浅谈 C++ 字符串:std::string 与它的替身们
Posted 鱼竿钓鱼干
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈 C++ 字符串:std::string 与它的替身们相关的知识,希望对你有一定的参考价值。
浅谈 C++ 字符串:std::string 与它的替身们
文章目录
零、前言
本文浅谈了 C++ 字符串的相关概念,侧重讨论了其实现机制、优缺点等方面,对于如何使用 C++ string,建议读者通过阅读其他文章学习了解。
期间参阅了很多优秀博客,具体参考文章在末尾和相应部分均有列出,强烈推荐看看
一、前辈:C 风格的字符串
该部分参阅了这两篇博客:
C的字符串有哪些问题
C风格字符串缺陷及改进
函数式编程 (用 PPT 例子介绍了停机问题)
1.1 什么是 C 风格的字符串
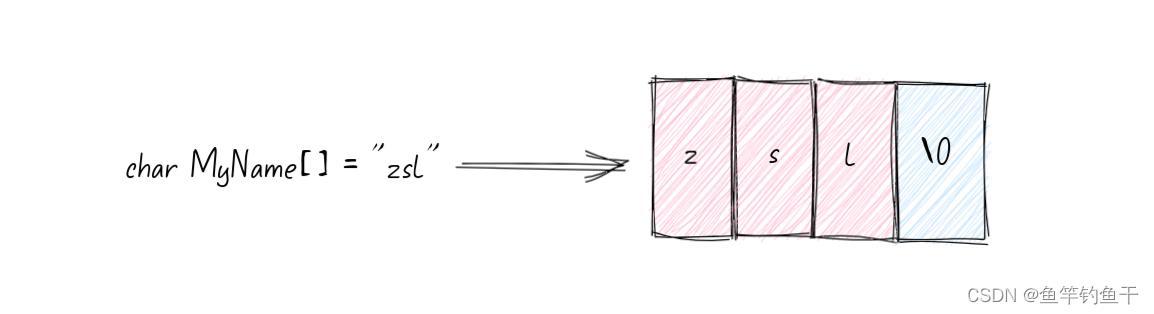
C 语言实际并不存在所谓的字符串类型,而是把以’\\0’ 结尾的字符数组当作字符串
char notstring[8] = 'n','o','t',' ','s','t','r','i','n','g'; // 不是字符串
char istring[8] = 'i','s',' ','s','t','r','i','n','g','\\0'; // 是字符串
char MyID[11] = "FishingRod"; // 结尾自动包含\\0
char MyName[] = "zsl"; // 让编译器自动计数
1.2 C 风格的字符串有什么缺陷
C 风格的字符串缺陷主要有以下几点
- 以 ‘\\0’ 作为结尾,没有直接指明长度
- 相关 API 设计糟糕
- 缺乏内存管理
- 线程安全问题
1.2.1 以 ‘\\0’ 作为结尾,没有直接指明长度
难以校验字符串正确性
校验 C 风格字符串正确性近乎可以等价于解决停机问题。下面简单介绍以下停机问题,便能认识到其中相似之处。
停机问题:给定任意一个程序及其输入,判断该程序是否能够在有限次计算以内结束。

假设停机问题有解,那么我们就可以发明一个自动检查程序里面有没有死循环的工具了!我们给它任意一个函数和这个函数的输入,就能告诉你这个函数会不会运行结束。
我们用下列伪代码描述
function halting(func, input)
return if_func_will_halt_on_input;
接下来充分利用停机判定,构造另一函数
function myfunc(func)
if(halting(func, func))
for(;;) // 死循环
接下来调用
myfunc(myfunc)
函数 myfunc 以 myfunc 为输入时,停机还是不停机呢?出现悖论了!
