Pytorch AMP——自动混合精度训练
Posted 云中君不见
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch AMP——自动混合精度训练相关的知识,希望对你有一定的参考价值。
浮点数类型
Pytorch 有好几种类型的浮点数,它们占的内存大小不同,自然也有不同的精度:
torch.FloatTensor (32-bit floating point)
torch.DoubleTensor (64-bit floating point)
torch.HalfTensor (16-bit floating point 1)
torch.BFloat16Tensor (16-bit floating point 2)
| Data type | dtype |
|---|---|
| 32-bit floating point | torch.float32 or torch.float |
| 64-bit floating point | torch.float64 or torch.double |
| 16-bit floating point [1] | torch.float16 or torch.half |
| 16-bit floating point [2] | torch.bfloat16 |
[1] Referred to as binary16: uses 1 sign, 5 exponent, and 10 significand bits. Useful when precision is important.
[2] Referred to as Brain Floating Point: use 1 sign, 8 exponent and 7 significand bits. Useful when range is important, since it has the same number of exponent bits as float32
半精度浮点数 (FP16) 是一种计算机使用的二进制浮点数数据类型,使用 2 字节 (16 位) 存储,表示范围为 [ − 6.5 e 4 , − 5.9 e − 8 ] ∪ [ 5.9 e − 8 , 6.5 e 4 ] [-6.5e^4, -5.9e^-8] \\cup [5.9e^-8, 6.5e^4] [−6.5e4,−5.9e−8]∪[5.9e−8,6.5e4] 。PyTorch 默认使用单精度浮点数 (FP32) 进行网络模型的计算和权重存储。FP32 在内存中用 4 字节 (32 位) 存储,表示范围为 [ − 3 e 38 , − 1 e − 38 ] ∪ [ 1 e − 38 , 3 e 38 ] [-3e^38, -1e^-38] \\cup [1e^-38, 3e^38] [−3e38,−1e−38]∪[1e−38,3e38] 。
Pytorch 中可以使用 .half() 从单精度向半精度转换;反过来使用 .float() 进行转换。
AMP
PyTorch 1.6 版本引入了自动混合精度模块——AMP (Automatic Mixed Precision)。
如果 GPU 支持 Tensor Core (Volta、Turing、Ampere架构),AMP 将大幅减少显存消耗,加快训练速度。对于其它类型的 GPU,仍可以降低显存,但训练速度可能会变慢。
混合精度,是指 Pytorch 对于某些运算采用 torch.float16 的类型进行计算,如矩阵运算、卷积操作;对于另外一些运算采用 torch.float32。具体可参见下表:
| CUDA Ops that can autocast to float16 | CUDA Ops that can autocast to float32 |
|---|---|
| __matmul__, addbmm, addmm, addmv, addr, baddbmm, bmm, chain_matmul, multi_dot, conv1d, conv2d, conv3d, conv_transpose1d, conv_transpose2d, conv_transpose3d, GRUCell, linear, LSTMCell, matmul, mm, mv, prelu, RNNCell | __pow_, __rdiv_, __rpow_, __rtruediv_, acos, asin, binary_cross_entropy_with_logits, cosh, cosine_embedding_loss, cdist, cosine_similarity, cross_entropy, cumprod, cumsum, dist, erfinv, exp, expm1, group_norm, hinge_embedding_loss, kl_div, l1_loss, layer_norm, log, log_softmax, log10, log1p, log2, margin_ranking_loss, mse_loss, multilabel_margin_loss, multi_margin_loss, nll_loss, norm, normalize, pdist, poisson_nll_loss, pow, prod, reciprocal, rsqrt, sinh, smooth_l1_loss, soft_margin_loss, softmax, softmin, softplus, sum, renorm, tan, triplet_margin_loss |
可以看到,对于计算损失函数这种对于精度要求较高的运算,Pytorch 会选择单精度浮点数 torch.float32。
自动,是指可以通过 autocast 上下文管理器自动进行类型转换。
比如,
# Creates model and optimizer in default precision
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
for input, target in data:
optimizer.zero_grad()
# Enables autocasting for the forward pass (model + loss)
with autocast():
output = model(input)
loss = loss_fn(output, target)
# Exits the context manager before backward()
loss.backward()
optimizer.step()
前向传播以及 loss 的计算,类型转换会自动进行。
对于我们自定义的模型,autocast 也可以作为装饰器,修饰 forward 函数:
class AutocastModel(nn.Module):
...
@autocast()
def forward(self, input):
...
Gradient Scaling
关于什么是 Gradient Scaling 以及为什么要使用它,官方文档给出了详细的解释:
If the forward pass for a particular op has float16 inputs, the backward pass for that op will produce float16 gradients. Gradient values with small magnitudes may not be representable in float16. These values will flush to zero (“underflow”), so the update for the corresponding parameters will be lost.
To prevent underflow, “gradient scaling” multiplies the network’s loss(es) by a scale factor and invokes a backward pass on the scaled loss(es). Gradients flowing backward through the network are then scaled by the same factor. In other words, gradient values have a larger magnitude, so they don’t flush to zero.
Each parameter’s gradient (.grad attribute) should be unscaled before the optimizer updates the parameters, so the scale factor does not interfere with the learning rate.
