Redis dict详解
Posted ljheee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis dict详解相关的知识,希望对你有一定的参考价值。
dict,又称字典(dictionary)或映射(map),是集合的一种;这种集合中每个元素都是KV键值对。
字典dict在各编程语言中都有体现,面向对象的编程语言如C++、Java中都称其为Map。
Redis的KV存储结构
Redis内存数据库,最底层是一个redisDb;

redisDb 整体使用 dict字典 来存储键值对KV;
字典中的每一项,使用dictEntry ,代表KV键值;类似于HashMap中的键值对Entry。
why dict/map?
dict是一种用于维护key和value映射关系的数据结构,与很多编程语言中的Map类似。
为什么dict/map 这么受欢迎呢?
因为dict/map实现了key和value的映射,通过key查询value是效率非常高的操作,时间复杂度是O©,C是常数,在没有冲突/碰撞的情况下,可以达到O(1)。
dict本质上是为了解决算法中的查找问题(Searching),一般查找问题的解法分为两个大类:一个是基于各种平衡树,一个是基于哈希表。
- 平衡树,如二叉搜索树、红黑树,使用的是“二分思想”;
如果需要实现排序,则可使用平衡树,如:用大顶堆实现TreeMap; - 哈希表,如Java中的Map,Python中的字典dict,使用的是“映射思想”;
我们平常使用的各种Map或dict,大都是基于哈希表实现的。在不要求数据有序存储,且能保持较低的哈希值冲突概率的前提下,基于哈希表的查找性能能做到非常高效,接近O(1),而且容易实现。
Redis dict的应用
字典dict 在 Redis 中的应用广泛, 使用频率可以说和 SDS 以及双端链表不相上下, 基本上各个功能模块都有用到字典的地方。
其中, 字典dict的主要用途有以下两个:
- 实现数据库键空间(key space);
- 用作 hash 键的底层实现之一;
以下两个小节分别介绍这两种用途。
Redis数据库键空间(key space)
Redis 是一个键值对数据库服务器,服务器中每个数据库都由 redisDB 结构表示(默认16个库)。其中,redisDB 结构的 dict 字典保存了数据库中所有的键值对,这个字典被称为键空间(key space)。
{kind=link}
可以认为,Redis默认16个库,这16个库在各自的键空间(key space)中;其实就通过键空间(key space)实现了隔离。而键空间(key space)底层是dict实现的。
键空间(key space)除了实现了16个库的隔离,还能基于键空间通知(Keyspace Notifications) 实现某些事件的订阅通知,如某个key过期的时间,某个key的value变更事件。
键空间通知(Keyspace Notifications),是因为键空间(key space)实现了16个库的隔离,而我们执行Redis命令最终都是落在其中一个库上,当有事件发生在某个库上时,该库对应的键空间(key space)就能基于pub/sub发布订阅,实现事件“广播”。
键空间(key space),详细分析,可参见:Redis键空间通知(Keyspace Notifications)
dict 用作 hash 键的底层实现
Redis 的 hash 键使用以下两种数据结构作为底层实现:
- 压缩列表ziplist ;
- 字典dict;
因为压缩列表 比字典更节省内存,所以程序在创建新 Hash 键时,默认使用压缩列表作为底层实现, 当有需要时,才会将底层实现从压缩列表转换到字典。
ziplist 是为 Redis 节约内存而开发的、非常节省内存的双向链表,深入学习可移步Redis的list
压缩链表转成字典(ziplist->dict)的条件
同时满足以下两个条件,hash 键才会使用ziplist:
1、key和value 长度都小于64