所以停机问题不可判定。类似的,如果你要去判断 C 风格的字符串是否正确,唯一的方法即使遍历它并判断循环是否终止。任何处理无效 C 风格字符串的循环都是死循环(或导致缓冲区溢出)。
取得字符串长度的操作时间复杂度为 O ( N ) O(N) O(N),它本可以是 O ( 1 ) O(1) O(1)。
由于以 ‘\\0’ 作为结束标志,所以想要获取字符串长度就要遍历整个字符串,这导致 strlen() 函数的时间复杂度为
O
(
N
)
O(N)
O(N) 而不是
O
(
1
)
O(1)
O(1) ,在下面的代码例子中是刚学 C 语言的时候容易犯下的错误,在循环中使用 strlen() 作为判定条件,导致时间复杂度由预期的
O
(
N
)
O(N)
O(N) 变为
O
(
N
2
)
O(N^2)
O(N2)
#include <string.h>
#include <stdio.h>
int main()
char str[] = "abcde";
int len = strlen(str); // O(N)
for(int i = 0; i < strlen(str); ++i) // O(N^2)
printf("%c", str[i]);
for(int i = 0; i < len; ++i) // O(N)
printf("%c", str[i]);
1.2.2 相关 API 设计糟糕
可以发现 C 风格字符串的相关操作 API 并不是那么优雅,存在着缺少错误检查、缓冲区溢出、没考虑传入 NULL 等等问题。其中很大一部分原因是因为这些函数并非标准化下共同努力的结果,而是诸多程序员各自贡献积累起来的。等到 C 标准化开始的时候,“修整”他们已经太晚了,太多的程序对函数的行为已经有了明确的定义。下面作简单列举,具体可以参看这两篇博客中的说明:C的字符串有哪些问题、C风格字符串缺陷及改进
- gets() 的使用会将应用暴露在缓冲区溢出的问题之下。
- strtok() 会修改它解析的字符串,因此,它在要求可重入和多线程的程序中可能不可用。
- fgets 有着“忽视”出现在在换行符 ‘\\n’ 出现之前的空字符 ‘\\0’ 的奇怪语义。
- 在某些情况下, strncpy() 不会将目标字符串以 ‘\\0’ 结尾。
- 将 NULL 传给 C 库中的字符串函数会导致未定义的空指针访问。
- 参数混叠(parameter aliasing) (重叠,或称为自引用)在大多数 C 库函数中都是未定义行为。
- 许多 C 库字符串函数都带有受限范围的整数参数。传递超出这些范围的整数的行为不会被检测到,并会造成未定义行为。
1.2.3 缺乏内存管理
C 风格的字符串缺乏内存管理,对于长度固定或长度范围确定的字符串来说,可以使用固定长度的字节数组来存储。但是如果需要动态改变字符串长度时,就需要手动的申请和释放内存块,增加了心智负担,容易造成缓冲区溢出等内存管理问题。
1.2.4 线程安全问题
由于 C 语言出生的时候还没有多线程这些东西,所以对字符串进行修改的相关函数大多不具备线程安全性。
1.3 如何改进 C 风格的字符串或避免危险
- 给字符串加上长度
- 添加简单的内存管理功能
- 仔细阅读参考手册
- 弃用危险的 API
- 使用更加安全的字符串函数库
当然,如果没有硬性规定只能使用纯 C 语言编程,你也可以考虑使用 C++ 提供的 std::string。
二、标准库:std::string
2.1 什么是 std::string
C++ 内置了 std::string 类,这大大增强了对字符串的支持,处理起字符串来更加方便了。std::string 一定程度上可以替代 C 风格的字符串。
#include <string>
#include <iostream>
int main()
std::string s1 = "std::string";
std::string s2 = "not C string";
std::cout << s1 << " " << s2 << std::endl;
std::cout << "s1 size = " << s1.size() << std::endl;
std::cout << "s1 length = " << s1.length() << std::endl;
std::cout << "s1 + s2 = " << s1 + s2 << std::endl;
for(int i = 0; i < s1.size(); ++i)
std::cout << s1[i] << " ";
const char* Cstring = s1.c_str();
return 0;
2.2 std::string 的实现方式
这一部分参阅了下面几篇博客/书籍
漫谈C++ string(1):std::string实现
C++ folly库解读(一) Fbstring —— 一个完美替代std::string的库
深入剖析 linux GCC 4.4 的 STL string
Linux 多线程服务端编程 陈硕
C++标准库中string的三种底层实现方式
std::string的Copy-on-Write:不如想象中美好
通过查看 gcc 源代码 gcc-12.2.0 <string.h> 可以发现 string 实际上是 basic_string 模板的 char 版本特化。
namespace pmr
template<typename _Tp> class polymorphic_allocator;
template<typename _CharT, typename _Traits = char_traits<_CharT>>
using basic_string = std::basic_string<_CharT, _Traits,
polymorphic_allocator<_CharT>>;
using string = basic_string<char>; // Here!!!
