GPU服务器Ubuntu环境配置教程及各种踩坑
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPU服务器Ubuntu环境配置教程及各种踩坑相关的知识,希望对你有一定的参考价值。
博主的GPU服务器快要过期了,为了让其发挥更多的光和热,博主打算将系统重装,来分别感受下不同系统下的GPU服务器。哈哈哈
博主为了快速运行项目,在购买服务器时选择的是Pytorch 1.9.1 Ubuntu 18.04 ,该系统下会帮我们安装好驱动,conda,因此省时省力,那么现在我们抱着体验的态度那就无需系统帮我们安装了这些附属软件了,首先登场的便是纯净版的Ubuntu。
Ubuntu下的GPU环境配置
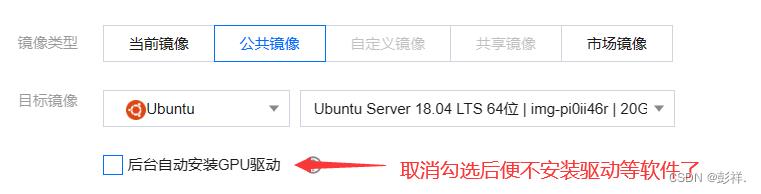
再次进入输入nvidia-smi,,此时已经找不到我们的驱动了
那么下面第一步便是安装驱动
查看显卡配置
首先我们需要查看我们的显卡配置,他会给我们推荐我们所适合的驱动版本
输入ubuntu-drivers devices,如果提示没有这个命令可以在执行sudo apt install ubuntu-drivers-common安装后再次执行如图:
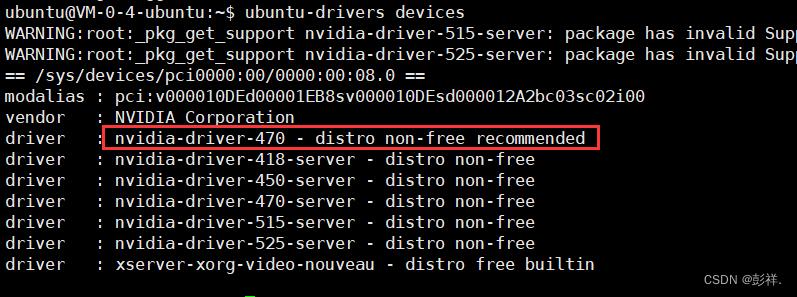
他给出我们的推荐版本是nvidia-driver-470,这与我们先前预装的版本也是一致的
- 此时如果同意安装推荐版本,那我们只需要终端输入:
sudo ubuntu-drivers autoinstall就可以自动安装了。
注意:sudo ubuntu-drivers autoinstall会吃网卡驱动(即可能会使网卡驱动丢失),所以还是推荐使用方法二,由于博主使用的是服务器,也就随便造了
- 当然我们也可以使用 apt 命令安装自己想要安装的版本,比如我想安装 340 这个版本号的版本,终端输入:
sudo apt install nvidia-340就自动安装了
成功方法
我们使用方法2
sudo apt install nvidia-470
再次出问题:无法定位软件包:nvidia-470
ubuntu@VM-0-4-ubuntu:~$ sudo apt install nvidia-470
Reading package lists... Done
Building dependency tree
Reading state information... Done
报错:
E: Unable to locate package nvidia-470