2、键值对数小于512
该配置 在redis.conf
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
如何实现字典dict/映射
dict,又称字典(dictionary)或映射(map),是集合的一种;这种集合中每个元素都是KV键值对。
它是根据关键字值(key)而直接进行访问KV键值对的数据结构。也就是说,它通过把关键字值映射到一个位置来访问记录,以加快查找的速度。这个映射函数称为哈希函数(也称为散列函数)。
因此通常我们称字典dict,也叫哈希表。
映射过程,通常使用hash算法实现,因此也称映射过程为哈希化,存放记录的数组叫做散列表、或hash表。
哈希化之后难免会产生一个问题,那就是对不同的关键字,可能得到同一个散列地址,即不同的key散列到同一个数组下标,这种现象称为冲突,那么我们该如何去处理冲突呢?
最常用的就是链地址法,也常被称为拉链法,就是在冲突的下标处,维护一个链表,所有映射到该下标的记录,都添加到该链表上。
Redis字典dict如何实现的?
Redis字典dict,也是采用哈希表,本质就是数组+链表。
也是众多编程语言实现Map的首选方式,如Java中的HashMap。
Redis字典dict 的底层实现,其实和Java中的ConcurrentHashMap思想非常相似。
就是用数组+链表实现了分布式哈希表。当不同的关键字、散列到数组相同的位置,就拉链,用链表维护冲突的记录。当冲突记录越来越多、链表越来越长,遍历列表的效率就会降低,此时需要考虑将链表的长度变短。
将链表的长度变短,一个最直接有效的方式就是扩容数组。将数组+链表结构中的数组扩容,数组变长、对应数组下标就增多了;将原数组中所有非空的索引下标、搬运到扩容后的新数组,经过重新散列,自然就把冲突的链表变短了。
如果你对Java的HashMap或ConcurrentHashMap 底层实现原理比较了解,那么对Redis字典dict的底层实现,也能很快上手。
dict.h 给出了这个字典dict的定义:
/*
* 字典
*
* 每个字典使用两个哈希表,用于实现渐进式 rehash
*/
typedef struct dict
// 特定于类型的处理函数
dictType *type;
// 类型处理函数的私有数据
void *privdata;
// 哈希表(2 个)
dictht ht[2];
// 记录 rehash 进度的标志,值为 -1 表示 rehash 未进行
int rehashidx;
// 当前正在运作的安全迭代器数量
int iterators;
dict;
typedef struct dictType
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
dictType;
结合上面的代码,可以很清楚地看出dict的结构。一个dict由如下若干项组成:
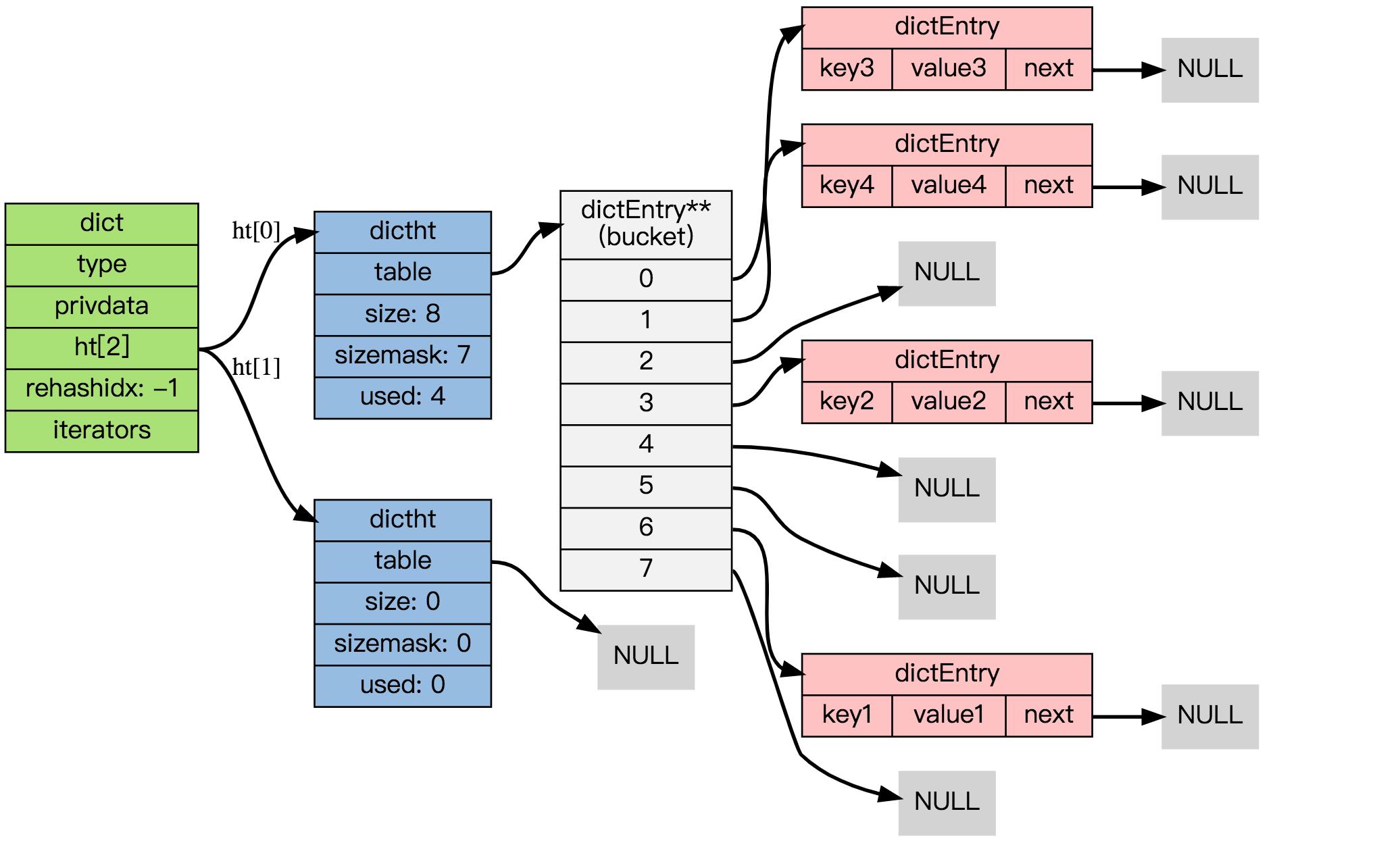
dictType *type;一个指向dictType结构的指针(type)。它通过自定义的方式使得dict的key和value能够存储任何类型的数据。void *privdata;一个私有数据指针(privdata)。由调用者在创建dict的时候传进来。dictht ht[2];两个哈希表(ht[2])。只有在rehash的过程中,ht[0]和ht[1]才都有效。而在平常情况下,只有ht[0]有效,ht[1]里面没有任何数据。上图表示的就是rehash进行到中间某一步时的情况。int rehashidx;当前rehash索引(rehashidx)。如果rehashidx = -1,表示当前没有在rehash过程中;否则,表示当前正在进行rehash,且它的值记录了当前rehash进行到哪一步了。int iterators;当前正在进行遍历的iterator的个数。这不是我们现在讨论的重点,暂时忽略。
dictType结构包含若干函数指针,用于dict的调用者对涉及key和value的各种操作进行自定义。这些操作包含:
