征图做检测(比如S3FD中使用更低的conv3_3检测)
3. FPN(已经是检测网络的标配了)
2.关于anchor的设置的优化
论文中提到的anchor设置没有对齐感受野,通常几个像素的中心位置偏移,对大目标来说IOU变化不会很大,但对小目标IOU变化剧烈,尤其感受野不够大的时候,anchor很可能偏移出感受野区域,影响性能。
关于anchor的设计,作者还提到了
In practice, one can also design a distribution of default boxes to best fit a specific dataset. How to design the optimal tiling is an open question as well
论文提到根据特定数据集设计default box,在YOLOV2中使用聚类的方式初始化anchor,能够更好的匹配到ground truth,帮助网络更好的训练
3.如何从分类网络到预测网络?
首先,要理解VGG,ResNet等最后都会使用全连接层提取特征,然后经过softmax计算每一类的概率。缺点:1.最终分类的预测是对整张图片进行预测的,如果一张图片中出现多个目标,就不能单纯使用分类网络,要把最后的全连接层换做卷积层 2.由于全连接层的存在,网络的输入大小必须是固定的
由于使用全连接层提取特征,所以提取的是全图的特征,所以一张图像中只能包含一个目标,如果有多个目标,提取出来的特征就不准确,影响最后的预测
4.如何提取多个目标的特征?
1.使用卷积层代替全连接层进行特征提取
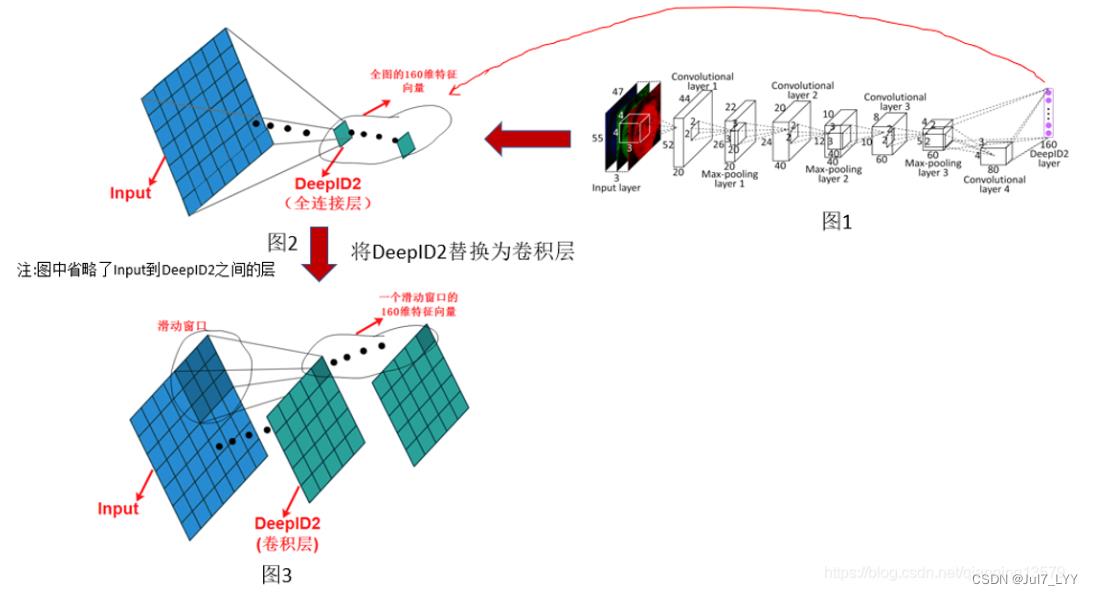
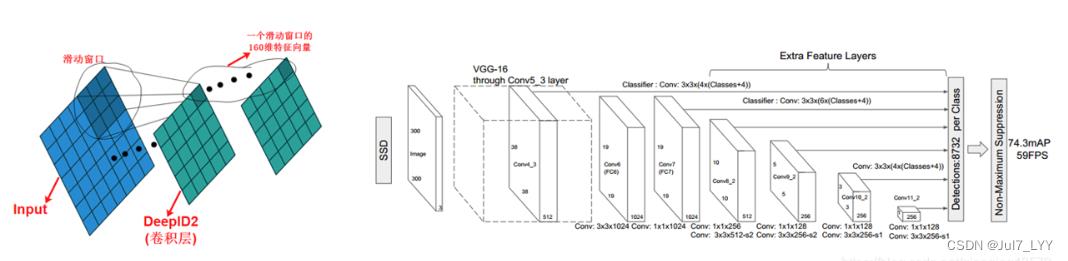
