spark sql map():_*函数
Posted 阿飞聊风控
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark sql map():_*函数相关的知识,希望对你有一定的参考价值。
需求想计算hive中每个字段的长度
或者想将hive表中每个字段的类型都转化为Double时,怎么办呢?
一种方法可能是for循环
另一种方法是spark sql的map函数可以解决
- for循环
val colNames = df.columns
var df1 = df
for (colName <- colNames)
df1 = df1.withColumn(colName, col(colName).cast(DoubleType))
df1.show()
- 通过
map():_*
上面的方法效率较低,发现scala有array:_*这样的传参语法,而df的select方法也支持这样传,因此可以有如下的写法:
case1: 将df中的字段类型都转化为double
val colNames = df.columns
val cols = colNames.map(f => col(f).cast(DoubleType))
df.select(cols: _*).show()
case2: 计算df中字段的长度
val strLen = udf((entity_id:String) => (entity_id.length))
val fe_list = Array("entity_id", "rule")
spark.sql("select * from vc.ad_rule_result where day='2020-11-10'")
.select(fe_list.map(c=>strLen(col(c))):_*).show(100)
case3: 对指定的列进行加密
def encode(col: String): String =
if (col == null || col == "" || col == "null" || col == "NULL") return ""
CryptUtils.checkAndEncryptWithAES(col.trim)
val encodeUdf: UserDefinedFunction = udf(encode _)
val encodeColumns = columns.split(",").map(_.trim)
val table = sparkSession.table(tableName)
val selectedColumns = table.columns.toSeq.map
c => if(encodeColumns.contains(c)) encodeUdf(table(c)).as(c) else table(c)
val result = table.select(selectedColumns: _*)
case4: 计算指定列的长度
样本数据:
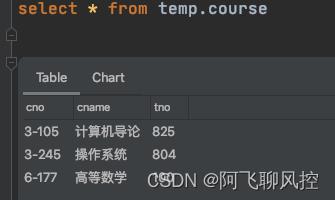
计算每个列的长度
val strLen = udf((str:String)=>(str.length))
val test_df = spark.sql(s"select * from temp.course")
val selectedColumns = test_df.columns.toSeq.map
c=> strLen(col(c)).as(c)
test_df.select(selectedColumns:_*).show()

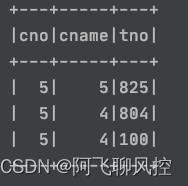
计算某一些列的长度
val selectCols = Array("cname", "cno")
val strLen = udf((str:String)=>(str.length))
val test_df = spark.sql(s"select * from temp.course")
val selectedColumns = test_df.columns.toSeq.map
c=>if(selectCols.contains(c)) strLen(col(c)).as(c) else col(c)
test_df.select(selectedColumns:_*).show()
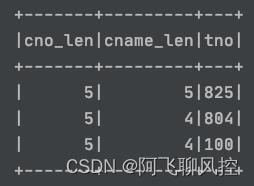
另起别名:
val selectCols = Array("cname", "cno")
val strLen = udf((str:String)=>(str.length))
val test_df = spark.sql(s"select * from temp.course")
val selectedColumns = test_df.columns.toSeq.map
c=>if(selectCols.contains(c)) strLen(col(c)).as(c+"_len") else col(c)
test_df.select(selectedColumns:_*).show()
以上是关于spark sql map():_*函数的主要内容,如果未能解决你的问题,请参考以下文章
Spark SQL 内置函数Map Functions(基于 Spark 3.2.0)
spark wordcont Spark: sortBy和sortByKey函数详解
在 Spark 中使用 map() 和 filter() 而不是 spark.sql
Spark 系列—— Spark SQL 聚合函数 Aggregations
spark程序里如果给rdd.map传递一个会返回null的函数,最后rdd里面是会少一个元素还是有为null的元素啊
大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池