物联网遇到流计算
Posted DataFlow范式
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了物联网遇到流计算相关的知识,希望对你有一定的参考价值。

今天,笔者和大家聊一聊物联网(IoT),不少人都说物联网开启了万物互联时代,尤其是 5G 的逐渐普及和应用,将会构建万物互联的智能世界,实现物理世界的数字化,影响到每一个人。
三言两语聊 IoT
物联网市场太大,所以不少企业针对物联网提供了一站式智能解决方案,可谓是包装一层又一层,深不见底。留两张图,自己感受一下物联网的浪潮冲击。


很早以前,就有一个公式:AIoT(人工智能物联网)= AI(人工智能)+IoT(物联网),大部分读者应该在电影中都看到过 AIoT 描述的世界,省略十万字。
如果说 IoT 和 AI 是主导科技行业的两大趋势,想必大部分读者应该是认同的。尤其对于工业自动化来说,IoT 和 AI 的融合将重新定义工业自动化的未来,引领工业 4.0 革命,说起来感觉有点夸大的感觉,但是很显然这两项技术目前正在各个行业中被结合起来应用,并非是笔者在 2011 年所看到的一堆炒作和充满泡沫的东西。
没有套路
在本篇文章中,笔者不会长篇累牍讲解 IoT 相关内容,而是会结合物联网和大数据相关技术,实现一个常见的物联网方面的解决方案,即 IoT 设备实时数据采集、监控以及指标数据的实时流计算。
为了完成这个解决方案,涉及的技术包括:
Apache NiFi
Apache NiFi 开源好几年了(NiFi 是 NAS 在 2014 年贡献给 Apache 社区,2015 年成为 Apache 顶级项目),笔者也是断断续续拜访拜访,逢年过节写写项目,但是都没有在生产环境大规模应用。如果用一句话描述 Apache Nifi 的话,即一个易于使用、功能强大、可靠的系统来处理和分发数据(来自官网)。如果再深入描述的话,请阅读官网http://nifi.apache.org。
不少读者,喜欢拿 Apache NiFi 和 StreamSets 做比较,其实都是 Dataflow 数据处理的工具。虽然 StreamSets 图形化很美,但是企业级的 StreamSets Control Hub 不是开源的,论开源方面的企业级功能完整度,个人更喜欢 Apache NiFi。Apache NiFi Registry
Apache NiFi Registry 属于 Apache NiFi 的子项目,用于一个或多个 NiFi 以及 MiNiFi 实例之间的共享资源的存储和管理。我们在部署 CEM 时,需要配置 Registry 服务的相关信息。MiNiFi
MiNiFi 是 Apache NiFi 的一个子项目,一种轻量级的边缘代理工具,包含了 Apache NiFi 的核心功能,专注于边缘设备的数据收集和处理,毕竟 Apache NiFi 真的不小。在本项目中,笔者使用 MiNiFi 作为 IoT 设备的数据采集 Agent。Apache Kafka
如果你们公司有大数据平台,但是没有使用开源的 Kafka,好吧,你们公司真有钱。Apache Kudu
