这一遍看Mybatis的原因是怀念一下去年的 10月24号我写自己第一个项目时使用全配置文件版本的MyBatis,那时我们三个人刚刚大二,说实话,当时还是觉得MyBatis挺难玩的,但是今年再看最新版的Mybatis3.5.3, 还是挺有感觉的 Mybatis的官网一级棒...
Mybatis的核心组件及其生命周期#
SqlSessionFactoryBuider:#
作用: 构建器,根据配置信息生成SqlSessionFactory
生命周期: 这个类可以被实例化、使用和丢弃,一旦创建了 SqlSessionFactory,就不再需要它了。 因此 SqlSessionFactoryBuilder 实例的最佳作用域是方法作用域(也就是局部方法变量)。 你可以重用 SqlSessionFactoryBuilder 来创建多个 SqlSessionFactory 实例,但是最好还是不要让其一直存在,以保证所有的 XML 解析资源可以被释放给更重要的事情。
SqlSessionFactory#
作用: 生成sqlSession
生命周期: SqlSessionFactory 一旦被创建就应该在应用的运行期间一直存在,没有任何理由丢弃它或重新创建另一个实例。 使用 SqlSessionFactory 的最佳实践是在应用运行期间不要重复创建多次,多次重建 SqlSessionFactory 被视为一种代码“bad smell”。因此 SqlSessionFactory 的最佳作用域是应用作用域。 有很多方法可以做到,最简单的就是使用单例模式或者静态单例模式
SqlSession#
作用: 它表示一次sql的会话,即可以去执行sql返回结果,也可以获取为mapper生成的代理对象 ,支持事物,通过commit、rollback方法提交或者回滚事物
生命周期: 每个线程都应该有它自己的 SqlSession 实例。SqlSession 的实例不是线程安全的,因此是不能被共享的,所以它的最佳的作用域是请求或方法作用域。 绝对不能将 SqlSession 实例的引用放在一个类的静态域,甚至一个类的实例变量也不行。 也绝不能将 SqlSession 实例的引用放在任何类型的托管作用域中,比如 Servlet 框架中的 HttpSession。 如果你现在正在使用一种 Web 框架,要考虑 SqlSession 放在一个和 HTTP 请求对象相似的作用域中。 换句话说,每次收到的 HTTP 请求,就可以打开一个 SqlSession,返回一个响应,就关闭它。 这个关闭操作是很重要的,你应该把这个关闭操作放到 finally 块中以确保每次都能执行关闭。
SqlMapper#
作用: : MyBatis的映射器,现在大多数都使用java接口,早前使用配置文件来描述sql查询结果和java对象之间的映射规则 定义参数类型, 描述缓存,描述SQL语句 ,定义查询结果和POJO的映射关系
生命周期: 最好把映射器放在方法作用域内
基于XML版本的环境搭建测试#
基于xml版本,搭建mybatis开发环境中,存在一个主配置文件,和多个子配置文件,主配置文件中配置数据库相关的信息, 而子配置文件中配置的是单个Dao接口层中的抽象方法对应的sql语句
主配置文件如下
需要注意的地方,下面的<mapper >标签中resource属性存放的是从配置文件的路径,但是从配置文件的目录信息得和src中相应的接口位于相同的目录
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!--mybatis的主配置文件-->
<configuration>
<!--配置环境-->
<environments default="mysql">
<!--配置mysql的环境-->
<environment id="mysql">
<!--配置事务的类型-->
<transactionManager type="JDBC"/>
<!--配置数据源-->
<!--dataSource存在三个, 其中的POOLED池化的连接池-->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/trymybatis"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<!--指定映射配置文件的位置,也就是针对每个Dao的配置文件的位置-->
<!--下面指定的xml配置文件的路径,需要和src下IUserDao接口的目录保持一致-->
<mappers>
<mapper resource="com/changwu/dao/IUserDao.xml"/>
</mappers>
</configuration>从配置文件
需要注意的地方: 命名空间是全类名,id是方法名,返回值是全类名
还有一点就是,单个mapper标签中,namespace和id都不能少,两者合在一起才能确定一个全局唯一的方法,至于为什么我们配置一个接口就ok,而不用添加配置文件,那是因为Mybatis会使用代理技术,为接口生成代理对象,让程序员使用代理对象
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace是全类名-->
<mapper namespace="com.changwu.dao.IUserDao">
<!--
id为方法名
resultType为返回值个体的封装类
-->
<select id="findAll" resultType="com.changwu.pojo.User">
select * from user
</select>
</mapper>其他数据源的配置方式
把如下的配置放在resourse目录下面
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/trymybatis
jdbc.username=root
jdbc.password=root然后将主配置文件改成下面这样