- hashFunction,对key进行哈希值计算的哈希算法。
- keyDup和valDup,分别定义key和value的拷贝函数,用于在需要的时候对key和value进行深拷贝,而不仅仅是传递对象指针。
- keyCompare,定义两个key的比较操作,在根据key进行查找时会用到。
- keyDestructor和valDestructor,分别定义对key和value的析构函数。
私有数据指针(privdata)就是在dictType的某些操作被调用时会传回给调用者。
dictht(dict hash table)哈希表
dictht 是字典 dict 哈希表的缩写,即dict hash table。
dict.h/dictht 类型定义:
/*
* 哈希表
*/
typedef struct dictht
// 哈希表节点指针数组(俗称桶,bucket)
dictEntry **table;
// 指针数组的大小
unsigned long size;
// 指针数组的长度掩码,用于计算索引值
unsigned long sizemask;
// 哈希表现有的节点数量
unsigned long used;
dictht;
/*
* 哈希表节点
*/
typedef struct dictEntry
// 键
void *key;
// 值
union
void *val;
uint64_t u64;
int64_t s64;
v;
// 链往后继节点
struct dictEntry *next;
dictEntry;
dictht 定义一个哈希表的结构,包括以下部分:
- 一个dictEntry指针数组(table)。key的哈希值最终映射到这个数组的某个位置上(对应一个bucket)。如果多个key映射到同一个位置,就发生了冲突,那么就拉出一个dictEntry链表。
- size:标识dictEntry指针数组的长度。它总是2的指数次幂。
- sizemask:用于将哈希值映射到table的位置索引。它的值等于(size-1),比如7, 15, 31, 63,等等,也就是用二进制表示的各个bit全1的数字。每个key先经过hashFunction计算得到一个哈希值,然后计算(哈希值 & sizemask)得到在table上的位置。相当于计算取余(哈希值 % size)。
- used:记录dict中现有的数据个数。它与size的比值就是装载因子。这个比值越大,哈希值冲突概率越高。
Redis dictht的负载因子
我们知道当HashMap中由于Hash冲突(负载因子)超过某个阈值时,出于链表性能的考虑、会进行扩容,Redis dict也是一样。
一个dictht 哈希表里,核心就是一个dictEntry数组,同时用size记录了数组大小,用used记录了所有记录数。
dictht的负载因子,就是used与size的比值,也称装载因子(load factor)。这个比值越大,哈希值冲突概率越高。当比值[默认]超过5,会强制进行rehash。
dictEntry结构中包含k, v和指向链表下一项的next指针。k是void指针,这意味着它可以指向任何类型。v是个union,当它的值是uint64_t、int64_t或double类型时,就不再需要额外的存储,这有利于减少内存碎片。当然,v也可以是void指针,以便能存储任何类型的数据。
next 指向另一个 dictEntry 结构, 多个 dictEntry 可以通过 next 指针串连成链表, 从这里可以看出, dictht 使用链地址法来处理键碰撞: 当多个不同的键拥有相同的哈希值时,哈希表用一个链表将这些键连接起来。
下图展示了一个由 dictht 和数个 dictEntry 组成的哈希表例子:

如果再加上之前列出的 dict 类型,那么整个字典结构可以表示如下:
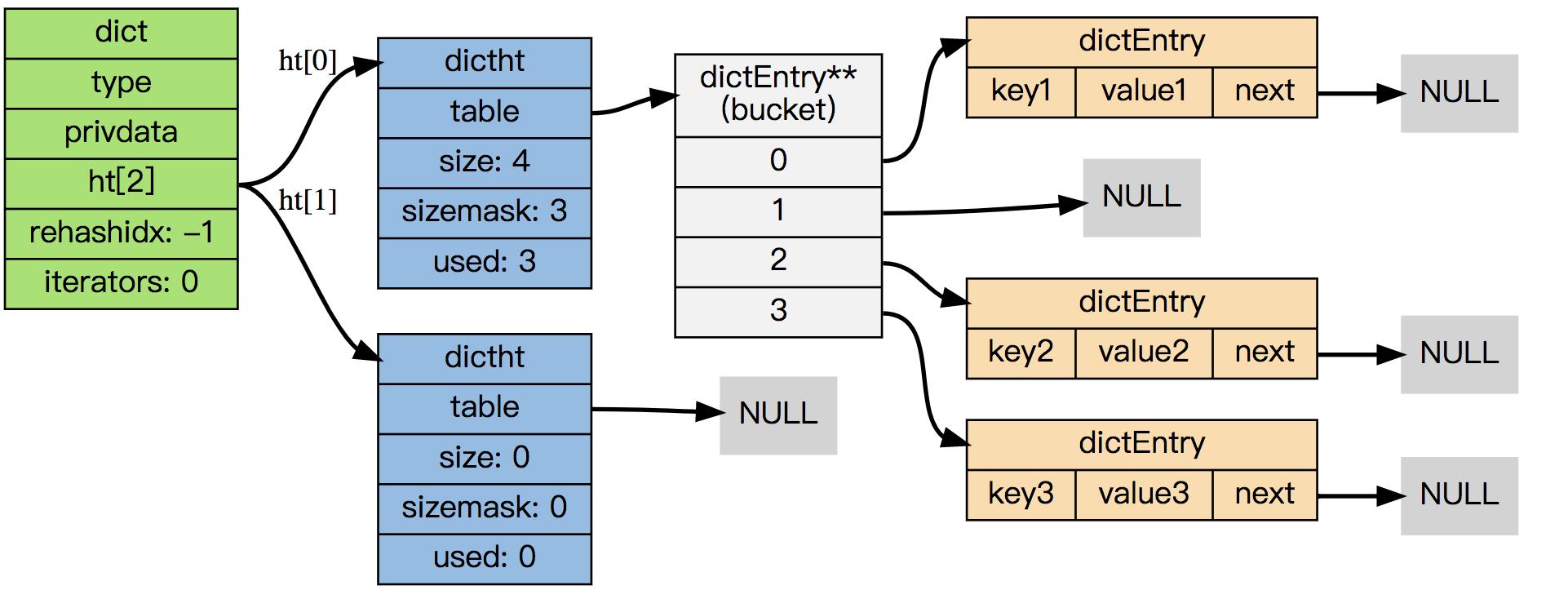
在上图给出的示例中, 只使用了 0 号哈希表ht[0],且rehashidx=-1表明字典未进行 rehash。