我们将图1简化为图2的表示形式,其中图2中省略了Input到DeepID2中间的层,我们看到当DeepID2是全连接层的时候,感受野对应了全图,所以提取的是全图的特征,现在我们把DeepID2替换为卷积层,其中卷积层的输出通道数为160,这是为了能够提取160维的特征向量,图3中我们可以看到当使用卷积层的时候,DeepID2的输出特征图的每个位置的感受野不是对应了全图,而是对应了原图的某一个滑动窗口,这样DeepID2这一层就可以提取原图多个滑动窗口的特征了,图3中我们可以看到一共提取出了25个滑动窗口的160维特征向量,然后我们就可以对这25个滑动窗口做分类了。这样就使得检测成为了可能。
2.使用卷积层代替全连接层进行分类
我们知道在分类网络中softmax的前一层使用的是全连接层,且该全连接层的输出节点数为分类数,比如上文中的DeepID2的后面的fc2层。
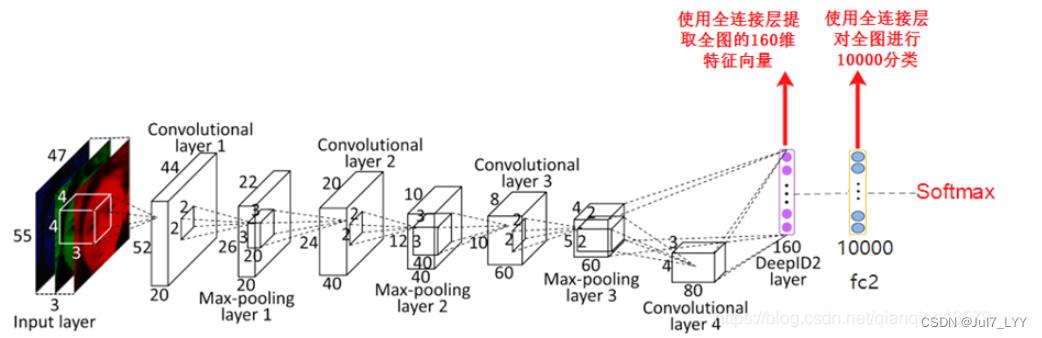
但是现在DeepID2这一层变成了卷积层之后,fc2层就不适合采用全连接层了。下面我们将fc2层替换为卷积层,我们采用1x1卷积(也可以使用3x3卷积),同时卷积层的输出通道数为10000,对应了10000分类。
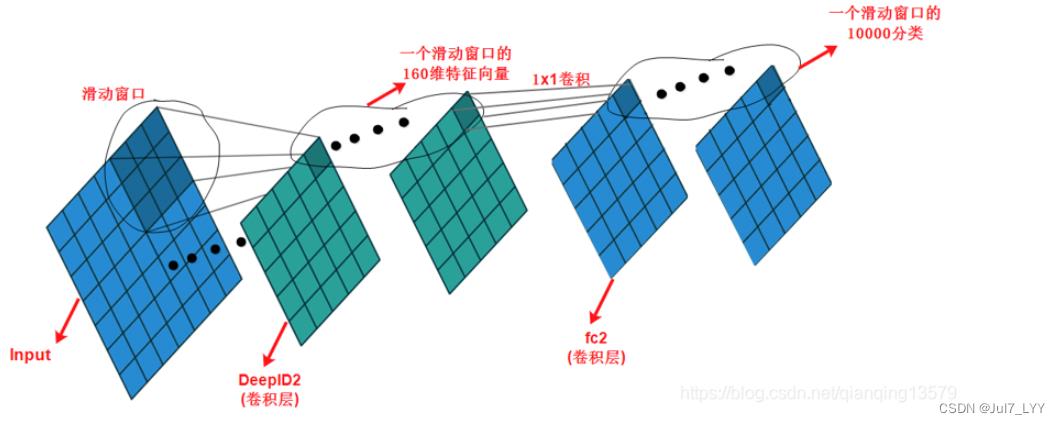
我们看到当fc2采用1x1卷积的时候,fc2层的特征图中的每个位置对应了一个滑动窗口的10000分类,这样一共得到25x10000的特征向量,表示对25个滑动窗口的10000分类。最后将这25x10000的特征向量输入softmax,就可以实现对这25个滑动窗口的分类了。
这其实就是经典的OverFeat的核心思想。
什么是OverFeat?
