推荐系统(二十)谷歌YouTubeDNN(Deep Neural Networks for YouTube Recommendations)
Posted 天泽28
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统(二十)谷歌YouTubeDNN(Deep Neural Networks for YouTube Recommendations)相关的知识,希望对你有一定的参考价值。
推荐系统(二十)谷歌YouTubeDNN(Deep Neural Networks for YouTube Recommendations)
推荐系统系列博客:
- 推荐系统(一)推荐系统整体概览
- 推荐系统(二)GBDT+LR模型
- 推荐系统(三)Factorization Machines(FM)
- 推荐系统(四)Field-aware Factorization Machines(FFM)
- 推荐系统(五)wide&deep
- 推荐系统(六)Deep & Cross Network(DCN)
- 推荐系统(七)xDeepFM模型
- 推荐系统(八)FNN模型(FM+MLP=FNN)
- 推荐系统(九)PNN模型(Product-based Neural Networks)
- 推荐系统(十)DeepFM模型
- 推荐系统(十一)阿里深度兴趣网络(一):DIN模型(Deep Interest Network)
- 推荐系统(十二)阿里深度兴趣网络(二):DIEN模型(Deep Interest Evolution Network)
- 推荐系统(十三)阿里深度兴趣网络(三):DSIN模型(Deep Session Interest Network)
- 推荐系统(十四)多任务学习:阿里ESMM(完整空间多任务模型)
- 推荐系统(十五)多任务学习:谷歌MMoE(Multi-gate Mixture-of-Experts )
- 推荐系统(十六)多任务学习:腾讯PLE模型(Progressive Layered Extraction model)
- 推荐系统(十七)双塔模型:微软DSSM模型(Deep Structured Semantic Models)
- 推荐系统(十八)Gate网络(一):新浪微博GateNet
- 推荐系统(十九)Gate网络(二):百度GemNN(Gating-Enhanced Multi-Task Neural Networks)
写在前面: 这篇发表在RecSys’16上的文章,距今已经有些年头了,初读这篇论文是在18年的时候,如今从实习到工作已3年多时间,再次重温,心中还是不禁感叹『经典』二字,还是那句话:『谷歌出品,必属精品』,虽然这句话不是完全的对,但适用大部分谷歌发表的paper。谷歌的paper中总是带着强烈浓厚的工业实践风,这也是我个人比较喜欢的,有些论文你看一眼模型结构图基本就领会了这篇论文的80%-90%,但YouTubeDNN这篇论文,如果你只看模型结构图,也许只能领会20%-30%。当然任何商业公司的论文都会基于保密性的出发点,在论文中隐去核心的东西,所以有时候有一些细节的隐去会导致论文晦涩难懂,YouTube这篇论文也不例外。
