目标检测YOLOv5-7.0:加入实例分割
Posted zstar-_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测YOLOv5-7.0:加入实例分割相关的知识,希望对你有一定的参考价值。
前言
前段时间,YOLOv5推出7.0版本,主要更新点是在目标检测的同时引入了实例分割。
目前,YOLOv5团队已经转向了YOLOv8的更新,因此,7.0版本大概率是YOLOv5的最终稳定版。
更新信息
官方公告中给出了YOLOv5-7.0的更新要点:
- 推出了基于coco-seg的实例分割预训练模型
- 支持Paddle Paddle模型导出
- 自动缓存机制:使用
python train.py --cache ram可以自动扫描可用内存,并且为数据集的加载进行分配 - 加入Comet日志记录和可视化集成
实例分割实践
下载代码
git clone https://github.com/ultralytics/yolov5.git -b v7.0
下载预训练模型
官方仓库有不同模型大小的预训练模型,这里以yolov5m-seg为例。
下载链接:https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m-seg.pt
下载数据集
这里以教程文档中的coco128-seg.zip数据集为例。
下载链接:https://ultralytics.com/assets/coco128-seg.zip
数据集的文件结构如下:
- coco128-seg
- images
- train2017
- labels
- train2017
- images
数据集标签可视化
coco-seg数据集和coco数据集图片一样,唯一区别是标签不同。
coco-seg的标签示例如下:
45 0.557859 0.143813 0.487078 0.0314583 0.859547 0.00897917 0.985953 0.130333 0.984266 0.184271 0.930344 0.386521 0.80225 0.480896 0.763484 0.485396 0.684266 0.39775 0.670781 0.3955 0.679219 0.310104 0.642141 0.253937 0.561234 0.155063 0.559547 0.137083
50 0.39 0.727063 0.418234 0.649417 0.455297 0.614125 0.476469 0.614125 0.51 0.590583 0.54 0.569417 0.575297 0.562354 0.601766 0.56 0.607062 0.536479 0.614125 0.522354 0.637063 0.501167 0.665297 0.48 0.69 0.477646 0.698828 0.494125 0.698828 0.534125 0.712938 0.529417 0.742938 0.548229 0.760594 0.564708 0.774703 0.550583 0.778234 0.536479 0.781766 0.531771 0.792359 0.541167 0.802937 0.555292 0.802937 0.569417 0.802937 0.576479 0.822359 0.576479 0.822359 0.597646 0.811766 0.607062 0.811766 0.618833 0.818828 0.637646 0.820594 0.656479 0.827641 0.687063 0.827641 0.703521 0.829406 0.727063 0.838234 0.708229 0.852359 0.729417 0.868234 0.750583 0.871766 0.792938 0.877063 0.821167 0.884125 0.861167 0.817062 0.92 0.734125 0.976479 0.711172 0.988229 0.48 0.988229 0.494125 0.967063 0.517062 0.912937 0.508234 0.832937 0.485297 0.788229 0.471172 0.774125 0.395297 0.729417
其中第一个为类别标签,后面的两个为一组,即(x1,y1),(x2,y2)…意为一个个点,这些点连线即为所框选的实例。
下面的代码[2]实现了将标签进行可视化:
import cv2
import numpy as np
if __name__ == '__main__':
pic_path = r"coco128-seg\\images\\train2017\\000000000009.jpg"
txt_path = r"coco128-seg\\labels\\train2017\\000000000009.txt"
img = cv2.imread(pic_path)
height, width, _ = img.shape
file_handle = open(txt_path)
cnt_info = file_handle.readlines()
new_cnt_info = [line_str.replace("\\n", "").split(" ") for line_str in cnt_info]
# 45 bowl 碗 49 橘子 50 西兰花
color_map = "49": (0, 255, 255), "45": (255, 0, 255), "50": (255, 255, 0)
for new_info in new_cnt_info:
s = []
for i in range(1, len(new_info), 2):
b = [float(tmp) for tmp in new_info[i:i + 2]]
s.append([int(b[0] * width), int(b[1] * height)])
cv2.polylines(img, [np.array(s, np.int32)], True, color_map.get(new_info[0]))
cv2.imshow('img', img)
cv2.waitKey()

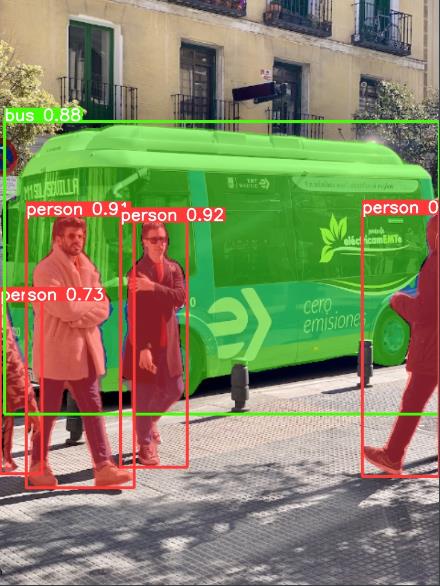
模型检测
下载好预训练模型,可以直接用其进行检测:
python segment/predict.py --weights yolov5m-seg.pt --data data/images/bus.jpg
检测结果存放在runs/predict-seg文件夹中。
模型训练
下面以coco128-seg数据集训练为例,首先修改data/coco128-seg.yaml配置文件,修改相应路径:
path: coco128-seg
train: images/train2017
val: images/train2017
之后终端运行:
python segment/train.py --weights yolov5m-seg.pt --data data/coco128-seg.yaml --epochs 5 --img 640 --project train-seg --batch-size 4
注:
- –project设定了训练结果的保存路径,按照默认路径
runs\\train-seg会引发wandb的报错:wandb.errors.UsageError: Invalid project name "runs\\train-seg": cannot contain characters "/,\\,#,?,%,:", found "\\" - 默认batch-size为16,普通单机有爆显存风险,因此调小。
最终模型依然会保存最佳和最后两个模型,以及一些验证结果图片,和之前版本相似。
参考
[1] YOLOv5官方仓库:https://github.com/ultralytics/yolov5/tree/v7.0
[2] 【深度学习】yolov5 tag7.0 实例分割 从0到1的体会,从模型训练,到量化完成 https://betheme.net/xiaochengxu/38021.html
以上是关于目标检测YOLOv5-7.0:加入实例分割的主要内容,如果未能解决你的问题,请参考以下文章