Transformers学习笔记1. 一些基本概念和编码器字典
Posted 编程圈子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Transformers学习笔记1. 一些基本概念和编码器字典相关的知识,希望对你有一定的参考价值。
Transformers学习笔记1. 一些基本概念和编码器、字典

一、基本概念
1. Hugging Face简介
Hugging Face是一家纽约的聊天机器人初创服务商,他们开源了Transformers库,并在开源社区大火起来,其官网地址: https://huggingface.co/

Hugging Face的主要模型可以大致分为几类:
- 自回归:GPT2, Transfoer-XL, XLNet
- 自编码:BERT, ALBERT, RoBERTa, ELECTRA
- Sequence to Sequence: BART, Pegasus, T5
2. Transformers
(1)简介
Transformers是一个NLP自然语言处理库。
开源地址:
https://github.com/huggingface/transformers
文档地址:
https://huggingface.co/docs/transformers/index
教程地址:
https://huggingface.co/transformers/v3.0.2/quicktour.html
安装Transforms可以使用pip:
pip install transformers
(1)预定义模型
Transformers默认框架为PyTorch,也支持TensorFlow,内置了以下神经网络:
- T5 model
- DistilBERT model
- ALBERT model
- CamemBERT model
- XLM-RoBERTa model
- Longformer model
- RoBERTa model
- Reformer model
- Bert model
- OpenAI GPT model
- OpenAI GPT-2 model
- Transformer-XL model
- XLNet model
- XLM model
- CTRL model
- Flaubert model
- ELECTRA model
每种模型至少一个预训练模型,在下面这个网址可以找到预训练模型:
https://huggingface.co/models
示例:bert-base-chinese 模型说明界面:
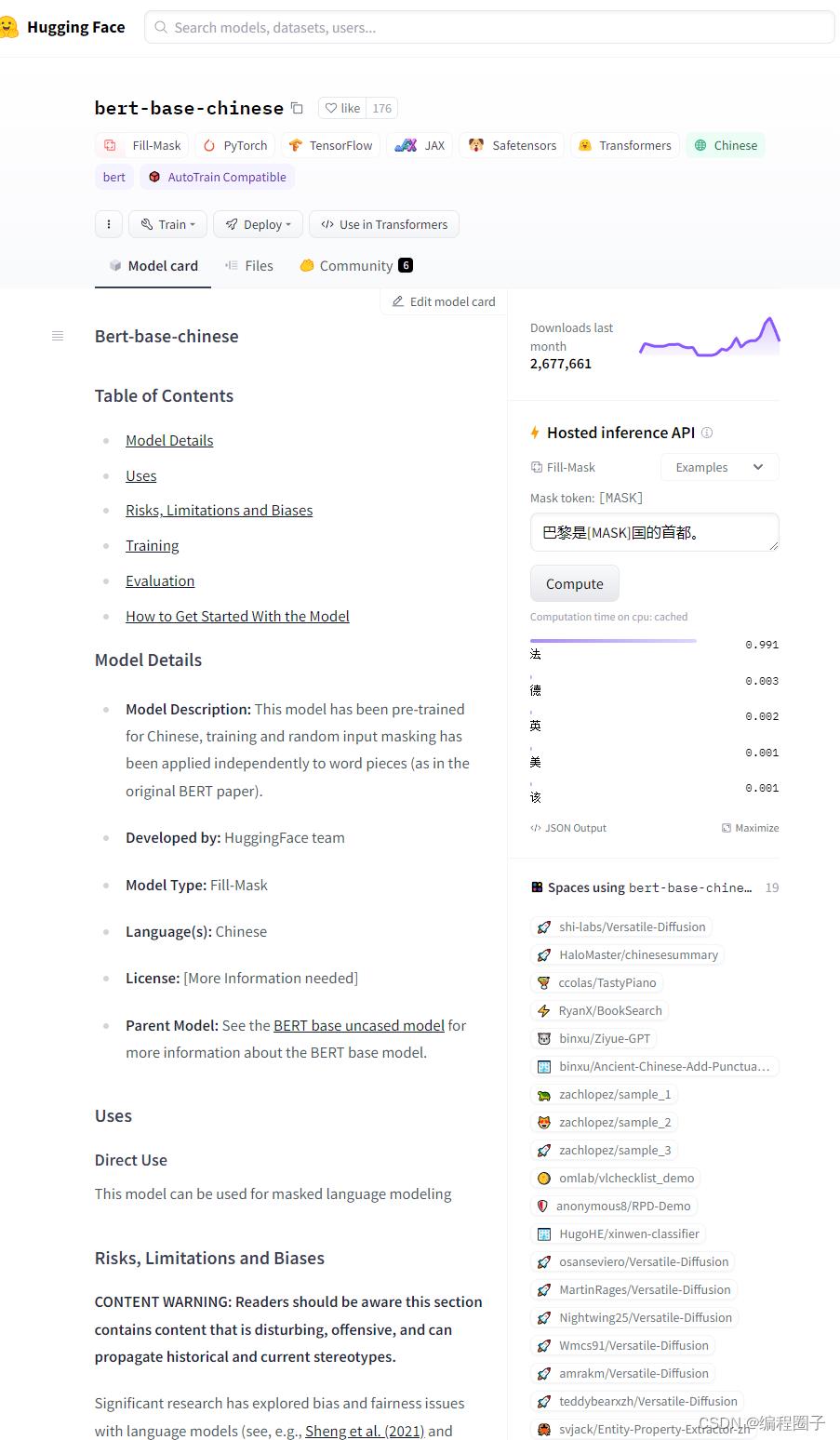
每种模型会围绕三种类型的类构建:
- 模型类 model
- 配置类 configuration
- 编码解码等 tokenizer 类
这些类实例化后,有两种方法在本地保存:
- from_pretrained():
- save_pretrained()
(2)使用方法
使用Transformers有三种方法:
- 使用pipeline
- 指定预训练模型
- 使用AutoModels 加载预训练模型
本文主要介绍pipeline。
3. Datasets
Hugging Face的数据集。
pip install datasets
加载数据集示例:
from datasets import load_dataset
datasets = load_dataset("madao33/new-title-chinese")
print(datasets)
查看有哪些公开数据集
方法1: 使用datasets包的list_datasets方法
from datasets import list_datasets
list_datasets()[:10]
# 打印值:
['acronym_identification', 'ade_corpus_v2', 'adversarial_qa', 'aeslc', 'afrikaans_ner_corpus', 'ag_news', 'ai2_arc', 'air_dialogue', 'ajgt_twitter_ar', 'allegro_reviews']
