百度飞桨顶会论文复现营目标检测综述笔记
Posted SSyangguang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百度飞桨顶会论文复现营目标检测综述笔记相关的知识,希望对你有一定的参考价值。
参加了百度飞桨顶会论文复现营第二期,这次是目标检测综述的笔记。
RCNN到Faster RCNN这几种模型讲的实在太多了,直接从FPN开始吧。
FPN:通过将深层特征与浅层特征相融合,并在多层预测,加强了浅层特征图的语义,特征更加鲁棒,定位更加准确。同时提高了检测精度,尤其对于小目标。模型结构图中蓝框越粗语义信息越多,图像分辨率越小,篮框越细上下文信息更强,图像分辨率越高。
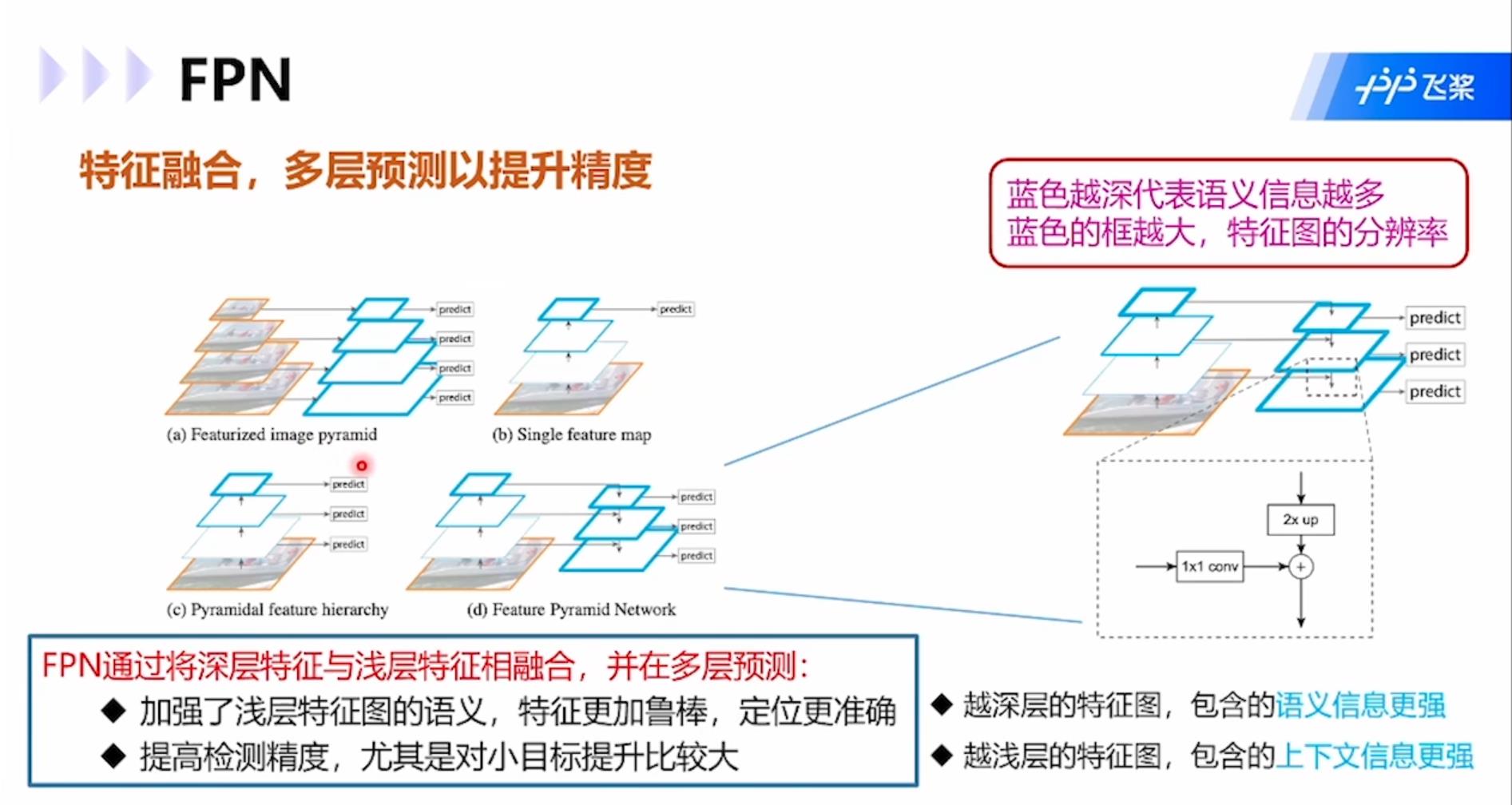
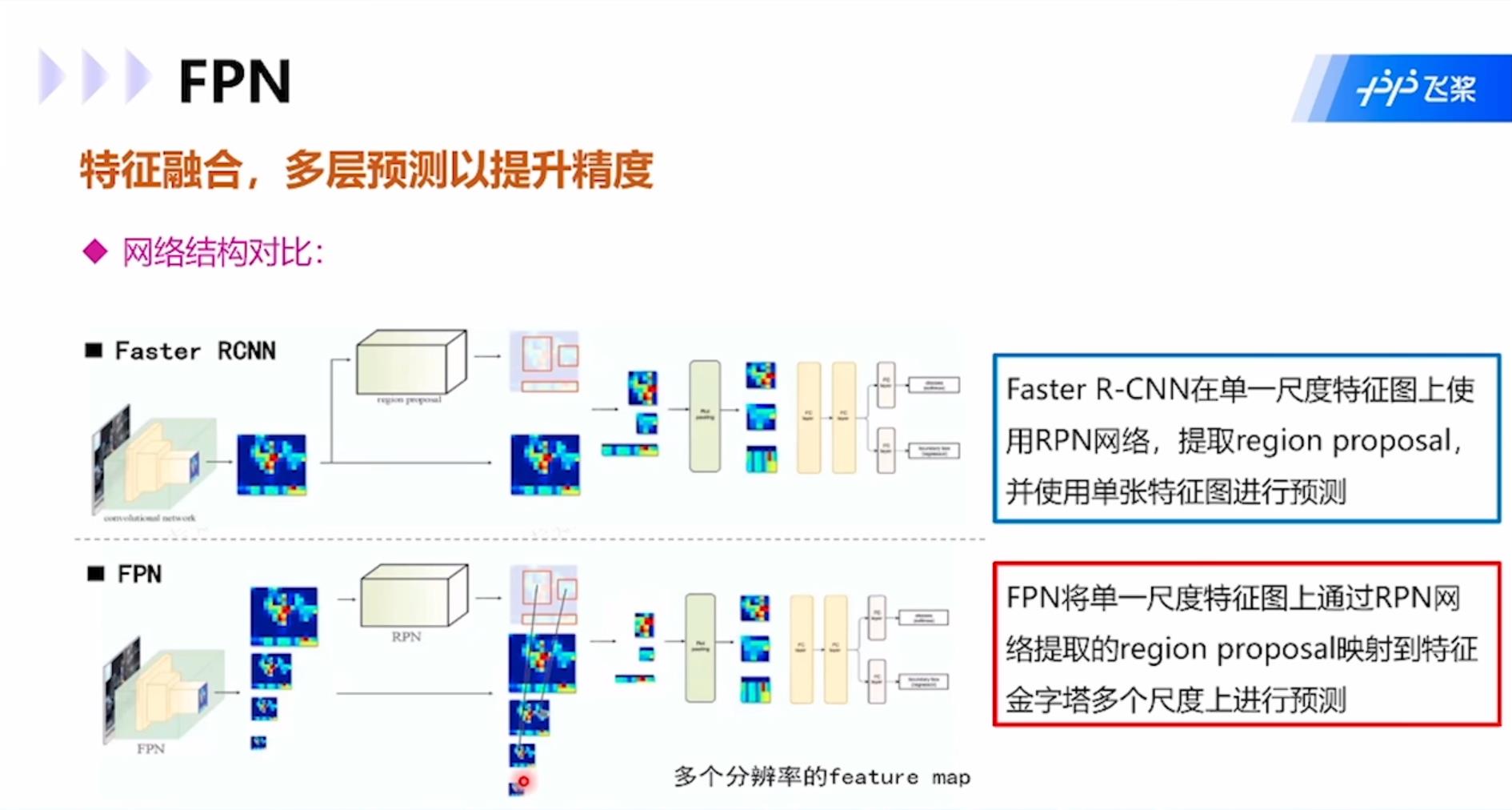
