[模型学习]Attention机制及其原理推导
Posted Amigo_5610
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[模型学习]Attention机制及其原理推导相关的知识,希望对你有一定的参考价值。
Attention的基本原理
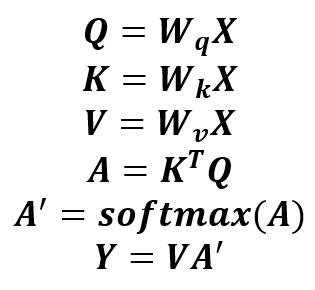
Attention基本原理
在该公式中,X为输入矩阵
1.1 步骤1
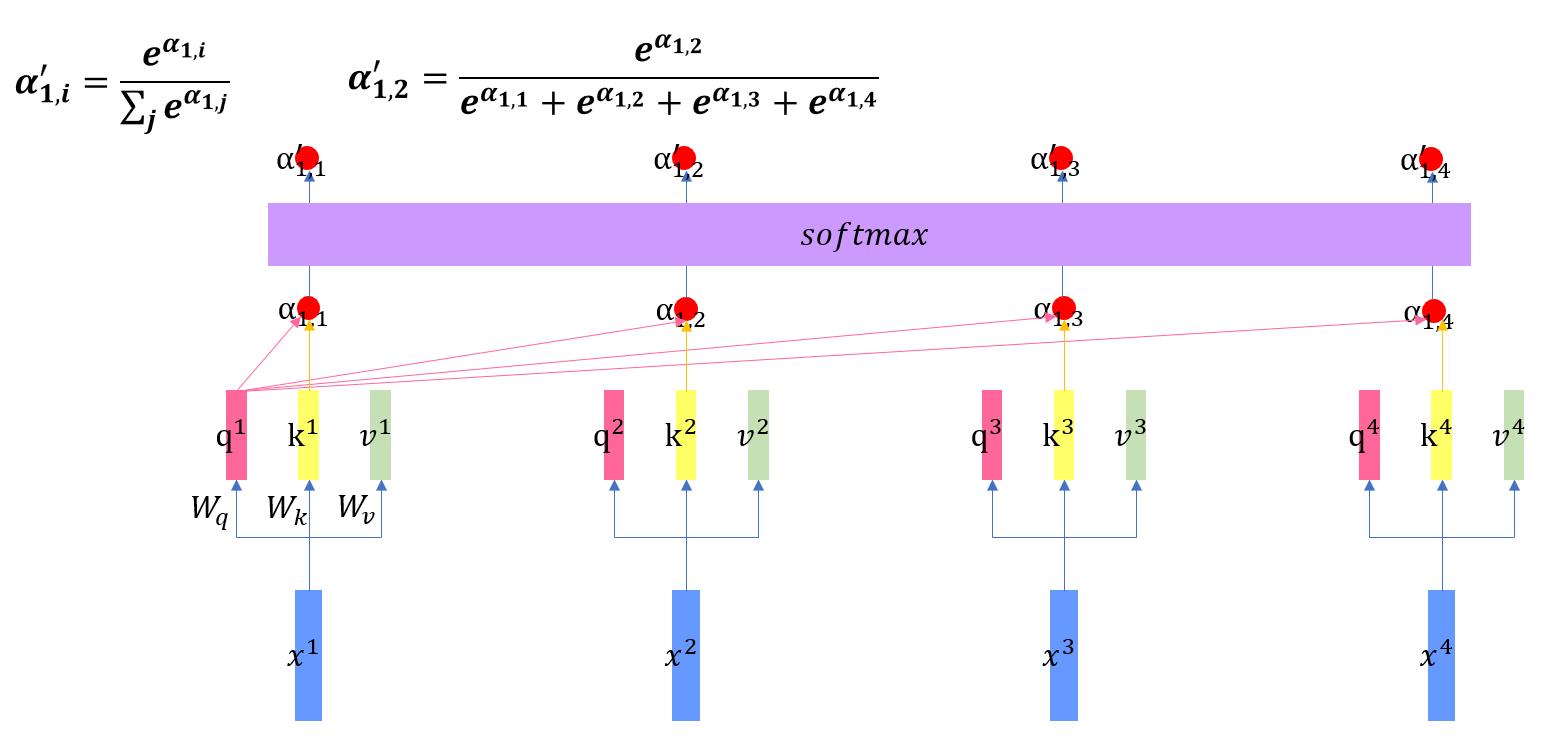
注意力机制步骤1
首先,每一个输入向量分别和Wq, Wk, Wv矩阵相乘,得到对应的q, k, v向量,然后每一个q向量分别与其他的k向量做内积,得到各个注意力分数(Attention Score)α,在得到该分数后,对其做softmax操作(操作流程在上图上方),得到α',这时,所有的α'的和为1。
1.2 步骤2
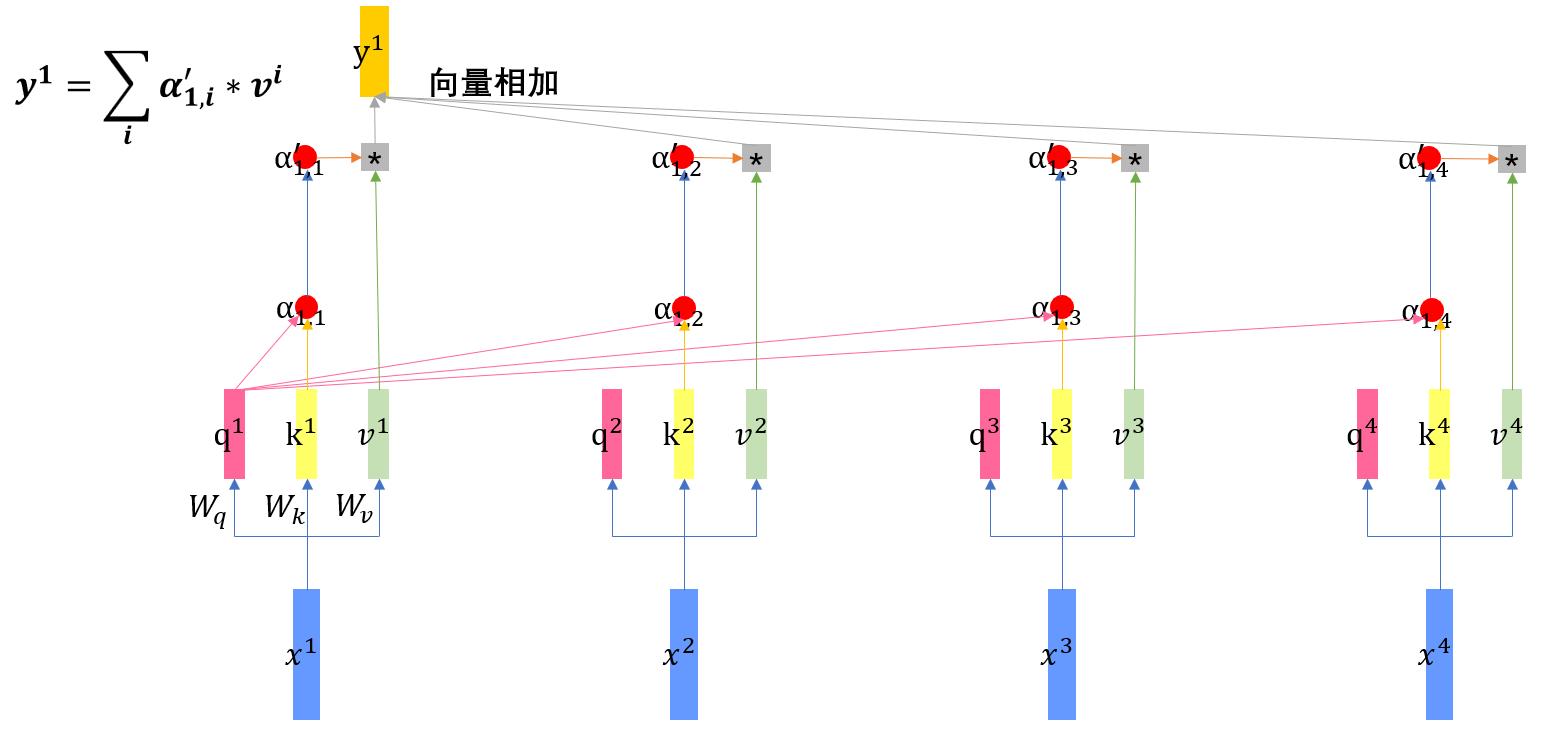
