MLP与KNN 0~9手写数字识别
Posted 404detective
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MLP与KNN 0~9手写数字识别相关的知识,希望对你有一定的参考价值。










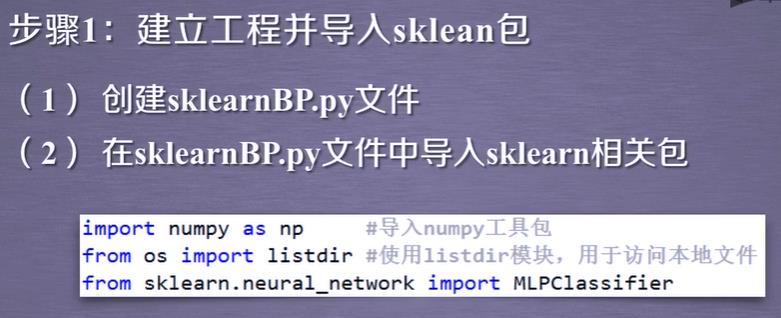







import numpy as np #导入numpy工具包
from os import listdir #使用listdir模块,用于访问本地文件
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
def img2vector(fileName):
'''将加载的32*32的图片矩阵展开成一列向量'''
retMat = np.zeros([1024],int) #定义返回的矩阵,大小为1*1024
fr = open(fileName) #打开包含32*32大小的数字文件
lines = fr.readlines() #读取文件的所有行
for i in range(32): #遍历文件所有行
for j in range(32): #并将01数字存放在retMat中
retMat[i*32+j] = lines[i][j]
return retMat
def readDataSet(path):
'''加载训练数据,并将样本标签转化为one-hot向量'''
fileList = listdir(path) #获取文件夹下的所有文件
numFiles = len(fileList) #统计需要读取的文件的数目
dataSet = np.zeros([numFiles,1024],int) #用于存放所有的数字文件
hwLabels = np.zeros([numFiles,10]) #用于存放对应的one-hot标签
for i in range(numFiles): #遍历所有的文件
filePath = fileList[i] #获取文件名称/路径
digit = int(filePath.split('_')[0]) #通过文件名获取标签,注意类型转换
hwLabels[i][digit] = 1.0 #将对应的one-hot标签置1
dataSet[i] = img2vector(path +'/'+filePath) #读取文件内容
return dataSet,hwLabels
#读取训练集
train_dataSet, train_hwLabels = readDataSet('E:\\Desktop\\python_code\\sklearn\\课程数据\\手写数字\\\\trainingDigits')
'''
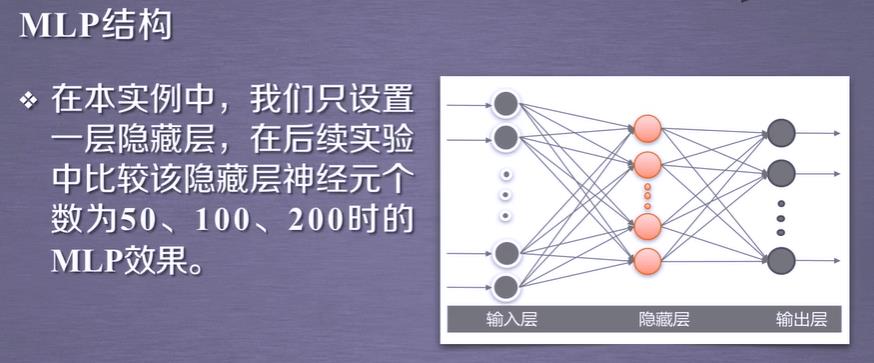
构建神经网络:设置网络的隐藏层数、各隐藏层神经元个数、激活函数、学习率、优化方法、最大迭代次数。
设置含100个神经元的隐藏层,hidden_layer_sizes 存放的是一个元组,表示第i层隐藏层里神经元的个数
使用logistic激活函数和adam优化方法,并令初始学习率为0.0001,
'''
clf = MLPClassifier(hidden_layer_sizes=(100,),
activation='logistic', solver='adam',
learning_rate_init = 0.0001, max_iter=2000)
print(clf)
'''
fit函数能够根据训练集及对应标签集自动设置多层感知机的输入与输出层的神经元个数
例如train_dataSet为n*1024的矩阵,train_hwLabels为n*10的矩阵,则fit函数将MLP的输入层神经元个数设为1024,输出层神经元个数为10
'''
clf.fit(train_dataSet,train_hwLabels)
#KNN
#knn = KNeighborsClassifier(algorithm='kd_tree', n_neighbors=3)
#knn.fit(train_dataSet, train_hwLabels)
#读取测试集
dataSet,hwLabels = readDataSet('E:\\Desktop\\python_code\\sklearn\\课程数据\\手写数字\\\\testDigits')
res = clf.predict(dataSet) #对测试集进行预测
error_num = 0 #统计预测错误的数目
num = len(dataSet) #测试集的数目
for i in range(num): #遍历预测结果
#比较长度为10的数组,返回包含01的数组,0为不同,1为相同
#若预测结果与真实结果相同,则10个数字全为1,否则不全为1
if np.sum(res[i] == hwLabels[i]) < 10:
error_num += 1
print("Total num:",num," Wrong num:", \\
error_num," WrongRate:",error_num / float(num))
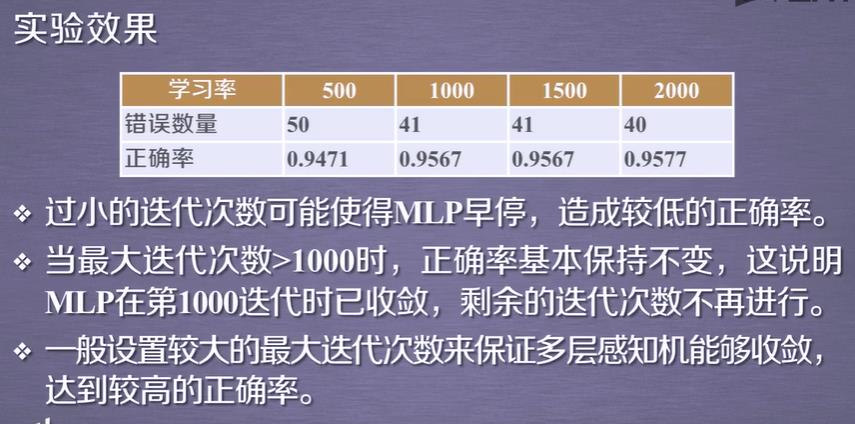
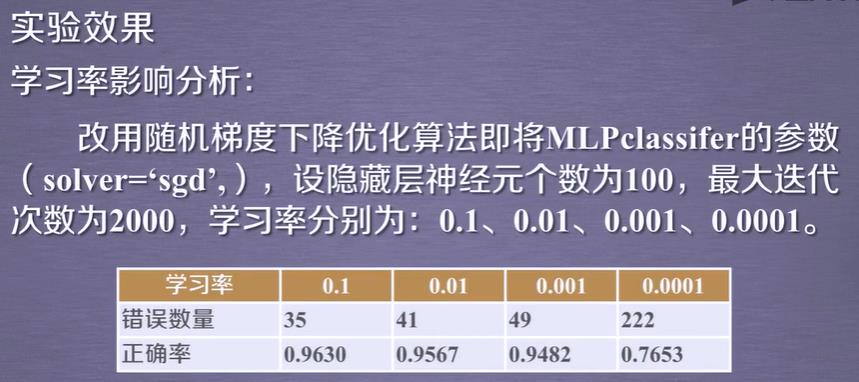
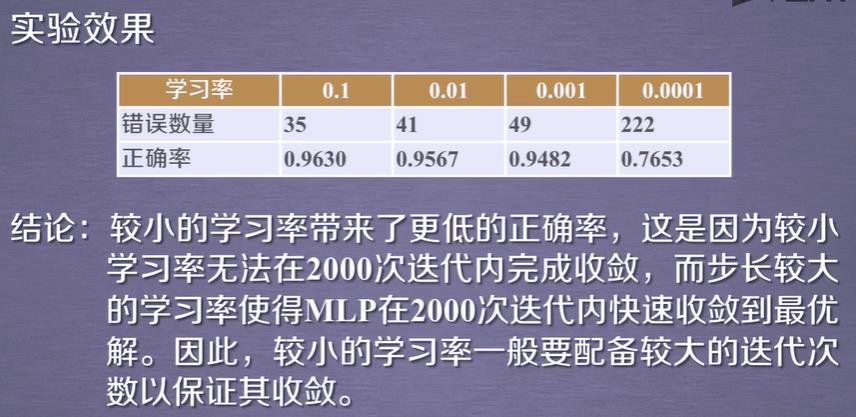

