重新设计 TCP 协议
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重新设计 TCP 协议相关的知识,希望对你有一定的参考价值。
看一段关于 TCP 协议的历史讨论,源自:The design philosophy of the DARPA internet protocols

读这段文字时,你可能觉得这不是在谈 TCP,而是在创造一个新协议,但事实上这就是 TCP 在被创造过程中真实的纠结。
现在来看,TCP 就是 RFC793 所描述的一个固定格式且简单的协议,它最终是把端到端逻辑和传输做到一起了,但一开始并不是这样。一开始 IP 并没有从 TCP 分离,IP 的功能被 TCP 承载,TCP/IP 作为一个协议来理解,一切明了。
端到端的 TCP 体现在保序和流控,而传输则交给了 IP 数据报,与传输相关的拥塞控制应由 IP 数据报负责,与保序和流控无关。
剥离了 IP 后的 TCP 即 byte-based stream,而负责传输的 IP 则为 packet-base datagram,1986 年后引入的 TCP 拥塞控制基于 byte-based stream 进行修正,注定会带来各种难题以及针对这些难题的各种非正式 trick,典型的问题即,TCP 分不清楚原始报文的 ACK 和重传报文的 ACK,因此会存在伪重传,针对伪重传引入了 Eifel 算法以及复杂的 dsack,undo 等机制,同时 RTT 测量也因此存在歧义。
但这些真实必要吗?
回到最初的设计阶段,如果重新设计 TCP 协议,一开始就考虑内置拥塞控制,穿越回转的 TCP 又会是什么样子?或者说,现在我们知道了 TCP 协议的各种问题之后,重新设计一个新的协议,它会是什么样子?
首先说下 UDP。
说到 UDP 的意义,很多人认为它不检测丢包,不重传,适合实时传输,比 TCP 快,诸如此类,但事实上没有任何应用偏好丢包,所谓不 care 丢包只是程度问题而非是非。UDP 的意义在于它是一个真正的分组交换网的传输抽象,UDP 本身就是数据报分组。
换句话说,网络上适合传输 UDP 数据报,而不适合传输 TCP 数据流。这是一个后见之明。当 TCP/IP 被标准化时,分离后的 TCP 已经在那里了:

以现在的眼光看,TCP 确实不适合直接在 IP 之上进行传输,以分层后的 TCP/IP 来看,TCP 需要一个传输抽象,即它应该被封装在 UDP 数据报里进行传输:
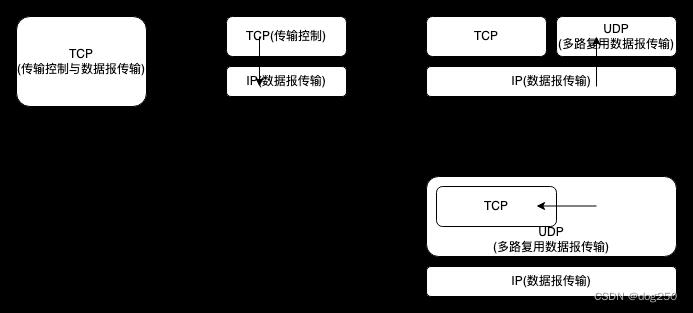
拥塞控制本应该引入到 IP,而不是 TCP,基于 IP 数据报做拥塞控制要比基于 TCP 流做拥塞控制容易得多。
我们现在设计拥塞控制算法时,常常提到 TCP 友好性,意思是某种传输协议对 TCP 的侵占,比如 UDP 就是 TCP 不友好的协议,UDP 流量很容易榨干带宽资源,因为它没有内置拥塞控制。让我们仔细揣摩这个现实,到底问题出在哪?凭什么 UDP 没有内置拥塞控制而 TCP 却必须要进行拥塞控制?
