100天精通Python(数据分析篇)——第72天:Pandas文本数据处理方法之判断类型去除空白字符拆分和连接
Posted 无 羡ღ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了100天精通Python(数据分析篇)——第72天:Pandas文本数据处理方法之判断类型去除空白字符拆分和连接相关的知识,希望对你有一定的参考价值。
文章目录
每篇前言
🏆🏆作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6
- 🔥🔥本文已收录于Python全栈系列专栏:《100天精通Python从入门到就业》
- 📝📝此专栏文章是专门针对Python零基础小白所准备的一套完整教学,从0到100的不断进阶深入的学习,各知识点环环相扣
- 🎉🎉订阅专栏后续可以阅读Python从入门到就业100篇文章;还可私聊进千人Python全栈交流群(手把手教学,问题解答); 进群可领取80GPython全栈教程视频 + 300本计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
本文是上篇的补充,基础不会的小伙伴请看上文:100天精通Python(数据分析篇)——第71天:Pandas文本数据处理方法之str/object类型转换、大小写转换、文本对齐、获取长度、出现次数、编码
一、Python字符串内置方法
1. 判断类型
| 方法 | 说明 |
|---|---|
| string.isspace() | 如果 string 中只包含空格,则返回 True |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True |
| string.isdecimal() | 如果 string 只包含数字则返回 True,全角数字 |
| string.isdigit() | 如果 string 只包含数字则返回 True,全角数字、⑴、\\u00b2 |
| string.isnumeric() | 如果 string 只包含数字则返回 True,全角数字,汉字数字 |
| string.istitle() | 如果 string 是标题化的(每个单词的首字母大写)则返回 True |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True |
2. 去除空白字符
| 方法 | 说明 |
|---|---|
| string.lstrip() | 截掉 string 左边(开始)的空白字符 |
| string.rstrip() | 截掉 string 右边(末尾)的空白字符 |
| string.strip() | 截掉 string 左右两边的空白字符 |
3. 拆分和连接
| 方法 | 说明 |
|---|---|
| string.partition(str) | 把字符串 string 分成一个 3 元素的元组 (str前面, str, str后面) |
| string.rpartition(str) | 类似于 partition() 方法,不过是从右边开始查找 |