方法2:到网站查看
https://huggingface.co/datasets
二、一些编码器知识
1. BPE算法
全称是byte pair encoder,字节对编码。可以理解为一种压缩算法,把出现频繁最高的字符对用新的字符替换,反复迭代,这样可以减少语料库的数量。
2. WordPiece算法
与BPE算法类似,但在合并时会引入概率计算,选择可以最大化训练数据可能性的组合 ,从而进一步优化合并结果。
3. SentencePiece
SentencePiece是一个无监督的文本标记器和去标记器,主要用于基于神经网络的文本生成系统,它是一个谷歌开发的开源工具。开源地址:
https://github.com/google/sentencepiece
4. tokenizer
tokenizer称为编码器或分词器。自然语言处理中,首先要把句子分词转化为唯一编码。
spaCy和Moses是两个较流行的基于规则的tokenizer。
(1)spaCy
在其官网: https://spacy.io/usage/spacy-101
可以直接在线运行一个demo。
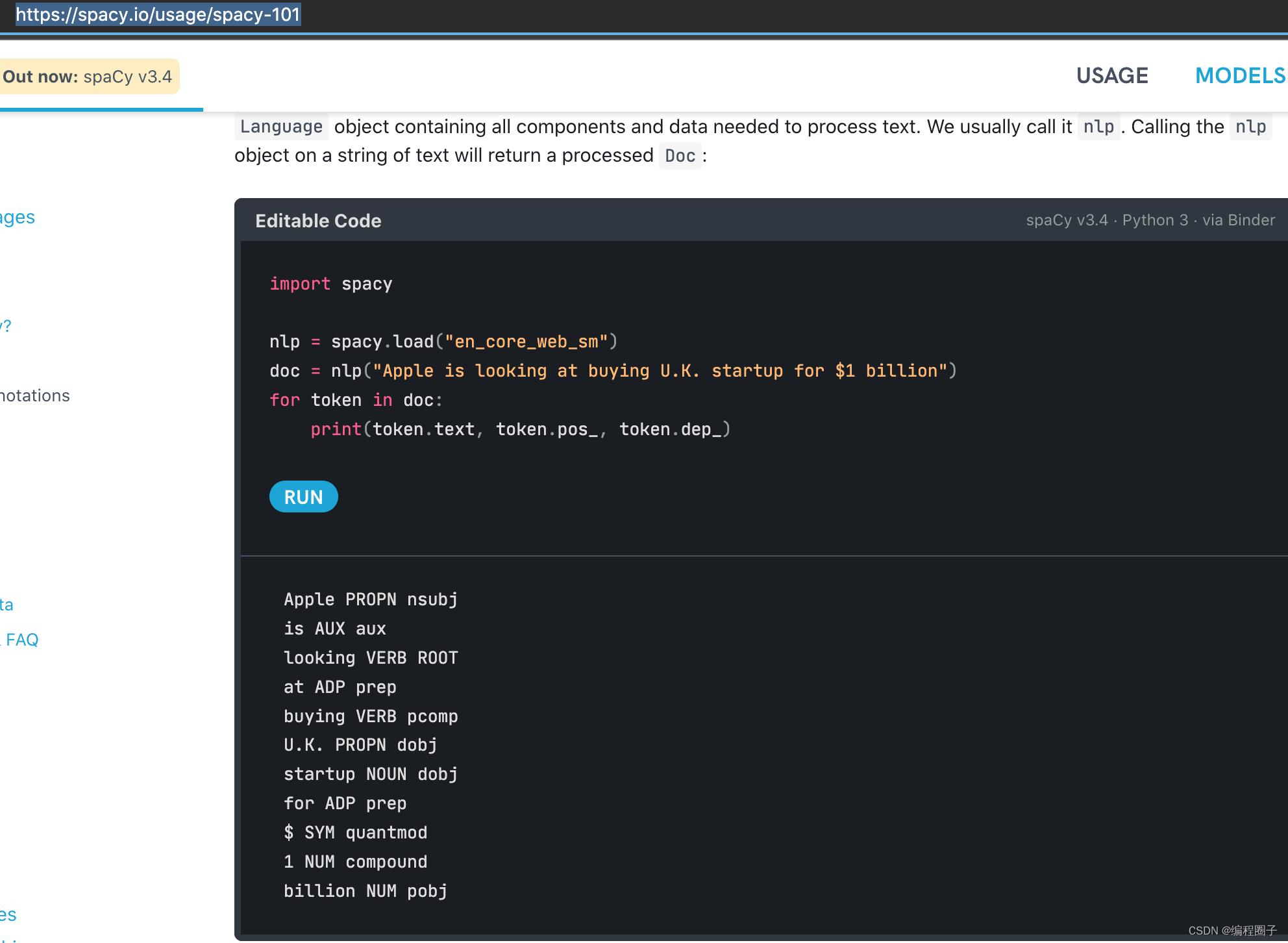
示例中对句子:
Apple is looking at buying U.K. startup for $1 billion进行分析,并输出单词的属性。其中pos_可以大致理解为单词是形容词、副词、动词之类属性, dep_更复杂一些,后面有时间再详细讲解。
Apple PROPN nsubj
is AUX aux
looking VERB ROOT
at ADP prep
buying VERB pcomp
U.K. PROPN dobj
startup NOUN dobj
for ADP prep
$ SYM quantmod
1 NUM compound
billion NUM pobj
(2)Moses
官网:http://www2.statmt.org/moses/
Moses 是一个统计机器翻译系统。
2. transformers编码规则
transformers 模型对语句采用了词级切分和字符级切分的混合,称为子词(subword)切分。该算法依赖这样一种原则 :
- 常用词不应该被拆分
- 非常用词应被切分为更有意义的词。
子词切分是在模型维护的词汇量、保持单词语义方面的一种折衷。
3. 使用tokenizer编解码
(1)使用encode编码函数
from transformers import BertTokenizer
# 定义模型、语料
tokenizer = BertTokenizer.from_pretrained(
# 预加载模型
pretrained_model_name_or_path='bert-base-chinese',
cache_dir=None,
force_download=False
)
sents = [
'今天是星期一。',
'今天天气很好',
'今天电脑运行有点故障',
'电脑硬盘好像坏了,读不出数据。'
]
print(tokenizer)
# 打印结果
PreTrainedTokenizer(name_or_path='bert-base-chinese', vocab_size=21128, model_max_len=512, is_fast=False, padding_side='right', truncation_side='right', special_tokens='unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]')
out = tokenizer.encode(
# 输入的语料
text=sents[0],
# 可以输入两条语料
text_pair=sents[1],
# 句子长度大于下面的max_length时,是否截断
truncation=True,