当然也可以在<properties>标签中使用url但是需要遵循url协议的规范
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!--mybatis的主配置文件-->
<configuration>
<properties resource="jdbcConfig.properties"> </properties>
<!--配置环境-->
<environments default="mysql">
<!--配置mysql的环境-->
<environment id="mysql">
<!--配置事务的类型-->
<transactionManager type="JDBC"/>
<!--配置数据源-->
<!--dataSource存在三个, 其中的POOLED池化的连接池-->
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<!--指定映射配置文件的位置,也就是针对每个Dao的配置文件的位置-->
<!--下面指定的xml配置文件的路径,需要和src下IUserDao接口的目录保持一致-->
<mappers>
<mapper class="com.changwu.dao.IUserDao"/>
</mappers>
</configuration>编码测试类
@Test
public void text01() {
try {
// 1. 读取配置文件
InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-config.xml");
// 2. 创建SqlSessionFactory工厂
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(resourceAsStream);
// 3. 创建sqlSession
SqlSession sqlSession = factory.openSession();
// 4. SqlSession 完全包含了面向数据库执行 SQL 命令所需的所有方法
// 使用正确描述每个语句的参数和返回值的接口(比如 BlogMapper.class),
// 你现在不仅可以执行更清晰和类型安全的代码,而且还不用担心易错的字符串字面值以及强制类型转换
IUserDao userDao = sqlSession.getMapper(IUserDao.class);
// 5. 执行方法
List<User> all = userDao.findAll();
for (User user : all) {
System.out.println(user.getUsername());
}
// 6, 释放资源
sqlSession.close();
resourceAsStream.close();
} catch (Exception e) {
e.printStackTrace();
}
}基于注解版本的环境搭建测试#
因为现在依然是MyBatis孤军深入,没有和Spring,Springboot等框架进行整合,因此上面说的那个主配置文件无论如果都不能缺失,不像SpringBoot那样一个@MapperScan("XXX")就完成扫描整合这么给力
基于注解的开发模式,我们可以轻易进一步去除单个dao层的接口对应的xml配置文件,取代之的是注解,三步:
- 第一步: 删除原来的子配置文件的目录
- 第二步: 在dao层接口使用注解开发
@Select("select * from user")
List<User> findAll();- 第三步: 修改部分主配置文件
<mappers>
<mapper class="com.changwu.dao.IUserDao"/>
</mappers>常用的注解#
- @Results
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Results {
// 因为当前的Results注解中存在实例的描述,使用id标识当前的map,实现给 @resultMap 的复用
String id() default "";
Result[] value() default {};
}- @Result
继续看看这个@Result注解,如下: 这个注解拥有xml中的resultMap中大部分的属性
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({})
public @interface Result {
boolean id() default false;
// 表中的列名
String column() default "";
// java实体类中的属性名
String property() default "";
// 实体类型
Class<?> javaType() default void.class;
JdbcType jdbcType() default JdbcType.UNDEFINED;
Class<? extends TypeHandler> typeHandler() default UnknownTypeHandler.class;
// 实体之间的关系为1对1
One one() default @One;
// 实体之间的关系为1对多
Many many() default @Many;
}- @One
跟进@One注解, 他是对select属性的封装, FetchType是一个枚举,三种值,分别是LAZY, EAGER, DEFAULT
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({})
public @interface One {
String select() default "";
FetchType fetchType() default FetchType.DEFAULT;