#ifdef _GLIBCXX_USE_CHAR8_T
using u8string = basic_string<char8_t>;
#endif
using u16string = basic_string<char16_t>;
using u32string = basic_string<char32_t>;
using wstring = basic_string<wchar_t>;
// namespace pmr
关于basic_string 的具体实现,各版本存在差异,下面介绍 3 种常见的实现方式
- eager copy
- COW
- SSO
2.2.1 eager copy 无特殊处理
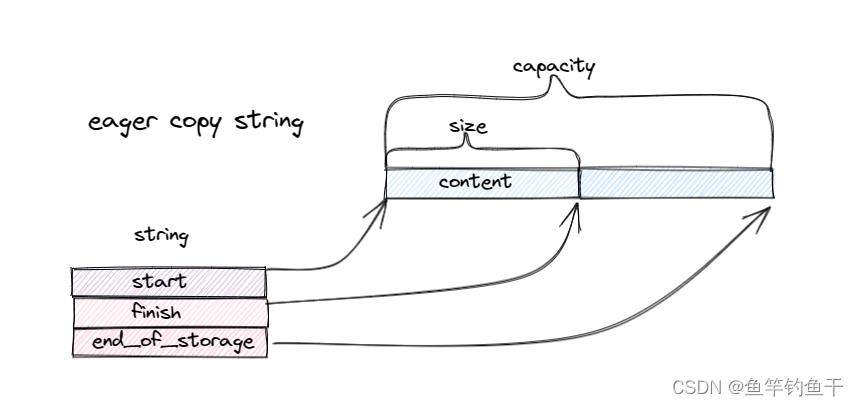
eager copy 非常朴素,没有什么特殊处理,采用类似 std::vector 的数据结构。现在很少有实现采用这种方式。
eager copy 采用深拷贝,在每次拷贝时将原 string 对应的内存以及所持有的动态资源完整地复制一份,没有任何特殊处理。这导致在需要对字符串进行频繁复制而又并不改变字符串内容时效率很低
// sgi-stl
class string
public:
const_pointer data() const return start;
iterator begin() return start;
iterator end() return finish;
size_type size() const return finish - start;
size_type capacity() const return end_of_storage - start;
private:
char* start;
char* finish;
char* end_of_storage;
当然也有其他实现 eager copy 的方式,在此不做详述,感兴趣的读者可以阅读 Linux 多线程服务端编程 陈硕 这本书中 《12.7 再探 std::string》 这一章节。
下面给出这一实现的简单图示
优点:
- 实现简单
- 每个对象互相独立,不用考虑那么多乱七八糟的场景。
缺点:
- 字符串较大时,拷贝浪费空间。
2.2.2 COW 写时复制
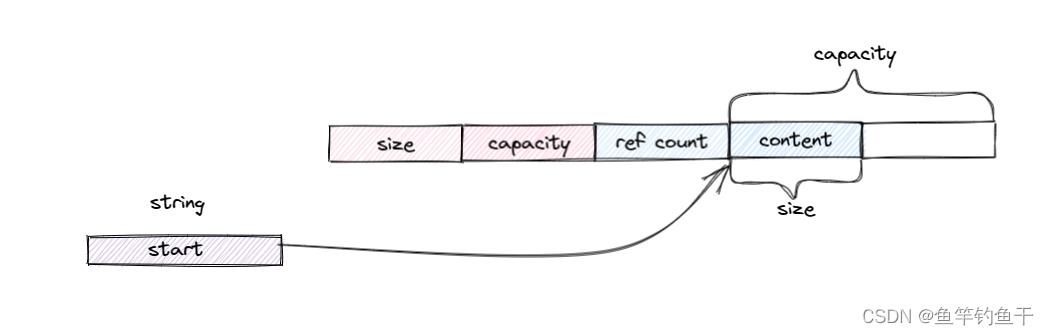
只有在某个 string 要对共享对象进行修改时,才会真正执行拷贝。
由于存在共享机制,所以需要一个std::atomic<size_t>,代表被多少对象共享。
class cow_string // libstdc++-v3
struct Rep
size_t size;
size_t capacity;
size_t refcount; // 引用计数应当是原子的
char* data[1]; // variable length
;
char* start;
为了方便验证,采用了 Compiler Explorer x86-64 gcc 4.6.4 的编译器,下面通过打印字符串的地址验证 COW 机制
// https://godbolt.org/z/zzaTvjzG9 可以通过这个链接在线查看结果
#include <iostream>
#include <string>
using namespace std;
int main ()
string a = "abcd" ;
string b = a ;
cout << "a.data() =" << (void *)a. data() << endl ;
cout << "b.data() =" << (void *)b. data() << endl ;
cout << endl;
string c = a ;