与Faster RCNN相比,FPN将单一尺度特征图上通过RPN网络提取的region proposal映射到特征金字塔多个尺度上进行预测,而Faster RCNN是在单一尺寸特征图上使用RPN网络,提取regional proposal,使用单张特征图进行预测。
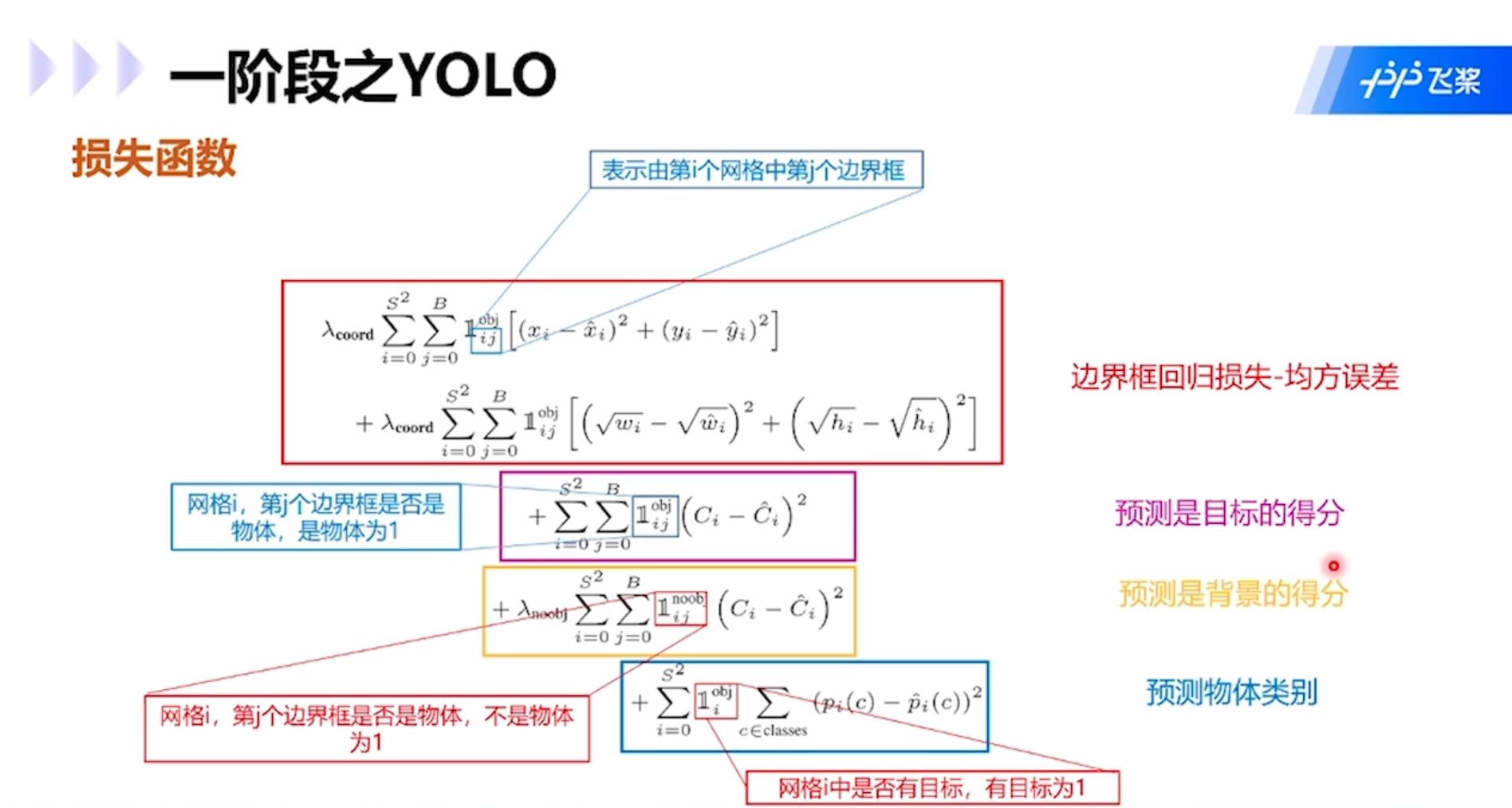
YOLO:属于one-stage模型,算法流程是:1.将输入图像划分为S×S个网格;2.每个网格预测B个边界框和这个边界框是物体的概率,具体为4个表示坐标的值xywh和1个置信度Pr(object)*IoU(truth&pred);3.每个网格预测C个类的概率。
每个网格内的预测边界框并不一定必须在网格内,可以横跨多个网格。每个网格还需要投票该网格的类别,然后将边界框和该网格类别合起来就是目标检测的结果。

损失函数包括四项:边界框回归损失-均方误差;预测是目标的得分;预测是背景的得分;预测物体类别。
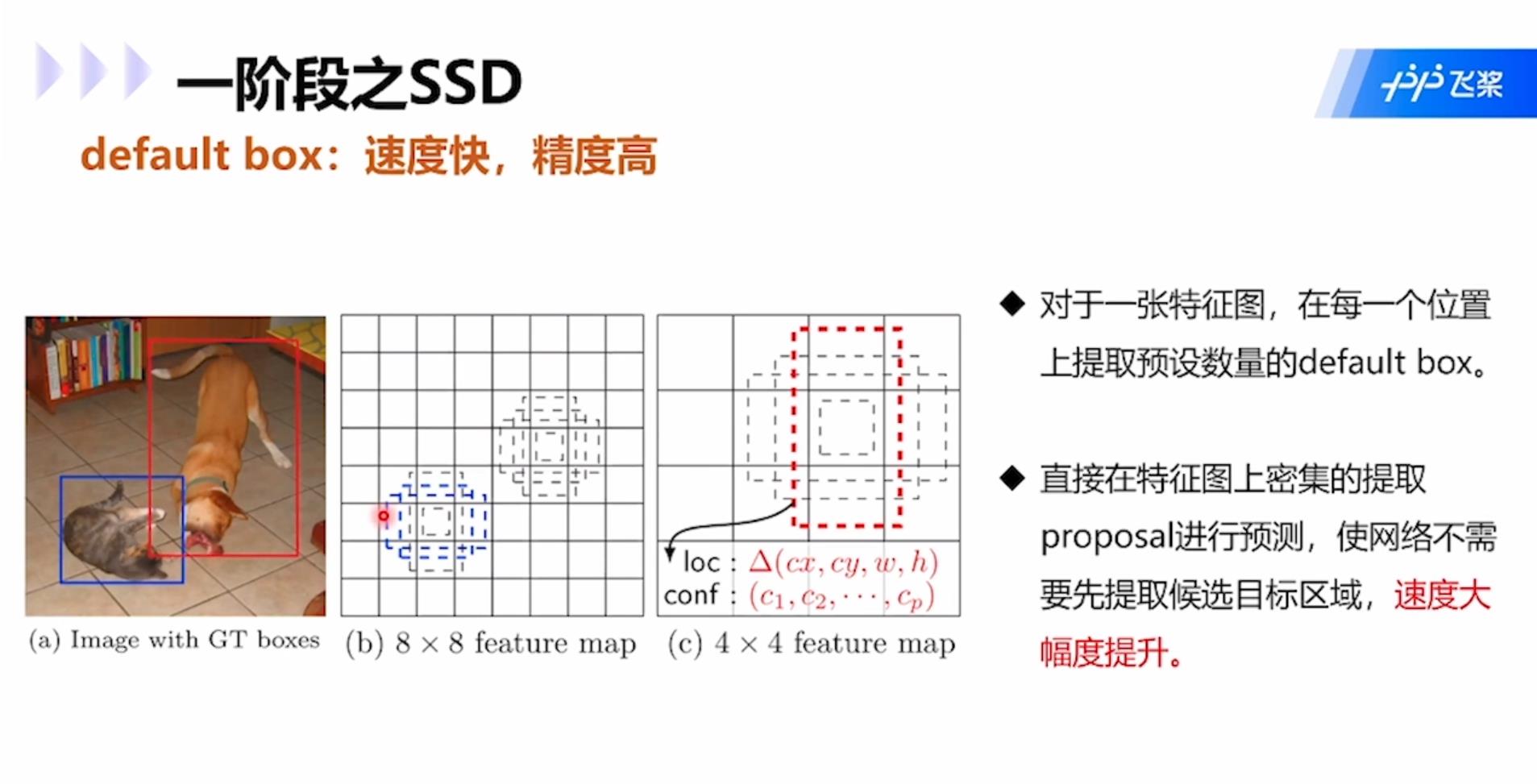