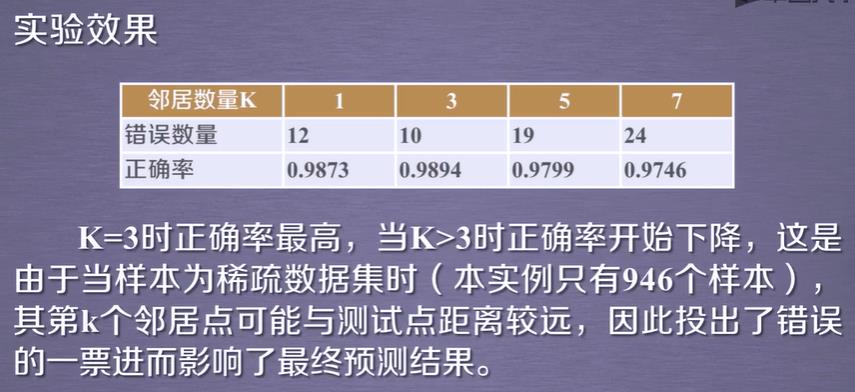

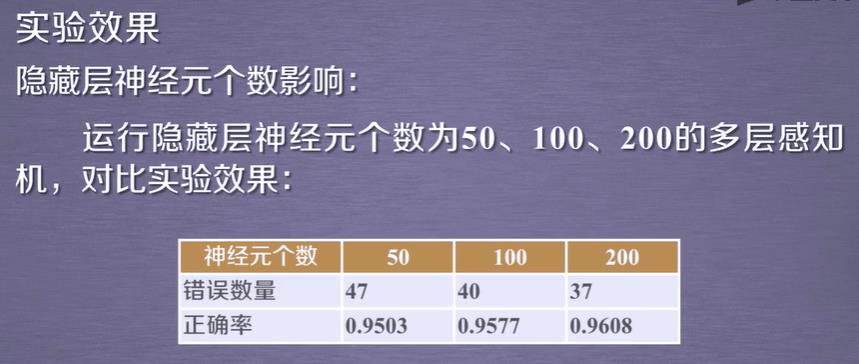
而且该训练KNN在运行速度上比MLP快很多
以上是关于MLP与KNN 0~9手写数字识别的主要内容,如果未能解决你的问题,请参考以下文章