在 Hadoop 生态系统中,属于新成员了。Apache Kudu 定位为 fast analytics on fast data,即支持对快速数据的快速分析,同样提供插入和更新功能。Apache Kudu 可以很方便地实时追加数据,并能够对数据进行分析,所以适合 IoT 实时数据存储和分析。Apache Flink
关于 Flink,笔者在之前的文章中写了很多,建议感兴趣的读者选择性阅读,这里就不贴出链接了,读者在找的过程中可能会发现其他有参考价值的文章。CEM
去年,Cloudera 发布的两款产品 Cloudera Flow Management 和 Cloudera Edge Management。CEM 即为 Cloudera Edge Management,用于边缘设备的监控和管理,以及发布 MiNiFi 数据采集流程到 NiFi 中,实现统一的管理。
CEM 中的 EFM 提供了一个可视化的界面,支持基于图形界面的流编程模型,可以在数千个 MiNiFi Agent 上开发、部署和监控边缘数据流。
对于这些组件的部署,笔者就不在本篇文章中详细讲解了,对于大部分企业级大数据平台而言,缺少的可能就是 CEM、NiFi 和 MiNiFi,尤其是 CEM,目前 CEM 属于商业产品,不过企业有条件可以基于 MiNiFi 进行开发或者使用其他已有的 Edge Agent 或 Gateway。
IoT 事件流旅途
在设计和开发之前,笔者先将 IoT 设备采集的事件流的旅途概括一下:
1. IoT 设备数据采集的事件流写入本地文件
2. MiNiFi Agent(Java 或 C++ 版本)采集事件消息
3. 使用 CEM 发布 MiNiFi 采集数据流程到 NiFi 中,并在 NiFi 中将 MiNiFi 采集的数据写入 Kafka
4. 使用 NiFi Connector,开发 Flink 流处理作业,用于消费 Kafka 中 IoT 事件消息并计算指标,将结果写入 Kudu。
简单描述,即开发 NiFi 可视化数据流,读取 IoT 设备数据并将其发送到 Kafka,然后在 YARN 中运行的 Flink 流应用程序将对其进行读取、校验数据和计算,然后将结果推送到 Kudu 表中。
Cloudera Edge Management
部署 MiNiFi Agent
首先,我们需要在 IoT 设备上部署 MiNiFi C++ 或 Java 版本的 Agent,并配置 CEM 相关地址信息,目的是通过 CEM 来监控和管理 IoT。
nifi.c2.enable=true
nifi.c2.rest.url=http://cem-server:10080/efm/api/c2-protocol/heartbeat
nifi.c2.rest.url.ack=http://cem-server:10080/efm/api/c2-protocol/acknowledge
## heartbeat in milliseconds. defaults to once a second
nifi.c2.agent.heartbeat.period=1000
## define parameters about your agent
nifi.c2.agent.class=iot_water
# Optional. Defaults to a hardware based unique identifier
nifi.c2.agent.identifier=agent_100