注意力机制步骤2
在得到softmax后的α'后,将每个输入向量对应的α'和其对应的v向量相乘(做缩放),然后将所有缩放后的向量相加,得到y向量。
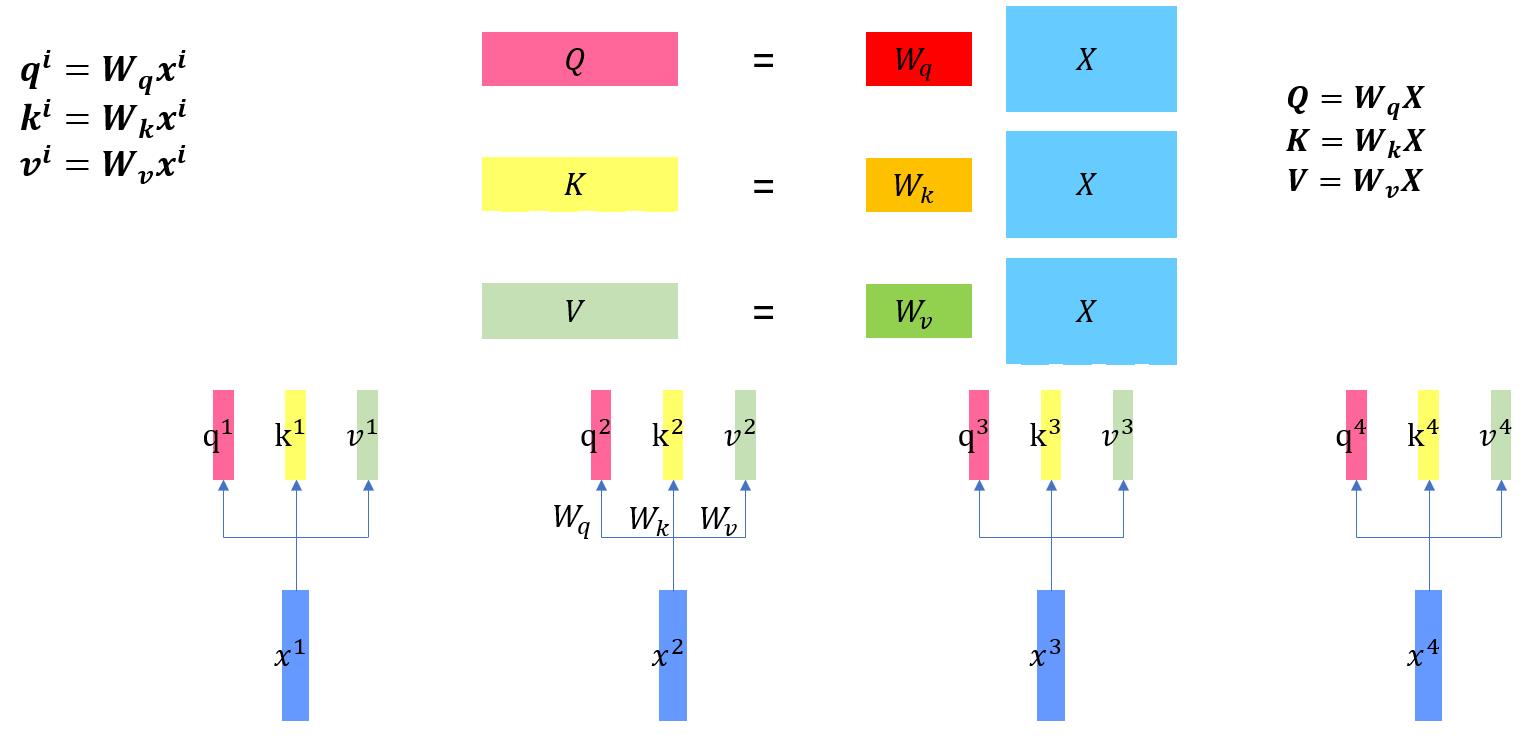
这是前三个公式的示意图
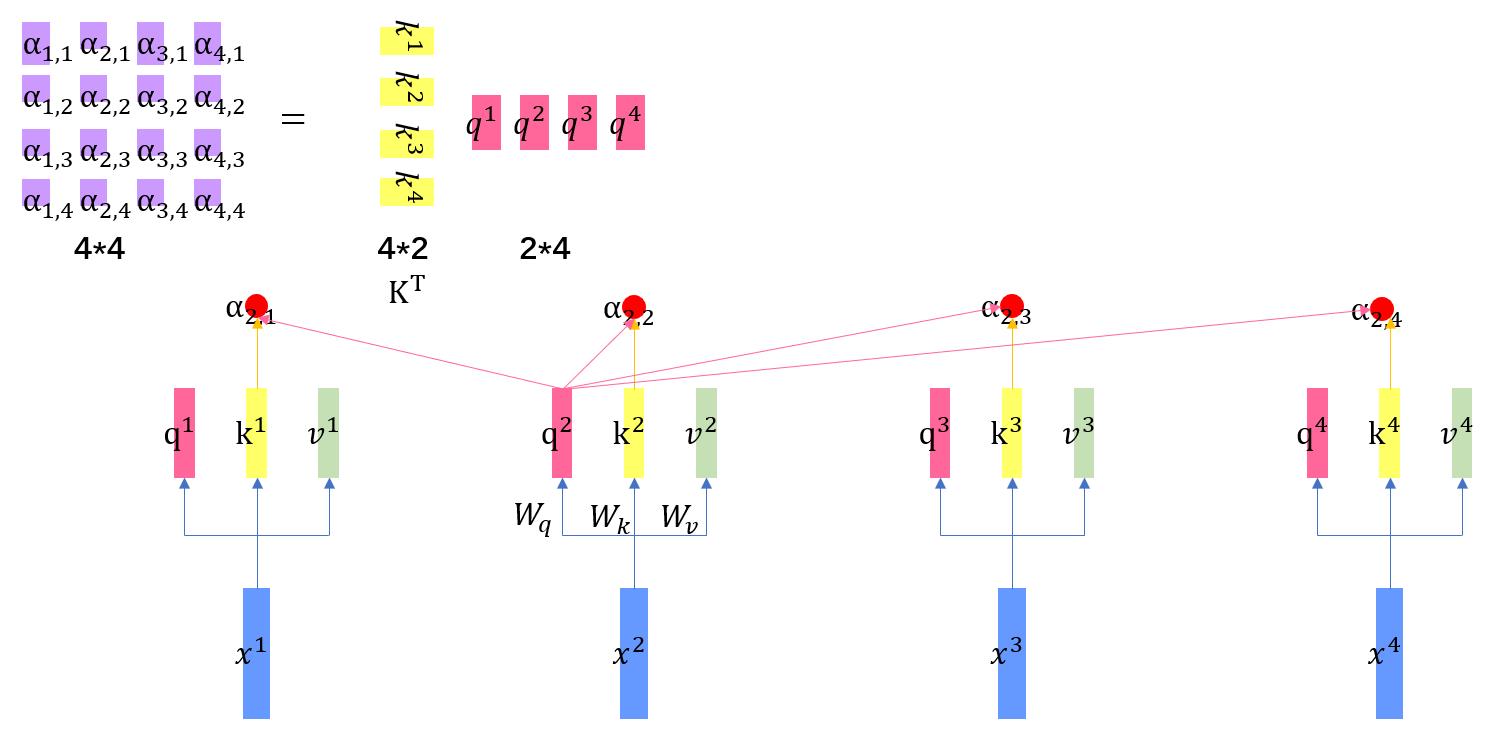
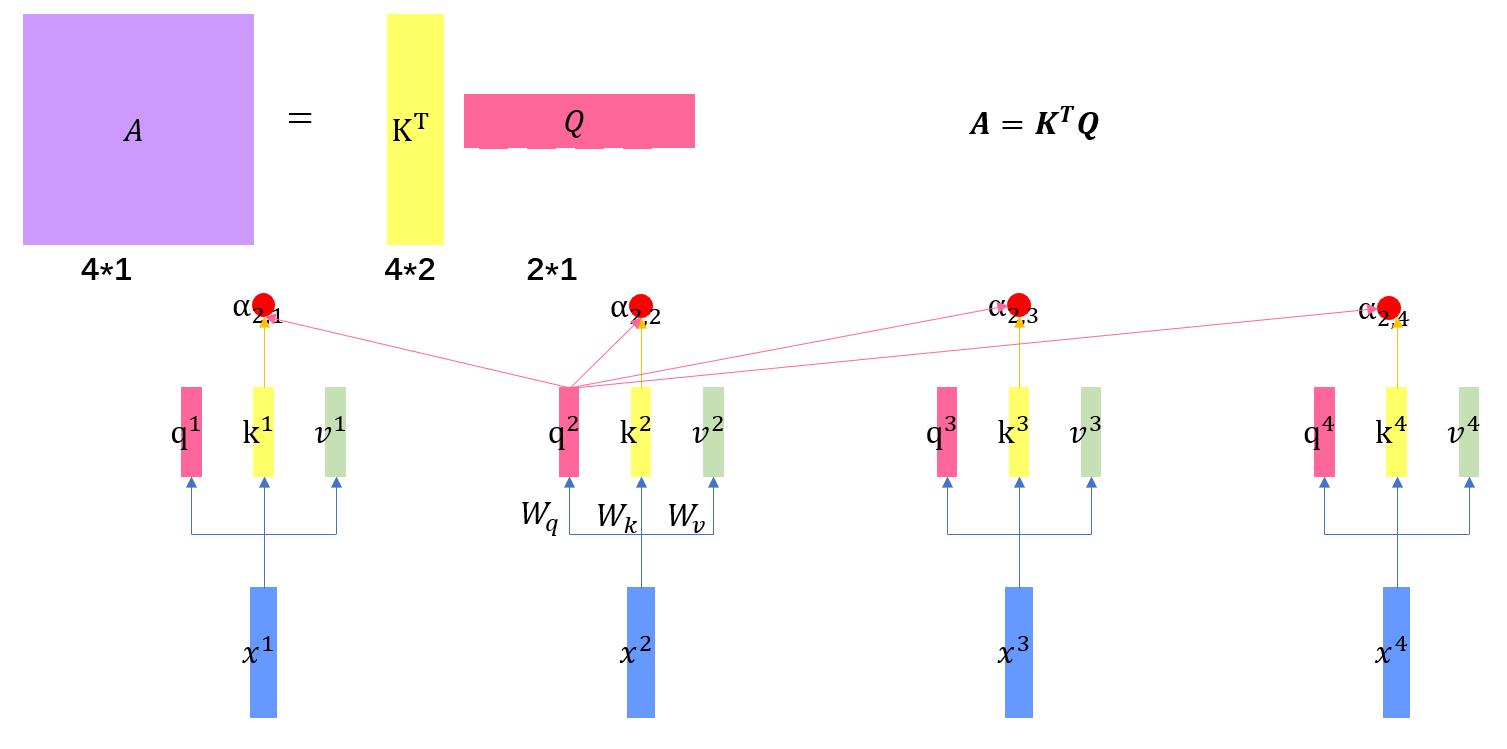
1.3 这两张图展示了第四个公式的实际过程