cout << "a.data() =" << (void *)a. data() << endl ;
cout << "b.data() =" << (void *)b. data() << endl ;
cout << "c.data() =" << (void *)c. data() << endl ;
cout << endl;
c[3] = 'e';
cout << "after write:" << endl;
cout << "a.data() =" << (void *)a. data() << endl ;
cout << "b.data() =" << (void *)b. data() << endl ;
cout << "c.data() =" << (void *)c. data() << endl ;
return 0;
输出结果为
// gcc 4.6.4
a.data() =0xbe02b8
b.data() =0xbe02b8
a.data() =0xbe02b8
b.data() =0xbe02b8
c.data() =0xbe02b8
after write:
a.data() =0xbe02b8
b.data() =0xbe02b8
c.data() =0xbe12f8
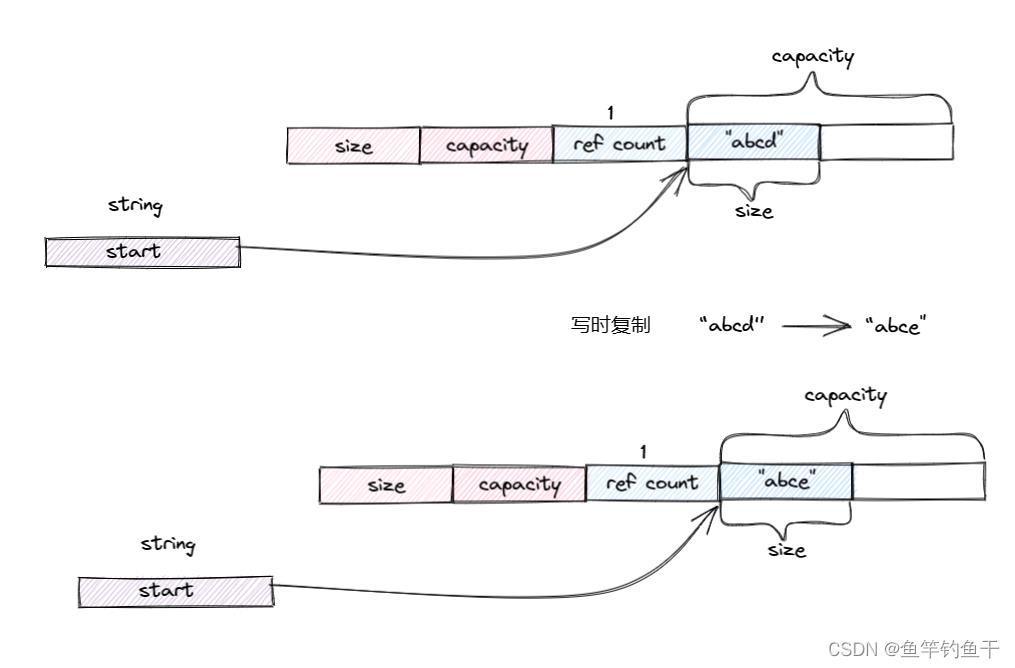
可以发现在 c 修改之前,它的地址与拷贝的 a 的地址是一样的,在修改之后就发生了变化。下面用两幅图简单说明这两个情况。
拷贝但不修改

拷贝并且修改
通过查看 gcc 变更文档,可以发现 gcc 在 5.1 版本将 std::string 的实现由 COW 改为下面要讲的 SSO 即短字符串优化。

下面时 gcc 5.1 版本下的编译结果
// https://godbolt.org/z/jGj6GjrdG
// gcc 5.1
a.data() =0x7ffd606a0dc0
b.data() =0x7ffd606a0da0
a.data() =0x7ffd606a0dc0
b.data() =0x7ffd606a0da0
c.data() =0x7ffd606a0d80
after write:
a.data() =0x7ffd606a0dc0
b.data() =0x7ffd606a0da0
c.data() =0x7ffd606a0d80
另外,在文章 深入剖析 linux GCC 4.4 的 STL string 中还通过 gdb debug 来查看引用计数来验证 COW ,并将 strncpy 和 std::string copy 做了简单的性能对比,发现对于单纯的拷贝场景来说,COW 确实达到了预期的效果,并且字符串越大效果越明显。
然而 COW 有一个严重的问题就是没有区分下标运算符的读操作和写操作
// https://godbolt.org/z/oarz1sn14
#include <iostream>
#include <string>
using namespace std;
int main ()
string a = "abcd" ;
string const_b = a ;
string c = a ;
string d = a;
cout << "a.data() =" << (void *)a. data() << endl ;
cout << "const_b.data() =" << (void *)const_b. data() << endl ;
cout << "c.data() =" << (void *)c. data() << endl ;
cout << "d.data() =" << (void *)d. data() << endl ;
cout << endl;
