Redis学习总结
Posted You295
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis学习总结相关的知识,希望对你有一定的参考价值。
Redis学习总结
一:底层实现
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
Redis数据库使用字典来作为底层实现的。对数据库的增删改查也是构建在对字典的操作之上,字典的底层是使用哈希表来实现的。
1.1.Redis速度快的原因
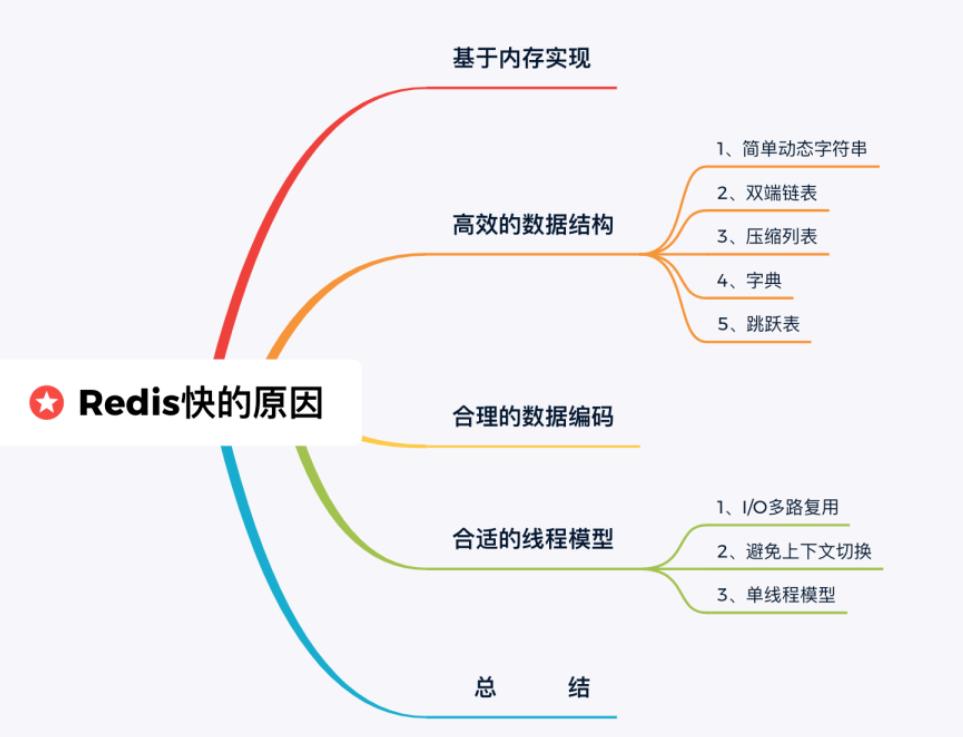
1)它是基于内存实现的:所有的数据都储存在内存中,减少了不必要的io操作,操作的速率高。
2)它的底层有多种数据结构可以支持多种数据类型,使得redis可以储存多种类型的数据。
3)合理的数据编码:根据字符串的长度以及个数适配不同的编码格式。
4)它的单线程的,单线程进行操作避免了频繁的上下文切换。
5)采用了非阻塞IO多路复用机制:多个客户端连接redis,各自发送命令到服务器,应对大量的请求,redis使用了IO多路复用机制同时监听多个套接字,并且将这些事情推送到一个队列中,然后逐个被执行,最终将结果返回给客户端。
1.2.sorted set有序是怎么实现的
sorted set中的每一个成员都会有double类型的分数(score)与之相连接,它就是通过集合中的分数来为元素进行排序,,尽管每个成员都是唯一的,但是分数确是可以重复的。
二:淘汰策略
在Redis中,允许用户设置最大使用内存大小server.maxmemory,当Redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
1)定时删除:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
2)惰性删除:key过期的时候删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。
3)定期删除:每隔一段时间执行一次删除(在redis.conf配置文件设置hz,1s刷新的频率)过期key操作
配置方案
- volatile-lru:从已设置过期的数据集中挑选最近最少使用的淘汰.
