: 使用集成学习库
Posted Sonhhxg_柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了: 使用集成学习库相关的知识,希望对你有一定的参考价值。
使用高质量的库可以加快初始开发速度,减少错误,减少重新发明轮子的情况,并降低长期维护成本。鉴于机器学习本质上是实验性的,库可以实现快速且可维护的实验。
本章的目标是
介绍 ML-Ensemble,这是一个基于 Python 的开源库,它包装了 scikit 集成类以提供高级 API。
通过 Dask 扩展 XGBoost,Dask 是一个灵活的 Python 并行计算库。Dask 和 XGBoost 可以协同工作以并行训练梯度提升树。
学习使用 Microsoft LightGBM 进行提升。
介绍 AdaNet,这是一种基于 TensorFlow 的轻量级框架,用于学习神经网络架构,但也用于学习集成模型。
ML-Ensemble
ML-Ensemble也称为 mlens,是一个开源 Python 库,用于构建与 scikit-learn 兼容的集成估计器。
你可以通过 pip 安装它。
pip install mlens构建集成的 API 风格与 Keras 等库非常相似。它提供了一种非常简单直接的方法来构建具有复杂交互的深度集成。
但是,为什么我们需要一个单独的库来进行集成呢?嗯,scikit-learn 不支持直接堆叠。您仍然可以编写它,但是您将不得不自己维护它。ML-Ensemble 提供了一种集成估计器的通用方法,并具有合理的文档。它值得探索,即使您决定不在生产代码中使用它。API 可帮助您非常快速地试验不同的集成。
让我们通过 mlens构建一个堆叠的集成。回想一下,堆叠通过元学习器组合了多个分类或回归估计器。第一层估计器基于完整的训练集进行训练,然后元学习器根据第一层估计器的预测输出进行训练。
让我们先设置数据。我们将使用make_moons 数据集。如果您不知道,make_moons 是一个简单的玩具数据集,可以制作两个半交错的圆圈。
# ---数据设置----
import numpy as np
from sklearn.metrics import accuracy_score
from sklearn.datasets import make_moons
seed = 42
X, y = make_moons(n_samples=10000,noise=0.4, random_state=seed)
# --- 1.初始化 ---
from mlens.ensemble import SuperLearner
ensemble = SuperLearner(scorer=accuracy_score, random_state=seed)
# --- 2.构建第一层 ---
ensemble.add([RandomForestClassifier(random_state=seed), SVC(random_state=seed)])
# --- 3.附上最终的元学习器 ---
ensemble.add_meta(LogisticRegression())
# --- 训练 ---
ensemble.fit(X_train, y_train)
# --- 预测 ---
preds = ensemble.predict(X_test)清单 5-1 通过 mlens 堆叠合奏
现在,让我们看一下代码。集成本质上是一个三步过程。
初始化ensemble,这里就是SuperLearner。
添加中间估计量。在这里,我们添加了两个分类器:RandomForest和SVM。请注意,它们将并行执行。
添加metalearner,这里是LogisticRegression。
调用 fit 方法并进行预测。形象地,可以用图5-1表示。
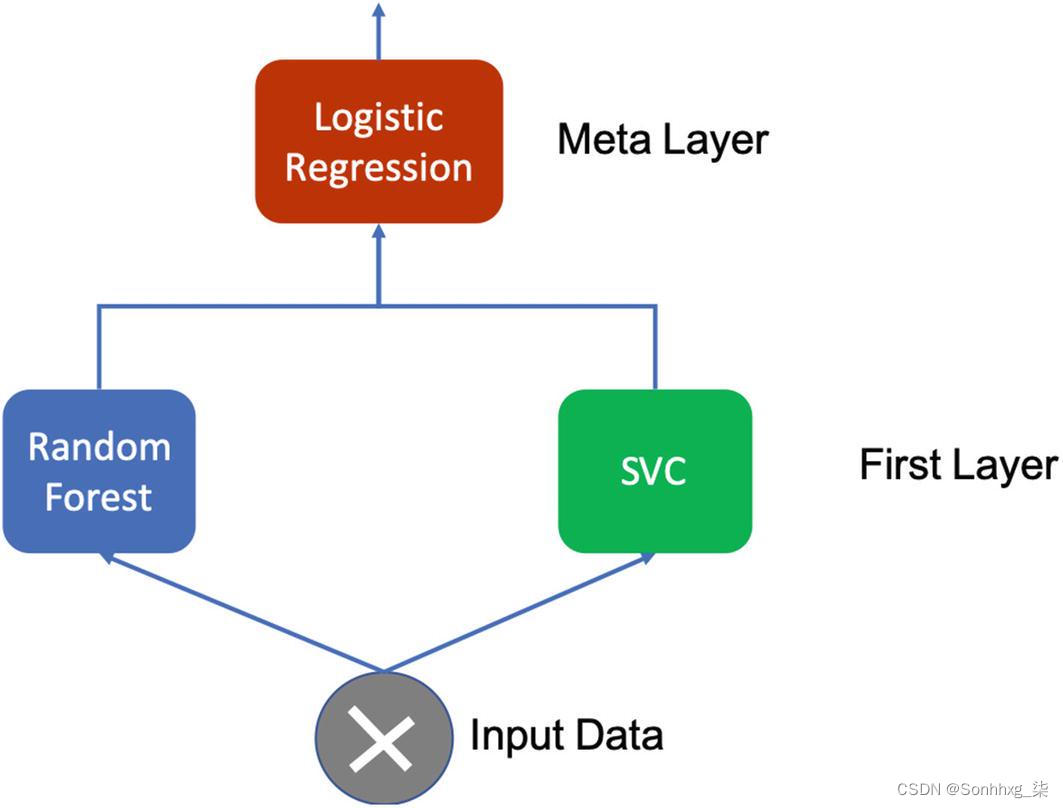
图 5-1 单层堆叠集成
是不是感觉像是在搭建一个神经网络,我们通过堆叠层来构建网络?