问题在于,拥塞控制本来就应该不区分传输层协议,它本就应该部署在 IP 层,作用于每一个 IP 数据报,而不是 TCP 数据流。如果对 IP 数据报一视同仁,那么无论 TCP 还是 UDP 便被纳入同一个系统中,难题也就不再是难题。
将 TCP 字节流封装到 UDP 数据报,则 TCP 仅剩下端到端保序和流控等传输控制逻辑,这是高尚的。
打个比方,当你需要运输一批大宗货物或零担货物,用什么容器,用多大规格容器来装这些货物是不需要货主操心的,货主甚至从头到尾对此一无所知,但无论运输什么货物,都需要使用集装箱,运输公司只需要提供集装箱,而货主则需要注明轻拿轻放,哪头朝上,并且支付保费即可,如果一些无所谓损毁遗失的货物,便不需要支付保费。同样的道理在 TCP/IP 依然适用。
传输层仅提供 UDP 集装箱,TCP 提供字节序列号并叮嘱 UDP/IP 一旦丢失序列号,必须重传。剩下的传输工作,交给 UDP 即可。
QUIC 就是这样一个 TCP/UDP/IP 协议,但它太重了,QUIC 是一个集大成的大协议(MPTCP 也是),但这个大协议是可以通过组合模式组装起来的。
我来试个简单的做法,将传输逻辑从 TCP 中分离出来:
- TCP 保序和流控使用 byte-based stream 在端到端实现,按照 byte stream 组织字节。
- TCP 传输使用 packet-based datagram 实现,交给 UDP,按照 packet seq 进行传输和确认。
看一下具体的设计。
struct packet
struct udphdr udp_hd;
struct tcp_payload