对于 nifi.c2.agent.class 参数的值,可以把 IoT 同样功能的设备配置相同的值,并通过 nifi.c2.agent.identifier 参数值来标识具体 IoT 设备。总结一下,就是对于某个具体的 IoT 设备,nifi.c2.agent.class 和 nifi.c2.agent.identifier 组合的值是全局唯一的。
nifi.c2.rest.url 和 nifi.c2.rest.url.ack 配置 CEM 服务地址。
MiNiFi 部署并启动成功后,开始发送心跳到 CEM 服务。
CEM 监控 Agent
通过 Cloudera Edge Management 的 Monitor 页面,我们可以监控到所有 IoT 设备的 Agent 心跳:
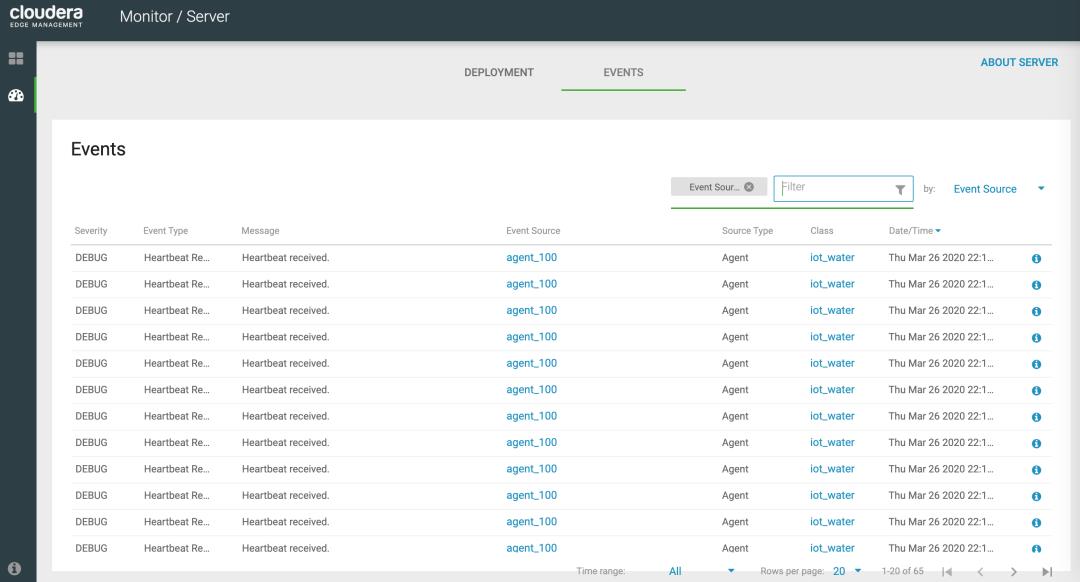
模拟实时生成水表数据
在实际场景中,可以根据 MQTT 协议发送数据。但是为了方便读者实验,笔者模拟实时生成水表数据,提供的 Python(支持2和3)脚本如下,感谢同事提供的模拟脚本:
import random
import sys
import threading
import json
import time
try:
import queue
except:
import Queue as queue
def gen_data(restaurant_id, water_id, q):
update_time = int(time.time())
current_time = int(time.time())
amount = random.randint(10, 50)
while True:
q.put(
"time": int(time.time()),
"restaurant_id": restaurant_id,
"water_id": water_id,
"amount": amount,
)
if amount < 100 and random.choice([True, False]):
percent = random.randint(3, 8)
if (amount + percent) < 100:
amount += percent
update_time = current_time
if current_time - update_time >= 6000:
break
time.sleep(30)
def write_data(file, q):
with open(file, 'w') as f:
while True:
data = q.get()
f.write(json.dumps(data) + '\\n')
f.flush()
def main(file):
q = queue.Queue()
for restaurant_id in range(1, 11):
for water_id in [1, 2]:
t = threading.Thread(target=gen_data, args=(restaurant_id, water_id, q))
t.start()
write_data(file, q)
if __name__ == '__main__':
