物体检测之从RCNN到Faster RCNN
Posted Young_Gy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了物体检测之从RCNN到Faster RCNN相关的知识,希望对你有一定的参考价值。
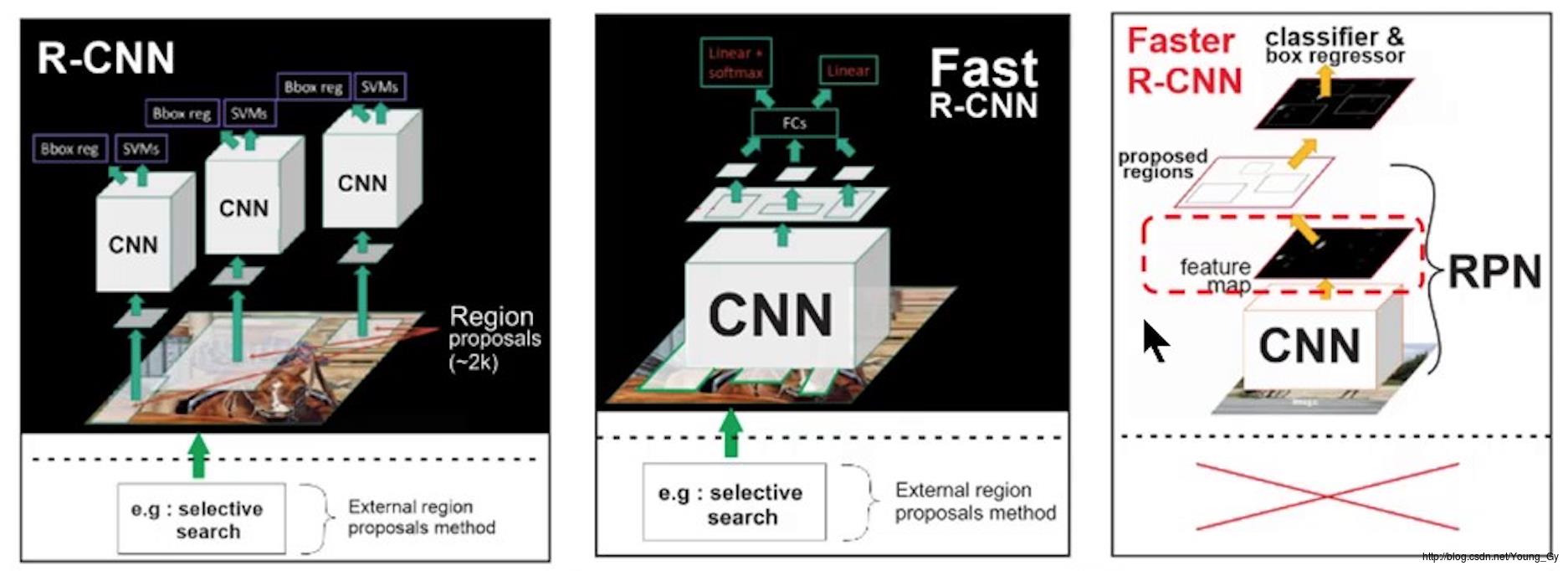
本文将简要介绍物体检测的two stage的相关算法,two stage包括:region proposals、classification。介绍的相关算法有:RCNN、Fast RCNN、Faster RCNN。
RCNN
RCNN是基于CNN物体检测的奠基之作。其核心思想是:利用selective search对图片选取多个proposals;将每个proposals送入预训练的CNN得到features;在features上使用分类器对齐分类,使用回归器得到准确边框。
问题与创新
问题:
- 目标检测进展缓慢,传统的基于SIFT、HOG的方法不符合视觉启发式、多阶段的认知,需要尝试新的方法。
- CNN在ImamgeNet图片分类领域上取得了较好的效果,同样的方法是否可以移植到目标检测领域(PASCAL VOC)。
创新:
- 将CNN应用到了目标检测上,相比传统基于HOG的方法提升巨大。
- 采用两阶段的方法,先提取proposal,再识别。
- 通过在相似数据集上有监督的预训练和目标领域的微调解决了数据量不足的问题。
架构

网络自底向上包括三部分:
- region proposal:使用selective search。
- CNN:使用在其他数据集上预训练的模型。
- 分类器和回归器
训练
训练包含4部分:
- CNN的预训练:在其他数据集上预训练CNN模型。
- CNN的微调:CNN部分输入是warped region proposals,输出是N+1个类别(N个分类目标与背景)。
- SVM detector的训练: 针对每个类别分别训练一个SVM。训练数据前景的条件是真实的box;背景的条件的IoU<0.3。
- Box regression的训练:针对每个类别分别训练一个regression。训练数据的条件是IoU>0.6。
CNN的微调部分有几个问题,分别是:
- proposals中如何区分前景背景:与真实proposal的IoV>0.5的记为前景,其余记为背景。
- 训练的时候数据的比例如何选取:batch_size设置为128,其中包含32个所有类别随机的前景和96个随机背景。选取的原则是偏向于数量较少的前景。
测试
- 利用selective search计算region proposals(大约2k个)
- warp proposals将其送入到CNN中得到features
- 利用各类的SVM计算proposals的类别与分数。针对每个类别,采用非极大抑制(Non-Maximum Suppression)得到该类别所有的proposals。
- 利用各类的Box regression修正类别的bounding box。
Fast RCNN
问题与创新
针对RCNN,其存在以下问题:
- 多步训练:先在大规模类似数据集上预训练CNN,然后微调CNN,最后在微调获得的特征上加入分类器、回归器。
- 训练过程耗费过多的时间、空间:时间空间主要花费在计算CNN的features。
- 测试过慢:时间主要花在了CNN的计算上。
其中,训练及测试过慢的主要原因是:RCNN中每个proposals都经过CNN计算,计算冗余。
