Tesseract-OCR编译及ViewerDebugging使用
Posted ayanwan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tesseract-OCR编译及ViewerDebugging使用相关的知识,希望对你有一定的参考价值。
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
一、简介
Tesseract-OCR依赖图像库Leptonica。 Leptonica是一个开源的图像处理和图像分析库。它主要包括的操作有:位图操作、仿射变换、形态学操作、连通区域填充、图像变换及像素掩模、融合、增强、算术运算等操作。
在使用Leptonica的时候,它依赖于开源的zlib、libjpeg、libpng、libtiff、giflib。
(1)zlib是一个很好的压缩、解压缩库。它的license是zlib授权,类似BSD。
(2)libjpeg是一个完全用C语言编写的库,包含了被广泛使用的JPEG解码、JPEG编码和其它的JPEG功能的实现。它的license类似BSD。
(3)libpng是官方的PNG参考库,它支持几乎所有的PNG功能,它也是可扩展的。它使用zlib库作为压缩引擎。它的license是permissive free software license,类似BSD。
(4)libtiff是一个用来读写TIFF文件的开源库,它依赖于libjpeg和zlib。它的license是BSD。
(5)giflib是一个读、写GIF图像的开源库,它的license类似BSD。
二、编译环境搭建
1、系统平台:windows10 - VS2013
2、Leptonica编译,可以直接从以下路径下载对应的VS版本:
https://github.com/charlesw/tesseract-vs2012
https://github.com/tesseract4java/tesseract-vs2013