main(sys.argv[1])
脚本功能如下:
10 家餐厅,ID 编号为 1 - 10(restaurant_id 取值为 1-10)
每个餐厅包含 2 个 IoT 水表设备(water_id 取值 1 或 2)
每隔 30s 生成每个餐厅的 2 条水表数据
time 为 event-time 时间
amount 为水表读数,实时增长
Json 格式数据
脚本执行时,每 30 秒生成 20 条数据。
nohup python iot_water.py iot_water.json &
类似如下的 Json 格式数据:
"restaurant_id": 2, "water_id": 2, "amount": 12, "time": 1585221777
"restaurant_id": 9, "water_id": 2, "amount": 38, "time": 1585221777
"restaurant_id": 1, "water_id": 1, "amount": 27, "time": 1585221777
"restaurant_id": 10, "water_id": 1, "amount": 17, "time": 1585221777
"restaurant_id": 3, "water_id": 1, "amount": 52, "time": 1585221777
"restaurant_id": 5, "water_id": 2, "amount": 28, "time": 1585221777
"restaurant_id": 9, "water_id": 1, "amount": 47, "time": 1585221777
"restaurant_id": 4, "water_id": 1, "amount": 41, "time": 1585221777
"restaurant_id": 6, "water_id": 2, "amount": 45, "time": 1585221777
"restaurant_id": 6, "water_id": 1, "amount": 30, "time": 1585221777
"restaurant_id": 2, "water_id": 1, "amount": 33, "time": 1585221777
"restaurant_id": 7, "water_id": 1, "amount": 37, "time": 1585221777
"restaurant_id": 7, "water_id": 2, "amount": 51, "time": 1585221777
"restaurant_id": 8, "water_id": 1, "amount": 11, "time": 1585221777
"restaurant_id": 8, "water_id": 2, "amount": 10, "time": 1585221777
"restaurant_id": 10, "water_id": 2, "amount": 47, "time": 1585221777
"restaurant_id": 3, "water_id": 2, "amount": 20, "time": 1585221777