SSD:同属于one-stage模型。对于同一张特征图,在每一个位置上提取预设数量的default box,然后直接在特征图上密集的提取proposal进行预测,使网络不需要先提取候选目标区域,速度大幅提升。
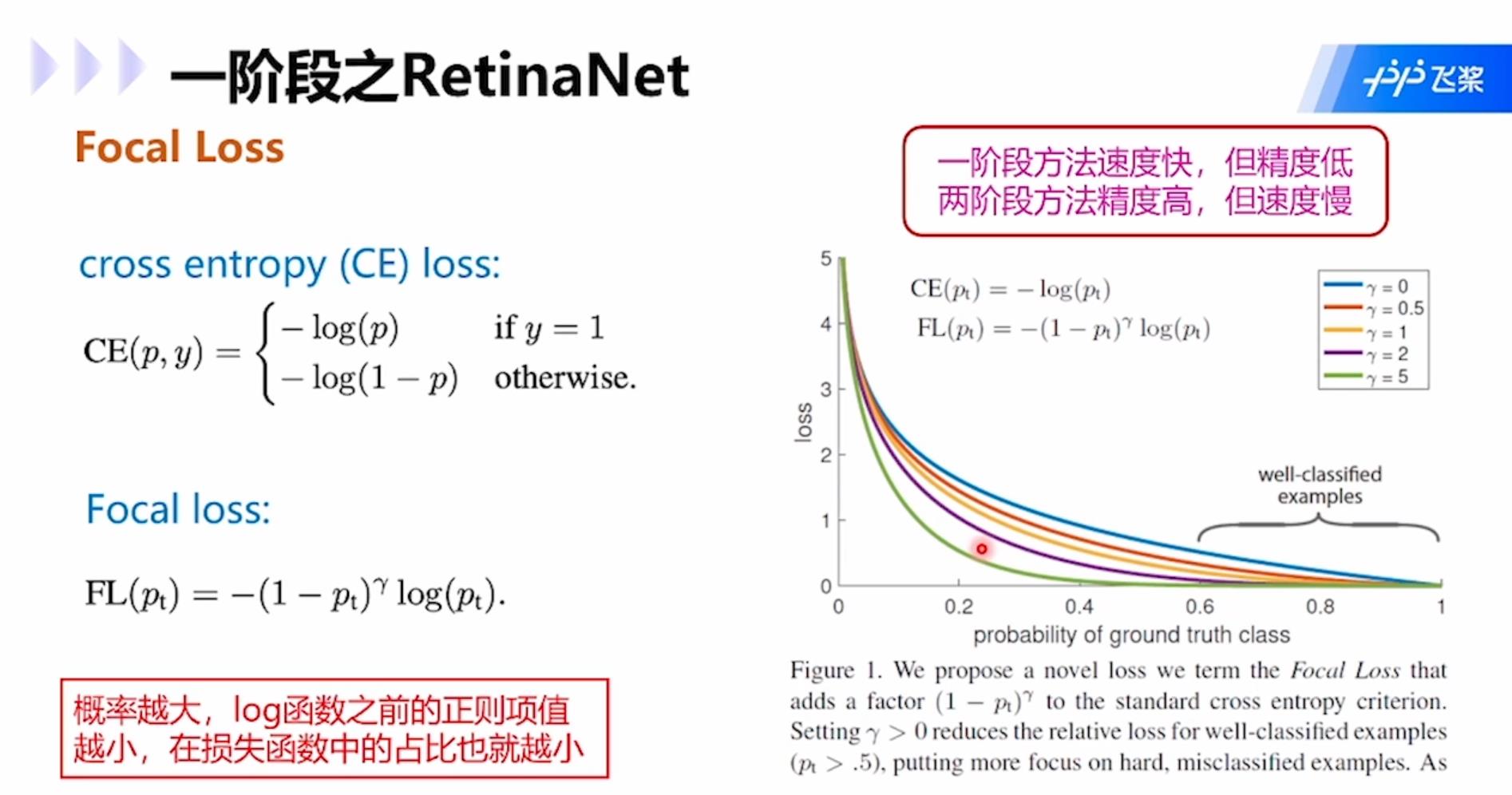
RetinaNet:解决了one-stage模型训练过程中,负样本数量大大超过正样本的问题。类别不平衡是指目标检测算法在早期会生成很多候选区域框,每个框都会生成一个分类类别,然而实际图像中往往只有几个目标,所以大多数候选区域的类别为“背景”,即类别不平衡,是的分类器的训练精度严重受损。
Two-stage模型中,RPN网络可以很大程度减轻类别不平衡问题,使类别极不平衡变为类别较不平衡,然而one-stage方法则会被严重影响精度。改进思路是对损失函数计算进行改进,例如focal loss,适用于各类网络。Focal loss的思路是在交叉熵函数的log前面加上(1-p),这个系数的意思就是1减去属于这个类别的概率,如果属于这个类别的概率比较大,就意味着高置信度被分为这