struct attribute
uint trans_seq;
uint64 timestamps;
attr;
// 以下字段用来组织数据结构,不参与传输
struct list_head list; // 索引该 packet 的发送顺序
struct rbtree rb; // 基于 ACK attributes 查找 packet
;
将传输过程作为报文的属性 “粘贴在箱子上”,箱子和货物分离,箱子上只粘贴和传输相关的信息,对内部 TCP 报文透明,同一个 packet,无论第一次传输还是重传,均会被贴上不同的传输属性,同时组织进发送端数据结构以便被索引。
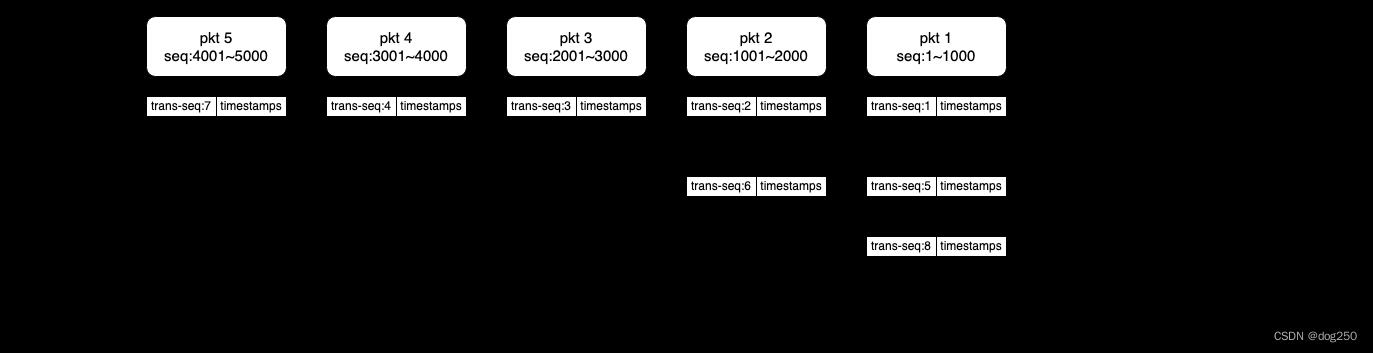
以下是一个传输传输示意图:
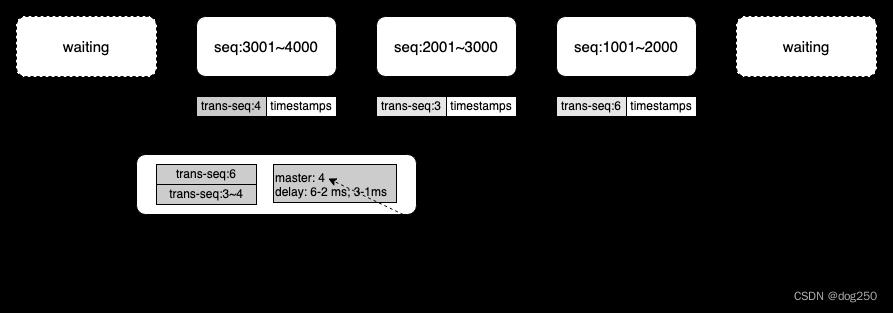
对于接收端,以 UDP 数据报作为接收单位,按照其 payload 组织保序,并且根据 packet 而不是 byte stream 生成 ACK。注意,新协议确认 packet,而不是确认 stream:
发送端收到 ACK 后的反应也因此变得简单:
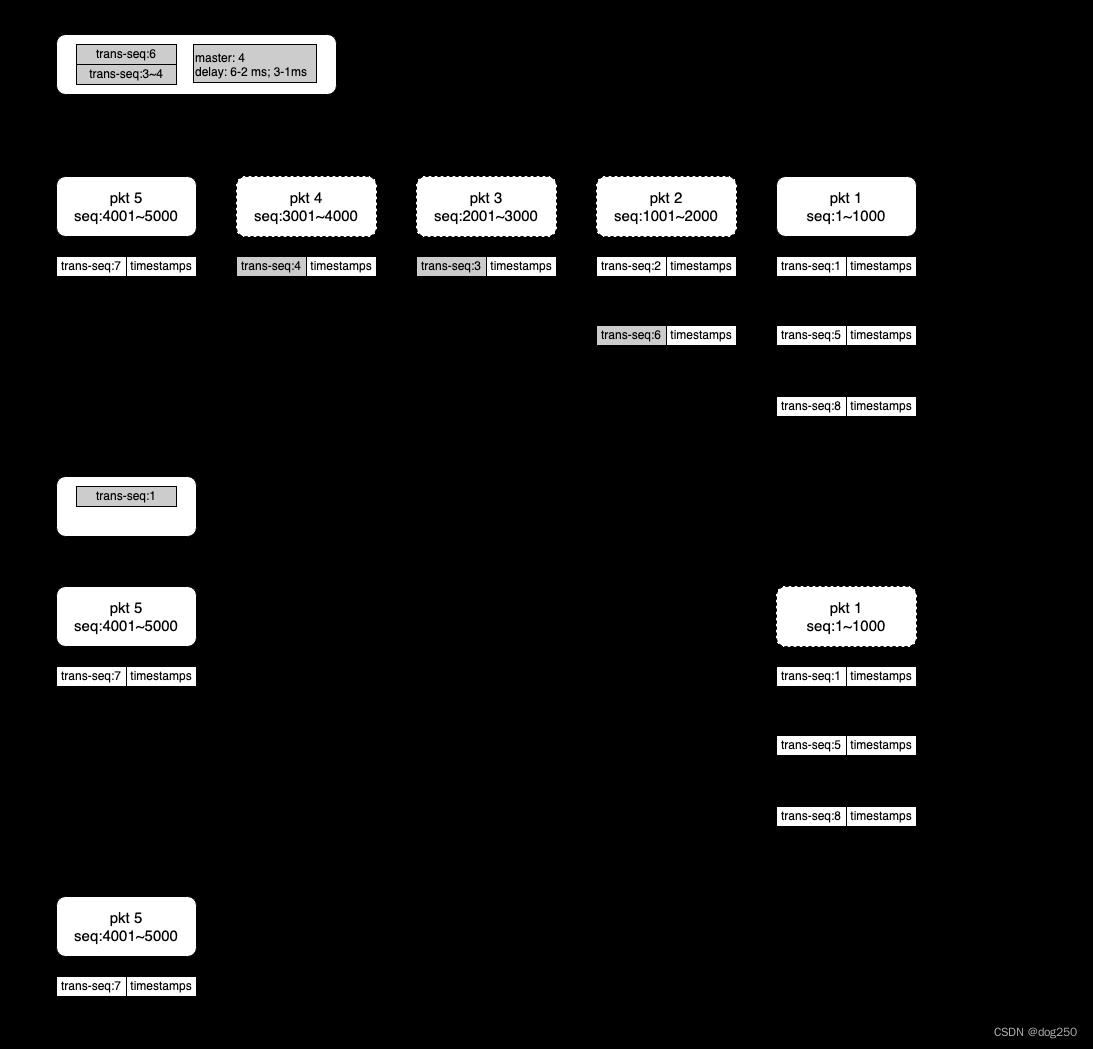
最初的 TCP 基于 byte stream 而不是 packet 进行传输确认(见文初的引图),其中一个理由是可以合并重传,但在新协议中,由于设计基础发生了根本改变,基于 packet 进行传输确认也很容易进行合并重传:
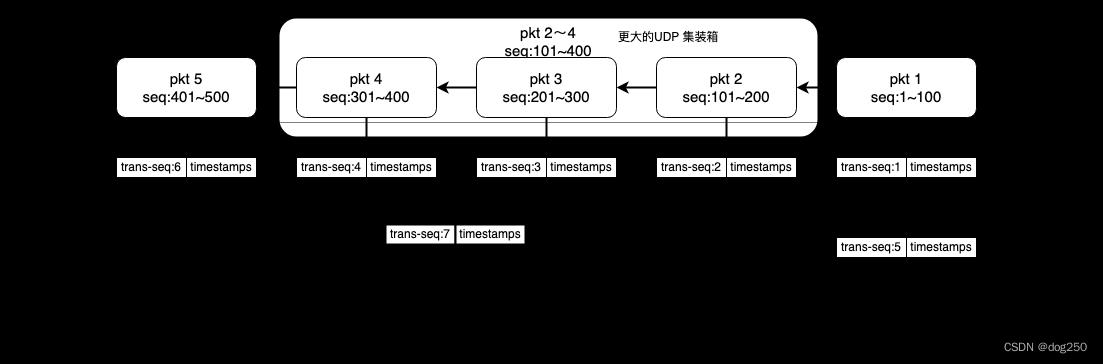