此时我们将安装命令修改为sudo apt-get install nvidia-driver-470,加了driver。
随后发现可以进行安装了,等待了几分钟后安装成功。
安装完成后一定要重启,否则还会报错:
NVIDIA-SMI has failed because it couldn’t communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
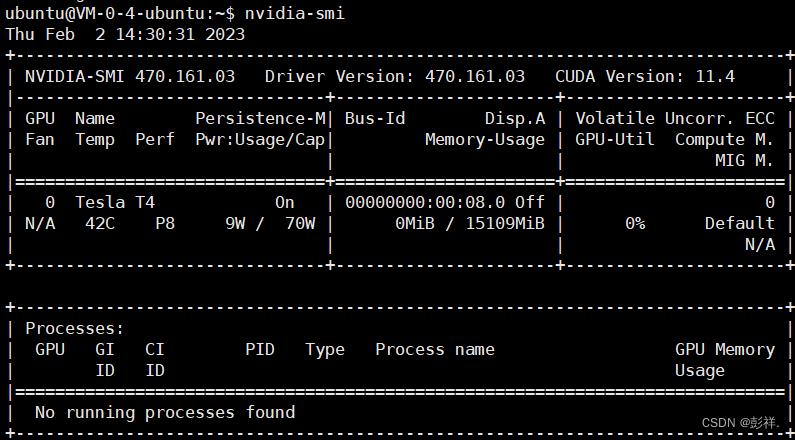
这样一想,之前使用自动安装时重启是不是也就正常了呢,不过方法一确实存在吃网卡驱动的问题,所以还是果断方法二吧,最终看下效果:
随后便是cuda的安装了
我们可以在nvidia官网上进行安装:
https://developer.nvidia.com/cuda-toolkit-archive
找到合适的cuda版本:如cuda11.4
随后执行下面的命令即可
wget https://developer.download.nvidia.com/compute/cuda/11.4.0/local_installers/cuda_11.4.0_470.42.01_linux.run
sudo sh cuda_11.4.0_470.42.01_linux.run
随后我们选择continue即可
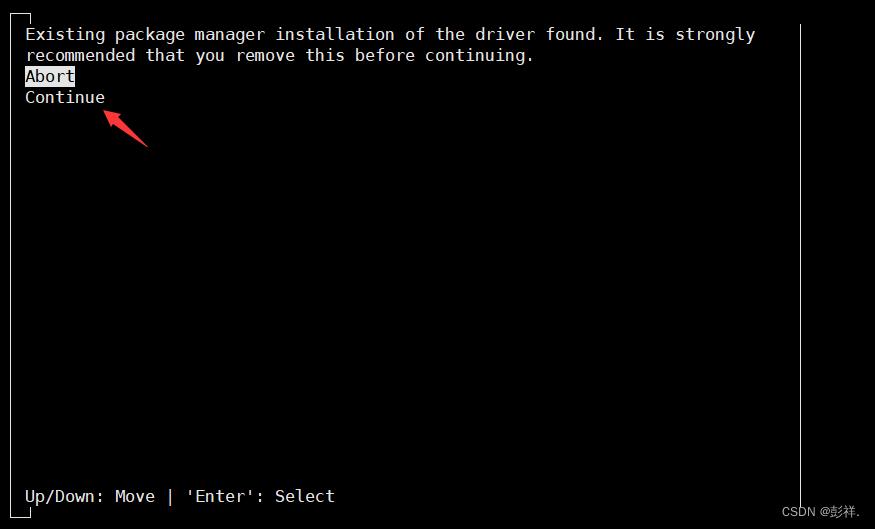
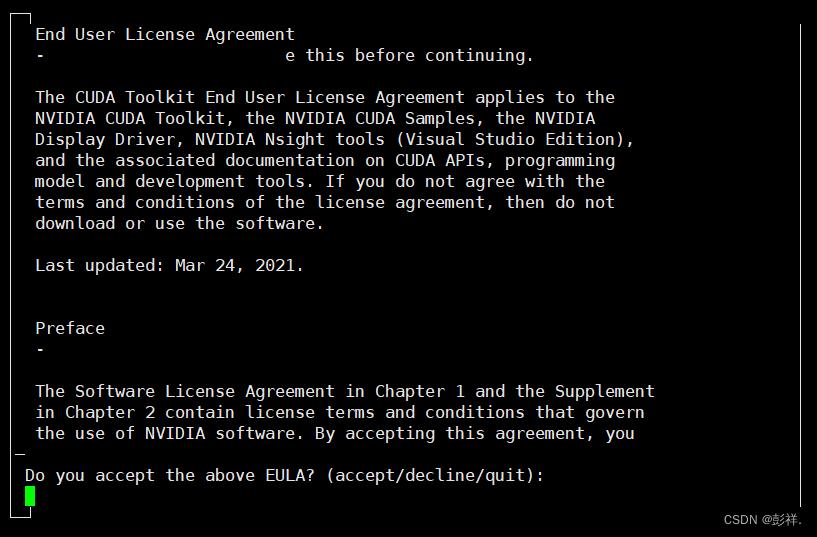
这里输入accept继续
依次点击Options - Driver Options- Do not install any of the OpenGL-related driver files。然后选择 Done 退回到初始页面,在初始页面下把打上X的Drive取消勾选(先前已经按照nvidia驱动了)。选择 Install 开始安装。
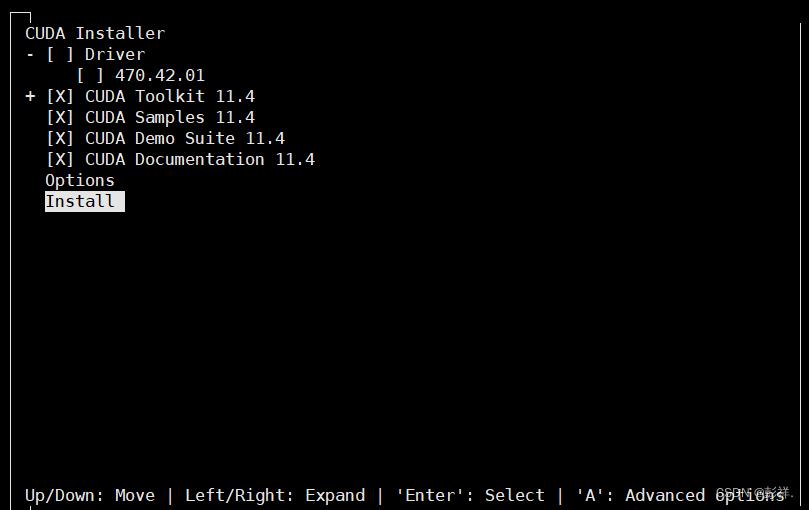
最后显示安装报告就完成了
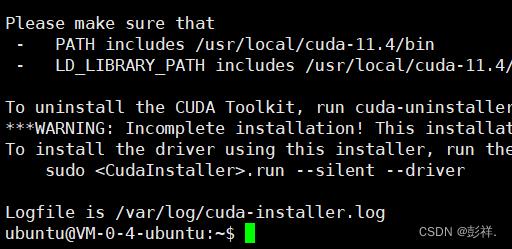
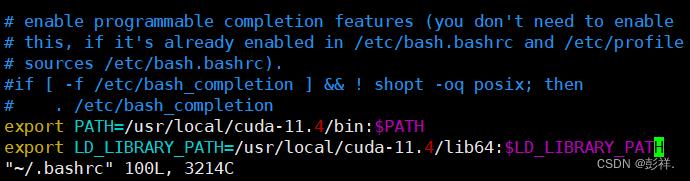
接下来便是将cuda加入环境变量:
执行:vim ~/.bashrc
在文件最后面添加:
export PATH=/usr/local/cuda-11.4/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.4/lib64:$LD_LIBRARY_PATH
 执行 source ~/.bashrc 使其生效