| string.split(str=“”, num) | 以 str 为分隔符拆分 string,如果 num 有指定值,则仅分隔 num + 1 个子字符串,str 默认包含 ‘\\r’, ‘\\t’, ‘\\n’ 和空格 |
| string.splitlines() | 按照行(‘\\r’, ‘\\n’, ‘\\r\\n’)分隔,返回一个包含各行作为元素的列表 |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
二、Pandas判断类型
| 方法 | 说明 |
|---|---|
| series_obj.str.isspace() | 如果 string 中只包含空格,则返回 True |
| series_obj.str.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True |
| series_obj.str.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True |
| series_obj.str.isdecimal() | 如果 string 只包含数字则返回 True,全角数字 |
| series_obj.str.isdigit() | 如果 string 只包含数字则返回 True,全角数字、⑴、\\u00b2 |
| series_obj.str.isnumeric() | 如果 string 只包含数字则返回 True,全角数字,汉字数字 |
| series_obj.str.istitle() | 如果 string 是标题化的(每个单词的首字母大写)则返回 True |
| series_obj.str.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True |
| series_obj.str.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True |
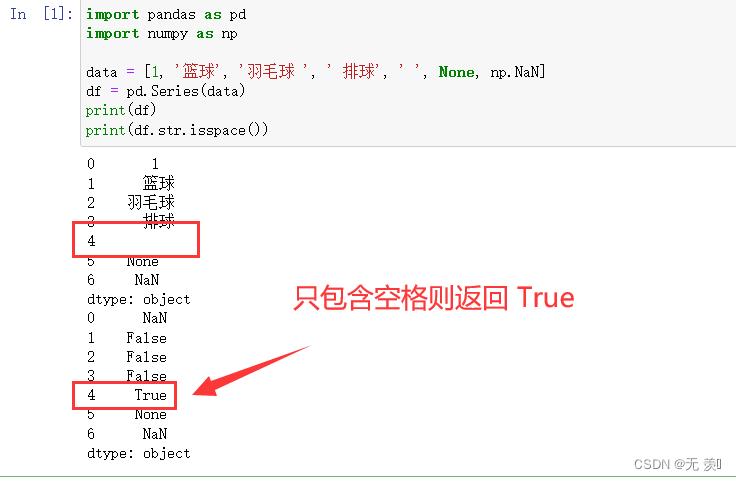
1. str.isspace()
如果 string 中只包含空格,则返回 True
import pandas as pd
import numpy as np
data = [1, '篮球', '羽毛球 ', ' 排球', ' ', None, np.NaN]
df = pd.Series(data)
print(df)
print(df.str.isspace())
运行结果:
2. str.isalnum()
如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True
import pandas as pd
import numpy as np
data = [1, '篮球', '羽毛球 ', ' 排球', ' ', None, np.NaN]
df = pd.Series(data)
print(df)