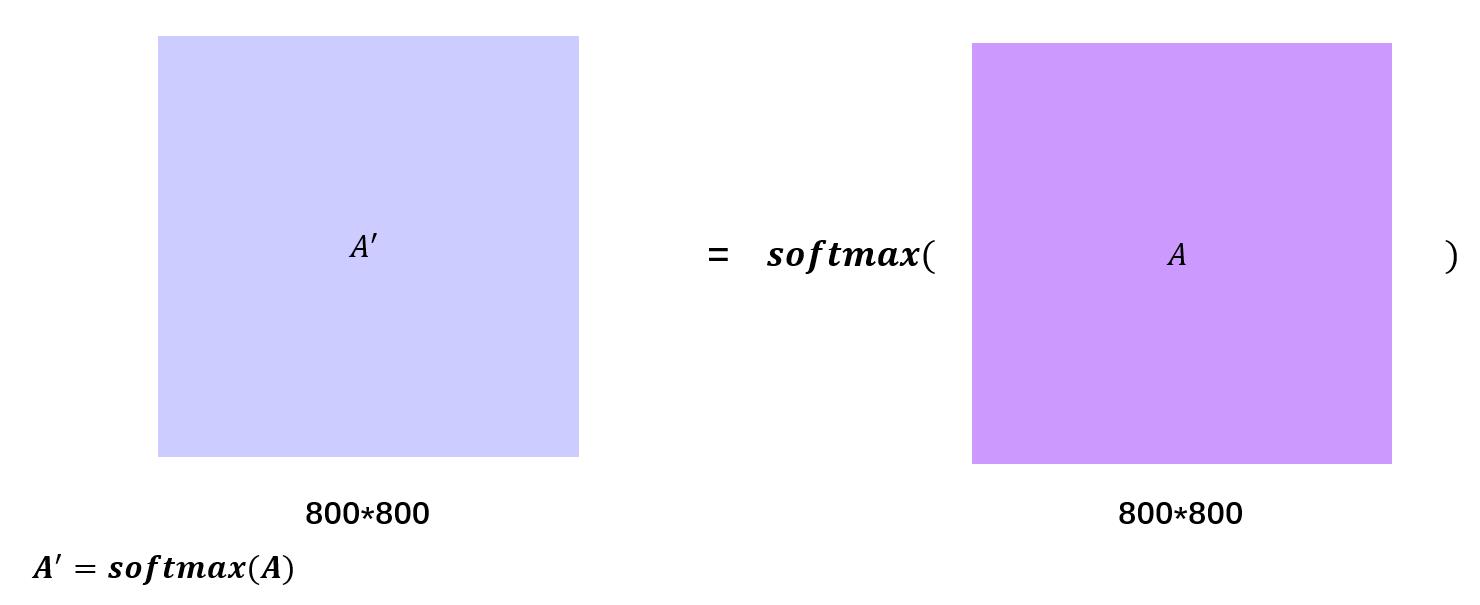
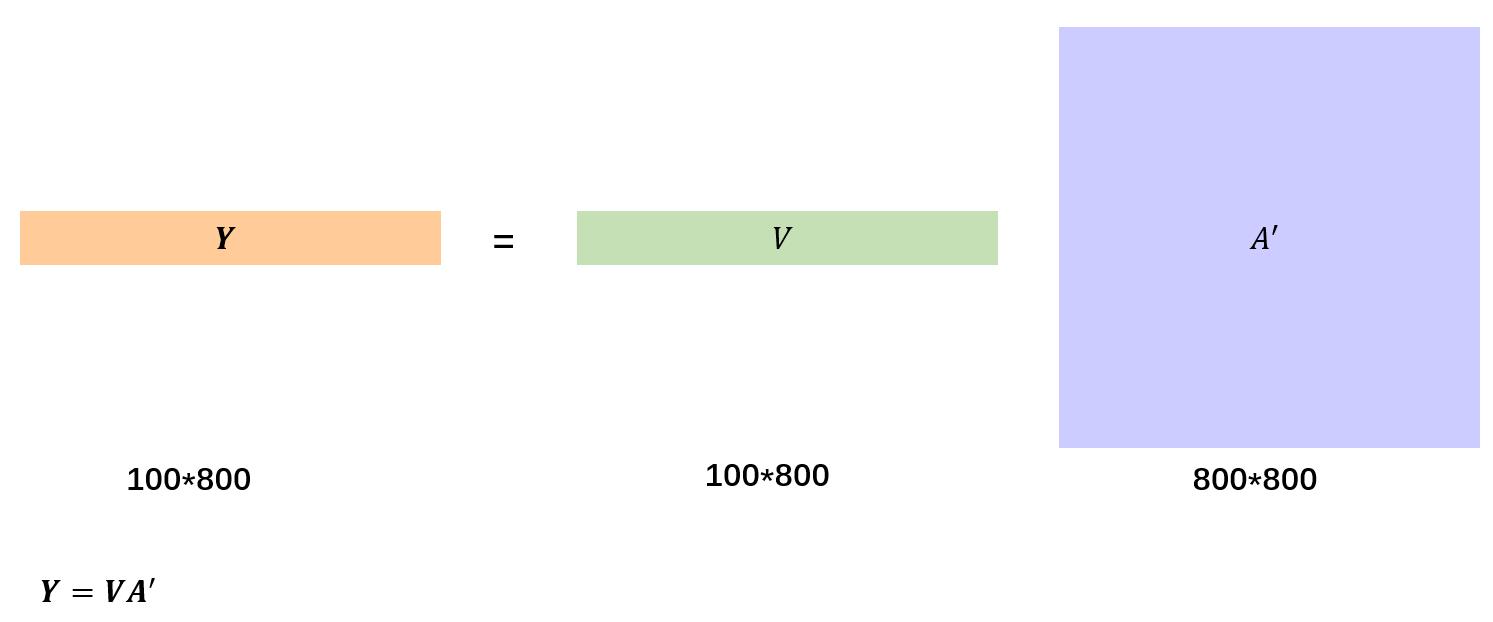
1.4 这两张图展示了最后两个公式的实际过程
整体看来,每一个输入元素都能够通过注意力分数得到与其他元素的关联信息,做到了“天涯若比邻”的效果。
1.5 位置向量的原理
在获取到注意力机制的结果后,由于我们需要处理的是序列,有先后关系,因此需要一个向量来表征一个元素的位置,这就是为什么需要位置向量。