执行 source ~/.bashrc 使其生效
source ~/.bashrc
echo $PATH 查看环境变量

运行nvcc -V命令:
ubuntu@VM-0-4-ubuntu:~$ nvcc -V
输出:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Wed_Jun__2_19:15:15_PDT_2021
Cuda compilation tools, release 11.4, V11.4.48
Build cuda_11.4.r11.4/compiler.30033411_0
显示安装的cuda版本为11.4,安装成功
随后依次执行下列语句验证cuda是否成功
cd ~/NVIDIA_CUDA-11.4_Samples/1_Utilities/bandwidthTest/
make
./bandwidthTest
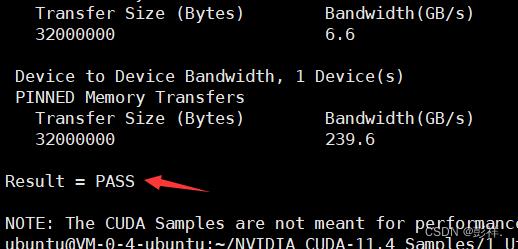
最终提示PASS说明运行成功。
这里最后Result=pass表示cuda显卡带宽测试通过。
失败案例
踩坑:应对失败最后只能重装系统
结论:不要使用方法一时出错使用)
踩坑过程
使用sudo ubuntu-drivers autoinstall果然出了问题:执行nvidia-smi时报错
NVIDIA-SMI has failed because it couldn’t communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
首先使用nvcc -V检查驱动和cuda:
ubuntu@VM-0-4-ubuntu:~$ nvcc -V
输出以下信息
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2017 NVIDIA Corporation
Built on Fri_Nov__3_21:07:56_CDT_2017
Cuda compilation tools, release 9.1, V9.1.85
说明显卡驱动是存在的然后查看已安装驱动的版本信息
ls /usr/src | grep nvidia
显卡驱动是可以找到的,没有问题。

随后依次输入以下命令
sudo apt-get install dkms
sudo dkms install -m nvidia -v 470.161.03
但在执行第二句代码时出了问题
File: /usr/src/nvidia-470.161.03/dkms.conf does not exist.