创新:
- single-stage training,使用multi-task loss,可以end2end训练,不需要额外存储空间。
- 针对图片先构建feature map再抽取区域,batch中的图片的个数较少,避免了冗余计算。
- 使用ROI pooling,有效地将不同大小的proposal固定为相同长度的向量。
- 采用Truncated SVD将全连接层分解成两个小的全连接,加速全连接过程的计算。
架构

网络架构如上图所示,自底向上包含下面几部分:
- 预训练的Cov层
- selective search提取的proposals
- 对Cov层上的各个proposal的映射做ROI pooling
- 全连接层
- 分类器和回归器
训练
训练包含
- 利用预训练的CNN初始化,并调整部分网络结构以初始化网络
- 利用multi-task loss对目标检测问题做fine tuning
在初始化网络部分,对预训练的CNN网络主要做了以下的修改:
- 最后一个max pooling层被ROI pooling层取代。ROI pooling层的固定参数是 H,W ,含义是将region均分成 H∗W 子区域,对每个子区域做max pooling从而得到固定的输出。
- 网络最后的全连接和softmax层被分类器、各个类别的回归器取代。
- 网络的输入源更改为2个,包括图片和图片对应的ROI。
在fine tuning部分,存在以下问题:
- proposals中如何区分前景背景:与真实proposal的IoV>0.5的记为前景,0.1<=Iov<0.5记为背景。
- 训练的时候数据的比例如何选取:选取的图片记为N,每张图片选择R/N个ROI。论文中使用的参数是N=2,R=128。这样做的好处是输入的图片较少,从而避免了因图片不同造成的冗余计算。选择25%的数据作为前景,75%的数据作为背景。
- 训练的时候使用综合分类、回归的multi-task loss。
测试
- 输入图像到CNN中得到feature map。
- 利用selective search计算region proposals(大约2k个)
- 在feature map上找到proposals的映射,针对每个proposal做ROI pooling得到固定长度的feature。
- 通过全连接、分类器、回归器得到各类别的概率及各类别的box。
- 针对每个类别,采用非极大抑制(Non-Maximum Suppression)得到该类别所有的proposals。
Faster RCNN
问题与创新
问题:
- SPP Net和Fast RCNN的计算瓶颈主要是region proposals。
创新:
- 将之前用于detection的CNN feature map用于计算region proposals。采用RPN网络计算region proposals。RPN网络和detection网络共享CNN权重,几乎实现了cost-free的proposals计算。
架构
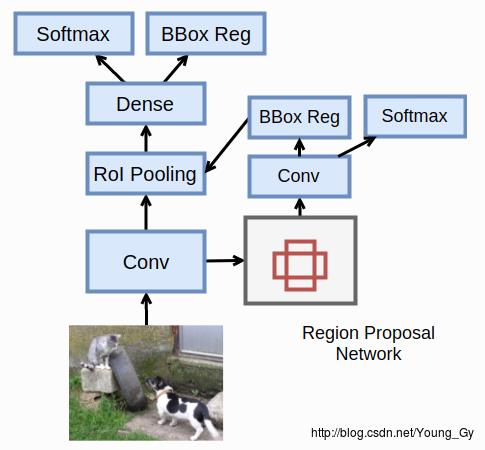
Faster RCNN的大体架构与Fast RCNN一致,唯一不同的是将Selective Search换成了Region Proposal Network去获得bounding box。
网络架构如上图所示,自底向上包含下面几部分:
- 预训练的Cov层
- Region Proposal Network提取的proposals