}- @Many
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({})
public @interface Many {
String select() default "";
FetchType fetchType() default FetchType.DEFAULT;
}- @ResultMap
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface ResultMap {
String[] value();
}类型别名#
原来在xml版本配置mapper时,会使用parameterType属性指定程序员提供的类的全类名,但是这个全类名真的太长了,于是MyBatis官方提供了给全类名取别名的标签,在Mybatis的主配置文件中添加如下的配置,如下:
<typeAliases>
<typeAlias alias="user" type="com.changwu.pojo.User"/>
</typeAliases>添加了全类名的配置之后,我们的在mapper中就可以使用别名了,如下: 并且在windows系统下不区分大小写
<update id="updateUser" parameterType="UsEr">
update user set username=#{username},birthday=#{birthday},sex=#{sex},address=#{address} where id = #{id}"
</update>但是像上面这样,为每一个POJO都添加上别名的配置,确实显得有点麻烦,于是可以像下面这样,为一整个包下面的类名配置别名, 别名就是类名不区分大小写的格式
<typeAliases>
<package alias="user" type="com.changwu.pojo"/>
</typeAliases>公共sql的抽取#
一处抽取,多处使用
<sql id="findUsers">
select * form user;
</sql>
<select id="findAll" resultType="com.changwu.pojo.User">
<include refid="findUsers"></include>
</select>优先级#
MyBatis支持的3种配置方式, 编码>properties配置文件>property元素标签, 优先级如下:
- 在properties配置文件中指定的配置文件的属性首先被读取
- 根据配置文件中的resources属性读取类路径下的属性文件,或者根据url属性读取属性文件并会覆盖同名属性
- 读取作为方法参数传递的属性,并覆盖已经读取的同名属性
不要混合使用xml版和注解版两种开发模式,否则Mybatis启动不了
MyBytais中的参数类型的封装#
在使用注解版做开发时,我们会在每个mapper中标记好入参的类型
简单类型#
MyBattis的参数传递是支持简单类型的,比如下面这种
<delete id="deleteUserById" parameterType="java.lang.Integer">
delete from user where id = #{id}
</delete>传递pojo对象#
看下面的代码和配置, 在编写sql时,我们直接指定参数的类型的Pojo对象
@Update({"update user set username=#{username},birthday=#{birthday},sex=#{sex},address=#{address} where id = #{id}"})
void updateUser(User user);还有这种配置
<update id="updateUser" parameterType="com.changwu.pojo.User">
update user set username=#{username},birthday=#{birthday},sex=#{sex},address=#{address} where id = #{id}"
</update>那么,myBatis如何解析我们传递的pojo对象呢? 答案是使用ojnl(Object graphic navigation Language) 对象图导航语言, 实际是底层是通过对象的方法来获取数据,但是在写法上却省略了getXXX
比如: 我们想获取username, 按理说这样写user.getUserName() 但是在ojnl表达式来说表达成 user.username, 于是我们就可以在sql中直接写上pojo中字段的属性名,MyBatis会自动完成从对象中,取值解析
注意点就是说,得sql中属性的顺序和pojo中属性的生命顺序保持一致,否则存进去的就是乱序的数值
传递pojo包装后的对象#
开发中可能会有各种各样的查询条件,其中,很多时候用来查询的条件不是简单的数据类型,而是一类对象, 举个例子: 如下
根据另一个封装类去查询用户列表,其中的QueryVo并不是持久化在数据库中的对象,而是某几个字段封装类,于是我们像下面这样传递值
@Select("select * from user where username = #{user.username}")
List<User> findUserByQueryVo(QueryVo vo);xml版本
<select id="findByQueryVo" paramterType="com.changwu.vo.QueryVo" resultType="com.changwo.pojo.User">
select * from user where username like #{user.username}
</select>
注意点: 传递pojo的包装类是有限制的, 在下面取值时,强制程序员不能把名字写错
user == vo对象中的属性名user