# 长度不到max_length时,是不是补pad
padding='max_length',
add_special_tokens=True,
# 最大长度
max_length=30,
# 返回的数据类型不指定,默认为list
return_tensors=None
)
print(out)
# 打印的结果
[101, 791, 1921, 3221, 3215, 3309, 671, 511, 102, 791, 1921, 1921, 3698, 2523, 1962, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
decodeTxt = tokenizer.decode(out)
print(decodeTxt)
# 打印的结果
[CLS] 今 天 是 星 期 一 。 [SEP] 今 天 天 气 很 好 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
Tokenizer对中文的处理比较简单,每个汉字都作为一个词。
(2)使用增强编码函数
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
pretrained_model_name_or_path='bert-base-chinese',
cache_dir=None,
force_download=False
)
sents = [
'今天是星期一。',
'今天天气很好',
'今天电脑运行有点故障',
'电脑硬盘好像坏了,读不出数据。'
]
print(tokenizer, sents)
out = tokenizer.encode_plus(
text=sents[0],
text_pair=sents[1],
truncation=True,
padding='max_length',
add_special_tokens=True,
max_length=30,
# 返回类型,可以是tf(tensorflow),pt(pytorch),np(numpy),默认返回list
return_tensors=None,
# 是否返回token_type_ids,结果第一个句子和特殊符号的位置是0,第二个句子的位置是1
return_token_type_ids=True,
# 是否返回attention_mask,pad的位置是0,其它位置是1
return_attention_mask=True,
# 是否返回special_tokens_mask,特殊符号的位置是1,其它位置是0
return_special_tokens_mask=True,
# 返回 length 标识的长度
return_length=True
)
for k, v in out.items():
print(k, ':', v)
tokenizer.decode(out['input_ids'])
# 输出结果:
PreTrainedTokenizer(name_or_path='bert-base-chinese', vocab_size=21128, model_max_len=512, is_fast=False, padding_side='right', truncation_side='right', special_tokens='unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]') ['今天是星期一。', '今天天气很好', '今天电脑运行有点故障', '电脑硬盘好像坏了,读不出数据。']
# 和简单编码结果一样
input_ids : [101, 791, 1921, 3221, 3215, 3309, 671, 511, 102, 791, 1921, 1921, 3698, 2523, 1962, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# 第2个句子的位置是1