YouTubeDNN包含召回和排序两个模块,目前这个时间点再去按照实用价值评价YouTubeDNN的话,其召回价值大于精排价值,因为目前精排迭代的模型已经很多了,基本上不会有公司使用YouTubeDNN的精排了,其召回应该还应用的很广,目前在我们自己的业务中就有一路YouTubeDNN的召回。
本篇博客将会从三个大的方面介绍YouTubeDNN:
- YouTubeDNN召回
1.1 优化目标
1.2 样本构造
1.3 高效的训练多分类模型
1.4 YouTubeDNN召回的模型架构
1.5 YouTubeDNN召回在线 - YouTubeDNN排序
一、YouTubeDNN召回
这是本篇博客的重点,也是目前实用价值更大的一块,下面来具体谈一谈:
1.1 优化目标
YouTubeDNN召回模块没有把CTR作为优化目标,而是预测用户下一个观看的视频(next watch),也就说给定一个用户及上下文后,在候选集(所有视频)中挑选用户在下一次最可能观看的视频(next watch,这里一般是topK个),因此即转化成了一个多分类问题(数百万),这里使用一个softmax输出在所有候选视频上的概率分布。
用公式形式化的定义就是:
P
(
w
t
=
i
∣
U
,
C
)
=
e
v
i
u
∑
j
∈
V
e
v
j
u
(1)
P(w_t=i|U,C) = \\frace^v_iu\\sum_j \\in Ve^v_ju \\tag1
P(wt=i∣U,C)=∑j∈Vevjueviu(1)
其中,
U
U
U表示用户,
C
C
C表示上下文,
w
t
w_t
wt表示用户在时刻
t
t
t 观看的视频,
V
V
V表示整个视频语料库,
v
j
v_j
vj表示视频
j
j
j的embedding,
u
u
u表示用户
u
u
u的embedding。因此,公式(1)的含义为:基于用户
U
U
U和上下文
C
C
C在时间
t
t
t,预估
w
t
w_t
wt类别为
i
i
i(这个类别为整个视频语料库
V
V
V,数量在百万级别)的概率。
1.2 样本构造
再来看YouTube这里样本的构造,这里把用户看完的视频作为正样本(注意是看完的,也就是完成播放的,而不是看了的)。YouTube这里也解释了为什么没有使用YouTube上面『点赞』和『踩』这种显式反馈作为正负样本,因为使用完播这种隐式反馈所能构造出来的正样本比显式反馈的『点赞』多了一个数量级。正常情况下,用户看完一个视频去点一下『赞』这种行为是比较少的。