什么是rehash,下文会详细展开。
Redis dict使用的哈希算法
前面提到,一个kv键值对,添加到哈希表时,需要用一个映射函数将key散列到一个具体的数组下标。
Redis 目前使用两种不同的哈希算法:
1、MurmurHash2
是种32 bit 算法:这种算法的分布率和速度都非常好;Murmur哈希算法最大的特点是碰撞率低,计算速度快。Google的Guava库包含最新的Murmur3。
具体信息请参考 MurmurHash 的主页: http://code.google.com/p/smhasher/ 。
2、基于 djb 算法实现的一个大小写无关散列算法:具体信息请参考 http://www.cse.yorku.ca/~oz/hash.html 。
使用哪种算法取决于具体应用所处理的数据:
- 命令表以及 Lua 脚本缓存都用到了算法 2 。
- 算法 1 的应用则更加广泛:数据库、集群、哈希键、阻塞操作等功能都用到了这个算法。
Redis dict各种操作
以下是用于处理 dict 的各种 API , 它们的作用及相应的算法复杂度:
| 操作 | 函数 | 算法复杂度 |
|---|---|---|
| 创建一个新字典 | dictCreate | O(1) |
| 添加新键值对到字典 | dictAdd | O(1) |
| 添加或更新给定键的值 | dictReplace | O(1) |
| 在字典中查找给定键所在的节点 | dictFind | O(1) |
| 在字典中查找给定键的值 | dictFetchValue | O(1) |
| 从字典中随机返回一个节点 | dictGetRandomKey | O(1) |
| 根据给定键,删除字典中的键值对 | dictDelete | O(1) |
| 清空并释放字典 | dictRelease | O(N) |
| 清空并重置(但不释放)字典 | dictEmpty | O(N) |
| 缩小字典 | dictResize | O(N) |
| 扩大字典 | dictExpand | O(N) |
| 对字典进行给定步数的 rehash | dictRehash | O(N) |
| 在给定毫秒内,对字典进行rehash | dictRehashMilliseconds | O(N) |
下面,会对一些关键步骤进行详细讲解。
dict的创建(dictCreate)
创建dict
dict *d = dictCreate(&hash_type, NULL);
dict *dictCreate(dictType *type,
void *privDataPtr)
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
int _dictInit(dict *d, dictType *type,
void *privDataPtr)
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
d->type = type;
d->privdata = privDataPtr;
d->rehashidx = -1;
d->iterators = 0;
return DICT_OK;
static void _dictReset(dictht *ht)
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
dictCreate为dict的数据结构分配空间并为各个变量赋初值。其中两个哈希表ht[0]和ht[1]起始都没有分配空间,table指针都赋为NULL。这意味着要等第一个数据插入时才会真正分配空间。
- ht[0]->table 的空间分配将在第一次往字典添加键值对时进行;
- ht[1]->table 的空间分配将在 rehash 开始时进行;
添加新键值对到字典(dictAdd)
根据字典所处的状态, 将给定的键值对添加到字典可能会引起一系列复杂的操作:
- 如果字典为未初始化(即字典的 0 号哈希表的 table 属性为空),则程序需要对 0 号哈希表进行初始化;