简单来说,如果梯度的数值太小,半精度浮点数无法表示,会出现 underflow 问题,导致反向传播无法继续进行。解决方法是,提前把损失函数乘以一个系数,让计算得到的梯度能够被半精度浮点数表示,这样反向传播就可以进行了。
最后更新参数的时候,要 unscale 梯度——除以前面那个系数,让梯度回到原来的范围。这样不会对学习率造成影响。
Remark 1:loss 乘以一个系数(比如128),这时半精度浮点数可能 overflow ,无法表示这么大的数。这需要把 loss 转换成单精度浮点数。
Remark 2:浮点数有个特点:当两个数字相差太大时,相加是无效的,又称舍入误差。看下面的例子:

所以,我们用半精度存储梯度;但在参数更新时,需要把梯度转换成单精度,否则可能会丢失梯度。详见下面一图流。
使用方法
# Creates model and optimizer in default precision
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# Creates a GradScaler once at the beginning of training.
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
# Runs the forward pass with autocasting.
with autocast(device_type='cuda', dtype=torch.float16):
output = model(input)
loss = loss_fn(output, target)
# Scales loss. Calls backward() on scaled loss to create scaled gradients.
# Backward passes under autocast are not recommended.
# Backward ops run in the same dtype autocast chose for corresponding forward ops.
scaler.scale(loss).backward()
# scaler.step() first unscales the gradients of the optimizer's assigned params.
# If these gradients do not contain infs or NaNs, optimizer.step() is then called,
# otherwise, optimizer.step() is skipped.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
注意:scaler.step 会自动 unscale 梯度,并使用 optimizer 进行参数更新。如果想在此之前进行梯度裁剪,可以手动调用 scaler.unscale_ 函数,再使用 clip_grad_norm_。如下面代码所示:
scaler.scale(loss).backward()
# Unscales the gradients of optimizer's assigned params in-place
scaler.unscale_(optimizer)
# Since the gradients of optimizer's assigned params are unscaled, clips as usual:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
# optimizer's gradients are already unscaled, so scaler.step does not unscale them,
# although it still skips optimizer.step() if the gradients contain infs or NaNs.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
一图流
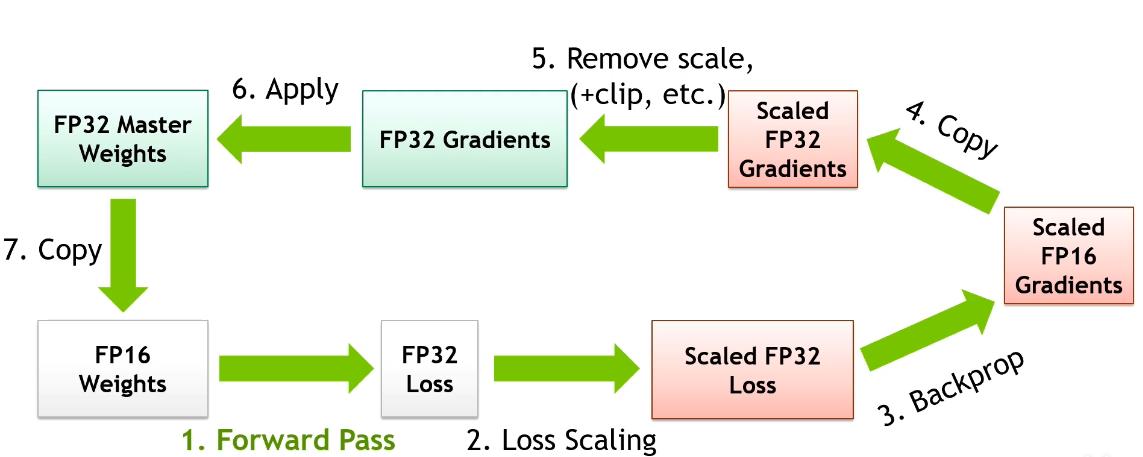
结合 Gradient Scaling 一章的 Remark 1, 2, 可以理解为什么第二步做 loss scaling 之前要转换成单精度;以及为什么要在单精度梯度上进行参数更新。
综合来看,AMP 将模型的权重、激活值、梯度等数据用 FP16 来存储,同时维护一份 FP32 的模型权重副本用于更新。在反向传播得到 FP16 的梯度以后,将其转化成 FP32 并 unscale,最后更新 FP32 的模型权重。因为整个更新过程是在 FP32 的环境中进行的,所以不会出现舍入误差。
附录
AMP 避坑:
来自知乎网友 “迪迦小饼干”:
如果混合精度训练出现了NAN,可以检查了一下之前模型中避免0产生加入的eps,eps<=1e-8的情况在半精度下直接默认为0的,所以混合精度会产生NAN。可以将eps调整到大于1e-7
视频介绍:
混合精度神经网络训练实例
优质文章:
由浅入深的混合精度训练教程
官方文档:
AUTOMATIC MIXED PRECISION PACKAGE - TORCH.AMP
CUDA AUTOMATIC MIXED PRECISION EXAMPLES
以上是关于Pytorch AMP——自动混合精度训练的主要内容,如果未能解决你的问题,请参考以下文章
Pytorch自动混合精度(AMP)介绍与使用 - autocast和Gradscaler
NLP涉及技术原理和应用简单讲解:paddle(分布式训练AMP自动混合精度训练模型量化模型性能分析)