个类别,所以1减去该概率的值就会很小,所以在分类的时候高概率会被分成某个类别的损失值就会比较小,也就是概率越大的类别在损失函数中占比越小,这样网络就会更聚焦在分类概率小的类别中。这样的方法在各类网络中都可以用。
考虑IoU损失的方法IoU-Net:通过非极大值抑制,消除冗余检测框。非极大值抑制NMS是指:1.将同一类的所有检测框按照分类置信度排序;2.将与分类置信度最高的检测框IoU大于一定阈值的检测框删除;3.从未处理的框中,再选出一个分类置信度最高的检测框,重复上述操作。

但是这种方式也会带来分类置信度删除存在问题,例如下图中红色预测框分类置信度高,绿框定位置信度高,如果使用分类置信度进行NMS,那么绿框会被舍弃,显然当前情况下绿框的预测效果要好些。分类置信度和定位准确度不对齐:只依靠分类的置信度来作为NMS中关键依据,可能会导致大量高质量的边界框丢失。

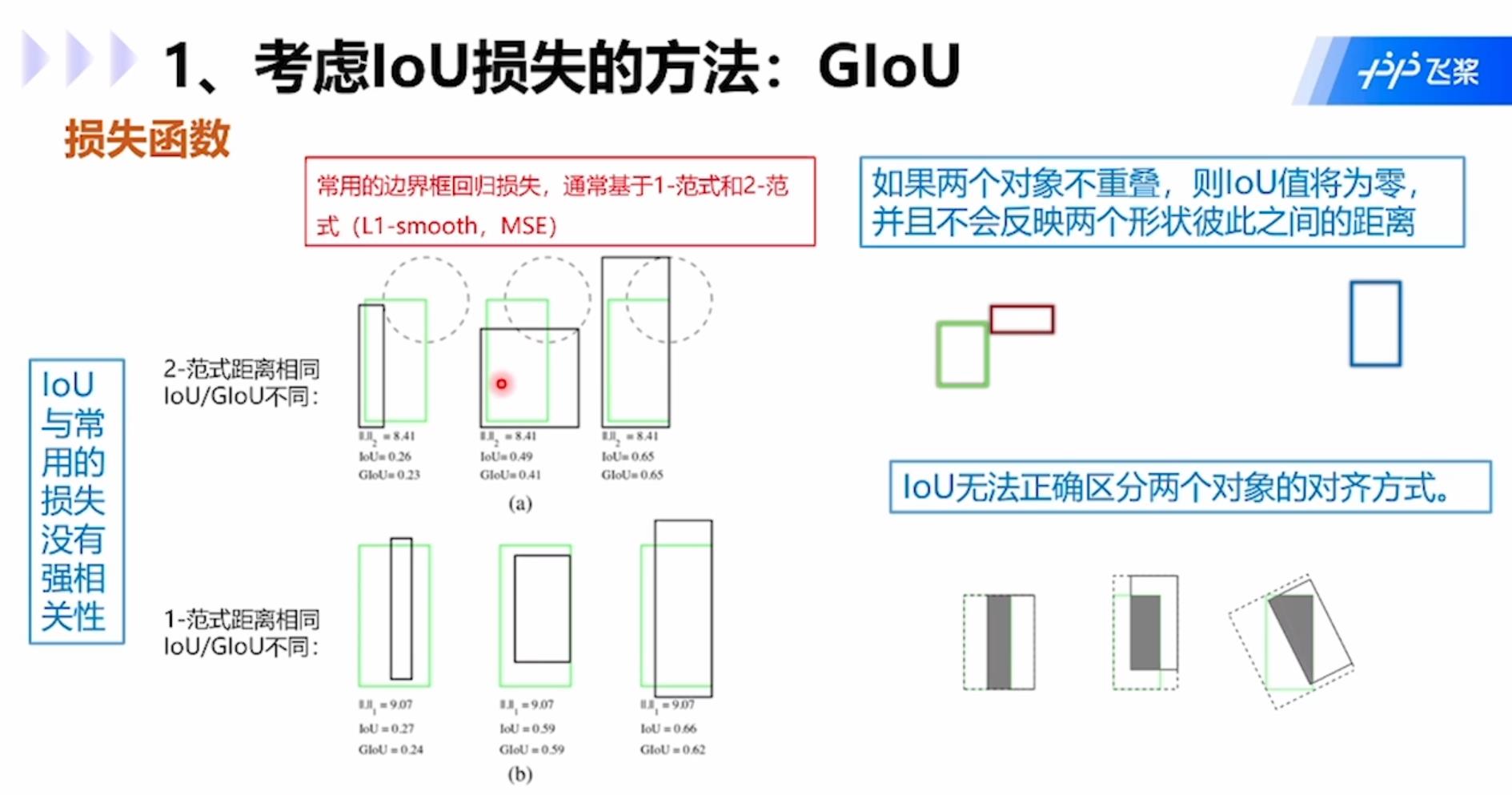