- 如果在插入时发生了键碰撞,则程序需要处理碰撞;
- 如果插入新元素,使得字典满足了 rehash 条件,则需要启动相应的 rehash 程序;
当程序处理完以上三种情况之后,新的键值对才会被真正地添加到字典上。
dictAdd函数是调用 dictAddRaw实现的:
/* 将Key插入哈希表 */
dictEntry *dictAddRaw(dict *d, void *key)
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d); // 如果哈希表在rehashing,则执行单步rehash
/* 调用_dictKeyIndex() 检查键是否存在,如果存在则返回NULL */
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry)); // 为新增的节点分配内存
entry->next = ht->table[index]; // 将节点插入链表表头
ht->table[index] = entry; // 更新节点和桶信息
ht->used++; // 更新ht
/* 设置新节点的键 */
dictSetKey(d, entry, key);
return entry;
整个添加流程可以用下图表示:
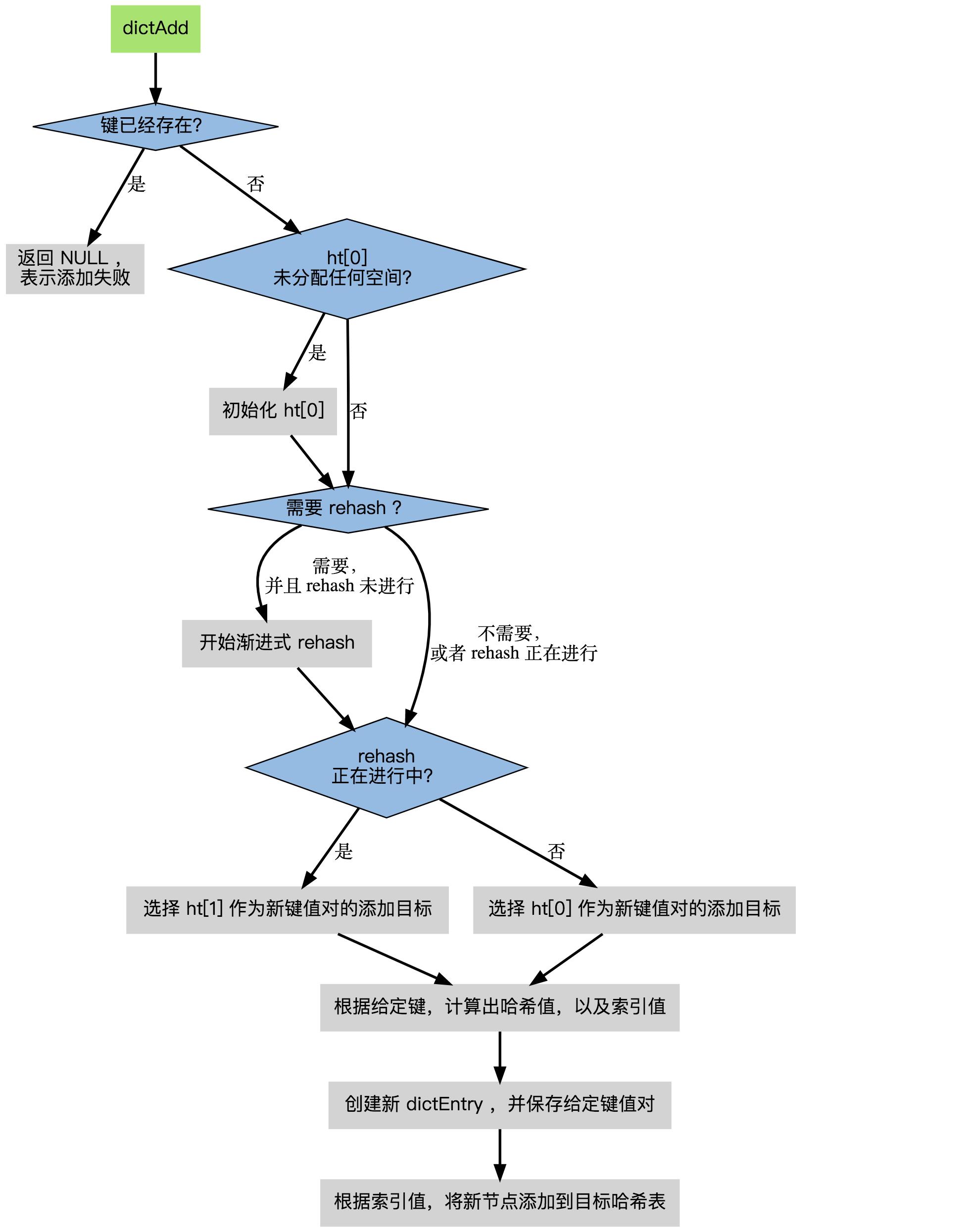
在接下来的三节中, 我们将分别看到,添加操作如何在以下三种情况中执行:
1、字典为空;
2、添加新键值对时发生碰撞处理;
3、添加新键值对时触发了 rehash 操作;
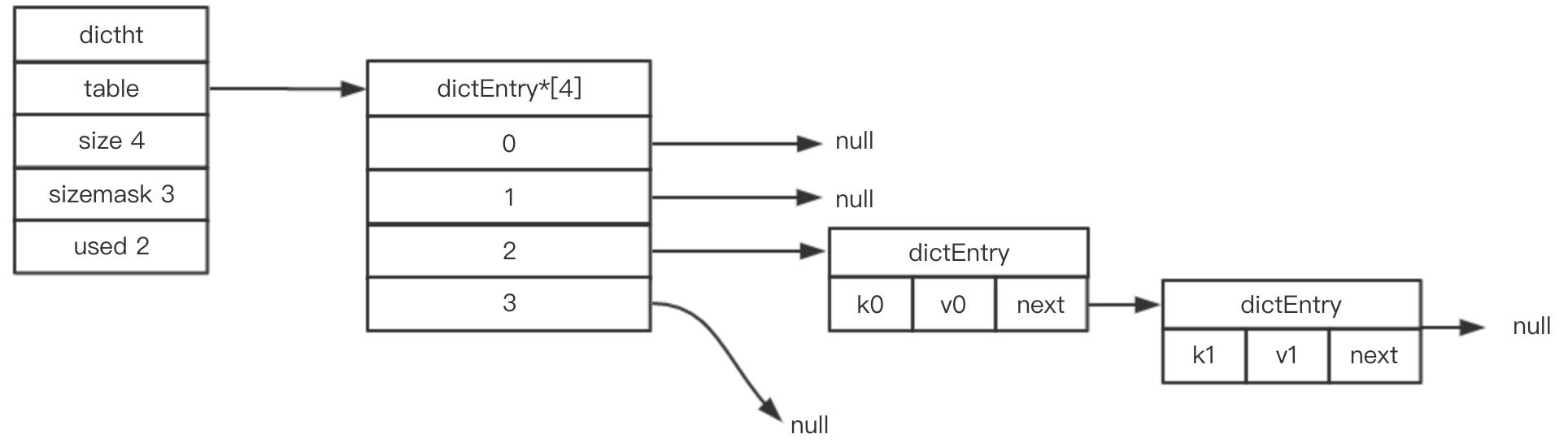
添加新元素时table为空
当第一次往空字典里添加键值对时, 程序会根据 dict.h/DICT_HT_INITIAL_SIZE 里指定的大小为 d->ht[0]->table 分配空间 (在目前的版本中, DICT_HT_INITIAL_SIZE 的值为 4 )。
以下是字典空白时的样子:

以下是往空白字典添加了第一个键值对之后的样子:
添加新键值对时发生碰撞
在哈希表实现中, 当两个不同的键拥有相同的哈希值时, 称这两个键发生碰撞(collision), 而哈希表实现必须想办法对碰撞进行处理。
字典哈希表所使用的碰撞解决方法被称之为链地址法: 这种方法使用链表将多个哈希值相同的节点串连在一起, 从而解决冲突问题。
假设现在有一个带有三个节点的哈希表,如下图:
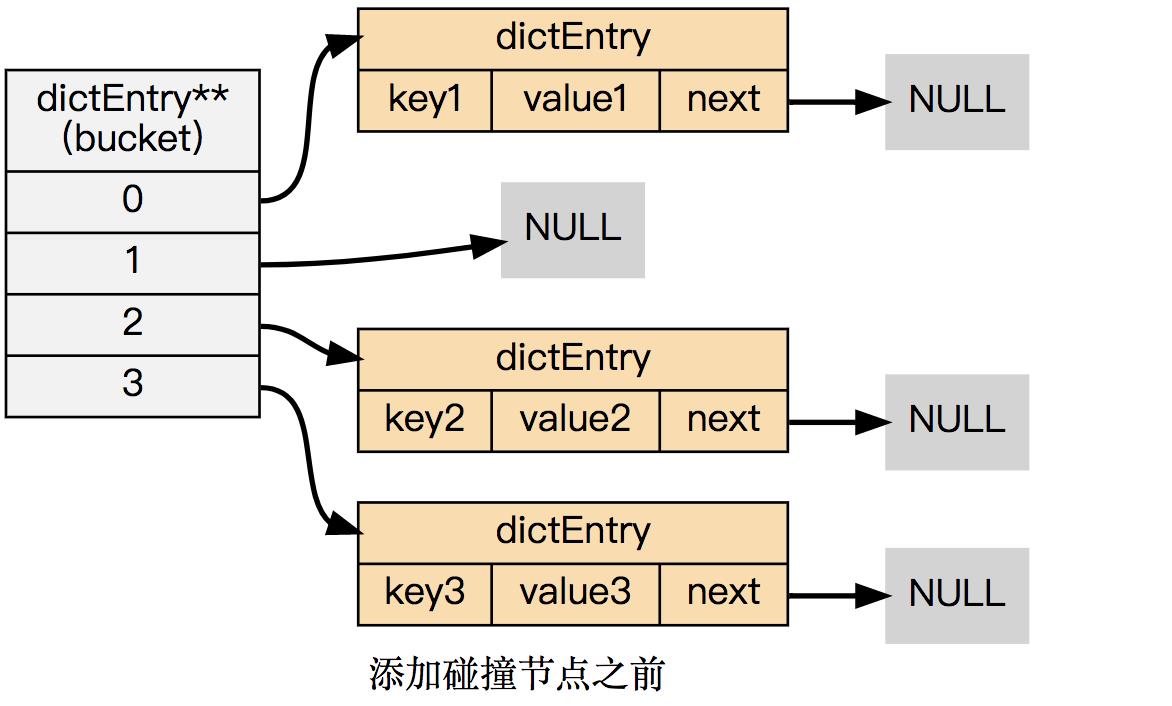
对于一个新的键值对 key4 和 value4 , 如果 key4 的哈希值和 key1 的哈希值相同, 那么它们将在哈希表的 0 号索引上发生碰撞。
通过将 key4-value4 和 key1-value1 两个键值对用链表连接起来, 就可以解决碰撞的问题:

添加新键值对时触发了 rehash
对于使用链地址法来解决碰撞问题的哈希表 dictht 来说, 哈希表的性能取决于大小(size属性)与保存节点数量(used属性)之间的比率:
哈希表的大小与节点数量,比率在 1:1 时,哈希表的性能最好;
如果节点数量比哈希表的大小要大很多的话,那么哈希表就会退化成多个链表,哈希表本身的性能优势便不复存在;
举个例子, 下面这个哈希表, 平均每次失败查找只需要访问 1 个节点(非空节点访问 2 次,空节点访问 1 次):
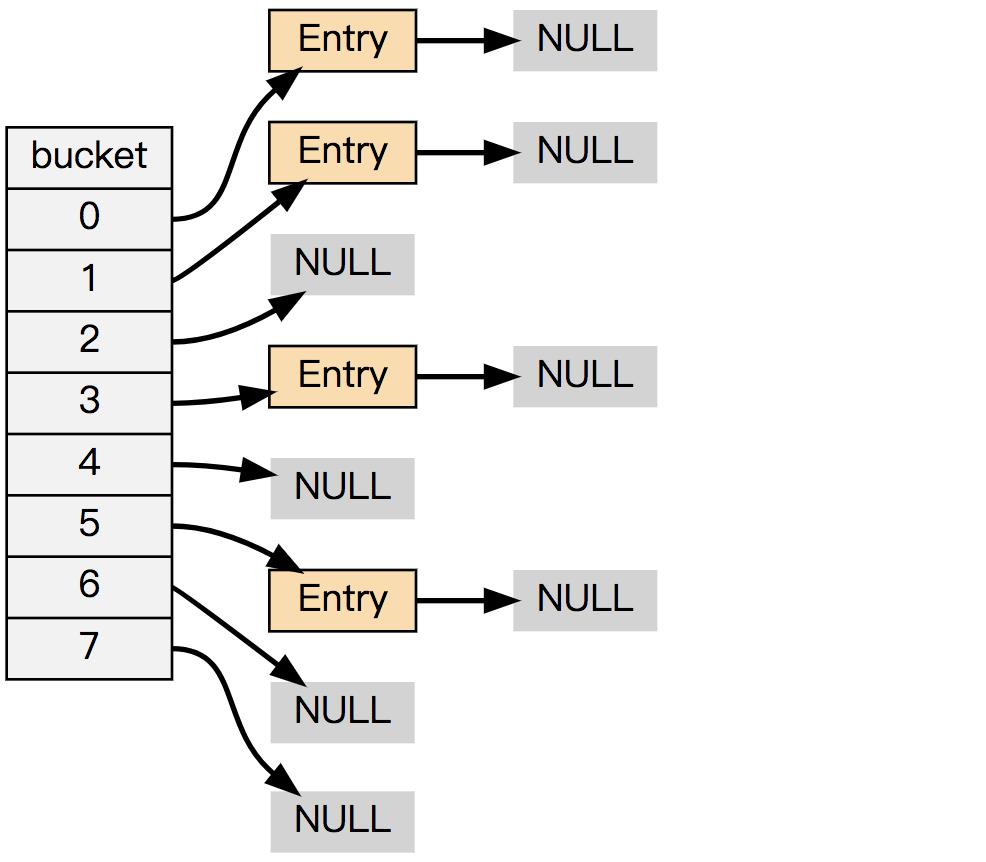
而下面这个哈希表, 平均每次失败查找需要访问 5 个节点:
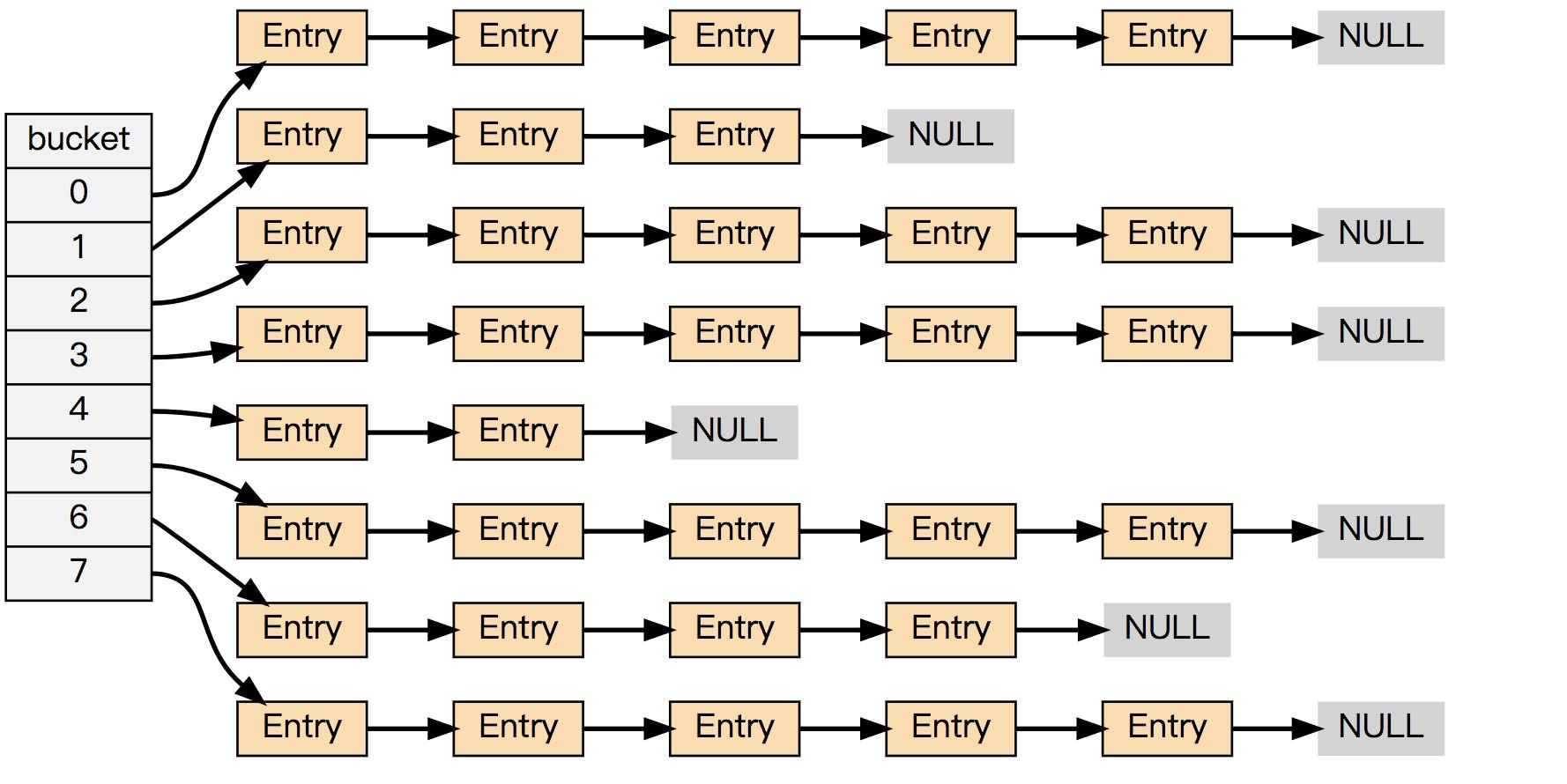
为了在字典的键值对不断增多的情况下保持良好的性能, 字典需要对所使用的哈希表(ht[0])进行 rehash 操作: 在不修改任何键值对的情况下,对哈希表进行扩容, 尽量将比率维持在 1:1 左右。