载入相应的VS后,编译出对应的库
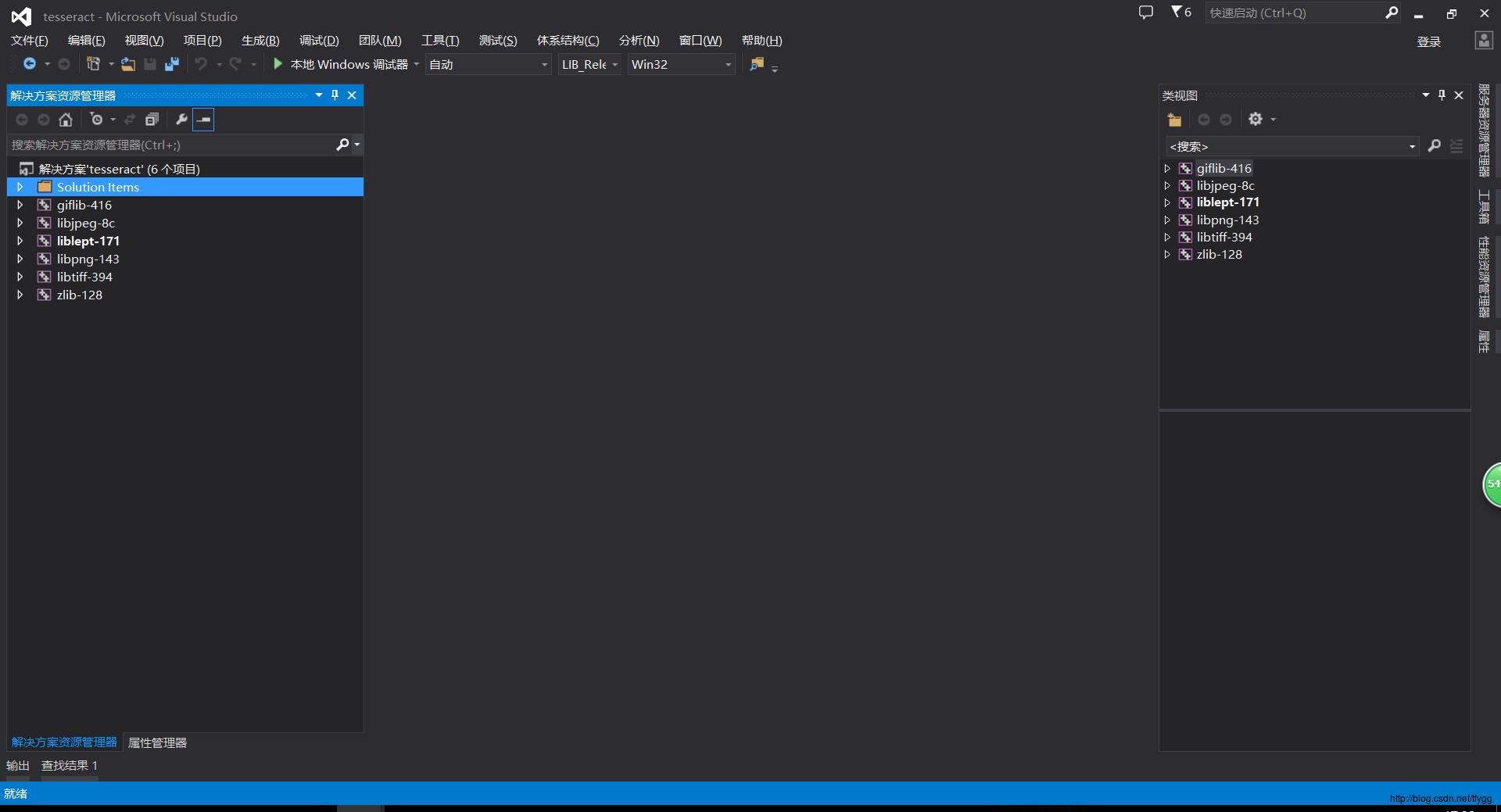
编译完成之后,会产tesseract-vs2013-master目录下生产一个buidl目录,build\\lib\\Win32下的库就是我们所需的各种库。
3、Tesseract-OCR
下载地址:https://github.com/charlesw/tesseract-vs
把 tesseract-vs2013-master/release 下面的include, lib目录整体复制到:\\tesseract-ocr,复制好的目录结构如下:
.. /tesseract-ocr/
+---include/
+---lib/
+---tesseract-vs-master/
+---tesseract-vs2013-master/
然后就可以进行编译了,接下来就可以进行验证了。
【测试】
1、命令行,执行:tesseract.exe dst2.png out

out就是输出的文件,共检测到49个文件。
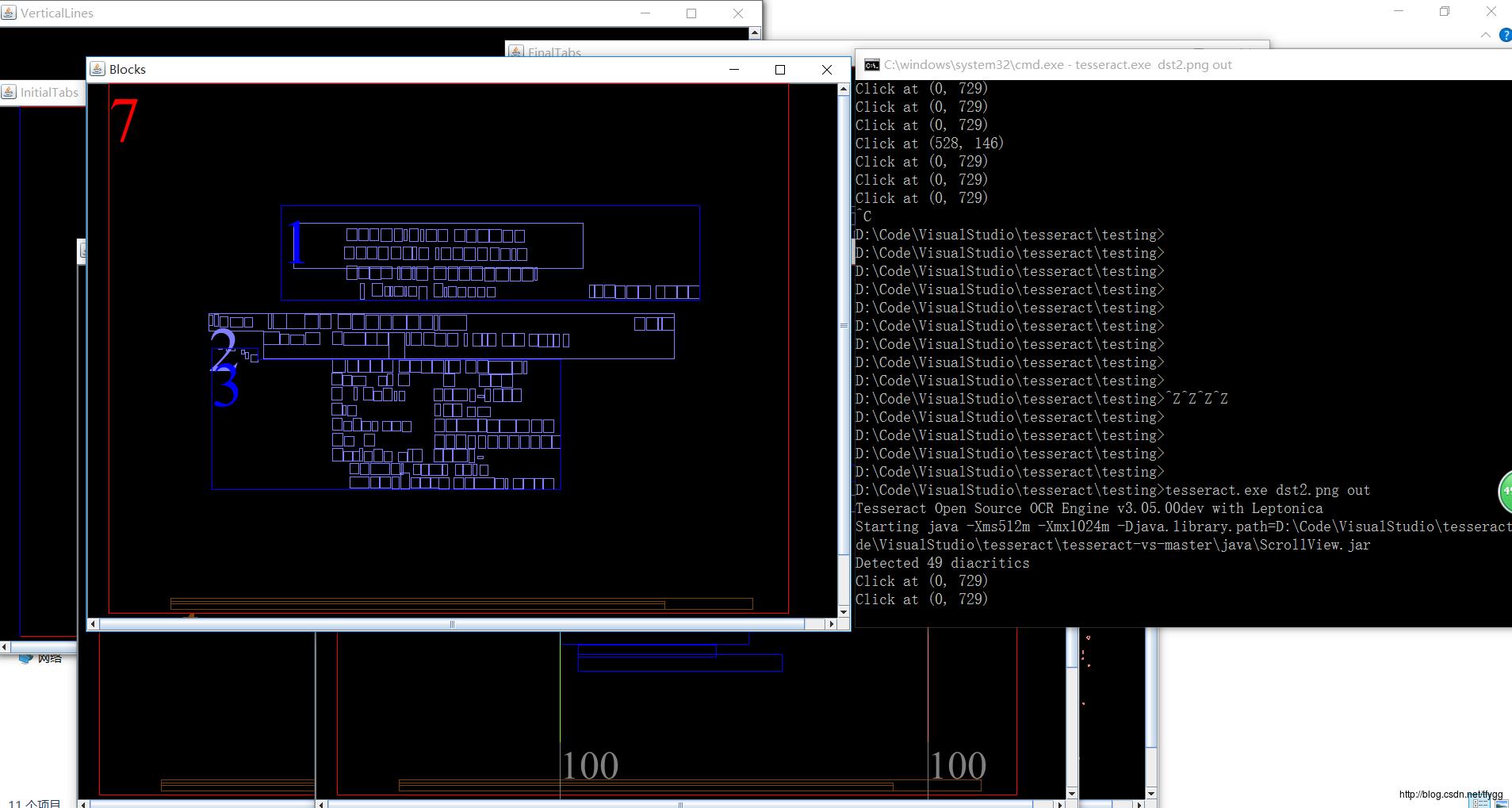
三、ViewerDebugging调试工具
首先,在tesseractmain.cpp文件中,加入以下代码:
if (!renderers.empty())
if (banner) PrintBanner();
//加入的调试信息
api.SetVariable("tessedit_dump_pageseg_images", "true"); //show no lines and no image picture
api.SetVariable("textord_show_blobs", "true"); //show blobs result
api.SetVariable("textord_show_boxes", "true"); //show blobs' bounding boxes
api.SetVariable("textord_tabfind_show_blocks", "true"); //show candidate tab-stops and tab vectors
api.SetVariable("textord_tabfind_show_reject_blobs", "true"); //show rejected blobs
api.SetVariable("textord_tabfind_show_initial_partitions", "true"); //show initial partitions
api.SetVariable("textord_tabfind_show_partitions", "1"); //show final partitions
api.SetVariable("textord_tabfind_show_initialtabs", "true"); //show initial tab-stops
api.SetVariable("textord_tabfind_show_finaltabs", "true"); //show final tab vectors
api.SetVariable("textord_tabfind_show_images", "true"); //show image blobs
bool succeed = api.ProcessPages(image, NULL, 0, renderers[0]);
if (!succeed)
fprintf(stderr, "Error during processing.\\n");
exit(1);
piccolo2d-core-3.0.jar
piccolo2d-extras-3.0.jar
下载后(请点击),就可以进行调试了。效果如下:
以上是关于Tesseract-OCR编译及ViewerDebugging使用的主要内容,如果未能解决你的问题,请参考以下文章