"restaurant_id": 5, "water_id": 1, "amount": 41, "time": 1585221777
"restaurant_id": 4, "water_id": 2, "amount": 36, "time": 1585221777
"restaurant_id": 1, "water_id": 2, "amount": 35, "time": 1585221777
Design 设计 Agent
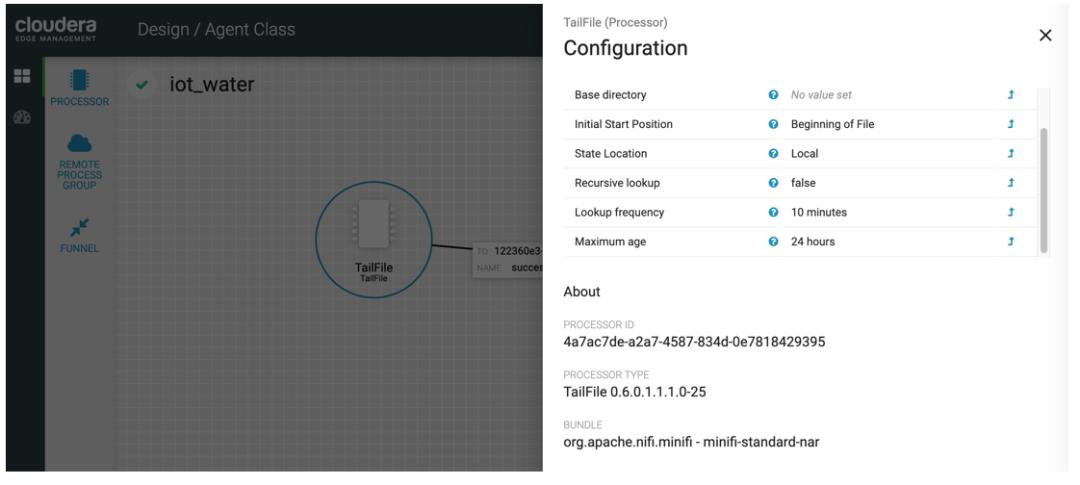
选择 TailFile Processor,配置上面在 IoT 设备上模拟生成的数据文件 iot_water.json 路径,以及文件状态等参数。
然后,选择 REMOTE PROCESS GROUP,填写 NiFi 实例的 URL,另外 TRANSPORT PROTOCOL 要选择 HTTP。
接着,我们将 TailFile Processor 和 REMOTE PROCESS GROUP 连接起来:

需要填写 DESTINATION INPUT PORT ID,这个 INPUT PORT ID 需要在 NiFi 中先生成。
此时我们到 NiFi 可视化页面配置对应的 Input Port:
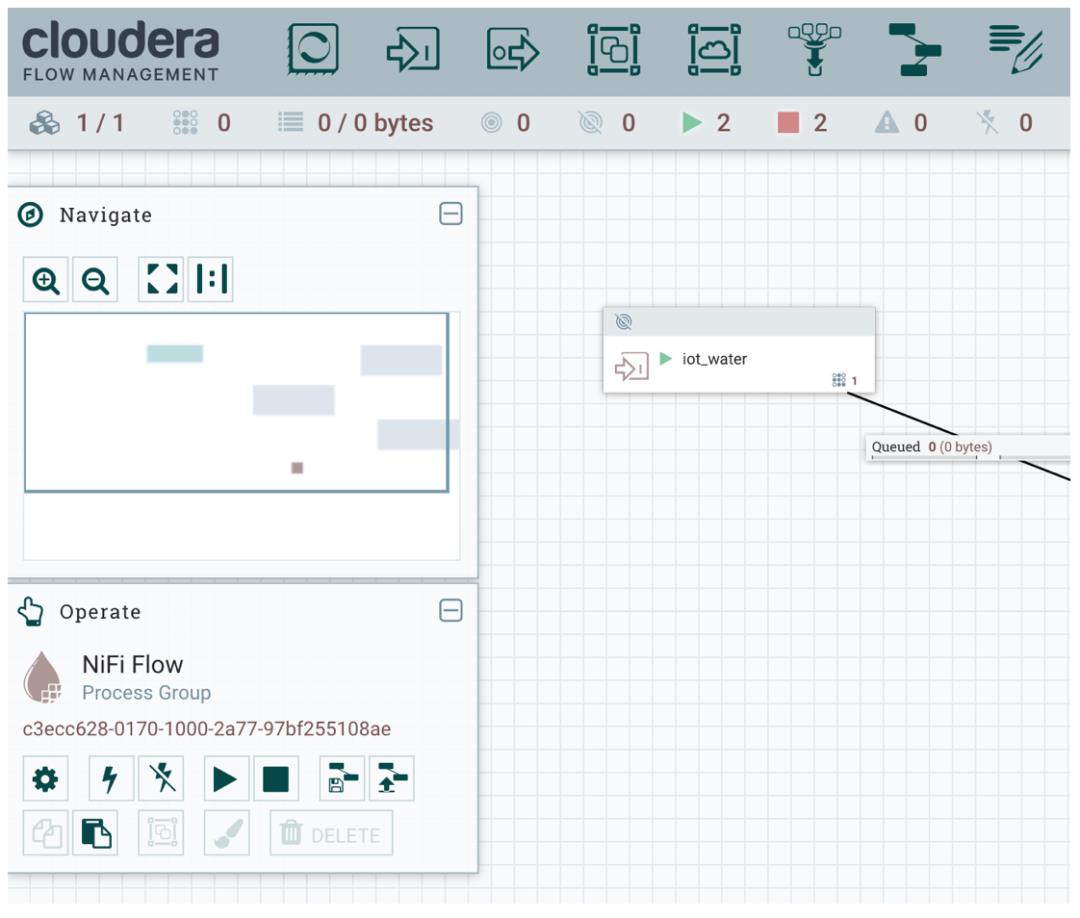
点击 iot_water,可以看到左下角有一个 ID,如下图所示:
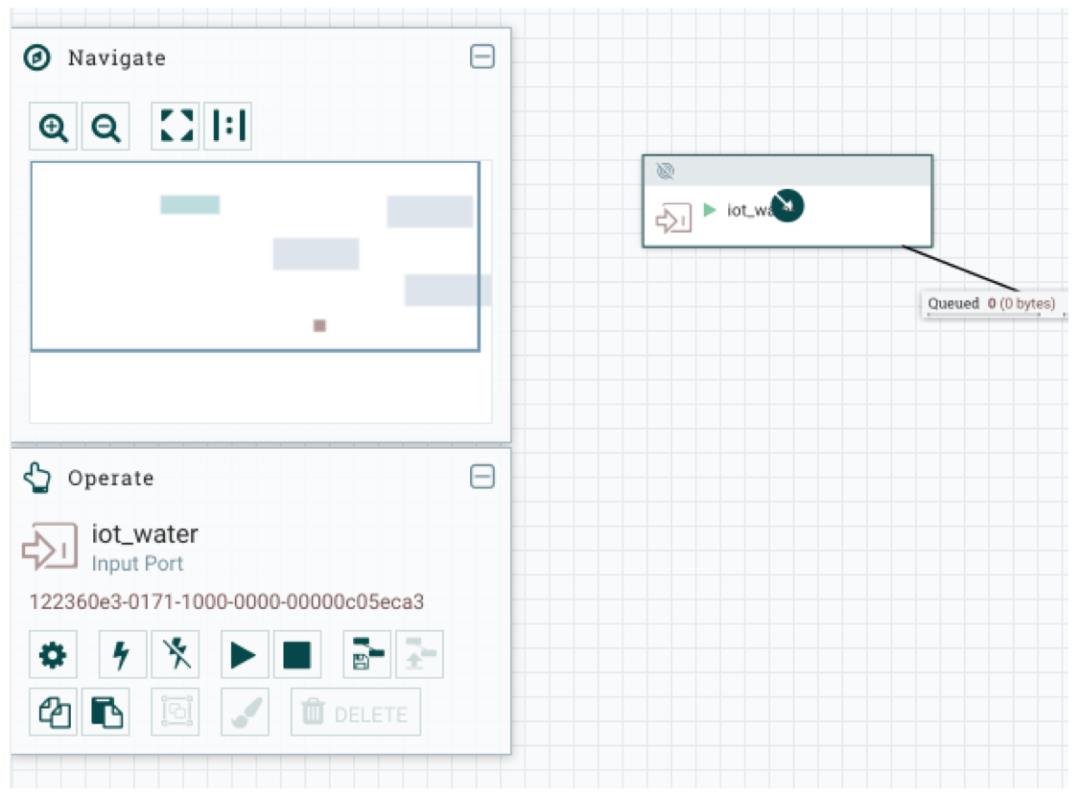
拷贝此 Id 并粘贴到 DESTINATION INPUT PORT ID 中,如下:
最后选择 ACTION 中的 Publish,将 Flow 推送至 NiFi 和 NiFi Registry。
NiFi 设计
Kafka 存储采集的原始设备数据
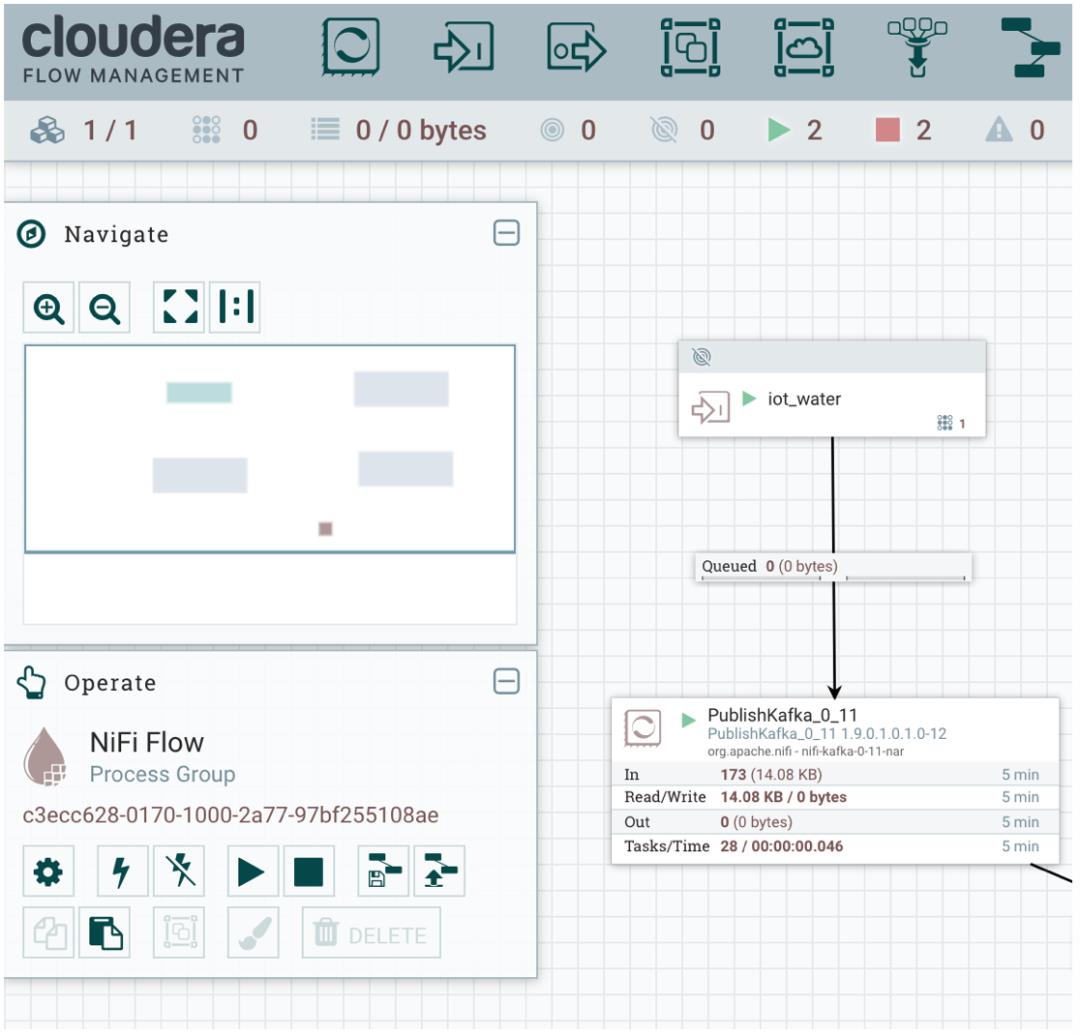
Input Port
Input Port 名称为 iot_water,接收来自 MiNiFi 采集的数据(NiFi 的输入端口对应 Minifi 的输出端口)。上面我们打通了 MiNiFi 和 NiFi,就是通过 Input Port 通过 HTTP 方式实现。笔者在实际应用中还会使用 Output Port 来开发 Flink 应用程序和 NiFi 交互。Processor
这里针对 Kafka 的测试环境版本,使用 Kafka 0.11 Producer,因此选择 PublishKafka_0_11 Processor,读者根据实际情况选择对应的 Processor。
Flink 处理设备数据
有时我们需要对设备数据进行处理,可能就会考虑使用 Flink 或 Spark 来实时消费 Kafka Topic 数据并根据业务指标来进行逻辑处理或者机器学习等。笔者一般使用 Flink 消费 Kafka 数据来进行实时计算,读者要注意 Kafka 和 Flink 的版本兼容性。
这一块涉及到针对具体业务的代码开发,后续笔者把一些案例项目放到 github 上,再分享出来。
另外,我们也可以使用 Flink 结合 NiFi Connector 进行操作,这样就可以让跑在 Flink 上的作业和 NiFi 流程结合起来,进行数据流实时处理,这里给一个示例:
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.connectors.nifi.NiFiDataPacket;
import org.apache.flink.streaming.connectors.nifi.NiFiSource;
import org.apache.nifi.remote.client.SiteToSiteClient;
import org.apache.nifi.remote.client.SiteToSiteClientConfig;
import org.apache.nifi.remote.protocol.SiteToSiteTransportProtocol;
public class NifiConnector
public static void main(String[] args) throws Exception
StreamExecutionEnvironment streamExecEnv = StreamExecutionEnvironment.getExecutionEnvironment();
SiteToSiteClientConfig clientConfig = new SiteToSiteClient.Builder()
.url("http://nifi-server:8080/nifi")
.portIdentifier("0c2435f3-0171-1000-ffff-ffffd25ac100")
.portName("flink")
.requestBatchCount(1)
.transportProtocol(SiteToSiteTransportProtocol.HTTP)
.buildConfig();
SourceFunction<NiFiDataPacket> nifiSource = new NiFiSource(clientConfig);
DataStreamSource<NiFiDataPacket> niFiDataPacketDataStreamSource = streamExecEnv.addSource(nifiSource);
niFiDataPacketDataStreamSource.print();
streamExecEnv.execute("Nifi2Flink");
如果代码显示太乱,直接看截图版本:

Kudu 存储计算的结果
在这个案例中,笔者并没有使用 Flink 处理 IoT 设备数据,毕竟原始数据比较简单,可以直接存储到 Kudu 中。不过读者可以使用 Flink 对消费的 Kafka 数据进行过滤操作、汇总操作、时间戳转换操作等等。
我们在上面设计 NiFi 流程时,已经把采集的 IoT 设备数据写入 Kafka Topic 为 iot_water 中,接下来我们继续添加直接消费 Kafka iot_water 数据(忽略 Flink 实时计算)并写入 Kudu 的流程。
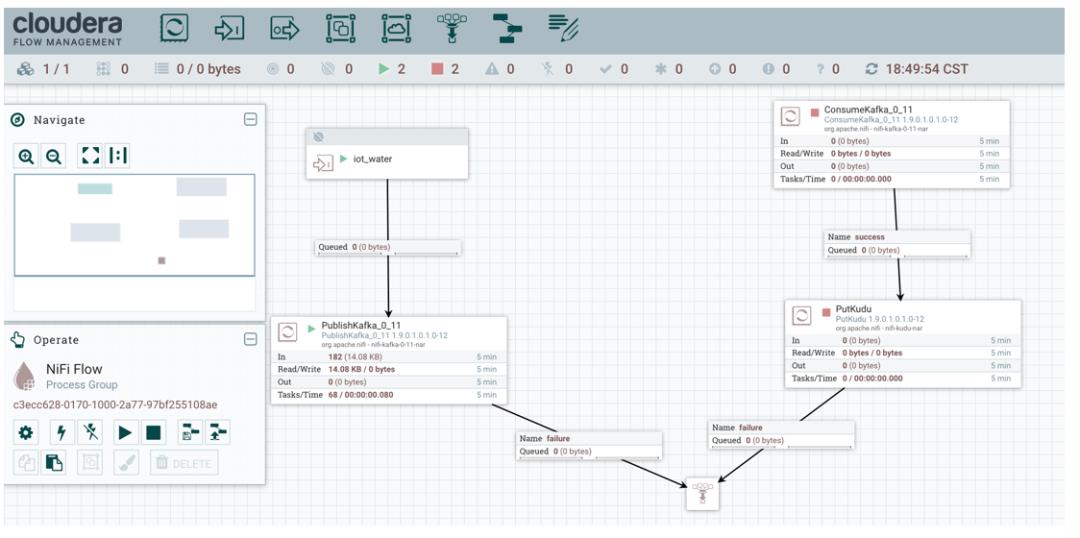
这块流程设计时,包括消费 Kafka 数据以及数据写入 Kudu。
消费 Kafka 数据