dictAdd 在每次向字典添加新键值对之前, 都会对哈希表 ht[0] 进行检查, 对于 ht[0] 的 size 和 used 属性, 如果它们之间的比率 ratio = used / size 满足以下任何一个条件的话,rehash 过程就会被触发:
- 自然 rehash : ratio >= 1 ,且变量 dict_can_resize 为true。
- 强制 rehash : ratio 大于变量 dict_force_resize_ratio (目前版本中, dict_force_resize_ratio 的值为 5 )。
什么时候 dict_can_resize 会为false?
在前面介绍字典的应用时也说到过, 数据库就是字典, 数据库里的哈希类型键也是字典, 当 Redis 使用子进程对数据库执行后台持久化任务时(比如执行 BGSAVE 或 BGREWRITEAOF 时), 为了最大化地利用系统的 copy on write 机制, 程序会暂时将 dict_can_resize 设为false, 避免执行自然 rehash , 从而减少程序对内存的触碰(touch)。当持久化任务完成之后, dict_can_resize 会重新被设为true。
另一方面, 当字典满足了强制 rehash 的条件时, 即使 dict_can_resize 不为true(有 BGSAVE 或 BGREWRITEAOF 正在执行), 这个字典一样会被 rehash 。
Rehash 执行过程
字典的 rehash 操作实际上就是执行以下任务:
1、创建一个比 ht[0]->table 更大的 ht[1]->table ;
2、将 ht[0]->table 中的所有键值对迁移到 ht[1]->table ;
3、将原有 ht[0] 的数据清空,并将 ht[1] 替换为新的 ht[0] ;
经过以上步骤之后, 程序就在不改变原有键值对数据的基础上, 增大了哈希表的大小。
dict的rehash 本质就是扩容,就是将数组+链表结构中的数组扩容;
这个过程,需要开辟一个更大空间的数组,将老数组中每个非空索引的bucket,搬运到新数组;搬运完成后再释放老数组的空间。
作为例子, 以下四个小节展示了一次对哈希表进行 rehash 的完整过程。
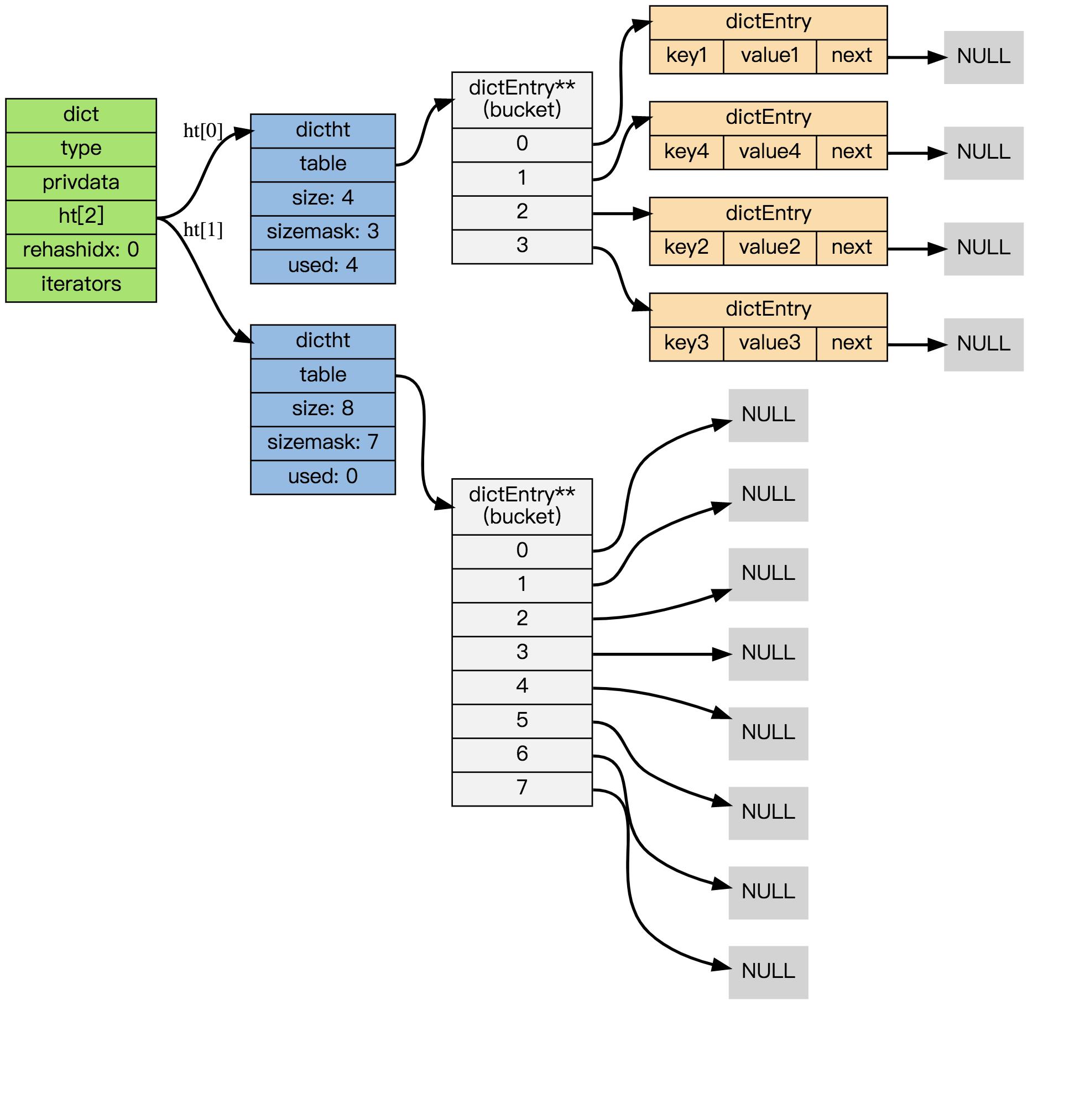
1. 开始 rehash
这个阶段有两个事情要做:
- 设置字典的 rehashidx 为 0 ,标识着 rehash 的开始;
- 为 ht[1]->table 分配空间,大小至少为 ht[0]->used 的两倍;
这时的字典是这个样子:
2. Rehash 进行中
在这个阶段, ht[0]->table 的节点会被逐渐迁移到 ht[1]->table , 因为 rehash 是分多次进行的(细节在下一节解释), 字典的 rehashidx 变量会记录 rehash 进行到 ht[0] 的哪个索引位置上。
注意除了节点的移动外, 字典的 rehashidx 、 ht[0]->used 和 ht[1]->used 三个属性也产生了变化。
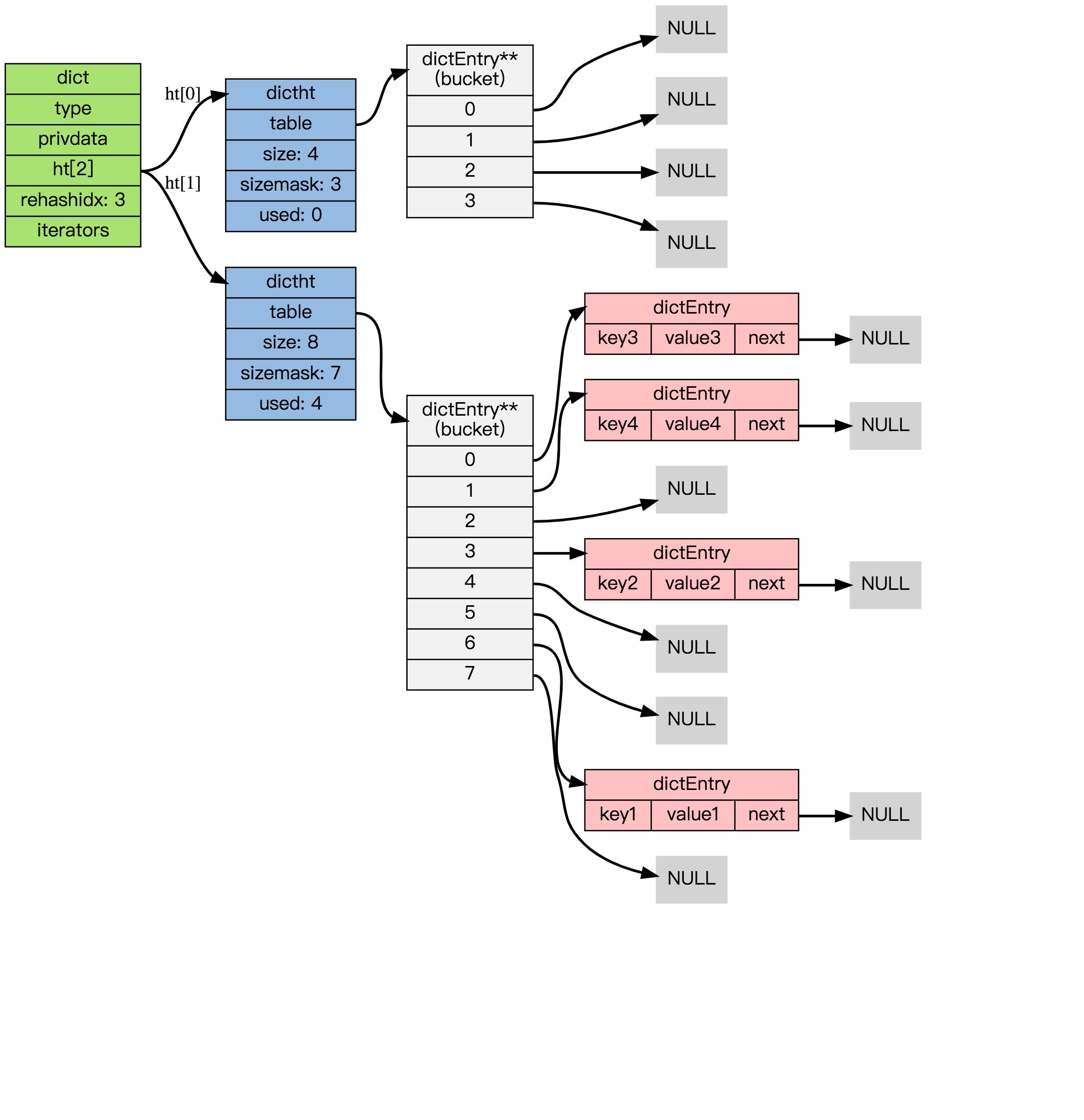
3. 节点迁移完毕
到了这个阶段,所有的节点都已经从 ht[0] 迁移到 ht[1] 了:
4. Rehash 完毕
在 rehash 的最后阶段,程序会执行以下工作:
- 释放 ht[0] 的空间;
- 用 ht[1] 来代替 ht[0] ,使原来的 ht[1] 成为新的 ht[0] ;
- 创建一个新的空哈希表,并将它设置为 ht[1] ;
- 将字典的 rehashidx 属性设置为 -1 ,标识 rehash 已停止;
以下是字典 rehash 完毕之后的样子:
incremental rehashing 增量/渐进式rehash
在上一节,我们了解了字典的 rehash 过程, 需要特别指出的是, rehash 并不是在触发之后,马上就执行直到完成; 而是分多次、渐进式地完成的。
rehash会产生的问题
1、rehash的过程,会使用两个哈希表,创建了一个更大空间的ht[1],此时会造成内存陡增;