根本原因是重启后,内核版本与驱动版本不兼容导致的显卡驱动出错。所以我们恢复之前的内核版本就可以解决这个问题。
首先查看目前的内核版本
uname -r
然后查看内核版本有哪些
grep menuentry /boot/grub/grub.cfg
修改开机系统启动项
sudo vi /etc/default/grub
按i进入编辑状态,修改其中第一行
GRUB_DEFAULT=0 ,修改为GRUB_DEFAULT=“1> 3”
选择第二个菜单的第四个子选项。
这里因人而异,得看自己的启动项有哪些。
修改完成后退出,按ESC,随后按shift+:变为可查询状态,最后输入wq!保存修改
然后更新GRUB文件
sudo update-grub
重启系统
sudo reboot
这个要等挺长时间,随后重启完成后博主发现连接不上服务器了,呜呜呜,看来这个方法失败了,奉劝自己电脑不要这么造。
那么博主只能重装系统了。
cuDNN安装
成功案例
再次进入:https://developer.nvidia.com/rdp/cudnn-archive,下载这个版本
安装过程实际上是把cudnn的头文件复制到CUDA的头文件目录里面去;把cuDNN的库复制到CUDA的库目录里面去。
首先是将我们在本地下载的文件上传到服务器上
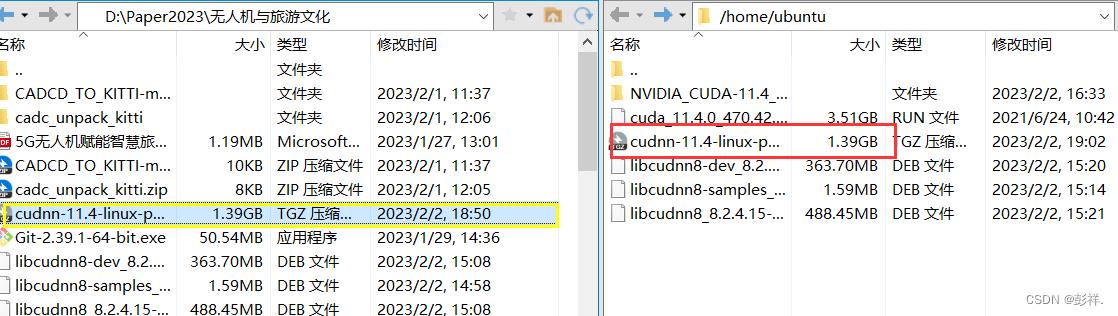
进行解压:
tar -xvf cudnn-11.4-linux-ppc64le-v8.2.4.15.tgz
之后再执行如下命令:(大家也可以一个一个的移动到相应的cuda文件下)
cd 进入刚刚解压的文件内,直到出现lib,include文件夹,一步步cd过来的,如下图:

在看到include与lib后我们需要将其复杂到cuda11.4对应的文件夹内,首先我们要先找到cuda11.4,在usr/local文件下

接下来将cudnn中相应的包放入cuda下即可,与windows下一样
在cudnn的文件目录下执行:
sudo cp lib/* /usr/local/cuda-11.4/lib64/
sudo cp include/* /usr/local/cuda-11.4/include/
随后配置权限:
sudo chmod a+r /usr/local/cuda-11.4/lib64/*
sudo chmod a+r /usr/local/cuda-11.4/include/*
接下面便是查看cuDNN版本了
旧版执行:
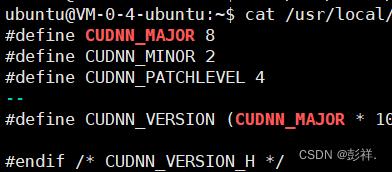