要检查层中估计器的性能,请调用数据属性。
print("Fit data:\\n%r" % ensemble.data)Fit data:
score-m score-s ft-m ft-s pt-m pt-s
layer-1 randomforestclassifier 0.84 0.00 0.06 0.00 0.01 0.00
layer-1 svc 0.86 0.00 0.14 0.00 0.06 0.00
第一列 score-m 包含分数。为简洁起见,后缀-m表示平均值,-s表示折叠间的标准差。ft和pt分别代表拟合时间和预测时间。我们鼓励您阅读文档以获取更多信息。请注意,我们在超级学习者初始化期间提供了评分功能。 如果我们可以在第一层添加两个估计器,那么您可以在任何层添加更多估计器也就不足为奇了。
多层合奏
添加多层 同样简单。我们只需要调用add函数来添加一个新层。请注意,层是按顺序执行的。然而,在一个层内,估计器可以并行运行。
ensemble = SuperLearner(scorer=accuracy_score, random_state=seed, verbose=2)
# 构建第1层
ensemble.add([RandomForestClassifier(random_state=seed), LogisticRegression(random_state=seed)])
# 构建第2层
ensemble.add([LogisticRegression(random_state=seed), SVC(random_state=seed)])
# 附上最终的元估计器
ensemble.add_meta(SVC(random_state=seed))图5-2是整体的可视化表示。
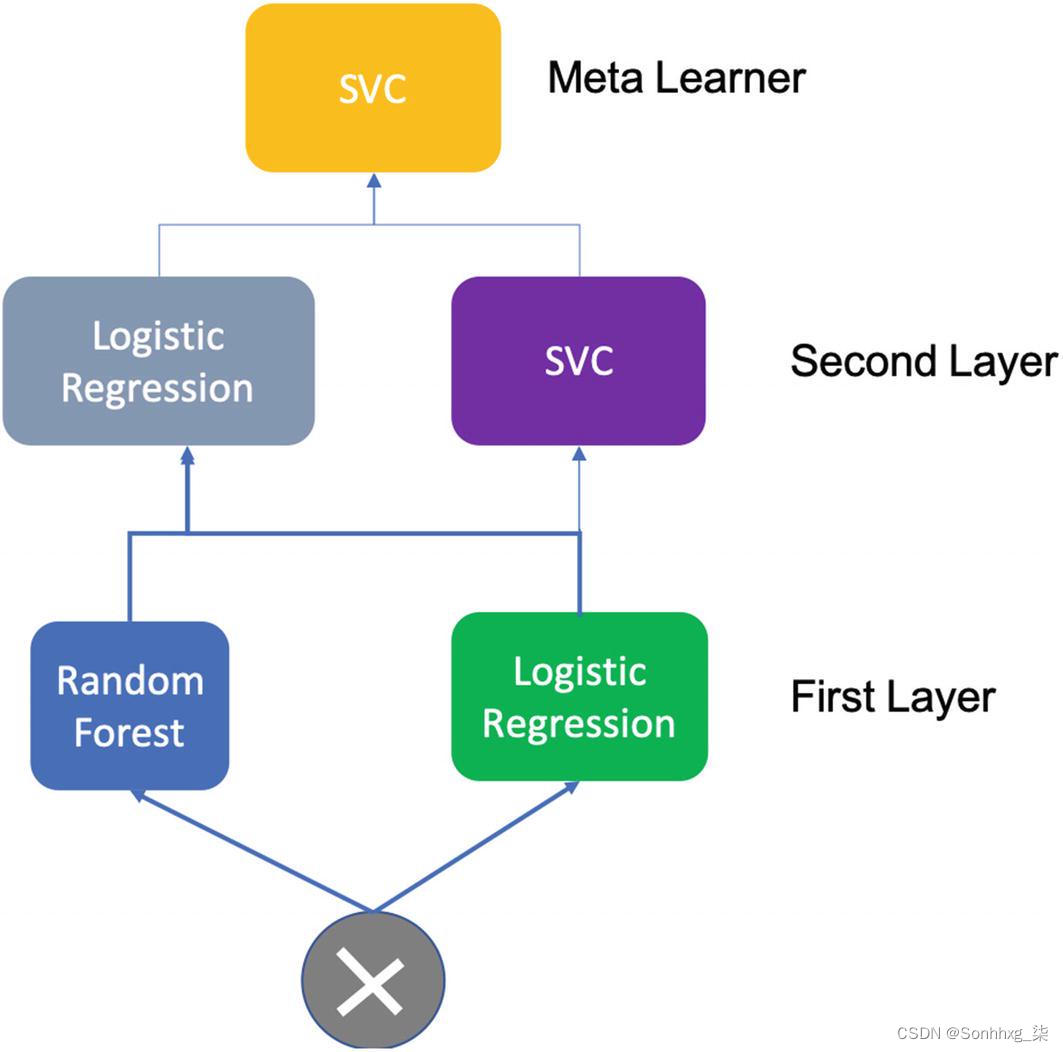
图 5-2 多层堆叠集成
集成模型选择
为了充分利用集成中的学习能力,进行超参数调整非常重要,将基础学习器的参数视为集成的参数。Metalearner是集成的关键部分,但是您将如何选择合适的 Metalearner?如果每次都必须评估整个集成,那么选择合适的元学习器的任务将变得计算量很大。
此问题的一种可能解决方法是将集成的较低层视为预处理管道,然后仅在较高阶层或元学习器上执行模型选择。将预处理管道视为仅评估一次的缓存结果。要为此目的使用整体,请在拟合之前将model_selection参数设置为True。这将修改transform方法的行为方式并确保在测试折叠时调用predict 。
在我们查看模型选择的端到端代码之前,您需要了解更多的库片段。
评分功能
我们需要将评分函数 包装在 mlens make_scorer()函数中。
这实质上是从性能指标或损失函数中得出的评分者。
from mlens.metrics import make_scorer
accuracy_scorer = make_scorer(accuracy_score, greater_is_better=True)greater_is_better参数的 true 值表示准确性,而 False 表示错误/损失。
但是为什么我们需要这样做呢?这是为了确保所有学习者的评分都以相同的方式进行。
make_scorer包装器是 scikit-learn 的sklearn.metrics.make_scorer() 的副本。sklearn make_scorer 是一个工厂函数,它包装了用于 GridSearchCV 和 cross_val_score 的评分函数。它采用一个评分函数,例如accuracy_score 、 mean_squared_error、adjusted_rand_index或average_precision并返回一个对估计器的输出进行评分的可调用函数。为了让您不会在这里迷路,请记住我们的目标是找到合适的金属学习者。现在您知道如何使评分保持一致,让我们讨论一下图书馆如何管理处理管道 。
Evaluator
mlens Evaluator 类允许您跨多个预处理管道并行地对多个模型进行网格搜索。评估器类预装转换器,从而避免在相同数据上重复安装相同的预处理管道。让我们通过代码来更好地理解它。为简洁起见,我们跳过了一些常见且明显的代码。
from mlens.model_selection import Evaluator
from scipy.stats import randint
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
Now we need to name the estimators.
ests = [('gnb', GaussianNB()), ('knn', KNeighborsClassifier())]然后我们准备参数列表。这与您在网格或随机搜索期间所做的没有什么不同。请注意,不包括 GNB,因为它没有任何参数。
pars = 'n_neighbors': randint(2, 20)
params = 'knn': pars我们现在可以通过调用evaluate方法对这些估计量和参数分布进行评估。
evaluator = Evaluator(scorer=accuracy_scorer, cv=10)