token_type_ids : [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# 特殊符号位置是1
special_tokens_mask : [1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
# pad位置是0,其它是1
attention_mask : [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# 句子的长度
length : 30
(3)批量编码、解码句子
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
pretrained_model_name_or_path='bert-base-chinese',
cache_dir=None,
force_download=False
)
sents = [
'今天是星期一。',
'今天天气很好',
'今天电脑运行有点故障',
'电脑硬盘好像坏了,读不出数据。'
]
print(tokenizer, sents)
out = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=[sents[0], sents[1]],
truncation=True,
padding='max_length',
add_special_tokens=True,
max_length=30,
# 返回类型,可以是tf(tensorflow),pt(pytorch),np(numpy),默认返回list
return_tensors=None,
# 是否返回token_type_ids,结果第一个句子和特殊符号的位置是0,第二个句子的位置是1
return_token_type_ids=True,
# 是否返回attention_mask,pad的位置是0,其它位置是1
return_attention_mask=True,
# 是否返回special_tokens_mask,特殊符号的位置是1,其它位置是0
return_special_tokens_mask=True,
# 返回 length 标识的长度
return_length=True
)
for k, v in out.items():
print(k, ':', v)
print(tokenizer.batch_decode(out['input_ids']))
输出结果:
PreTrainedTokenizer(name_or_path='bert-base-chinese', vocab_size=21128, model_max_len=512, is_fast=False, padding_side='right', truncation_side='right', special_tokens='unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]') ['今天是星期一。', '今天天气很好', '今天电脑运行有点故障', '电脑硬盘好像坏了,读不出数据。']
input_ids : [[101, 791, 1921, 3221, 3215, 3309, 671, 511, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 791, 1921, 1921, 3698, 2523, 1962, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
token_type_ids : [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
special_tokens_mask : [[1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
length : [9, 8]
attention_mask : [[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