- volatile-ttr:从已设置过期的数据集中挑选将要过期的数据淘汰
- volatile-random:从已设置过期的数据集中任意挑选数据淘汰
- allkeys-lru:从数据集中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集中任意挑选数据淘汰
- noenviction:禁止淘汰数据
[注意] redis淘汰数据时还会同步到aof
三:持久化方案
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失;
Redis 提供两种持久化机制 RDB(默认) 和 AOF 机制.
1)RDB:直接把内存中的数据保存到一个 dump 的文件中,定时保存,保存策略。默认 Redis 是会以快照"RDB"的形式将数据持久化到磁盘的一个二进制文件 dump.rdb。当 Redis 需要做持久化时,Redis 会 fork 一个子进程,子进程将数据写到磁盘上一个临时 RDB 文件中。当子进程完成写临时文件后,将原来的 RDB 替换掉,这样的好处是可以 copy-on-write。
需要注意的是,每次快照持久化都会将主进程的数据库数据复制一遍,导致内存开销加倍,若此时内存不足,则会阻塞服务器运行,直到复制结束释放内存;都会将内存数据完整写入磁盘一次,所以如果数据量大的话,而且写操作频繁,必然会引起大量的磁盘I/O操作,严重影响性能,并且最后一次持久化后的数据可能会丢失;
2).AOF:把所有的对 Redis 的服务器进行修改的命令都存到一个文件里,命令的集合。Redis 默认是快照 RDB 的持久化方式。当 Redis 重启的时候,它会优先使用 AOF 文件来还原数据集,因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。你甚至可以关闭持久化功能,让数据只在服务器运行时存。
优点:数据安全------通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof 工具解决数据一致性问题。----------AOF 机制的 rewrite 模式。AOF 文件没被 rewrite 之前(文件过大时会对命令 进行合并重写),可以删除其中的某些命令
缺点:AOF 文件比 RDB 文件大,且恢复速度慢。--------------数据集大的时候,比 rdb 启动效率低。
四:缓存雪崩
缓存的雪崩就是指在redis设值定时自动清空数据的时间,刚好达到所定的时间的时候在这一瞬间缓存全部失效,而就在这时有大量的请求发来,导致了所有的请求都打到了数据库上,造成了数据库响应不及时挂掉了,此时首页也就没有办法再继续向外提供服务了,这就是缓存的雪崩现象。
解决方案
1)可以随机初始化缓存的失效时间,这样所有的缓存就不会再同一时间失效
2)最暴力的方法,就是不设置失效时间
3)设置定时器,比如我设置的时间为30分钟,那我就在30分钟之前的某个时间将数据库的数据给它加进去,然后再重新定时为30分钟,不断地去刷新缓存,让他不会失效。
五:缓存穿透
指用户不断地用数据库中没有的参数来发送请求,当他发送请求后redis中也没有对应的数据,这样redis就查不到这个结果,然后就会去数据库中查,此时redis也就没有办法拦截,这就是穿透。

解决方案
1)对参数的合法性就行校验,当参数不合法时直接return掉。
2)使用布隆过滤器。
六:缓存击穿
做某一件商品推销活动时,将数据库中信息存到redis中,这件商品对应一个key,此缓存设置的失效时间为4个小时,当刚好达到4个小时的时候,此时这个key就会失效,之后的用户请求就会击穿redis打到数据库中,造成数据库响应不及时,然后挂掉。 它是指的击穿某一个热点的key。

解决方案
1)让这个缓存永不过期(当然这样不好)
2)利用分布式锁(互斥锁),当请求击穿redis时去请求数据时加上锁,这时就只能有一个线程可以去访问数据库,减轻了数据库的负担,之后这一个线程查询到数据后又将数据存到redis中,此时也可以设置让其他的线程睡上几毫秒,然后再去向redis请求查询,这样就能解决了。
以上是关于Redis学习总结的主要内容,如果未能解决你的问题,请参考以下文章