evaluator.fit(X, y, ests, params, n_iter=10)您可以通过 Evaluator 的cv_results和summary属性检查结果和摘要。
预处理
mlens预处理 功能可帮助您比较一组预处理管道中的模型。它通过一个充当转换器的类来实现这一点,允许您使用较低层或传入层作为“预处理”步骤,因此您只需要迭代地评估元学习者。让我们看一下代码以更好地理解它。
from sklearn.preprocessing import StandardScaler
preprocess_cases = 'none': [],
'sc': [StandardScaler()]
我们已经指定了要运行的预处理管道字典。字典中的每个条目都是要按顺序应用的转换器列表。
现在是时候查看一个端到端的示例以查看所有的部分了 。
from mlens.model_selection import Evaluator
from mlens.ensemble import SequentialEnsemble #--1
from mlens.metrics import make_scorer
from scipy.stats import uniform, randint
base_learners = [RandomForestClassifier(random_state=seed),
SVC(probability=True)] #--2
proba_transformer = SequentialEnsemble(
model_selection=True, random_state=seed).add(
'blend', base_learners, proba=True) #--3
class_transformer = SequentialEnsemble(
model_selection=True, random_state=seed).add(
'blend', base_learners, proba=False) #--4
preprocessing = 'proba': [('layer-1', proba_transformer)],
'class': [('layer-1', class_transformer)] #--5
meta_learners = [SVC(random_state=seed), ('rf', RandomForestClassifier(random_state=seed))] #--6
params = 'svc': 'C': uniform(0, 10),
'class.rf': 'max_depth': randint(2, 10),
'proba.rf': 'max_depth': randint(2, 10),
'max_features': uniform(0.5, 0.5)
#--7
scorer = make_scorer(accuracy_score) #--8
evaluator = Evaluator(scorer=scorer, random_state=seed, cv=2) #--9
evaluator.fit(X, y, meta_learners, params, preprocessing=preprocessing, n_iter=2)#--10
from pandas import DataFrame
df = DataFrame(evaluator.results) #--11清单 5-2 通过 mlens 处理管道

让我们解压代码 。
导入SequentialEnsemble类 。SequentialEnsemble允许用户构建具有不同层级的集成。图层的类别是混合、子集和堆栈。这三个类是将训练集映射到元学习器使用的预测集的不同方式。
使用RandomForest和SVM作为基础学习器。
设置两个相互竞争的合奏基地作为预处理变压器。这是一个带有 proba 的混合整体基础。请注意,proba表示该层是否应预测类别概率。这里将调用估计器的predict_proba方法。
这是一个没有概率的混合合奏。请注意,model_selection参数设置为True。这会修改transform方法的行为方式并确保在测试折叠时调用预测。
设置预处理映射。在评估候选元学习者之前,这张地图中的每条管道在每次折叠时都安装一次。
设置候选元学习者。这里的估计器将在所有预处理管道上运行。
设置参数映射。请注意,分布在随机森林的情况下有所不同。
包装得分函数。你已经知道为什么了。
实例化评估器。
调用评估器拟合方法 。
这不是必需的,但您可以将评估器结果加载到数据框中,以格式化的方式查看结果。同样,-s和-m后缀分别代表平均值和标准偏差。
概括
让我们快速回顾一下。ML-Ensemble 提供 Keras 风格的 API 构建集成。超级学习者课程有助于构建堆叠集成。mlens 提供了不同类型的堆叠层,例如 stack、blend 和 subset。多次运行整个集成以比较不同的元学习器可能非常昂贵。ML-Ensemble 实现了一个充当转换器的类,允许您将输入层用作“预处理”步骤,因此您只需要迭代地评估元学习器。您可以在http://ml-ensemble.com/info/index.html找到项目文档。