2、rehash的过程,可能涉及大量KV键值对dictEntry的搬运,耗时较长;
如果这个 rehash 过程必须将所有键值对迁移完毕之后才将结果返回给用户, 这样的处理方式将不满足Redis高效响应的特性。
rehash会产生的问题,主要层面就是内存占用陡增、和处理耗时长的问题,基于这两点,还会带来其他影响。
为了解决这些问题, Redis 使用了incremental rehashing,是一种 增量/渐进式的 rehash 方式: 通过将 rehash 分散到多个步骤中进行, 从而避免了集中式的计算/节点迁移。
dictAdd 添加键值对到dict,检查到需要进行rehash时,会将dict.rehashidx 设置为 0 ,标识着 rehash 的开始;
后续请求,在执行add、delete、find操作时,都会判断dict是否正在rehash,如果是,就执行_dictRehashStep()函数,进行增量rehash。
每次执行 _dictRehashStep , 会将ht[0]->table 哈希表第一个不为空的索引上的所有节点就会全部迁移到 ht[1]->table 。
也就是在某次dictAdd 添加键值对时,触发了rehash;后续add、delete、find命令在执行前都会检查,如果dict正在rehash,就先不急去执行自己的命令,先去帮忙搬运一个bucket;
搬运完一个bucket,再执行add、delete、find命令 原有处理逻辑。

ps:实际上incremental rehashing增量/渐进式rehash,只解决了第二个:耗时长的问题,将集中式的节点迁移分摊到多步进行,ht[1]占用的双倍多内存,还一直占用。
下面我们通过dict的查找(dictFind)来看渐进式rehash过程;
dict的查找(dictFind)
dictEntry *dictFind(dict *d, const void *key)
dictEntry *he;
unsigned int h, idx, table;
if (d->ht[0].used + d->ht[1].used == 0) return NULL; /* dict is empty */
if (dictIsRehashing(d)) _dictRehashStep(d);// 如果哈希表在rehashing,则执行单步rehash
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++)
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he)
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
if (!dictIsRehashing(d)) return NULL;
return NULL;
上述dictFind的源码,根据dict当前是否正在rehash,依次做了这么几件事:
- 如果当前正在进行rehash,那么将rehash过程向前推进一步(即调用_dictRehashStep)。实际上,除了查找,插入和删除也都会触发这一动作。这就将rehash过程分散到各个查找、插入和删除操作中去了,而不是集中在某一个操作中一次性做完。
- 计算key的哈希值(调用dictHashKey,里面的实现会调用前面提到的hashFunction)。
- 先在第一个哈希表ht[0]上进行查找。在table数组上定位到哈希值对应的位置(如前所述,通过哈希值与sizemask进行按位与),然后在对应的dictEntry链表上进行查找。查找的时候需要对key进行比较,这时候调用dictCompareKeys,它里面的实现会调用到前面提到的keyCompare。如果找到就返回该项。否则,进行下一步。
- 判断当前是否在rehash,如果没有,那么在ht[0]上的查找结果就是最终结果(没找到,返回NULL)。否则,在ht[1]上进行查找(过程与上一步相同)。
下面我们有必要看一下增量式rehash的_dictRehashStep的实现。