IoU存在的问题包括:1.IoU与常用的损失没有强相关性;2.如果两个对象不重叠,那么IoU为0,并且不会反应两个形状彼此之间的距离;3.IoU无法正确区分两个对象的对齐方式。
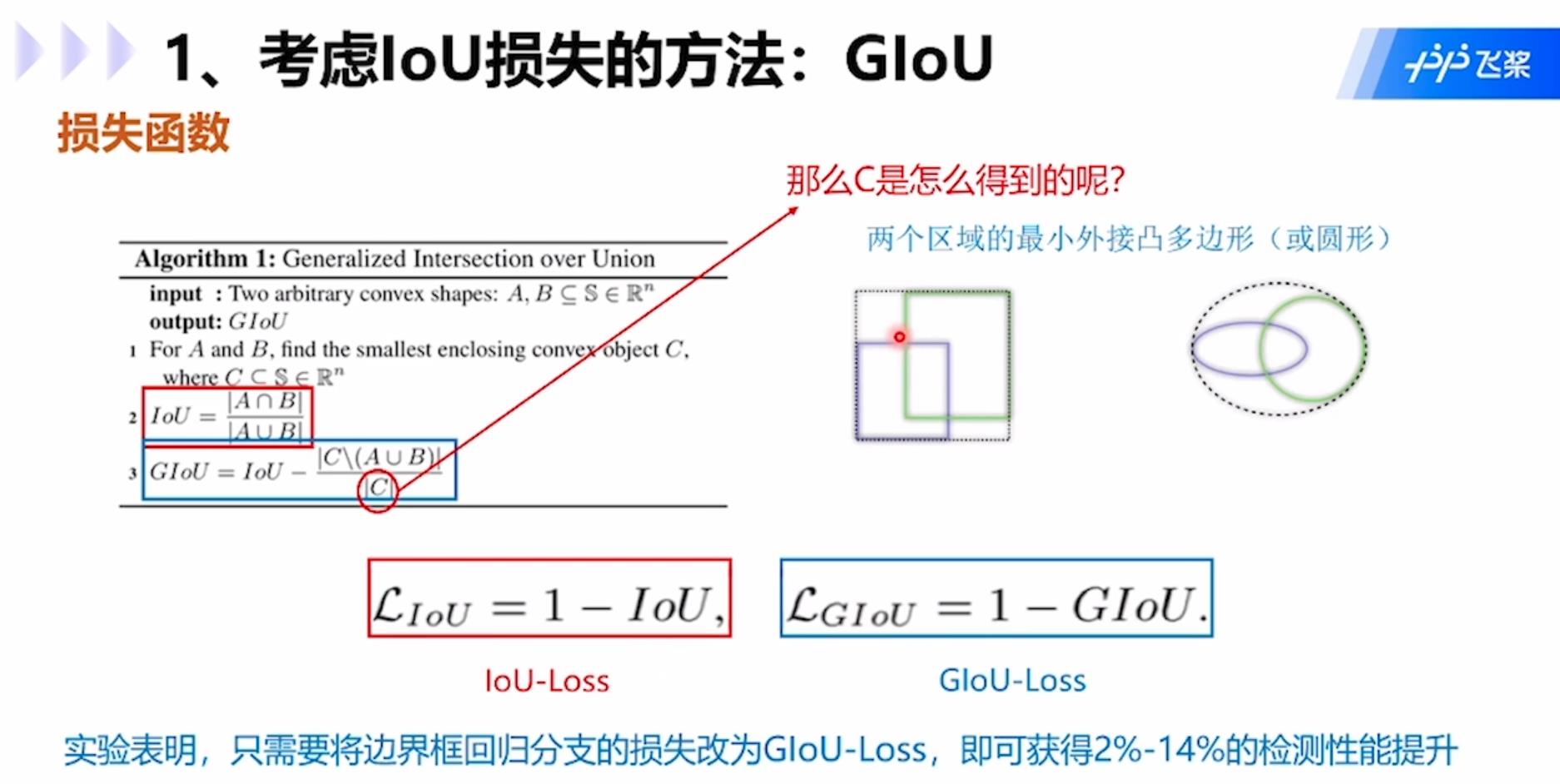
GIoU:GIoU公式中C是两个矩形框的最小外接矩形,就是虚线的大矩形框,公式中分子是外接矩形框去除两个小矩形框A和B后的部分,分母就是C,用IOU减去该值就是GIOU的值。
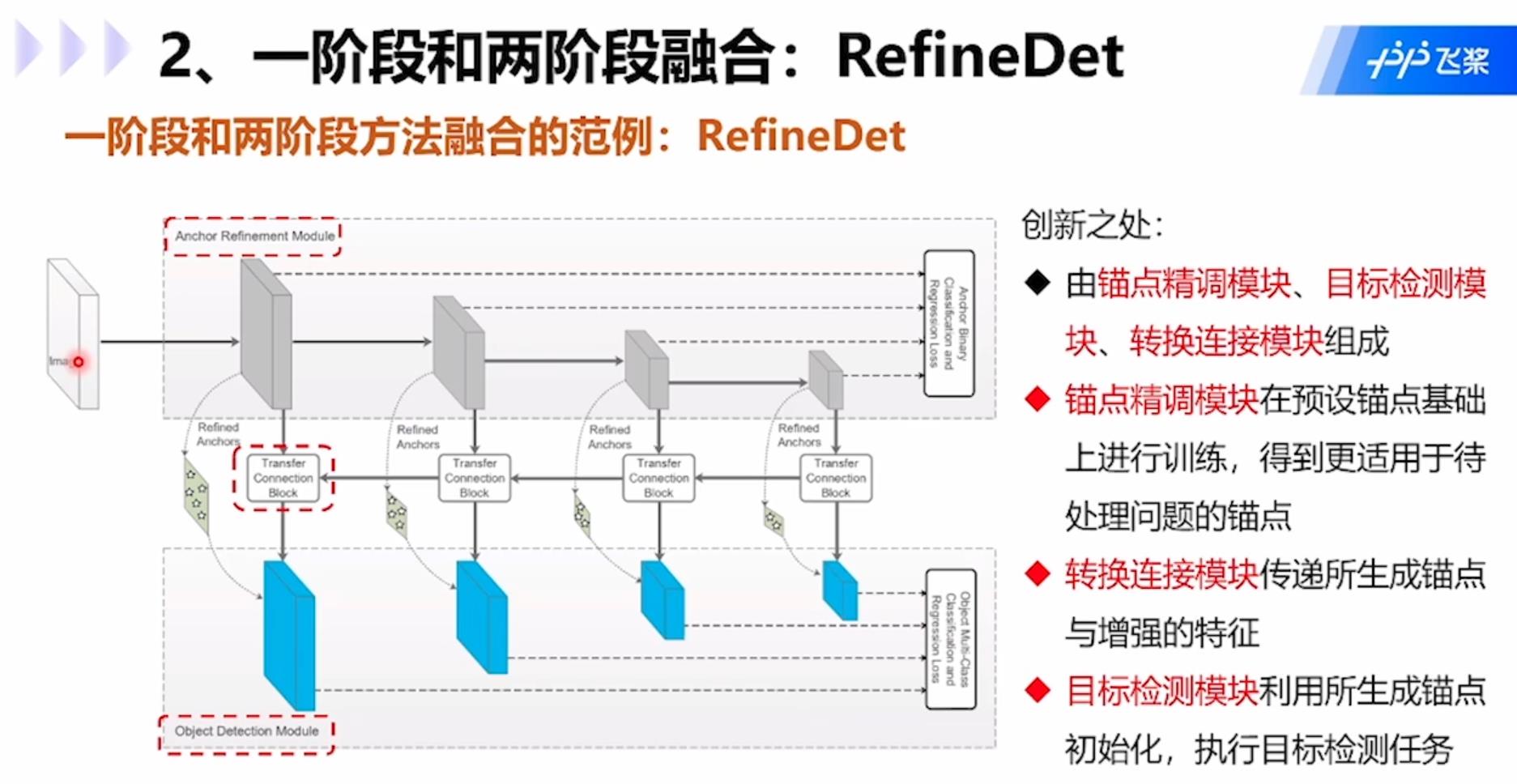
一阶段和两阶段融合的模型RefineDet:创新点在于:1.由锚点精调模块、目标检测模块、转换连接模块组成;2.锚点精调模块在预设锚点基础上进行训练,得到更适用于待处理问题的锚点;3.转换连接模块传递所生成锚点与增强的特征;4.目标检测模块利用所生成锚点初始化,执行目标检测任务。
Anchor方法的问题:无需预先设置锚点。必须针对不同问题定义一组固定宽高比的锚点,错误的设计可能会妨碍检测器,影响速度和精度。