通过 Dask 扩展 XGBoost
如您所知,XGBoost 是梯度提升的优化实现,而Dask是Python 中用于并行计算的灵活库。
您可以将两者结合起来并行训练梯度提升树。
在我们通过 Dask 扩展 XGBoost 之前,您需要了解 Dask。
要了解和欣赏 Dask 的价值,您需要了解Python 科学生态系统。图5-3让您大致了解这么多有用的库和框架的广泛可用性。
图 5-3 Python 的科学生态系统
然而,这些包并不是为了扩展到单台机器之外而设计的。Dask 的开发是为了扩展这些包和周围的生态系统。它与现有的 Python 生态系统一起工作,将其扩展到多核机器和分布式集群。这些库中的大多数都不可扩展。对于计算机内存无法容纳的数据集,您将如何使用 NumPy 或 Pandas?Dask 使NumPy 和 Pandas可以处理分布式数据。分布式NumPy和Pandas的想法是不是很酷很令人兴奋?不过,Dask 并不局限于扩展 NumPy 和 Pandas;可扩展性优势扩展到整个生态系统。
在高层次上,Dask 可以帮助您解决两个问题。
处理大于 RAM 的数据集。(您已经知道 Pandas 和 NumPy 需要内存中的完整数据集。)
跨线程、核心或不同机器分配任务。
最好的部分是,由于 Dask 是基于 Python 的,并且它的 API 与大多数 scikit-learn 库接口相匹配,因此您已经感到宾至如归。
Dask 在两个层面上运作。
在高层次上,Dask 提供了模仿 NumPy、列表和 Pandas 的高级 Array、Bag 和 DataFrame 集合,但可以在不适合主内存的数据集上并行操作。Dask 的高级集合是用于大型数据集的 NumPy 和 Pandas 的替代品。
在底层,Dask 提供了并行执行任务图的动态任务调度器。Dask 的调度程序是在复杂情况下或其他任务调度系统(如 Luigi 或 IPython Parallel)中直接使用线程或多处理库的替代方法。
Dask 的逻辑架构(参见图5-4)可以帮助您更好地理解这些概念。
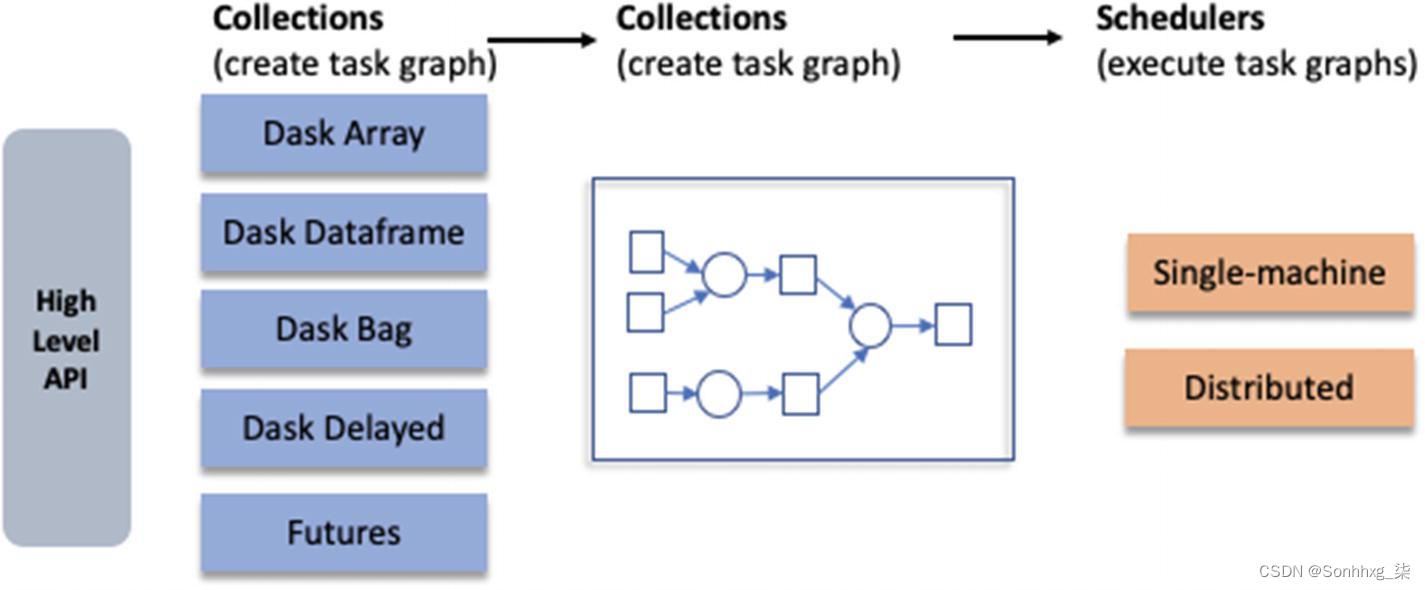
图 5-4 任务架构
现在让我们深入了解 Dask 数组和数据帧。
Dask 数组和数据框
一张图片说一千个单词。Dask 数组的逻辑结构如图5-5所示。
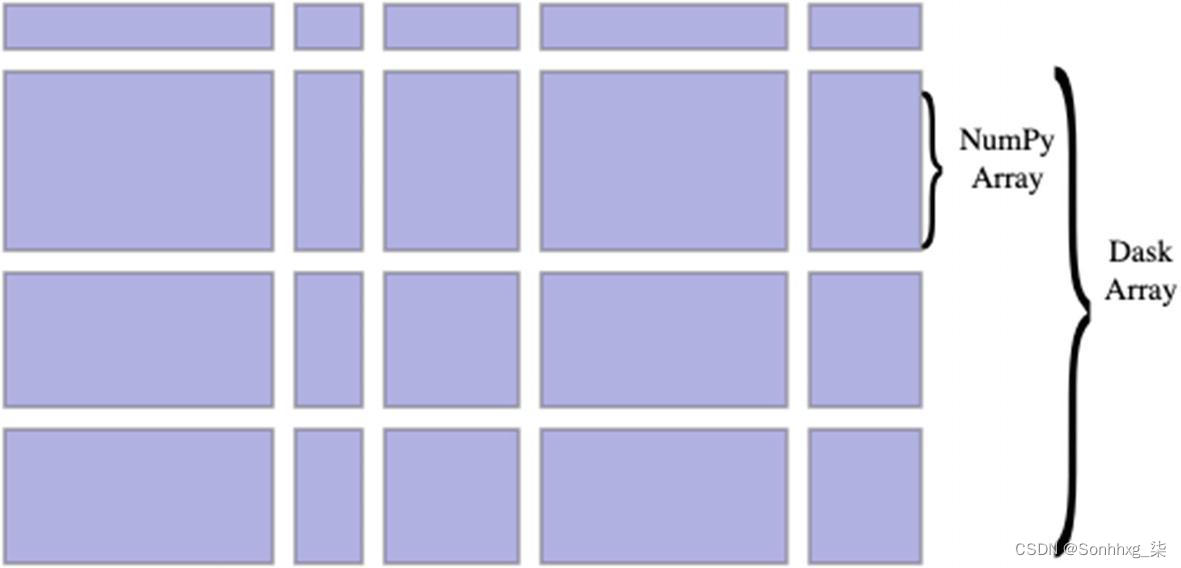
图 5-5 Dask数组的逻辑结构
您可以在图5-5中看到,Dask 数组实质上管理着NumPy 数组的集合 ,尽管它为用户提供了单一的逻辑视图。这张照片可能会引发您的想法,是的,它们是真实的。您可以将处理的各个 NumPy 数组分配给不同的线程、内核或机器。他们住在哪里并不重要。Dask 是一位出色的秘书,负责管理内部的所有协调工作。
同样的图片(参见图5-6)也可以用于数据帧。Dask 数据帧协调许多 Pandas 数据帧,沿索引分区。
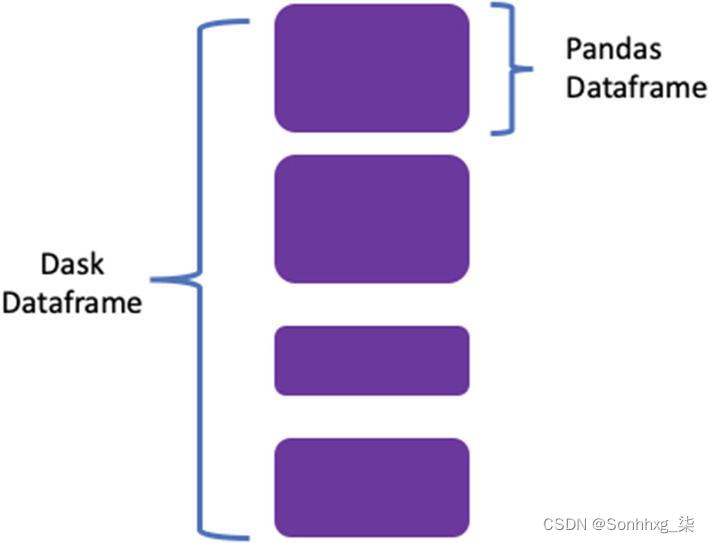
图 5-6 Dask 数据框的逻辑结构
让我们看一下代码,了解如何在 Dask 数据框中读取CSV 。
import dask.dataframe as dd
df = pd.read_csv("hdfs://mycsv.csv", parse_dates =['timestamp'])
Let’s also look at how it would have been done in Pandas.
import pandas as pd
df = dd.read_csv("hdfs://mycsv.csv", parse_dates =['timestamp'])代码在两个库中是相同的,这不是复制/粘贴错误。Dask API 在设计时牢记 Python 风格,以确保学习曲线最小。Python 数据计算生态系统中的几乎所有包都可以在不做太多更改的情况下获得分布式和并行处理的好处。
除了分布式处理,并行处理是 Dask 扩展数据处理任务的另一个特性。让我们看看 Dask 如何使用更简单的dask.delayed接口并行化自定义算法。让我们看一下清单5-3中的代码。
def inc(x):
return x + 1
def double(x):
return x ∗ 2
def add(x, y):
return x + y
data = [1, 2, 3, 4, 5]
output = []
for x in data:
a = inc(x)
b = double(x)
c = add(a, b)
output.append(c)
total = sum(output)清单 5-3用于并行处理的 Dask 延迟接口
虽然代码很简单,但您可以清楚地看到处理可以并行化。inc和double可以并行执行。
Dask延迟函数可以修饰前面的函数,使它们延迟运行。它不是立即执行函数,而是推迟执行,将函数及其参数放入任务图中。现在让我们将自定义函数包装在延迟函数中,如清单5-4所示。
import dask
output = []
for x in data:
a = dask.delayed(inc)(x)
b = dask.delayed(double)(x)
c = dask.delayed(add)(a, b)
output.append(c)
total = dask.delayed(sum)(output)清单 5-4 Dask 惰性执行
请务必注意,尚未发生任何inc、double、 add或sum调用。相反,对象总计是一个延迟结果,其中包含整个计算的任务图。
幸运的是,您可以通过调用total.visualize()方法查看任务图,如图5-7所示。
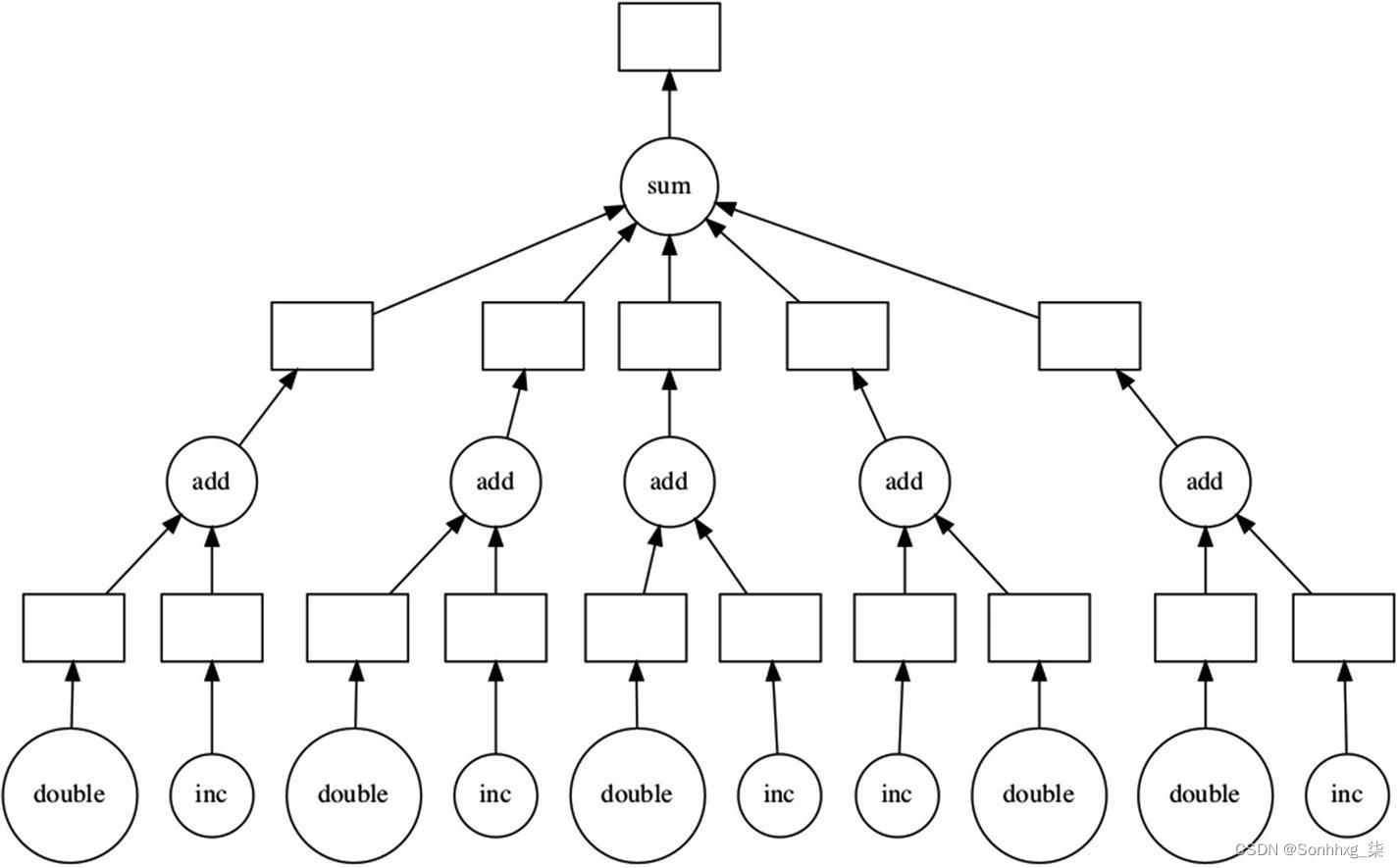
图 5-7 任务图
图中的每个节点都是可以分配给不同线程、池甚至机器的任务。运行操作时执行节点。对于清单5-2中的代码,它是对计算函数的调用。
total.compute()弄清楚这里发生的事情很重要。这不是大型数据集问题,而是计算挑战。当您听到“混乱数据”时,大多数时候,它是大型数据集和自定义数据处理逻辑的组合。Dask 在两个级别上运行:大数据和执行中的并行任务。清单5-5是 Dask 数组任务的图形。
import dask.array as da
x = da.ones((15, 15), chunks=(5, 5))
y = x + x.T
y.visualize()清单 5-5 任务图
在这里,我们正在创建一个由形状 (5,5) 的三个块组成的 Dask 二维数组,然后添加该数组及其转置。图5-8是计算的任务图。
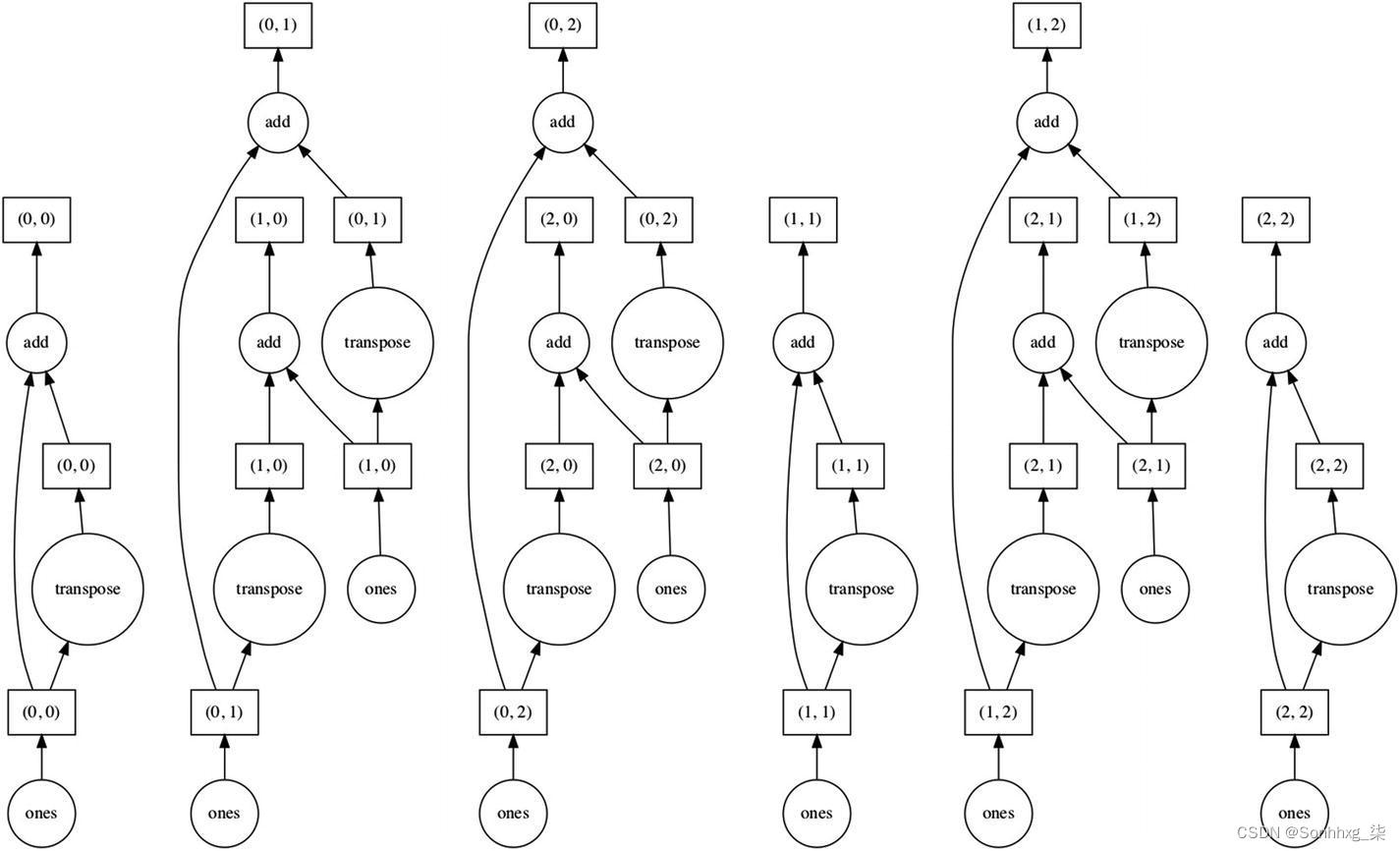
图 5-8 Dask 二维数组任务图
Dask-ML
如果将 Dask 与 scikit-learn 结合使用会得到什么?您将获得可扩展的 ML 算法。
但是 scikit-learn 不是已经并行了吗?是的,但 scikit-learn 仅在带有 Joblib 的单机上提供并行计算。让我们使用LogisticRegression构建一个分类器(参见清单5-6)。我们将使用生成随机n分类问题的make_classification 数据集。
from dask_glm.datasets import make_classification
from dask_ml.linear_model import LogisticRegression
from dask_ml.model_selection import train_test_split
X, y = make_classification()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
lr = LogisticRegression()
lr.fit(X_train, y_train)
lr.predict(X_test)清单 5-6 带 Dask 的单机逻辑回归
发现此代码与标准 scikit-learn 代码没有区别时,请不要感到惊讶。它使用 Joblib,它本身提供基于线程和基于进程的并行性。在 scikit-learn 的正常使用中,Joblib支持n_jobs=参数。从图形上看,该过程如图5-9所示。

图 5-9 使用Joblib在单台机器上进行基于Dask线程和进程的处理
Dask 可以将这种并行性扩展到集群中的许多机器。这适用于中等数据大小,但计算量大,例如随机森林、超参数优化等。在我们查看代码之前,图5-10显示了分布式计算的样子。
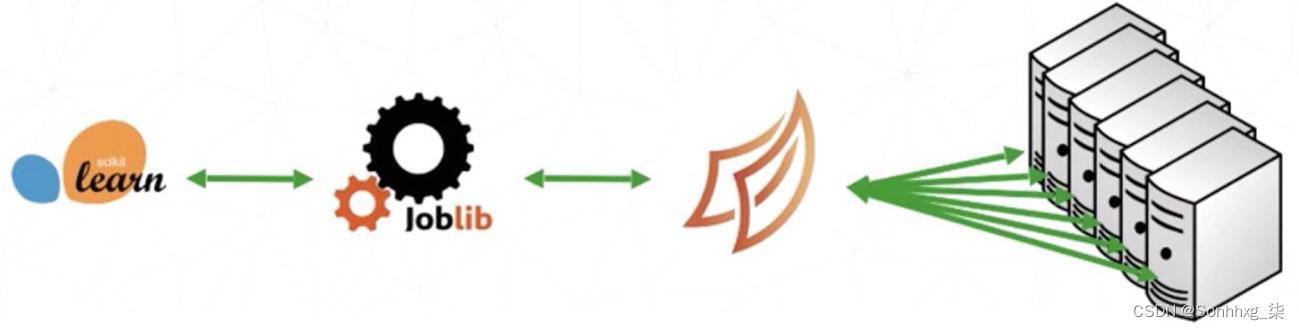
图 5-10 集群环境中的Dask并行执行
在这里,Dask 通过 Joblib 与 scikit-learn 对话,以便使用集群来训练模型。让我们通过清单5-7中的代码看看实际情况。
from dask_ml.model_selection import GridSearchCV
parameters = 'penalty': ['l1', 'l2'], 'C': [0.5, 1, 2]
lr = LogisticRegression()
est = GridSearchCV(lr, param_grid=parameters)
est.fit(X_train,y_train)清单 5-7 GridSearch 和 LogisticRegression 通过 dask
到现在为止没有惊喜。我们正在使用网格搜索来寻找logisticRegression 参数的最佳值:惩罚和系数 C。数据集与我们在清单5-6中使用的数据集相同。现在我们想在集群上切换训练。
from dask_ml.model_selection import GridSearchCV
parameters = 'penalty': ['l1', 'l2'], 'C': [0.5, 1, 2]
lr = LogisticRegression()
est = GridSearchCV(lr, param_grid=parameters)
import joblib #--1
from dask.distributed import Client #--2
client = Client() #--3