OverFeat说的简单一点就是特征提取算子,就相当于SIFT,HOG等这些算子一样。
简单的来说就是,在于充分利用了卷积神经网络的特征提取功能,它把分类过程中,提取到的特征,同时又用于定位检测等各种任务。只需要改变网络的最后几层,就可以实现不同的任务,而不需要从头开始训练整个网络的参数。
其主要是把网络的第一层到第五层看做是特征提取层,然后不同的任务共享这个特征提取层。基本用了同一个网络架构模型(特征提取层相同,分类回归层根据不同任务稍作修改、训练)、同时共享基础特征。
注意:
这里并没有说检测网络不能使用全连接层,其实检测网络也可以使用全连接层。检测网络只是使用卷积层代替全连接层提取特征,最后对特征进行分类和回归可以使用卷积层也可以使用全连接层,YOLOV1最后就使用了全连接层对特征进行分类和回归,只是这样会有一些缺点:网络的输入大小必须是固定的,而且最后检测的效果往往没有使用卷积层做分类和回归的效果好。
3.如何确定每个滑动窗口的类别?(引入anchor)
上文中,我们将传统的分类网络一步一步的修改成了一个检测网络,知道了如何提取多个目标的特征以及使用卷积层代替全连接层进行分类,现在我们还差最后一步:要对多个目标进行分类,还需要知道他们的groundtruth,也就是他们的类别,那么如何确定类别呢?这里就要用到anchor这项技术。anchor就是用来确定类别的。
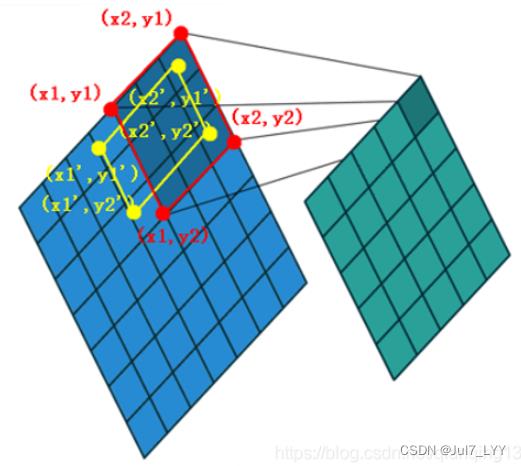
我们知道anchor的参数是可以手动设置的,上图中
anchor的大小被设置为 [x1,y1,x2,y2],这个anchor就是上文中提到的滑动窗口
groundtruth对应 [x1’,y1’,x2’,y2’]
然后通过计算anchor和groundtruth之间的IOU就可以确定这个滑动窗口的类别了(比如IOU>0.5的为正样本,IOU<0.3的为负样本)。
SSD的整体框架已经基本搭建好了。其实SSD的多个检测层就等价于多个DeepID2层,不同检测层有不同大小的滑动窗口,能够检测到不同大小的目标。每个检测层后面会接2路3x3卷积用来做分类和回归,对应了fc2层。
二、SSD框架解析
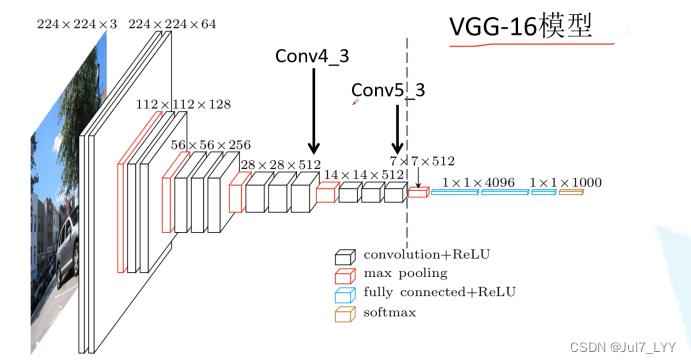
1.SSD框架与VGG16的关系

虚线方框对应下边虚线前边的一部分,conv4-3是第一个预测特征层,上述黄线标注部分代表,之前池化缩减一半,现在保持不变。conv7是第二个预测特征层。conv8-2第三个预测特征层,以此类推…
2.图像解释框架为什么使用多尺度?