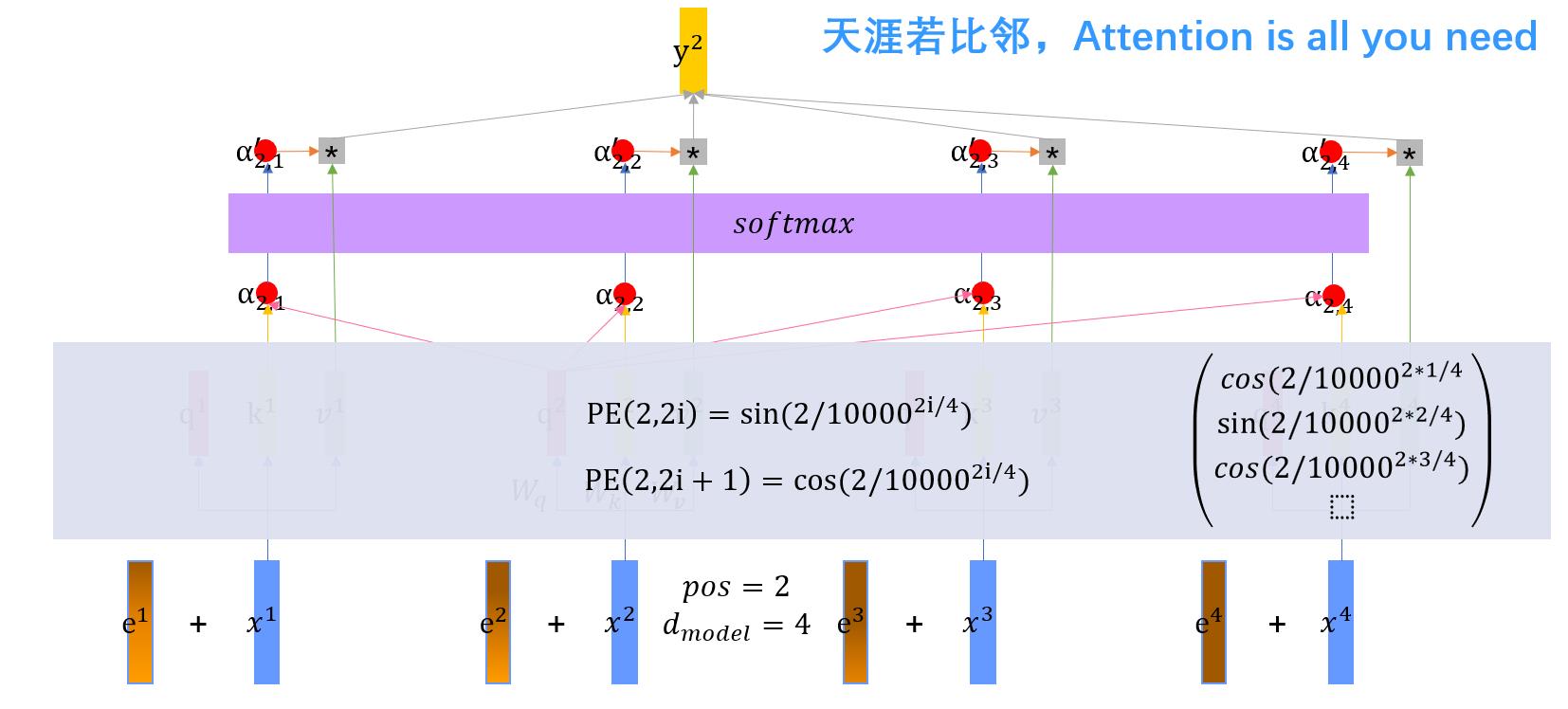
在上图中,红色的e向量就是我们所说的位置向量。在这里,我们假设要求x2的位置向量,x2的位置是2,那么pos=2,x2的维度是4,位置向量的维度与对应向量维度相等,那么位置向量的维度也为4。在此基础上,位置向量的奇数位置的元素计算公式为对应的cos公式,偶数位置的计算公式为sin公式,如图,由此,得到位置向量。
如何形象理解注意力机制