['[CLS] 今 天 是 星 期 一 。 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]', '[CLS] 今 天 天 气 很 好 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]']
4. 字典操作
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
pretrained_model_name_or_path='bert-base-chinese',
cache_dir=None,
force_download=False
)
sents = [
'今天是星期一。',
'今天天气很好',
'今天电脑运行有点故障',
'电脑硬盘好像坏了,读不出数据。'
]
print(tokenizer, sents)
# 定义字典
dict = tokenizer.get_vocab()
print(type(dict), len(dict), '天气' in dict)
# 添加新词
tokenizer.add_tokens(new_tokens=['今天', '天气', '星期一'])
dict = tokenizer.get_vocab()
print(type(dict), len(dict), '天气' in dict)
# 添加新符号
tokenizer.add_special_tokens('eos_token':'[EOS]')
dict = tokenizer.get_vocab()
print(type(dict), len(dict), '天气' in dict)
out = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=[(sents[0], sents[1])],
truncation=True,
padding='max_length',
add_special_tokens=True,
max_length=30,
# 返回类型,可以是tf(tensorflow),pt(pytorch),np(numpy),默认返回list
return_tensors=None,
# 是否返回token_type_ids,结果第一个句子和特殊符号的位置是0,第二个句子的位置是1
return_token_type_ids=True,
# 是否返回attention_mask,pad的位置是0,其它位置是1
return_attention_mask=True,
# 是否返回special_tokens_mask,特殊符号的位置是1,其它位置是0
return_special_tokens_mask=True,
# 返回 length 标识的长度
return_length=True
)
for k, v in out.items():
print(k, ':', v)
print(tokenizer.batch_decode(out['input_ids']))
输出结果:
PreTrainedTokenizer(name_or_path='bert-base-chinese', vocab_size=21128, model_max_len=512, is_fast=False, padding_side='right', truncation_side='right', special_tokens='unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'以上是关于Transformers学习笔记1. 一些基本概念和编码器字典的主要内容,如果未能解决你的问题,请参考以下文章
Transformers学习笔记3. HuggingFace管道函数Pipeline
Transformers学习笔记3. HuggingFace管道函数Pipeline
Transformers学习笔记2. HuggingFace数据集Datasets