性能分析之两个性能瓶颈分析案例
Posted zuozewei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能分析之两个性能瓶颈分析案例相关的知识,希望对你有一定的参考价值。
最近处理了几个项目中的性能问题,来跟大家唠唠。
这几个问题是非常常见的。
性能瓶颈就有这么个特点,大部分瓶颈分析到最后,都给人有一种猛拍大腿突然醒悟的感觉。但是在分析到具体的原因之前,都是抓耳挠腮,百思不解。
这就是性能瓶颈的魅力所在了。
问题一:单队列网卡导致软中断高
这个问题在专栏也好,公众号文章也好,都不止一次描述过。但是看到过的同学们似乎还是没办法在项目中非常快速地定位出来。
问题的现象我就不描述了,无非就是 TPS 压不上去。
先看一下这个压力的路径。

这是一个清晰的路径。
我们直接来说判断的关键点,这样直面关键数据的描述方式会让有些急性子的人觉得欣慰。
在上图的第二个代理服务器上,看到如下图所示,可以看到有一个SI CPU高达 58.3。
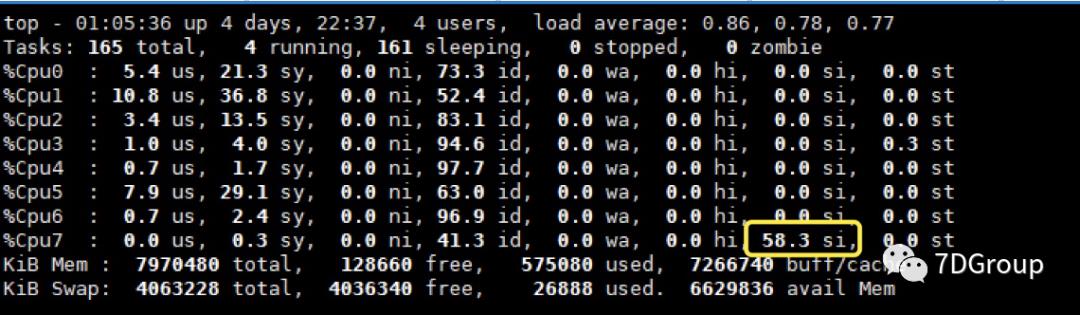
其实看到这里,如果是对我们以前输出的文章都有看过的人来说,应该已经知道是什么原因了。
这个问题的技术判断和解决方案应该说已经是老生常谈了,其实就是在 KVM 参数里面把 Queues 队列打开。
但是在这个项目中却不是简单就可以解决的。因为上面提到这个基础设施是企业3提供的。而影响的却是企业2的业务服务。
于是企业2联系企业3说,要把虚拟机的配置修改一下支持多队列网卡,企业3说不行,要解决问题去虚拟机操作系统层面解决,别想着改KVM这一层。
于是这样明确可优化的点,也就搁浅了。
这样的场景,我想有很多人都碰到过,一个明确的问题,就因为工作之间的不配合、不理解、渎职导致明显的问题推进不了。
不配合多是发生在多个公司合作的场景中,反正你干你的,我干我的,你别给我带来麻烦就行,反正所有事情只要让我做的,我第一句肯定是拒绝,除非等上层大领导压下来才做。
不理解就更普遍了,技术细节上不懂,又不去深究。要修改吧,又担心出现“可能”的新问题而不去做,而这个“可能”又是因为技术上不懂。记得前阵子我处理过一个数据库的问题,一个DBA为了验证IO能力好不好,直接用DD命令顺序写的测试方式得出存储IO能力差的结论。结果几个公司争吵了两个月都没解决得了问题。
从这些事情可以看出来,性能问题不止是技术问题,还会涉及到沟通、协作甚至合同、商务的问题。
问题2:通过网络队列判断瓶颈点
这是一个生产上的问题。架构简单画一下。

架构逻辑是非常简单的。在kafka的队列中一直都有没处理完的消息,这个客户的技术人员一直在对着kafka较劲。但是一直也都没有定位出问题。折腾了好多天,辗转反侧来到了我的手里。
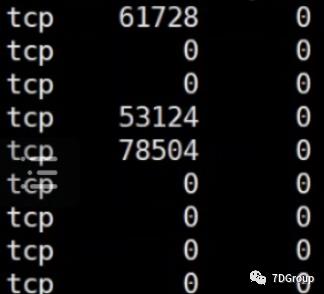
我让他们在每个环节上执行了 netstat 检查了队列之后,看到如下情况:
kafka主机上:

消费服务主机上:
Hbase主机上:
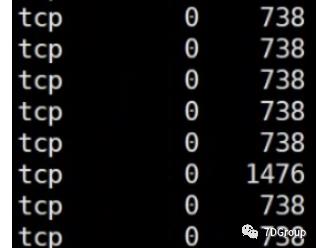
以上图中的数据并不是只看瞬间值,刷新了多次都是这样,只截取了一段展示。
从这些信息上就可以看出来,是消费主机上的问题,因为它的recv_Q是有值的,而其他两边都是Send_Q上有值。
于是登录到这个主机上,一通操作。查CPU-查进程-查线程-打印栈,发现只有三个消费线程。
于是问题得以定位,因为消费服务的能力不够,而导致的两边都阻塞。解决的方法也就比较清晰了,增加消费服务线程。
从这两个问题可以看出来,其实问题的判断往往就在某个关键的计数器上。但是从现象到这个关键的计数器却有着一段不容易走的路,这就是我们一直强调的 RESAR 性能分析七步法的价值所在了。
以上是关于性能分析之两个性能瓶颈分析案例的主要内容,如果未能解决你的问题,请参考以下文章