- 对Cov层上的各个proposal的映射做ROI pooling
- 全连接层
- 分类器和回归器
下面,将详细介绍RPN网络架构。
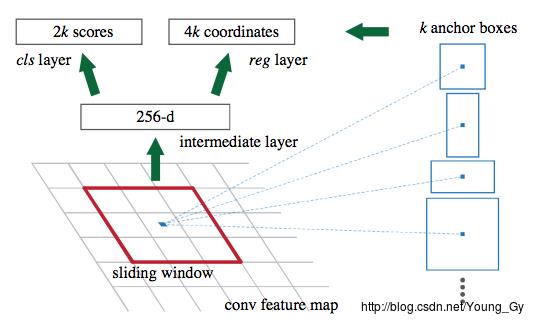
RPN网络在feature map上加了一个n*n(3*3),通道为256的卷积,这样feature map上的每一个点连同其周围的8个点都被映射成了一个大小256的向量;接着再通过1*1的卷积,得到通道为(2k+4k=6k)的feature map。其中,k代表锚框的数量。
训练
训练包含
- Region Proposal Network的训练
- 将RPN网络和Fast RCNN detection网络的卷积共享
先来谈RPN网络的训练
RPN网络的输入是正负例的锚框,输出是边框的修正(回归)以及是不是前景(二分类)。
选择正负例锚框的标准如下,其batch为256,正负比例为1比1:
- 正例:对每个真实box,距离其IOU最大的锚框;对任意一个真实box,IOU>0.7的锚框。
- 负例:对所有真实box,IOU<0.3的锚框。
其中,对于1000*600大小的图片,大约有20000(60*40*9)个锚框。忽略了与边界相交的锚框后还剩6000个。但是这些边框有相当一部分相交的很多,因此采用IOU阈值为0.7的NMS,余下2000个锚框。
损失函数使用的是综合分类、回归的multi-task loss。
再来谈如何共享RPN和Fast RCNN的卷积
一般来说,有三种共享卷积的方法:
- 交替训练RPN和Fast RCNN,使用一个训练的结果去初始化另外一个
- 当成一个网络去做end2end的训练,综合RPN的2类loss和Fast RCNN的loss
- 使用Fast RCNN的loss去做完全backward的训练
实际使用时,采取4-step的训练:
- 先预训练再微调训练RPN网络
- 使用上一步RPN网络的结果,先预训练再微调训练Fast RCNN网络。在这一步后两个网络还未共享CNN权重。
- 使用上一步Detection网络的结果去初始化RPN网络,接着固定CNN的权重不变,微调RPN网络。在这一步后两个网络共享权重。
- 使用上一步RPN的结果去初始化Detection网络,接着固定CNN的权重不变,微调RPN网络。
测试
- 输入图像到CNN中得到feature map。
- 利用RPN网络计算region proposals
- 针对每个proposal做ROI pooling得到固定长度的feature。
- 通过全连接、分类器、回归器得到各类别的概率及各类别的box。
- 针对每个类别,采用非极大抑制(Non-Maximum Suppression)得到该类别所有的proposals。
总结
- RCNN将CNN引入了物体检测上,提出了proposal-classification做物体检测的整体框架。
- Fast RCNN针对RCNN不同proposals间冗余计算的问题,提出了先构建feature map,再将region proposal的region映射到feature map上进行计算;同时采用ROI pooling解决proposal大小不同的问题。
- Faster RCNN针对Fast RCNN的速度瓶颈在region proposal上,直接在CNN的feature map上加了RPN网络提供高效的proposal计算。
以上是关于物体检测之从RCNN到Faster RCNN的主要内容,如果未能解决你的问题,请参考以下文章