cat /usr/local/cuda-11.4/include/cudnn.h | grep CUDNN_MAJOR -A2
新版本有更新,将cuDNN版本信息单拉了一个文件名cudnn_version.h
执行:
cat /usr/local/cuda-11.4/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
博主是新版,因此使用的是第二个命令,显示成功
失败案例
首先我们进入官网:https://developer.nvidia.com/rdp/cudnn-archive
找到合适的版本如cuda11.4下ubuntu的cuDNN为:
Ubuntu 18.04下,需要三个下载包,分别是运行时库、开发库以及代码示例:

本地下载后,上传(scp/rsync)到GPU服务器上执行dpkg安装即可。
执行前需要cd到home/ubuntu文件目录下才能安装。
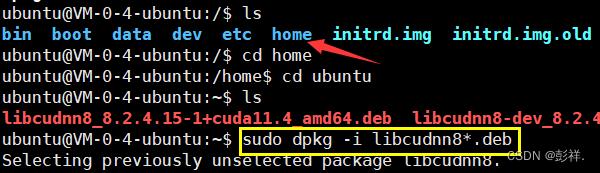
sudo dpkg -i libcudnn8*.deb
然而最后还是失败了,呜呜呜,因此采用其他的方法
最终我们终于将cuda与cudnn安装成功了。
Anconda安装
可以前往官网下载,但速度很慢,我们可以使用清华源镜像进行下载
下载地址:https://mirrors.bfsu.edu.cn/anaconda/archive/
博主选择的是这一款:
右键获取下载连接:
https://mirrors.bfsu.edu.cn/anaconda/archive/Anaconda3-2022.10-Linux-x86_64.sh
随后我们在服务器上输入:
wget https://mirrors.bfsu.edu.cn/anaconda/archive/Anaconda3-2022.10-Linux-x86_64.sh
下载完成后安装即可:(在下载目录下)
sudo bash Anaconda3-2022.10-Linux-x86_64.sh
接受许可输入yes回车
使用默认安装目录即可,回车
输入yes确认使用conda init初始化Anaconda3

之后便安装成功了,关闭当前连接重新打开后输入:conda -V,查看环境

接下来就是便是一样的步骤了,只需要安装好tensorflow,pytorch等资源包就可以运行程序了。
我们来简单测试一下,首先创建一个cuda环境
conda create -n test python=3.8
提示我们没有权限
NoWritableEnvsDirError: No writeable envs directories configured.