with joblib.parallel_backend('dask'): #--4
est.fit(X_train, y_train) #--5清单 5-8 通过 dask 在集群上进行训练
让我们解压代码。请注意,scikit-learn 网格搜索代码没有变化,我们使用与清单5-6中相同的数据。
我们导入Joblib 库。回想一下,Joblib 在本地机器上的不同线程或进程上运行 scikit-sklearn 函数。我们正在导入它以注册新的后端,这里是 Dask。本质上就是把图5-9改成图5-10。
我们从 Dask dask.distributed导入客户端以连接到 Dask 集群。
我们正在初始化客户端以连接到 Dask 集群。但是我们什么时候启动集群的?当客户端在没有参数的情况下初始化时,集群在本地运行。要在本地运行集群,我们需要做的就是不带任何参数初始化客户端。
使用joblib.parallel_backend 上下文,我们指定使用 Dask 后端或集群进行训练。
现在估计器适合集群而不是线程或进程。
集群可以在带有 Docker 或 Kubernetes 的云环境中运行。请查看有关在云计算机上设置集群的文档。
Scaling XGBoost
您在前面的章节中了解了 XGBoost。在这里,您将学习如何使用 Dask 和 XGBoost 并行训练梯度提升树。回想一下,XGBoost 代表 eXtreme Gradient Boosting,顾名思义,它是梯度提升的一种实现。梯度提升方法试图将新的预测器与先前预测器产生的残差相匹配。
dask -xgboost 项目非常小而且非常简单 (200 TLOC)。与具有调度程序和工作程序的 Dask 集群一样,Dask 在运行 Dask 调度程序的同一进程中启动 XGBoost 调度程序,并在每个 Dask 工作程序中启动 XGBoost 工作程序。它们共享相同的物理进程和内存空间。Dask 就是为支持这种情况而构建的,这就是它如此无缝的原因。在训练期间,Dask 工作人员将所有 Pandas 数据帧(它们是 Dask 数据帧的组成部分)提供给本地 XGBoost,并让 XGBoost 执行它的操作。重要的是要注意并记住 Dask 不为 XGBoost 提供动力;它只是设置它,给它数据,并让它在后台完成它的工作。
Dask 和 XGBoost 可以相互共享数据并可以相互监控,因为它们可以存在于同一个 Python 进程中。这与NumPy和Pandas在单个进程中一起运行的方式非常相似。如果您想轻松地使用多个专门的服务并避免大型单体框架,那么与多个系统共享分布式进程可能会非常有益。现在让我们看看如何在代码中将 XGBoost与 Dask 结合使用(参见清单5-9)。
from dask.distributed import Client
client = Client() # --1
# 准备虚拟数据集
from dask_ml.datasets import make_classification
X, y = make_classification(n_samples=100000, n_features=20,
chunks=1000, n_informative=4,
random_state=0) #--2
# 拆分训练和测试
from dask_ml.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15) #--3
#Train Dask-XGBoost
import xgboost
import dask_xgboost
params = 'objective': 'binary:logistic',
'max_depth': 4, 'eta': 0.01, 'subsample': 0.5,
'min_child_weight': 0.5 #--4
bst = dask_xgboost.train(client, params, X_train, y_train, num_boost_round=10) #--5
# 绘制特征重要性
%matplotlib inline
import matplotlib.pyplot as plt
ax = xgboost.plot_importance(bst, height=0.8, max_num_features=9)
ax.grid(False, axis="y")
ax.set_title('Estimated feature importance')
plt.show()
#Results清单 5-9 通过 dask 缩放 XGBoost
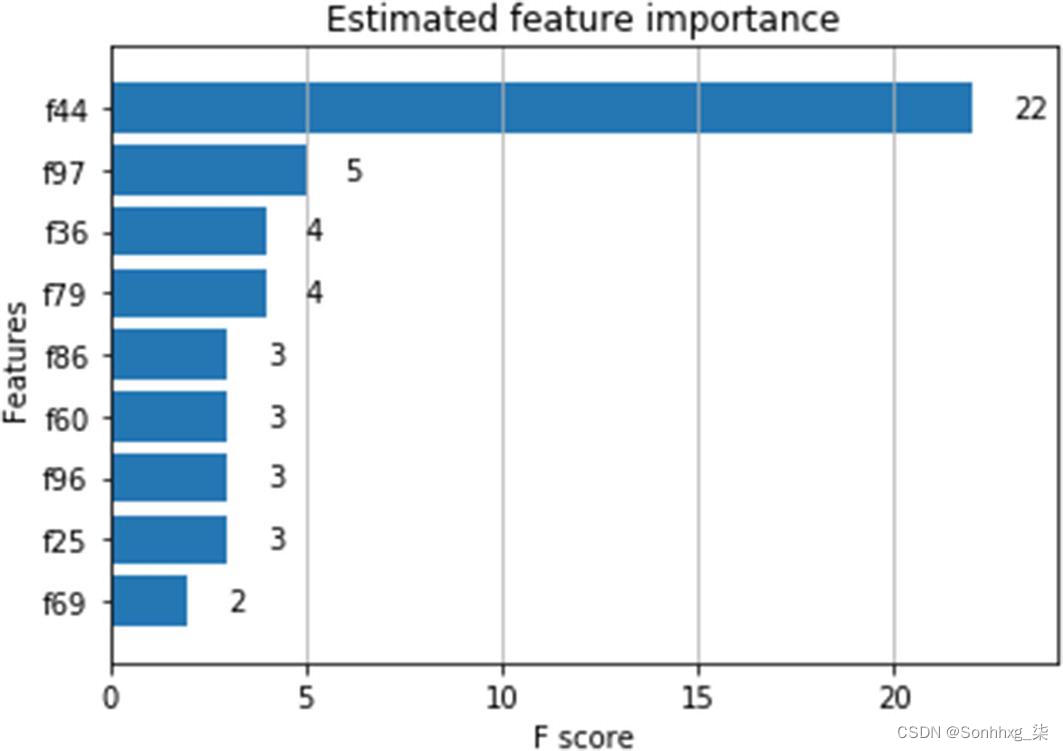
图 5-11特征重要性得分图
让我们在这里解压代码。
初始化客户端。您已经知道 Dask 集群将是本地集群。您可以检查 cluster 的值以查看集群详细信息。
使用 make_classification 函数生成随机玩具数据集。我们以前也用过这个。
将数据集拆分为训练和测试数据,以通过确保我们有一个公平的测试来帮助评估。
指定 XGBoost 参数。