这里有必要说下训练样本是怎么构造的,感觉也是个非常大的细节。就拿我们自己的日志举例子吧,我们的原始日志都是item级别的(有曝光的item),一条原始日志由<item信息,用户信息,上下文信息,是否点击>组成,我们在抽取训练样本时,只抽取有点击的item,显然该点击的item就为生成的训练样本的label,然后我们需要去用户过去X天点击的item序列,用户过去X天query历史,以及一些该item相关的特征等。
YouTube这里介绍了一个trick,就是每个用户抽取的训练样本数量是相等的,这样做主要是为了防止活跃用户主导整个模型。 这是一个非常好的trick,大家可以借鉴。
此外还有个非常非常重要的点,大家可以思考下:当我们在做精排模型时,如果训练样本全都是这个模型曝光出去的item会不会有问题?
答案是显而易见的,这会导致精排模型『自嗨』也就是自我学习,它在排序的时候会非常倾向于把自己之前排出去过的再次排出去,没见过的新内容露出的可能性非常小。由此又涉及到另一个主题EE,即Explore&Expliot。YouTube这篇论文也提到了这个问题,原话如下:
Training examples are generated from all YouTube watches (even those embedded on other sites) rather than just watches on the recommendations we produce. Otherwise, it would be very difficult for new content to surface and the recom- mender would be overly biased towards exploitation.
1.3 高效的训练多分类模型
YouTube这里的类别数量达到百万的级别,采用softmax来训练显然效率很低。至于效率为什么低,似乎这个话题又回到了谷歌另一篇旷世之作word2vec论文里了,这里简单说一下,因为softmax的分母,每一次都要对语料库中所有的item计算一次。因此,word2vec里提出了两种解决办法:负采样(negative sample)和分层的softmax(hierarchical softmax)。YouTube这里并没有创新什么方法,也是在自己的场景下通过实验比较了下两种方法,最终选了一个效果比较好的方法:负采样。 提到负采样就不得不提NCE(Noise-Contrastive Estimation,噪声对比估计),负采样为NCE的一个变种,NCE通过较大化正样本的概率,同时最小化负样本的概率来优化目标函数,也就是在训练每个样本时, 负采样只挑选DNN的部分权重做小范围更新,举个例子:假设我们的视频语料库大小为1000个,一条训练样本为x=A, y=B,即输入特征A,期望的label为B,即期望B对应的那个神经元为1(最后softmax层),其余的999个神经元都应该输出0,也就是视频语料库中除了B之外的999个视频都称之为negative word,negative sample的做法是随机选择一小部分比如10个negative word来更新对应的权重参数。