众所周知,这个是Attention的公式,但是很明显,我们除了会直接使用它,并不能理解它的实际涵义。现在,我们忽略Q, K, V矩阵,把上面的公式转换成下一个公式:

首先我们观察 ,这是一个矩阵乘以其转置,我们下面模拟这个运算过程:
,这是一个矩阵乘以其转置,我们下面模拟这个运算过程:
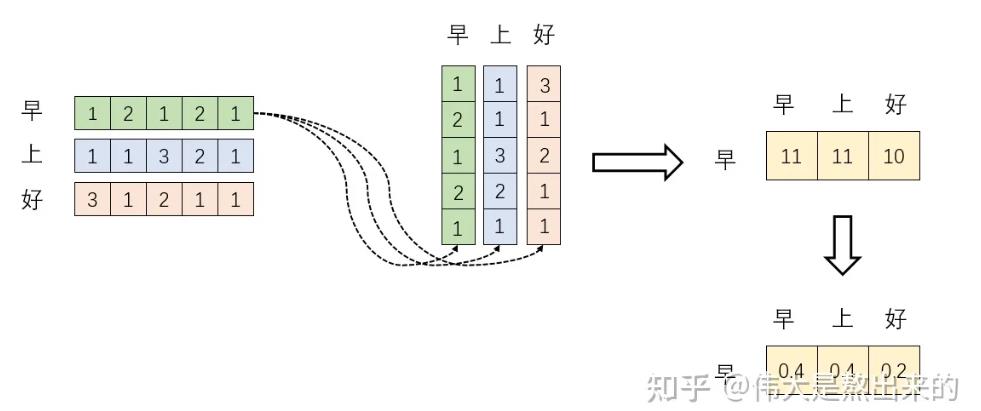
我们假设左边的是X,右边的是X的转置,经过矩阵乘法,得到结果,矩阵乘法的这里是做向量内积,我们知道,向量越重合(越相似),内积越大,若垂直(不想管),内积越小。由此可看出不同字符之间的相似性。