调用 train 方法来拟合模型。dask -xgboost是 XGBoost 的一个小包装器。Dask 设置 XGBoost,提供 XGBoost 数据,并让 XGBoost 使用所有 Dask worker 在后台进行训练。bst对象是一个常规的xgboost.Booster对象,这意味着 XGBoost 的所有方法都可以在这里使用。
使用xgboost.plot_importance方法绘制特征重要性。
Microsoft LightGBM
LightGBM是一个基于决策树算法的快速、分布式、高性能的梯度提升框架。它用于排名、分类和许多其他机器学习任务。
如果你关注 Kaggle 比赛,那么你就会知道提升的力量和受欢迎程度。XGBoost 开创了这一切,成为赢得 Kaggle 比赛的标准算法。然而,对于大数据,XGBoost 的训练时间会急剧增加。LightGBM 解决了可扩展性和速度的问题,显着降低了内存消耗。值得记住的是,XGBoost 和 LightGBM 都是 GBT(梯度提升)的特定实例,它们都实现了相同的底层算法;但是,它们各自引入了各种技巧来提高训练效率或提高性能。它被设计为分布式和高效的,具有以下优点。
更快的训练速度和更高的效率
降低内存使用率
更高的准确性
支持并行和 GPU 学习
能够处理大规模数据
为什么 LightGBM 架构是最好的
XGBoost 和 LightGBM 属于同一梯度提升决策树 (GBDT)系列,具有相似的架构。在这里,我们专注于使 LightGBM 训练准确模型的架构思想。
Growing the Tree
为了拆分和训练每个单独的决策树,可以采用两种策略:level-wise 和 leaf-wise。
level-wise 策略维护一个平衡的树。平衡树 是指每片叶子与根的距离“不超过一定距离”的树。本质上,所有叶节点与根的距离相同。您可以在图5-12中看到,拆分确保树保持平衡。
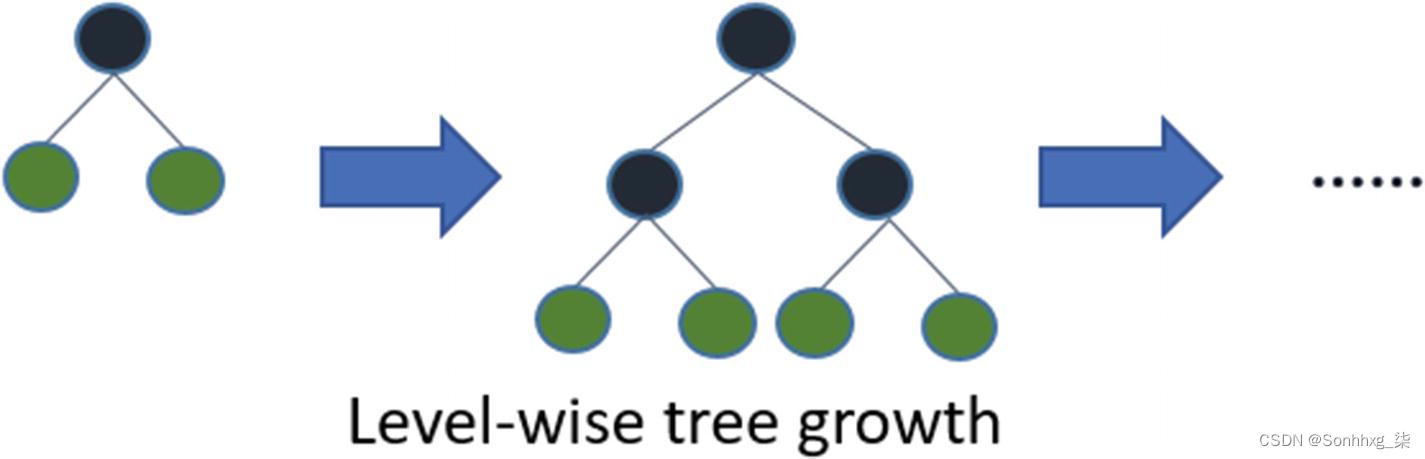
图 5-12 Level-wise tree split strategy (来源:https ://mlexplained.com )
leaf-wise 策略分裂损失最大的叶子(见图5-13)。这使得训练变得灵活,尽管容易出现过度拟合。LightGBM 按叶子生长树木。它选择具有最大 delta loss 的叶子来生长。通过保持叶子的数量固定,leaf-wise 算法往往比 level-wise 算法实现更低的损失。有趣的是,leaf-wise 增长是 LightGBM 的独有特性,但 XGBoost 也实现了这种增长策略。
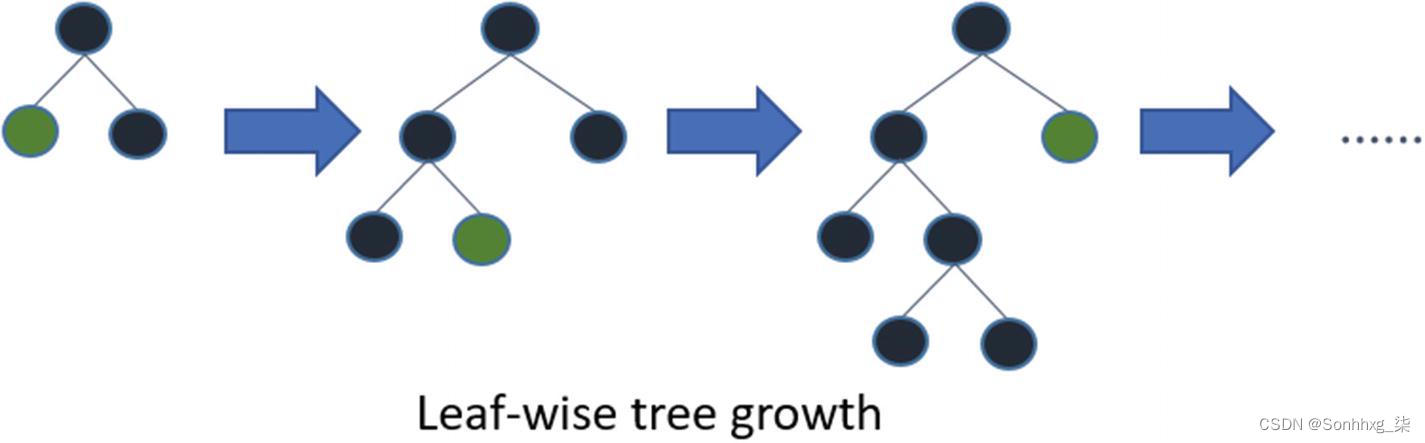
图 5-13 Leaf-wise tree split strategy (来源:https ://mlexplained.com )
寻找最佳拆分
为每个叶子找到最佳分割是训练 GBDT 的关键挑战。
您可以使用蛮力并遍历每个特征来找到最佳分割,但这既不可扩展也不实用。
想一想包含数百万个文档和一百万个单词的词汇量的数据集。GBDT 需要永远在 tf-idf 矩阵上进行训练。唯一可能的方法是以某种方式近似最佳分割。让我们来看看这方面的一些策略。
基于直方图的方法
基于直方图的方法将特征分组到一组箱中,并对箱而不是特征执行拆分。这有助于加快训练速度并降低复杂性,因为可以在构建每棵树之前对特征进行分箱。请注意,必须提前对特征进行排序,此方法才能有效。
处理缺失值
LightGBM 的输入往往是稀疏的,因为它经常用于表格或文本数据。一种可能的选择是忽略缺失值,然后将其分配给分割的任何一侧以减少损失。当zero_as_missing参数 设置为True时,这就是 LightGBM 所做的。它认为所有零值都缺失。
基于梯度的单侧采样
一个普遍的观察是,并非所有特征都在训练中发挥重要作用。这些特征具有较低的梯度。LightGBM 专注于具有高梯度的数据点(即,在最佳分割期间,它倾向于忽略低梯度特征)。然而,这伴随着抽样偏差的固有风险。为了缓解这些问题,LightGBM 应用了两个技巧:使用较小梯度随机采样数据和重要性采样。这实质上增加了具有小梯度的样本的权重,同时计算它们对损失变化的贡献。
独家功能捆绑
独占特征捆绑是一种利用大型数据集稀疏性的技术。考虑到稀疏性,一些特征永远不会一起非零;例如,Python 和政治很少有机会在文档中结合在一起。它们可以“捆绑”成一个单一的功能,而不会丢失任何信息。寻找最佳束是一个 NP-hard 问题,因此,LightGBM 使用一种近似技术来容忍特征束中非零元素之间一定程度的重叠。详细了解该近似值在这里没有多大价值,但如果您有兴趣,可以在www.microsoft.com/en-us/research/wp-content/uploads/2017/11/lightgbm阅读全文.pdf _
现在您对 LightGBM 的工作原理有了更多的了解,理解它的参数应该很容易。
参数
毫不奇怪,参数格式是key1=value1 key2=value2 ....。它可以在配置文件和命令行中设置。通过使用命令行,参数在=前后不能有空格。通过使用配置文件,一行只能包含一个参数。您可以使用# 进行评论。