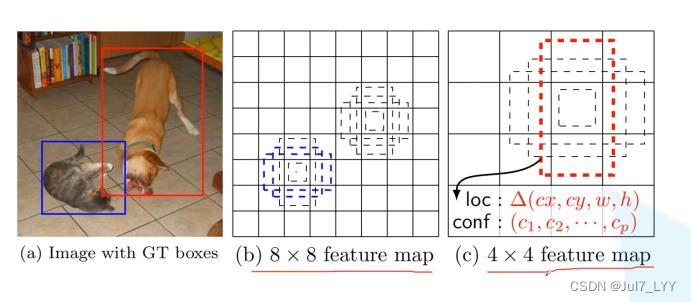
较低层的匹配小目标,高层的匹配相对大点的目标。(这样能更好的吻合)
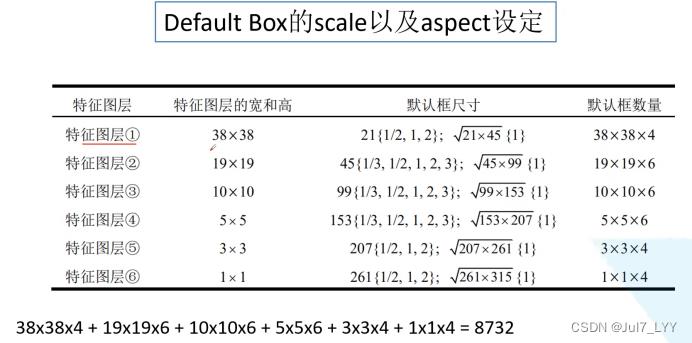
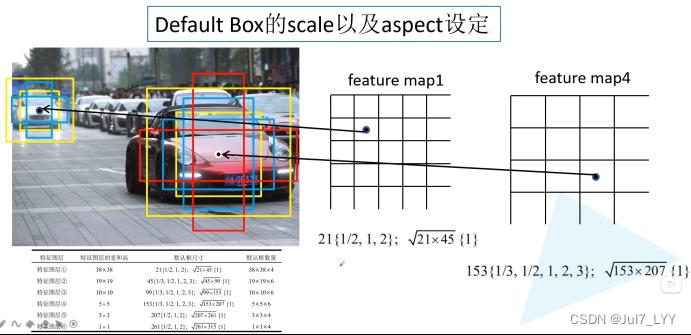
3.Default Box的引入

因为代码和原论文尺度不相符,故上述公式不做详细解释

这里的尺度为什么有两个参数呢?因为原公式中有Sk和Sk+1,后边的anchor比例要加上1:根号Sk*Sk+1这个比例
4.如何在6个预测特征层上预测?预测器如何实现?