print(df.str.isalnum())
运行结果:

3. str.isalpha()
如果 string 至少有一个字符并且所有字符都是字母则返回 True
import pandas as pd
import numpy as np
data = [1, 'A', 'Ab', 'AbC', ' ', None, np.NaN]
df = pd.Series(data)
print(df)
print(df.str.isalpha())
运行结果:

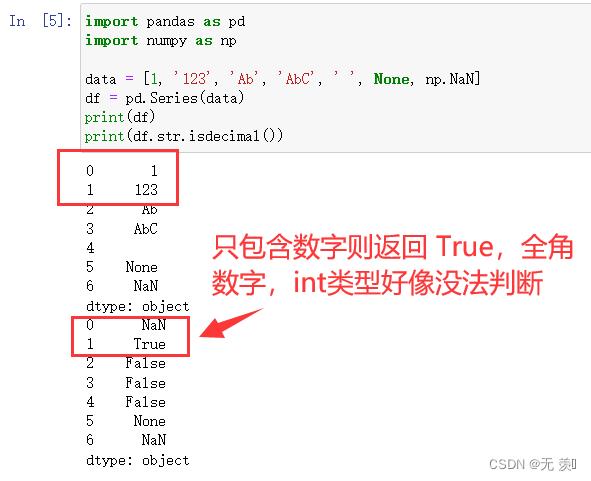
4. str.isdecimal()
如果 string 只包含数字则返回 True,全角数字
import pandas as pd
import numpy as np
data = [1, '123', 'Ab', 'AbC', ' ', None, np.NaN]
df = pd.Series(data)
print(df)
print(df.str.isdecimal())
运行结果:
5. str.isdigit()
如果 string 只包含数字则返回 True,全角数字、⑴、\\u00b2
import pandas as pd
import numpy as np
data = [1, '123', 'Ab', 'AbC', ' ', None, np.NaN]
df = pd.Series(data)
print(df)
print(df.str.isdigit())
运行结果:

6. str.isnumeric()
如果 string 只包含数字则返回 True,全角数字,汉字数字
import pandas as pd
import numpy as np
data = [1, '123', 'Ab', 'AbC', ' ', None, np.NaN]
df = pd.Series(data)
print(df)
print(df.str.isnumeric())

7. str.istitle()
如果 string 是标题化的(每个单词的首字母大写)则返回 True
import pandas as pd
import numpy as np
data = [1, 'A', 'Ab', 'ABC ab', 'Abc Ab', None, np.NaN]
df = pd.Series(data)
print(df)
print(df.str.istitle())
运行结果:

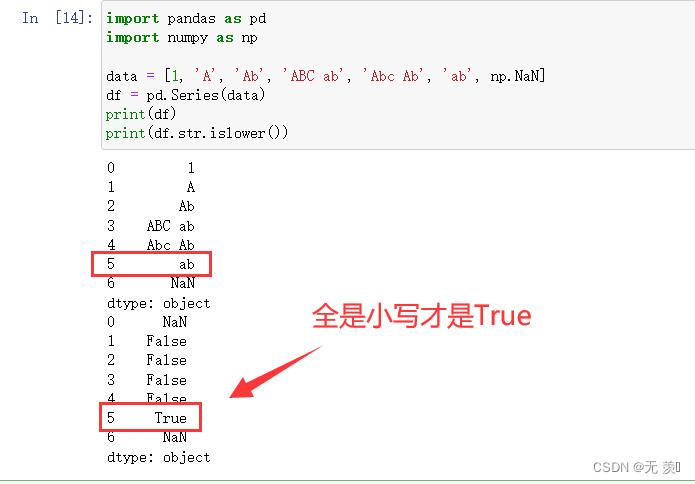
8. str.islower()
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True。简单来说:全是小写才是True
import pandas as pd
import numpy as np
data = [1, 'A', 'Ab', 'ABC ab', 'Abc Ab', 'ab', np.NaN]
df = pd.Series(data)
print(df)
print(df.str.islower())
运行结果:
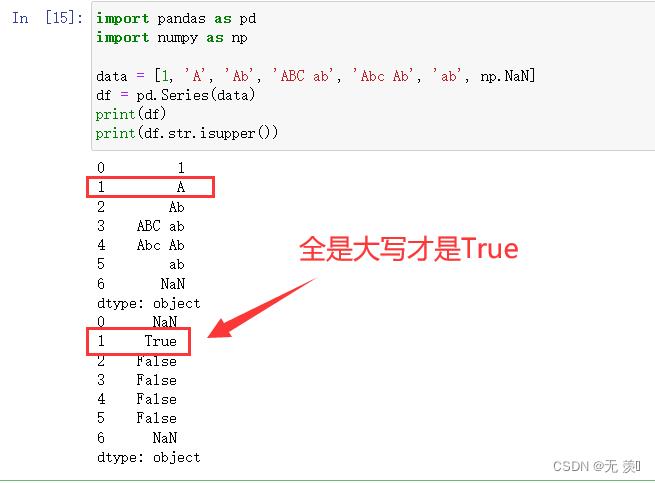
9. str.isupper()
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True。简单来说:全是大写才是True
import pandas as pd
import numpy as np
data = [1, 'A', 'Ab', 'ABC ab', 'Abc Ab', 'ab', np.NaN]
df = pd.Series(data)
print(df)
print(df.str.isupper())
运行结果:
三、Pandas去除空白字符
| 方法 | 说明 |
|---|---|
| series_obj.str.lstrip() | 截掉 string 左边(开始)的空白字符 |
| series_obj.str.rstrip() | 截掉 string 右边(末尾)的空白字符 |
| series_obj.str.strip() | 截掉 string 左右两边的空白字符 |
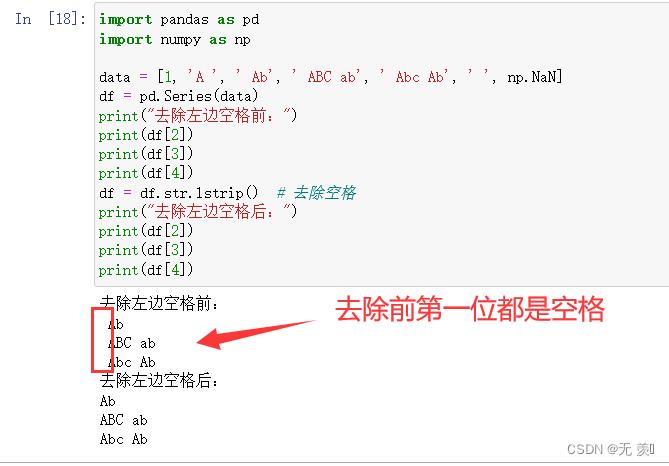
1. str.lstrip()
截掉 string 左边(开始)的空白字符
import pandas as pd
import numpy as np
data = [1, 'A ', ' Ab', ' ABC ab', ' Abc Ab', ' ', np.NaN]
df = pd.Series(data)
print("去除左边空格前:")
print(df[2])
print(df[3])
print(df[4])
df = df.str.lstrip() # 去除空格
print("去除左边空格后:")
print(df[2])
print(df[3])
print(df[4])
运行结果:
2. str.rstrip()
截掉 string 右边(末尾)的空白字符
import pandas as pd
import numpy as np
data = [1, 'A ', 'Ab ', 'ABC ab ', 'Abc Ab ', ' ', np.NaN]
df = pd.Series(data)
print("去除左边空格前:")
print(df[2])
print(df[3])
print(df[4])
df = df.str.rstrip() # 去除空格
print("去除左边空格后:")
print(df[2])
print(df[3])
print(df[4])
运行结果:

3. str.strip()
截掉 string 左右两边的空白字符
import pandas as pd
import numpy as np
data = [1, ' A ', ' Ab ', ' ABC ab ', ' Abc Ab ', ' ', np.NaN]
df = pd.Series(data)
print("去除左边空格前:")
print(df[2])
print(df[3])
print(df[4])
df = df.str.strip() # 去除空格