选择 Kafka 对应版本的 Consumer,笔者这里选择 ConsumeKafka_0_11。
Security Protocol 支持多种方式:
PLAINTEXT
SSL
SASL_PLAINTEXT
SASL_SSL
笔者使用测试环境比较简单,直接使用 PLAINTEXT。Topic Name(s) 填写前面采集 IoT 设备数据的 iot_water。
数据写入 Kudu
我们选择 PutKudu,写入 Kudu 数据库,当然如果没有部署 Kudu,也可以存储到 HBase(选择 PutHBaseJSON Processor)。
1. 通过 impala-shell 在 Kudu 中创建表:
CREATE TABLE iot_water
(
time BIGINT,
restaurant_id INT,
water_id INT,
amount INT,
PRIMARY KEY(time, restaurant_id, water_id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU;
2. Table Name
Table Name 参数配置具体的 Kudu 表名,如果通过 Impala 创建,要注意表名,笔者这里为 impala::default.iot_water。如果读者不知道表名的完整名称,可以通过 kudu table list master_addresses 命令查看 Kudu 表名。其实在 Impala 中,Kudu 的表也是显示具体的表名,不知道直接写db.table 行不行,读者试一下即可。
3. Kerberos Credentials Service
如果开启了 Kerberos,需要选择 KeytabCredentialsService,并配置该 Controller Service Details:


配置完成后,要 Enabled,即 State 状态为 Enabled。
4. Record Reader
选择 JsonTreeReader,并进行配置,默认值即可:
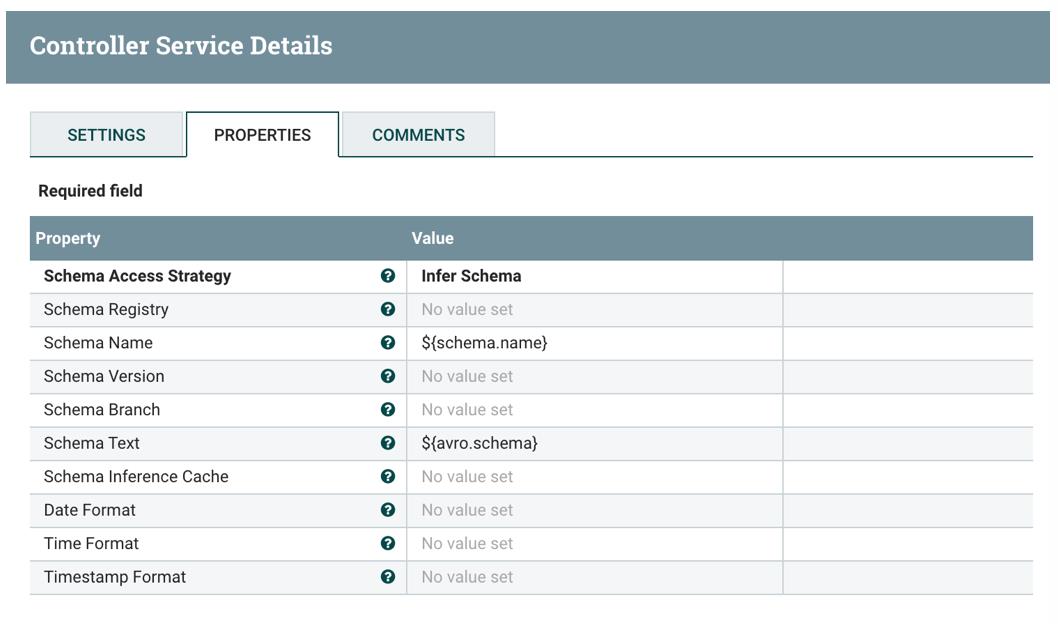
PutKudu 处理器自动推断 JSON 数据的模式并写入配置的 Kudu 表中。
5. Insert Operation
根据需求可以选择 INSERT、INSERT_IGNORE 或 UPSERT。
6. Flush Mode
根据需求可以选择 AUTO_FLUSH_BACKGROUND、AUTO_FLUSH_SYNC 或 MANUAL_FLUSH。
启动 NiFi 流程

到此,我们在 NiFi 中完成了整个流程的配置,接下来启动 NiFi 流程后,就会从上图中看到数据流的动态变化(在实际开发中,我们会一个一个启动流,方便检查程序逻辑的结果是否符合预期以及排查错误)。
NiFi 运行正常后,通过 impala-shell 来查看 Kudu 里面的数据,比如简单获取最新的水表读数:
select from_unixtime(time,'yyyy-MM-dd HH:mm:ss') as iot_time,
restaurant_id,
water_id,
amount
from iot_water
order by time desc limit 20;