在每个特征层上使用3*3的卷积去生成预测类别的概率和default box的坐标偏移量。

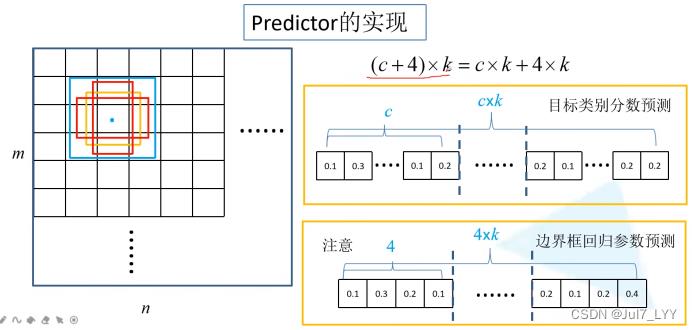
这里的c是包含背景类别的。
5.fasterrcnn和ssd边界框回归参数的不同点
在fasterrcnn生成anchor时,会生成4c个边界框,每一个anchor会去生成每一个目标类别的边界框回归参数。
在ssd当中,每一个default box只生成4个边界框回归参数,不关注每一个default box是属于哪个类别的。(dfbox和类别没有关系)
6.正负样本的选取问题
1.正样本的两种方式选取
1.取与真实预测框最大匹配的default box
2.取与真是预测框IOU大于0.5的default box
2.负样本的选取
如果把除了正样本以外的全部当成负样本来用,那么就太多了,正样本可能只有十几个,但是default box有八千多个,如果这么选取会导致样本不平衡。
对剩下的负样本计算最大置信度损失,从大到小选取,大概选取的比例是正样本:负样本=1:3
7.损失的计算
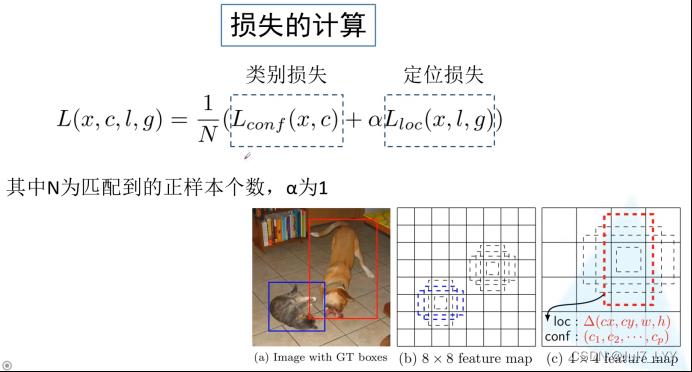

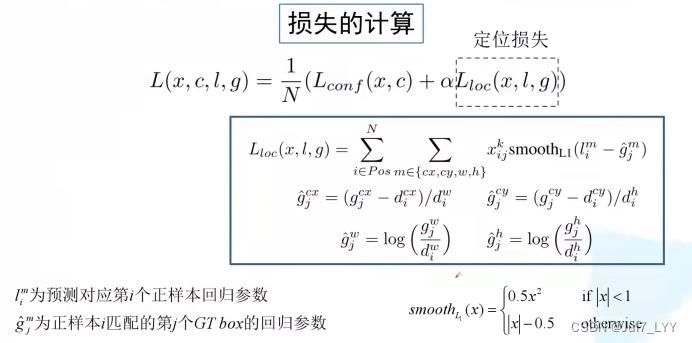
定位损失只针对正样本,因为负样本没有对应的GT
三、经常遇到的一些小问题
1.为什么anchor可以设置实际响应的区域?
这就是CNN的神奇之处,这个问题目前我还不知道如何解释,就像目前的深度学习依然是不可解释的一样,这点就当作一个结论记住就可以了。
2.为什么同一个检测层可以设置不同大小的anchor?
我们知道可以通过anchor设置每一层实际响应的区域,使得某一层对特定大小的目标响应。
是否每一层只能对理论感受野响应呢?有效感受野理论表明,每一层实际响应的区域其实是有效感受野区域,而且这个有效感受野区域在训练过程中会发生变化(比如不同数据集的影响等),正是由于有效感受野有这个特性,所以我们可以在同一个检测层设置不同大小的anchor,也就是说你既可以设置anchor大小为理论感受野大小,也可以将anchor大小设置为其他大小,最后训练出来的网络会根据你的设置对特定大小的区域响应。
3.为什么在同一个特征图上可以设置多个anchor检测到不同尺度的目标?
刚开始学SSD的朋友一定有这样的疑惑,同一层的感受野是一样的,为什么在同一层可以设置多个anchor,然后在分类和回归两个分支上只需要使用不同通道的3x3卷积核就可以实现对不同anchor的检测?虽然分类和回归使用的是同一个特征图,但是不同通道的3x3卷积核会学习到那块区域的不同的特征,所以不同通道对应的anchor可以检测到不同尺度的目标。
anchor本身不参与网络的实际训练,anchor影响的是classification和regression分支如何进行encode box(训练阶段)和decode box(测试阶段)。测试的时候,anchor就像滑动窗口一样,在图像中滑动,对每个anchor做分类和回归得到最终的结果。
以上是关于目标检测SSD基本思想和网络结构以及论文补充的主要内容,如果未能解决你的问题,请参考以下文章
谈谈基于深度学习的目标检测网络为什么会误检,以及如何优化目标检测的误检问题