这个设计可以复用大量 TCP 现有的代码,几乎只是需要删减一些逻辑即可。将 byte-based ACK 改为 packet-based ACK 大大降低了实现的复杂程度。
最后我们来看看这个新设计有没有解决 TCP 的固有问题。
首先,ACK 歧义肯定是解决了,拥塞控制肯定是简易了,可 HoL 阻塞解决了吗?显然没有。只要 TCP 还是保序的,基于滑动窗口的停-等是保序的基础,那么 HoL 阻塞就是注定的,如果后面的数据先到达也能交付,那就不叫保序协议了。
其次,中间节点对 TCP 的固有假设可以放弃了吗?固有假设让 TCP 只能是 TCP 而不能升级。新协议显然缓解了该问题,ACK 采用 TLV 格式,提高了固有假设的难度,让固有假设成本更高。但深入思考该问题,这其实是典型的借力打力,固有假设恰恰违背了端到端原则,而 TCP 恰恰希望端到端解决一切问题。
回到新 TCP 依然存在的问题以及其解决方案本身,QUIC 到底是不是一个好协议?
显然,通过组合不同的组件,我这个新协议完全可以组合成 QUIC 协议的等价协议,可以捆绑多条流,可以修改源 UDP 端口,可以 Multi-Path,可以叠加 DTLS,诸如此类吧。所以,什么是 QUIC?名字重要吗?
这个想法思考很久了,像往年一样,大年二十九就出门了,直接在外面过除夕和春节,酒店里点了肯德基全家桶当年夜饭,顺便写了这篇文字。有点长,白天从云上草原,南浔古镇,一直到拈花湾,只有晚上回到酒店有时间,分了两天才写完。
浙江温州皮鞋湿,下雨进水不会胖。
以上是关于重新设计 TCP 协议的主要内容,如果未能解决你的问题,请参考以下文章