1.4 YouTubeDNN召回的模型架构
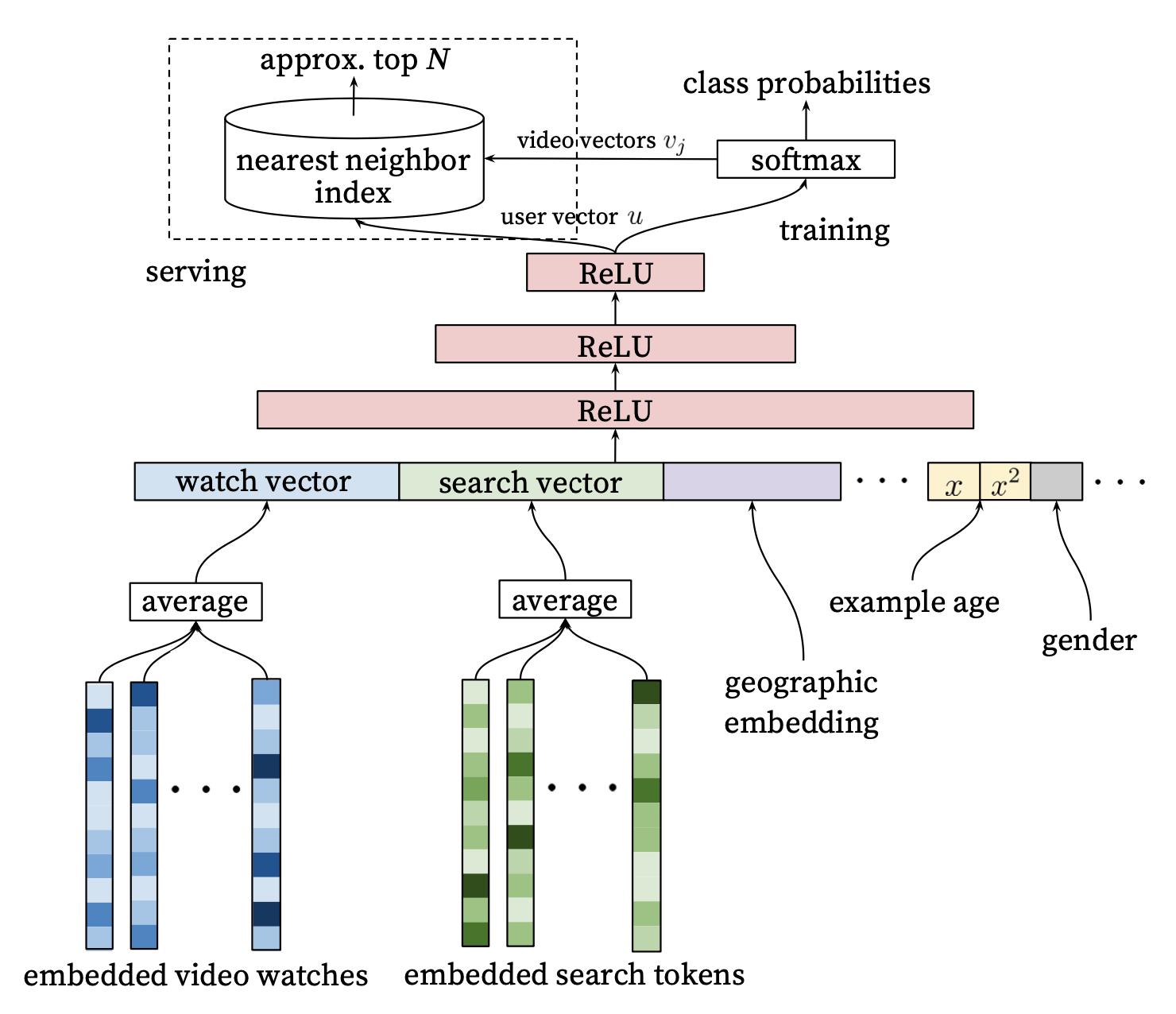
这里自底向上的看一下整体模型结构:
1.4.1 特征
这里特征大的方面就两类:类别特征和连续值特征。具体主要包含用户历史观看的视频序列,用户搜索的query切词,以及用户DMP特征。对于序列特征,比如用户历史观看的视频,分别对每个视频做完embedding后直接做了个average pooling,当然现在回过头的话你还可以做各种attention。
YouTube这里有两个trick:
- 简单的类别特征(比如年龄等二值的)以及连续值特征,直接输入,并且做了normalization压缩到[0,1]范围内,也就意味着压缩到同一量纲。
- 从模型结构图能够看出连续值特征还做了 x 2 x^2 x2等非线性转换,实验结果表明对连续值特征做非线性转换有0.2%的性能提升。
特殊特征Example Age: 这是一个非常巧妙的特征,也完全是YouTube工程师基于对自己场景深刻理解所设计的一个特征,设计这个特征的出发点是:YouTube工程师观察到YouTube平台上的用户比较喜欢新内容。关于这个example age到底怎么计算这个细节论文并没有交代的很清楚,我个人的理解加上参考了一些资料后, 认为是用当前训练时间减去label(视频item,也就是点击的那个item)的点击时间。 更详细的说,我们一般原始日志都是item级别的,即曝光的item,一条原始日志由<item信息,用户信息,上下文信息,是否点击>组成,我们在根据原始样本抽取特征生成训练样本时,这时候如果直接产出Example Age,其实就是用抽取时间减去label item的点击时间,当然也可以在训练时再产出这个特征,具体哪个方法还要看具体的效果。有个点就是在线上预估时,直接把这个特征置为0,用于确保预测时处在训练的最后一刻。
1.4.3 网络结构
虽然是一个普通的DNN,但有一个细节非常值得探讨,先来上图。
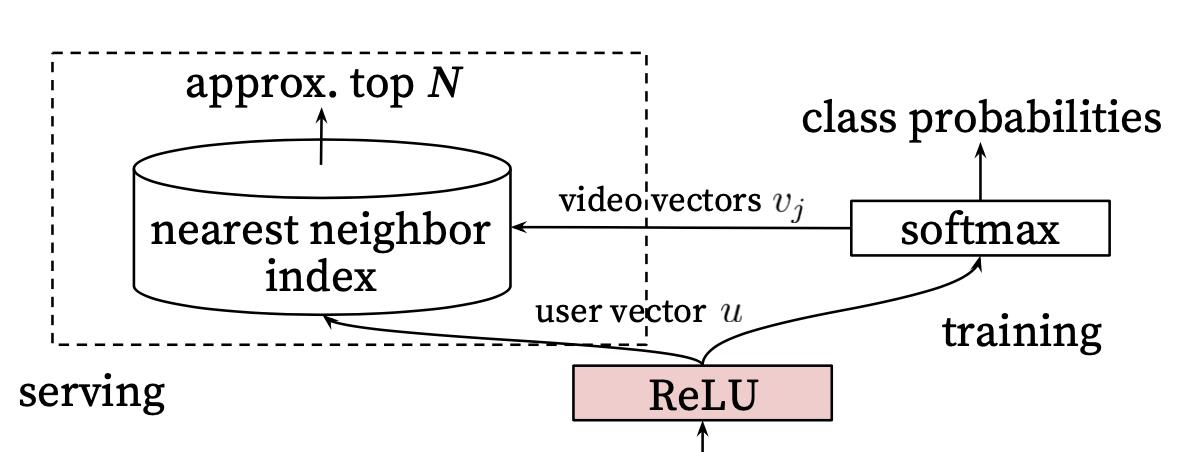
这里面涉及两个细节:
- 用户向量即 user vector u u u 是怎么生成的?
- 视频向量即 video vector v j v_j vj是怎么生成的?
目前很多很多博客文章都没有讲清楚视频向量(video vector
v
j
v_j
vj)是怎么生成的,这是一个非常重要的细节点。基于讲清楚的需要,我会重新画个图,如下图所示。
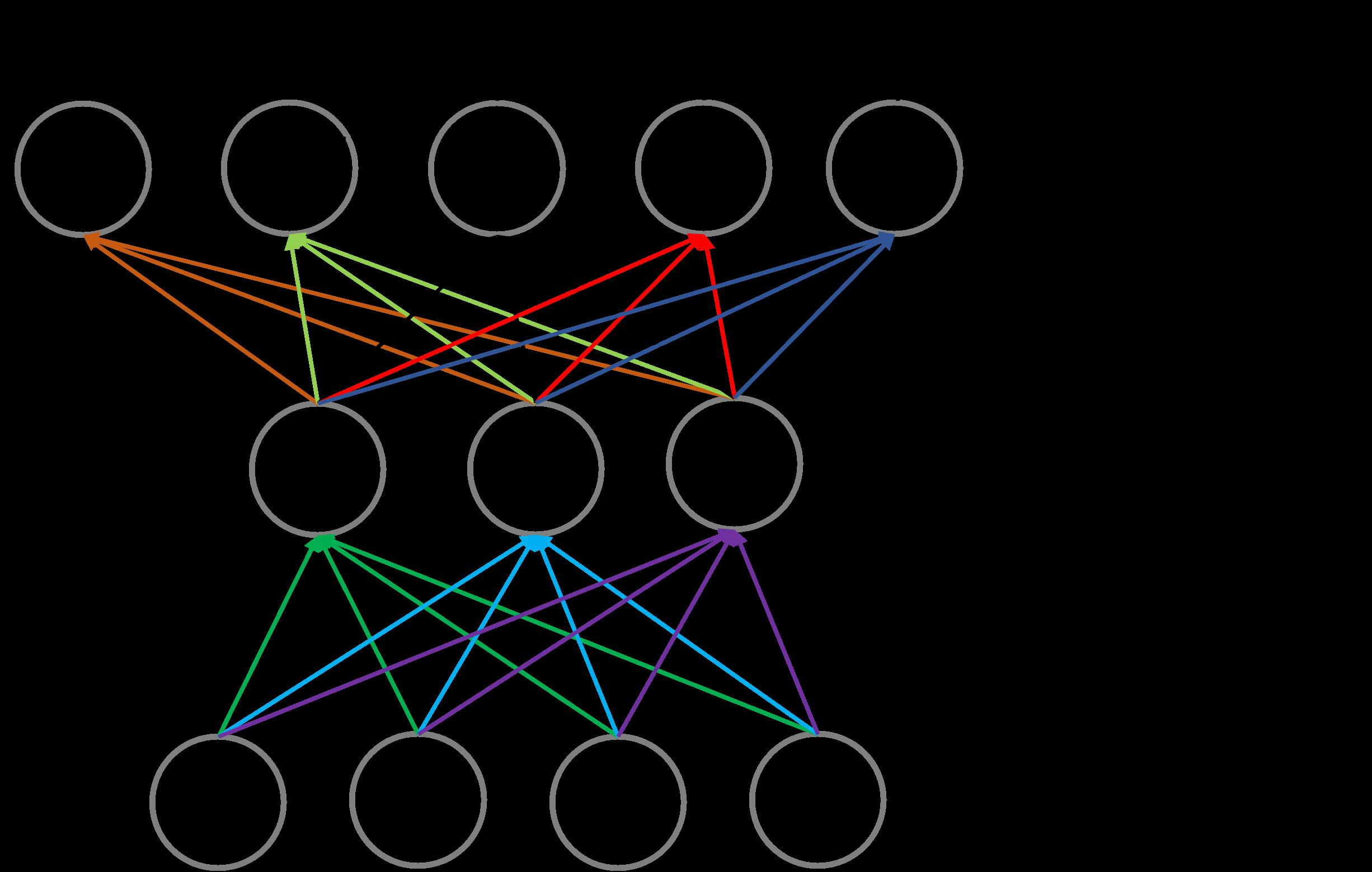
先回答一个问题:用户向量即 user vector
u
u
u 是怎么生成的?