print("去除左边空格后:")
print(df[2])
print(df[3])
print(df[4])
运行结果:

四. 拆分和连接
| 方法 | 说明 |
|---|---|
| series_obj.str.partition(str) | 把字符串 string 分成一个 3 元素的元组 (str前面, str, str后面) |
| series_obj.str.rpartition(str) | 类似于 partition() 方法,不过是从右边开始查找 |
| series_obj.str.split(str=‘’, num) | 以 str 为分隔符拆分 string,如果 num 有指定值,则仅分隔 num个子字符串,str 默认包含 ‘\\r’, ‘\\t’, ‘\\n’ 和空格 |
| series_obj.str.splitlines() | 按照行(‘\\r’, ‘\\n’, ‘\\r\\n’)分隔,返回一个包含各行作为元素的列表 |
| series_obj.str.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
1. str.partition(str)
把字符串 string 分成一个 3 元素的元组 (str前面, str, str后面)
import pandas as pd
import numpy as np
data = [1, 'a', 'Ab', 'ABC ab', 'Abc Ab', ' ', np.NaN]
df = pd.Series(data)
print(df)
df = df.str.partition()
print(df)
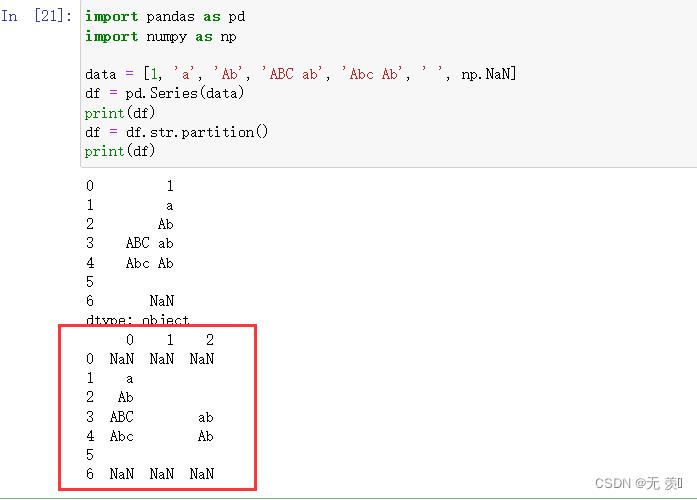
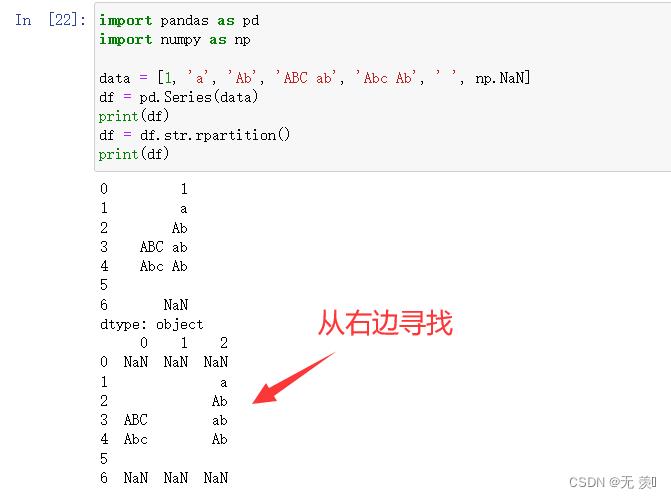
2. str.rpartition(str)
类似于 partition() 方法,不过是从右边开始查找
import pandas as pd
import numpy as np
data = [1, 'a', 'Ab', 'ABC ab', 'Abc Ab', ' ', np.NaN]
df = pd.Series(data)
print(df)
df = df.str.rpartition()
print(df)
3. str.split()
以 str 为分隔符拆分 string,如果 num 有指定值,则仅分隔 num + 1 个子字符串,str 默认包含 ‘\\r’,
‘\\t’, ‘\\n’ 和空格。简单来说:就是以指定字符串分割
1)指定字符串分割
import pandas as pd
import numpy as np
data = [1, 'a;b', 'Ab;', 'ABC;ab;abc', 'Abc;Ab;eee', ' ', np.NaN]
df = pd.Series(data)
print(df)
df = df.str.split(";")
print(df)
运行结果:

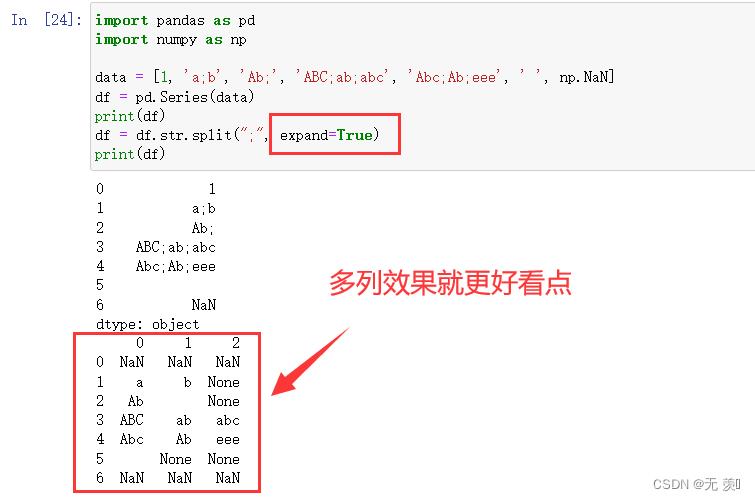