为了对目标保持足够高的召回率,需要大量锚点,而大多数锚点对应于与目标无关的候选区域。大量的锚点会导致显著的计算成本,尤其是当方法存在候选框分析阶段涉及重型分类器时。这样就需要用到anchor-free方法了。
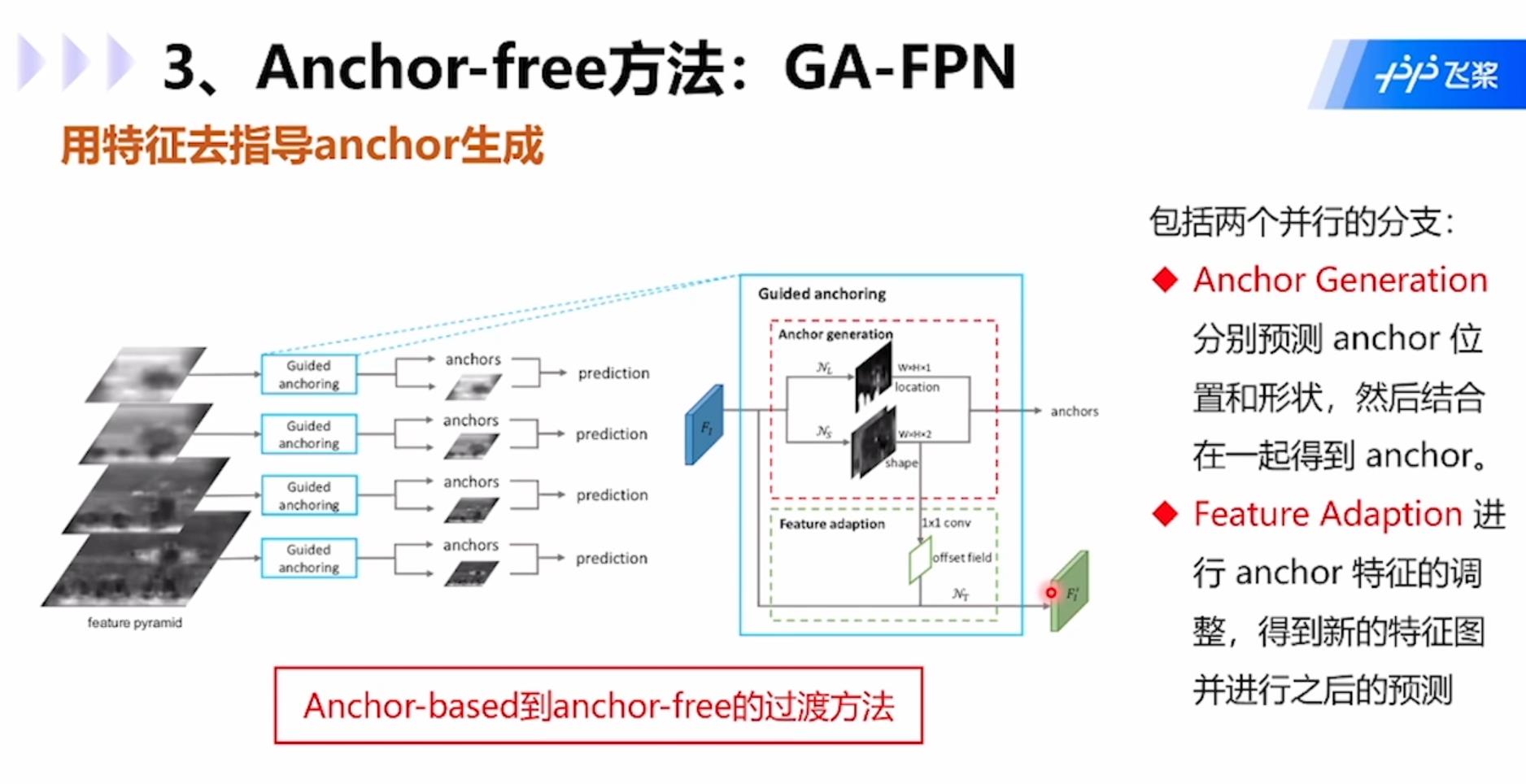
GA-FPN:使用特种功能去指导anchor的生成。模型包括两个并行的分支:1.Anchor Generation:分别预测anchor位置和形状,然后结合在一起得到anchor;2.Feature Adaption:进行anchor特征的调整,得到新的特征图并进行之后的预测。
CornerNet模型:利用成对角点预测的目标检测模型。利用单个卷积网络将框的左上角和右下角两个点组成一对关键点,进而不需要设计在单阶段检测中大量的anchor boxes,同时引入了corner pooling用于提升角点定位效果。这个模型思想新颖,只需要预测两个关键点的类别即可,只需要做点的拟合,不需要再做anchor。