这个问题相对简单些,根据论文中的描述就是为最后一层隐藏层的输出,用图3作为例子,则用户向量为
a
[
l
]
=
[
a
1
[
l
]
,
a
2
[
l
]
,
a
3
[
l
]
]
a^[l] = [a^[l]_1, a^[l]_2, a^[l]_3]
a[l]=[a1[l],a2[l],a3[l]],因此这里的用户向量为3维向量。
⭐再来回答第二个问题:视频向量即 video vector
v
j
v_j
vj是怎么生成的?
非常多的博客对这个问题一带而过,不知道是他们不屑讲解,还是他们也没有搞懂。最后一层隐藏层
a
[
l
]
a^[l]
a[l]与softmax层
a
[
l
+
1
]
a^[l+1]
a[l+1]之间通过参数
w
[
l
+
1
]
w^[l+1]
w[l+1]来转换,如下公式所示(
σ
\\sigma
σ为softmax函数):
a
[
l
+
1
]
=
σ
(
w
[
l
+
1
]
a
[
l
]
+
b
[
l
+
1
]
)
=
σ
(
[
w
10
[
l
+
1
]
w
11
[
l
+
1
]
w
12
[
l
+
1
]
w
20
[
l
+
1
]
w
21
[
l
+
1
]
w
22
[
l
+
1
]
w
30
[
l
+
1
]
w
31
[
l
+
1
]
w
32
[
l
+
1
]
w
40
[
l
+
1
]
w
41
[
l
+
1
]
w
42
[
l
+
1
]
w
50
[
l
+
1
]
w
51
[
l
+
1
]
w
52
[
l
+
1
]
]
⋅
[
a
1
[
l
]
a
2
[
l
]
a
3
[
l
]
]
+
[
b
1
[
l
]
b
2
[
l
]
b
3
[
l
]
]
)
(1)
\\beginaligned a^[l+1] &= \\sigma(w^[l+1]a^[l] + b^[l+1])\\\\ &= \\sigma(\\beginbmatrix w^[l+1]_10& w^[l+1]_11& w^[l+1]_12 \\\\ w^[l+1]_20& w^[l+1]_21& w^[l+1]_22 \\\\ w^[l+1]_30& w^[l+1]_31& w^[l+1]_32 \\\\ w^[l+1]_40& w^[l+1]_41& w^[l+1]_42 \\\\ w^[l+1]_50& w^[l+1]_51& w^[l+1]_52 \\\\ \\endbmatrix \\cdot \\beginbmatrix a^[l]_1\\\\ a^[l]_2 \\\\ a^[l]_3 \\\\ \\endbmatrix + \\beginbmatrix b^[l]_1\\\\ b^[l]_2 \\\\ b^[l]_3 \\\\ \\endbmatrix ) \\endaligned \\tag1
a[l+1]=σ(w[l+1]a[l]+b[l+1])=σ(