cout << "read const_b[0] = " << const_b[0] << endl;
cout << "a.data() =" << (void *)a. data() << endl ;
cout << "const_b.data() =" << (void *)const_b. data() << endl ;
cout << "c.data() =" << (void *)c. data() << endl ;
cout << "d.data() =" << (void *)d. data() << endl ;
cout << endl;
cout << "read c[0] = " << c[0] << endl;
cout << "a.data() =" << (void *)a. data() << endl ;
cout << "const_b.data() =" << (void *)const_b. data() << endl ;
cout << "c.data() =" << (void *)c. data() << endl ;
cout << "d.data() =" << (void *)d. data() << endl ;
cout << endl;
d[0] = '1';
cout << "write d[0] = '1'" << endl;
cout << "a.data() =" << (void *)a. data() << endl ;
cout << "const_b.data() =" << (void *)const_b. data() << endl ;
cout << "c.data() =" << (void *)c. data() << endl ;
cout << "d.data() =" << (void *)d. data() << endl ;
return 0;
结果如下
a.data() =0x14122b8
const_b.data() =0x14122b8
c.data() =0x14122b8
d.data() =0x14122b8
read const_b[0] = a
a.data() =0x14122b8
const_b.data() =0x14132f8
c.data() =0x14122b8
d.data() =0x14122b8
read c[0] = a
a.data() =0x14122b8
const_b.data() =0x14132f8
c.data() =0x1413328
d.data() =0x14122b8
write d[0] = '1'
a.data() =0x14122b8
const_b.data() =0x14132f8
c.data() =0x1413328
d.data() =0x1413358
可以发现,即使只是通过[]运算符去读取对应位置的值也会引发拷贝,这就可能导致意外开销。
另一方面,COW 对多线程并不友好,虽然 C++ 并没有要求多线程操作同一个字符串时的线程安全,但当多线程操作几个独立的字符串时,应当是安全的。
为了保证这点,COW 通过以下两点来实现
-
只对引用计数进行原子增减
-
需要修改时,先分配和复制,后将引用计数-1(当引用计数为0时负责销毁)
虽然使用原子操作相较直接使用 mutex 的开销要小很多但仍然会带来一定的性能损耗
- 系统通常会lock住比目标地址更大的一片区域,影响逻辑上不相关的地址访问。
- lock指令具有”同步“语义,会阻止CPU本身的乱序执行优化。
- 两个CPU对同一个地址进行原子操作,会导致cache bounce(抖动)
就操作顺序而言,先分配后复制再修改
以上是关于浅谈 C++ 字符串:std::string 与它的替身们的主要内容,如果未能解决你的问题,请参考以下文章