+---------------------+---------------+----------+--------+
| iot_time | restaurant_id | water_id | amount |
+---------------------+---------------+----------+--------+
| 2020-03-26 19:33:27 | 4 | 1 | 97 |
| 2020-03-26 19:33:27 | 10 | 2 | 98 |
| 2020-03-26 19:33:27 | 6 | 2 | 79 |
| 2020-03-26 19:33:27 | 1 | 1 | 99 |
| 2020-03-26 19:33:27 | 6 | 1 | 97 |
| 2020-03-26 19:33:27 | 1 | 2 | 84 |
| 2020-03-26 19:33:27 | 5 | 2 | 72 |
| 2020-03-26 19:33:27 | 5 | 1 | 93 |
| 2020-03-26 19:33:27 | 10 | 1 | 59 |
| 2020-03-26 19:33:27 | 2 | 1 | 86 |
| 2020-03-26 19:33:27 | 3 | 2 | 96 |
| 2020-03-26 19:33:27 | 3 | 1 | 97 |
| 2020-03-26 19:33:27 | 2 | 2 | 69 |
| 2020-03-26 19:33:27 | 7 | 2 | 96 |
| 2020-03-26 19:33:27 | 4 | 2 | 99 |
| 2020-03-26 19:33:27 | 8 | 1 | 57 |
| 2020-03-26 19:33:27 | 7 | 1 | 93 |
| 2020-03-26 19:33:27 | 9 | 1 | 91 |
| 2020-03-26 19:33:27 | 8 | 2 | 78 |
| 2020-03-26 19:33:27 | 9 | 2 | 94 |
+---------------------+---------------+----------+--------+
Fetched 20 row(s) in 0.23s
如果不想存储明细数据,只想保留最新的水表读数,那么创建 Kudu 表时设置primary key 为 (restaurant_id, water_id),然后将 Insert Operation 设置为 UPSERT。
当然,也可以 Kudu 的数据接入公司的可视化报表平台,实时查询数据。笔者这里使用 CDH 自带的 Hue 查询结果展示一下:

X 坐标为 restaurant_id,Y 坐标为 amount,显示的柱状图为每个 restaurant_id 的两个 IoT 设备的水表读数。
总结
在本篇文章中,笔者使用 NiFi 和 MiNiFi 以可视化的方式配置 IoT 事件消息的实时数据流处理的较为完整的流程,但是笔者只是做了一个引子,希望对读者带来一点点帮助,大家也可以结合业务的实际需求进行实战。
你若喜欢,点个在看哦

以上是关于物联网遇到流计算的主要内容,如果未能解决你的问题,请参考以下文章