static void _dictRehashStep(dict *d)
if (d->iterators == 0) dictRehash(d,1);
/*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time.
*/
int dictRehash(dict *d, int n)
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0)
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL)
d->rehashidx++;
if (--empty_visits == 0) return 1;
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de)
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0)
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
/* More to rehash... */
return 1;
根据dictRehash函数的注释,rehash的单位是bucket,也就是从老哈希表dictht中找到第一个非空的下标,要把该下标整个链表搬运到新数组。
如果遍历老数组,访问的 前N*10 个都是空bucket,则不再继续往下寻找。
dictAdd、dictDelete、dictFind在rehash过程中的特殊性
在哈希表进行 rehash 时, 字典还会采取一些特别的措施, 确保 rehash 顺利、正确地进行:
- 因为在 rehash 时,字典会同时使用两个哈希表,所以在这期间的所有查找dictFind、删除dictDelete等操作,除了在 ht[0] 上进行,还需要在 ht[1] 上进行。
- 在执行添加操作dictAdd时,新的节点会直接添加到 ht[1] 而不是 ht[0] ,这样保证 ht[0] 的节点数量在整个 rehash 过程中都只减不增。
dict的缩容
上面关于 rehash 的章节描述了通过 rehash 对字典进行扩展(expand)的情况, 如果哈希表的可用节点数比已用节点数大很多的话, 那么也可以通过对哈希表进行 rehash 来收缩(shrink)字典。
收缩 rehash 和上面展示的扩展 rehash 的操作几乎一样,执行以下步骤:
- 创建一个比 ht[0]->table 小的 ht[1]->table ;
- 将 ht[0]->table 中的所有键值对迁移到 ht[1]->table ;
- 将原有 ht[0] 的数据清空,并将 ht[1] 替换为新的 ht[0] ;
小结
Redis的dict最显著的一个特点,就在于它的rehash。它采用了一种称为增量式(incremental rehashing)的rehash方法,在需要扩容时避免一次性对所有key进行rehash,而是将rehash操作分散到对于dict的各个增删改查的操作中去。
这种方法能做到每次只对一小部分key进行rehash,而每次rehash之间不影响dict的操作。dict之所以这样设计,是为了避免rehash期间单个请求的响应时间剧烈增加,这与前面提到的“快速响应时间”的设计原则是相符的。
- Redis的dict也是使用数组+链表实现;
- 当冲突增加、链表增长,也是采用rehash(数组扩容)来将链表变短;
- dict数组扩容,也是按2的指数次幂,使用位运算,替代求余操作,计算更快;
- 渐进式rehash,其实是辅助式的;不是让触发rehash的一个人搬运完所有dictEntry,而是让后来者一起参与搬运。
福利: 关注公众号,回复“Redis源码”,即可获得 Redis 3.0源码注释版~
本文首发于公众号 架构道与术(ToBeArchitecturer),欢迎关注、学习更多干货~

以上是关于Redis dict详解的主要内容,如果未能解决你的问题,请参考以下文章