2)分割后转换成多列
设置:
expand=True
import pandas as pd
import numpy as np
data = [1, 'a;b', 'Ab;', 'ABC;ab;abc', 'Abc;Ab;eee', ' ', np.NaN]
df = pd.Series(data)
print(df)
df = df.str.split(";", expand=True)
print(df)
运行结果:
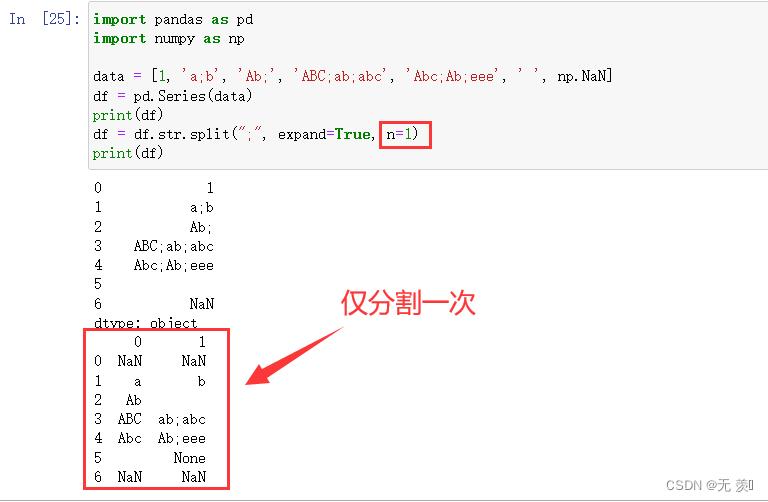
3)设置分割次数
设置:
n=1值
import pandas as pd
import numpy as np
data = [1, 'a;b', 'Ab;', 'ABC;ab;abc', 'Abc;Ab;eee', ' ', np.NaN]
df = pd.Series(data)
print(df)
df = df.str.split(";", expand=True, n=1)
print(df)
运行结果:
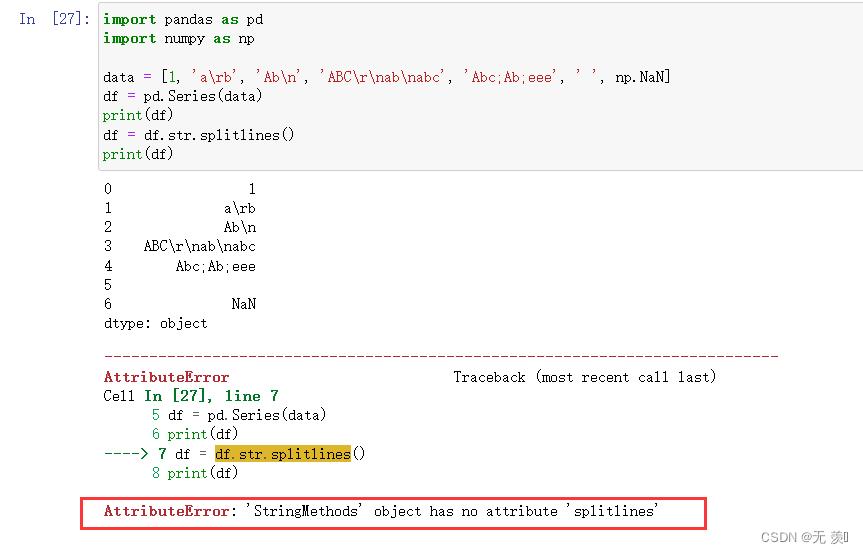
4. str.splitlines()
按照行(‘\\r’, ‘\\n’, ‘\\r\\n’)分隔,返回一个包含各行作为元素的列表。注意:这个方法Pandas无法使用
import pandas as pd
import numpy as np
data = [1, 'a\\rb', 'Ab\\n', 'ABC\\r\\nab\\nabc', 'Abc;Ab;eee', ' ', np.NaN]
df = pd.Series(data)
print(df)
df = df.str.splitlines()
print(df)
运行结果:
5. str.join(seq)
以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串。简单来说:就是往元素之间插入一个指定元素,形成新的字符串
import pandas as pd
import numpy as np
data = [1, 'ab', 'Ab', 'ABC ab abc', 'Abc Ab eee', ' ', np.NaN]
df = pd.Series(data)
print(df)
df = df.str.join('-')
print(df)
运行结果:

书籍介绍
《贝叶斯算法与机器学习》

涵盖了贝叶斯概率、概率估计、贝叶斯分类、随机场、参数估计、机器学习、深度学习、贝叶斯网络、动态贝叶斯网络、贝叶斯深度学习等。本书涉及的应用领域包含机器学习、图像处理、语音识别、语义分析等。本书整体由易到难,逐步深入,内容以算法原理讲解和应用解析为主,每节内容辅以案例进行综合讲解。
如果不想抽奖当当自营购买链接:http://product.dangdang.com/29478966.html
以上是关于100天精通Python(数据分析篇)——第72天:Pandas文本数据处理方法之判断类型去除空白字符拆分和连接的主要内容,如果未能解决你的问题,请参考以下文章