再经过Softmax函数,可以得到右下角的注意力得分,也就是本元素和其他元素的关系,也就是在1中我们的α。

得到注意力分数后,对于1中,就是分数和V向量相乘,在将相乘后的向量相加的过程,此处也可以按下图来理解,可以看到cross的向量是其他词语的向量经过叠加后的结果:
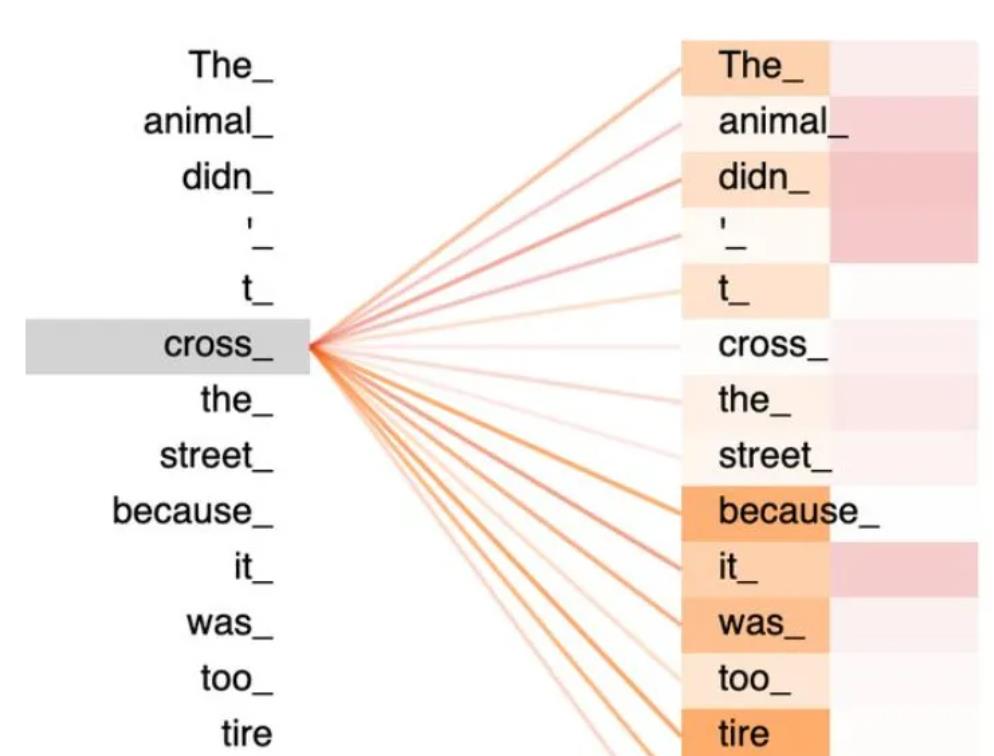
以上就是所有内容
在此特别感谢b站的课程up:【Attention、Transformer公式推导和矩阵变化】 https://www.bilibili.com/video/BV1q3411U7Hi/?share_source=copy_web&vd_source=54a003f2fe57290ef9f347426cdb53c9
以及知乎的创作者:https://zhuanlan.zhihu.com/p/410776234
以上是关于[模型学习]Attention机制及其原理推导的主要内容,如果未能解决你的问题,请参考以下文章