步骤如下:1.采用hourglass network提取特征,该网络通过串联多个hourglass module组成,每个hourglass module都是先通过一系列的降采样操作缩小输入的大小,然后通过上采样恢复到输入图像的大小;2. hourglass network后会有两个输出分支模块,分别表示左上角点预测分支和右下角点预测分支;3.每个分支模块包含一个corner pooling层和3个输出:heatmap、embeddings和offsets,其中heatmap用啦癌输出预测的角点信息,embeddings用来对预测的corner点做group,找到属于同一个目标的左上角和右下角角点,offsets基于输入图像中的点映射到特征图时的量化误差,对预测框做微调。

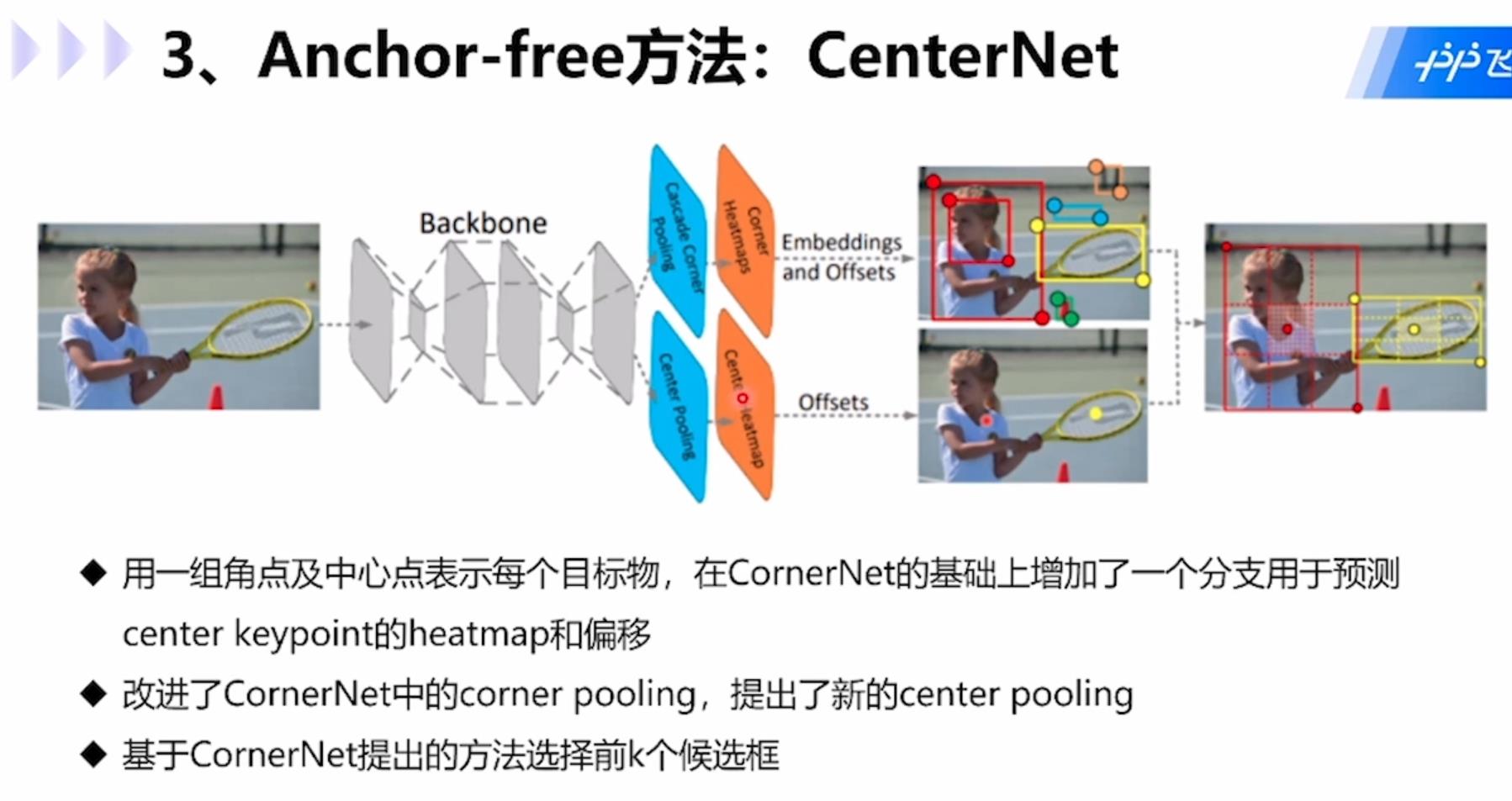
CenterNet模型:用成对角点+中心点预测目标,在CornerNet基础上,CenterNet通过检测每个目标看做是预测一组三个关键点(增加一个关键点来探索proposal中间区域的信息)而不是一对关键点,提供了更多的监督信息,从而提高了准确率和召回率。