- /home/ubuntu/.conda/envs
- /home/ubuntu/anaconda3/envs
执行
sudo chmod a+w .conda
添加完权限后再次创建cuda环境成功,然后我们为其安装pytorch
conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorch
完成后我们检测一下使用pycharm能否连接到服务器。连接成功
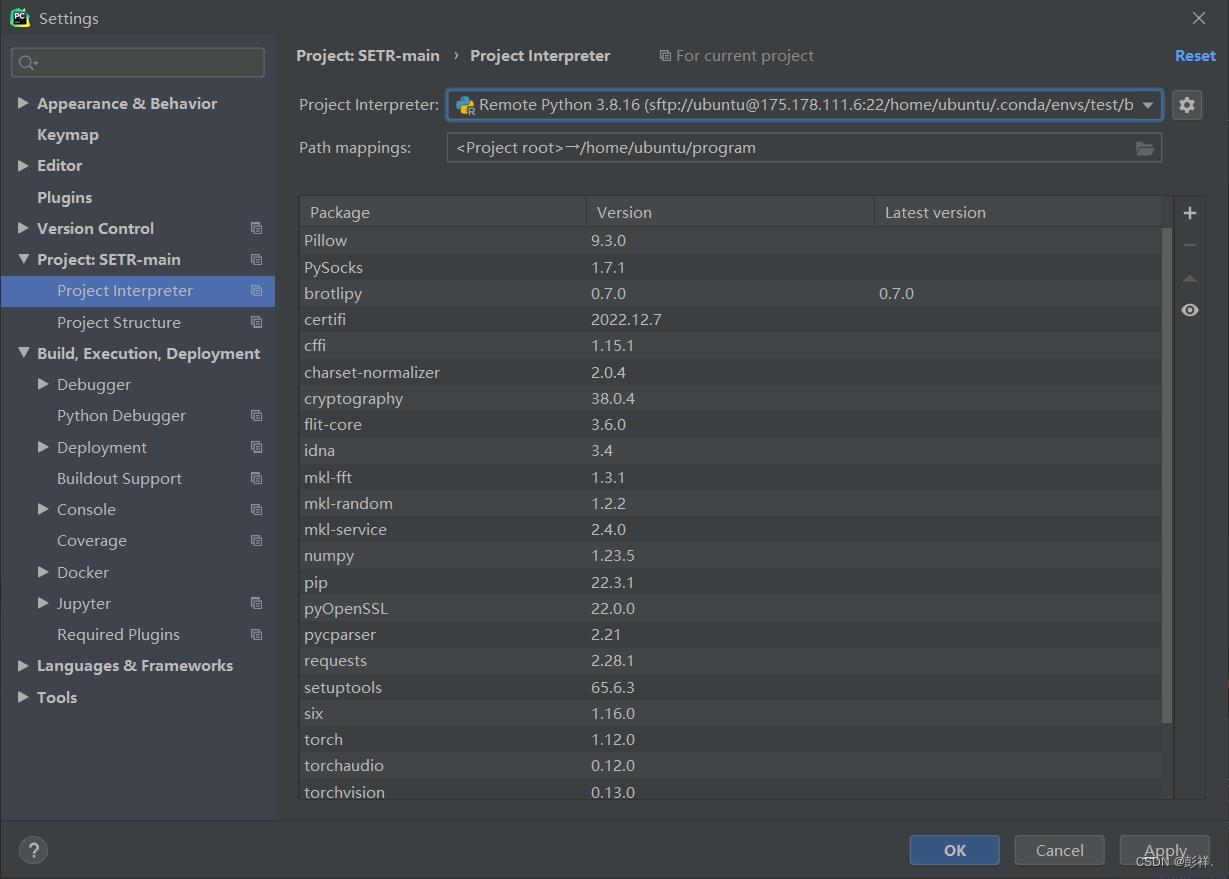
总结一下,使用服务器时千万不要自己这样一步步配置环境,实在是太麻烦了。
以上是关于GPU服务器Ubuntu环境配置教程及各种踩坑的主要内容,如果未能解决你的问题,请参考以下文章