如果一个参数同时出现在命令行和配置文件中,LightGBM 将使用命令行中的参数。不要在此处列出参数,而是阅读https://lightgbm.readthedocs.io/en/latest/Parameters.html上的文档。
Python 代码中的 LightGBM
让我们使用 LightGBM 构建一个二元分类器。我们将为用例使用 Python 接口(参见清单5-10)。
import lightgbm as lgb # --1
n_features = 20
data = np.random.rand(5000, 20) # --2
label = np.random.randint(2, size=5000)
X_trn, X_val, y_trn, y_val = train_test_split(data, label, test_size=0.30) # --3
feature_name = ['feature_' + str(col) for col in range(n_features)] # --4
train_data = lgb.Dataset(X_trn,label=y_trn,feature_name=feature_name, categorical_feature=[feature_name[-1]] #--5
validation_data = lgb.Dataset(X_val,label=y_val,reference=train_data) # --6
param = 'num_leaves': 31, 'objective': 'binary' # --7
param['metric'] = ['auc', 'binary_logloss'] # --8
num_round = 10
bst = lgb.train(param, train_data, num_round, valid_sets=[validation_data]) #--9
print('Feature importances:', list(bst.feature_importance())) # --10
data = np.random.rand(7, 20)
ypred = bst.predict(data) # --11
# --12
for i in range(7):
if ypred[i]>=.5: # setting threshold to .5
ypred[i]=1
else:
ypred[i]=0清单 5-10 使用 lightGBM 的二进制分类器
让我们解压代码。
导入 LightGBM 库。为简洁起见,省略了其他导入。
LightGBM Python 模块可以从 LibSVM(从零开始)/TSV/CSV/TXT 格式文件、NumPy 二维数组、Pandas 数据框、H2O DataTable 的框架和 SciPy 稀疏矩阵 LightGBM 二进制文件加载数据。数据存储在Dataset对象中。
将数据拆分为训练和验证。
为随机生成的特征分配名称。请注意,我们的数据集中有 20 个特征。
准备训练数据集。我们正在指定特征名称和分类值。LightGBM 可以直接使用分类特征作为输入。它不需要转换为 one-hot 编码,而且比 one-hot 编码快得多(大约 8 倍加速)。在加载到数据集之前将分类值转换为 int 很重要。
准备验证数据集。在 LightGBM 中,验证数据应该与训练数据保持一致。这里的Dataset对象非常节省内存,它只需要保存离散的bin。
LightGBM 可以使用字典来设置Parameters。由于这是一个二元分类问题,我们将目标设置为binary。检查文档以获取目标的其他可能值。
指定多个评估指标
通过调用 train 方法进行训练。您还可以使用 fit 并查看文档以了解详细信息。
使用 feature_importance 方法检查特征重要性。
调用 predict 方法来计算类别概率。
使用阈值将概率转换为类别预测。
还有一个参数调整领域,为此我们建议阅读https://lightgbm.readthedocs.io/en/latest/Parameters-Tuning.html上的文档。有了新的架构知识,理解起来就不难了。
自适应网络
AdaNet是一种基于 TensorFlow 的轻量级框架,可在最少专家干预的情况下自动学习高质量模型。它是一种迭代学习神经网络结构和权重作为子网络集合的算法。
该项目基于 AdaNet 算法,该算法在ICML 2017的“ AdaNet:人工神经网络的自适应结构学习”中提出,用于学习作为子网络集合的神经网络结构。
图片在这里很有帮助(见图5-14)。
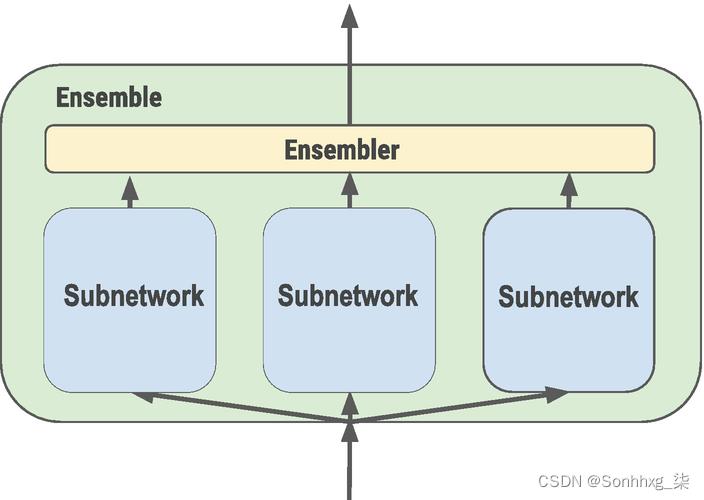
图 5-14 AdaNet子网络集成神经网络
这里子网络的输出被组合生成一个输出。它本质上使用了集成学习的概念,其中最终模型由更简单的模型组成。这使得模型更加复杂,但它也可以提供更好的准确性。
在每次迭代中,该算法都会检查一组候选网络并评估哪个提高了集成性能(或者从技术上讲,产生较小的损失),然后将其添加到集成中。需要注意的是,每个候选网络架构都必须由用户提供。
以上是关于: 使用集成学习库的主要内容,如果未能解决你的问题,请参考以下文章