具体步骤为:1.用一组角点和中心点表示每个目标,在CornerNet基础上增加一个分支用于预测center keypoint的heatmap和偏移;2.改进了CornerNet中的corner pooling,提出了新的center pooling;3.基于CornerNet提出的方法选择前k个候选框。
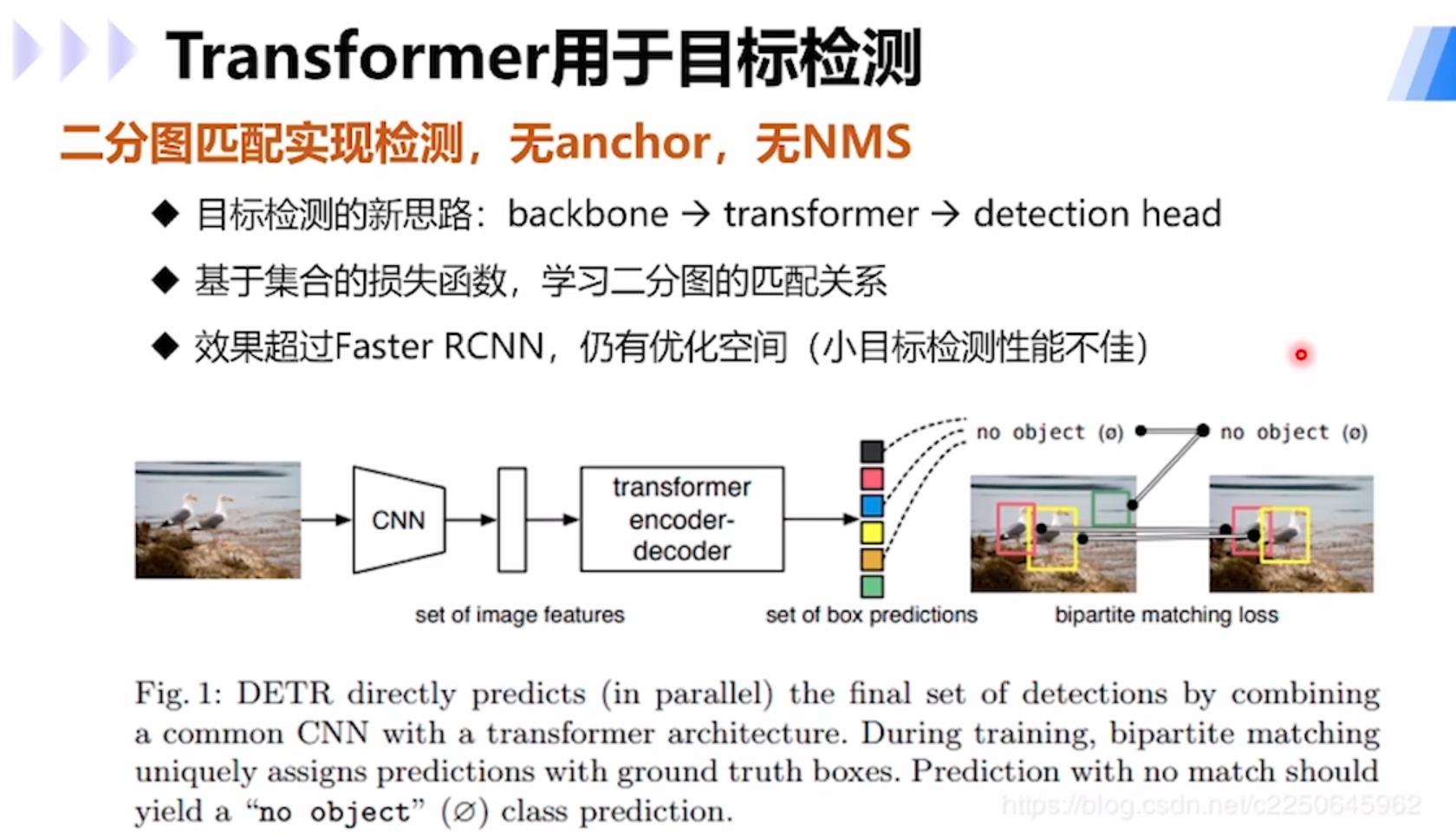
使用transformer进行目标检测的模型DETR:通过二分图匹配实现检测,无anchor,无NMS,提供了目标检测的新思路:backbone→transformer→detection head;基于集合的损失函数,学习二分图的匹配关系;大目标检测效果超过Faster R-CNN,小目标检测上仍有优化空间。
以上是关于百度飞桨顶会论文复现营目标检测综述笔记的主要内容,如果未能解决你的问题,请参考以下文章