username == vo对象中的属性user中的属性名username
MyBytais中的结果类型的封装#
基于XML的resultMap#
前面的实验中,我们的pojo字段名和数据表中列表保持百分百一致,所以我们在resultType标签中使用com.changwu.pojo.User接收返回的数据时才没出任何差错,但是一般在现实的开发中,同时使用数据库的列名的命名风格和java的驼峰命名法,然而,当我们的pojo的属性名个sql中的列表不一致时, Mybatis是不能完成两者的赋值的
- 解决方法1: 取别名
注解版本的,默认支持驼峰命名法,意思和忽略大小写擦不多,但是如果两者名字忽略大小写之后还不一样就真的得配置取别名了
@Select("select * from user")
@Select("select id as userId from user")<select id="findAll" resultType="com.changwu.pojo.User">
select id as userId from user;
</select>- 解决方法2: 使用配置
resultMap如下:- id为当前resultMap的唯一身份标识
- type表示查询的实体类是哪个实体类
- property为java中的实体类属性名
- column为数据库中列名
- 在
select标签中去除掉原来的resultType,取而代之的是resultMap
<resultMap id="userMap" type="com.changwu.pojo.User">
<id property="userId" column="id"></id>
<result property="userName" column="username"></result>
</resultMap>
<select id="findAll" resultMap="userMap">
select id as userId from user;
</select>解决方法3: 开启驼峰命名配置
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
<setting name="useGeneratedKeys" value="true"/>
</settings>
</configuration>但是如果两个字段的差异已经不是驼峰命名法可以解决的了,就只能去配置别名了
基于注解实现resultMap#
当实体类中的属性和表中的字段命名出现严重不一致时,我们使用通过注解解决此类问题
同样property中是java对象中的属性, column为表中的列名
通过@Results中的id属性值,使其他方法可以通过@ResultMap复用已经存在的映射关系
@Select("select * from user")
@Results(id = "userMap",value = {
@Result(id = true,property = "",column = ""),
@Result(id = true,property = "",column = ""),
@Result(id = true,property = "",column = ""),
@Result(id = true,property = "",column = ""),
})
List<User> findAll();
@Select("select * from user where id = #{id}")
@ResultMap(value = {"userMap"})
User findById(Integer id);MyBatis的数据连接池#
如何配置#
在如下Mybatis主配置文件中的<dataSource type="POOLED">
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!--mybatis的主配置文件-->
<configuration>
<properties resource="jdbcConfig.properties"> </properties>
<!--配置环境-->
<environments default="mysql">
<!--配置mysql的环境-->
<environment id="mysql">
<!--配置事务的类型-->
<transactionManager type="JDBC"/>
<!--配置数据源-->
<!--dataSource存在三个, 其中的POOLED池化的连接池-->
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<!--指定映射配置文件的位置,也就是针对每个Dao的配置文件的位置-->
<!--下面指定的xml配置文件的路径,需要和src下IUserDao接口的目录保持一致-->
<mappers>
<mapper class="com.changwu.dao.IUserDao"/>
</mappers>
</configuration>POOLED#
采用传统的javax.sql.DataSource规范中的连接池,这种数据源的实现利用“池”的概念将 JDBC 连接对象组织起来,避免了创建新的连接实例时所必需的初始化和认证时间。 这是一种使得并发 Web 应用快速响应请求的流行处理方式。
特点: 使用完了的连接会被回收,而不是被销毁
其他相应的属性
- poolMaximumActiveConnections : 任意时间正在使用的连接数量,默认为10
- poolMaximumIdleConnections : 任意事件可能存在的空闲连接数
- poolMaximumCheckoutTime : 在被强制返回之前,池中连接被检出(checked out)时间,默认值:20000 毫秒(即 20 秒)
- poolTimeToWait: 默认是20秒, 如果花费了20秒还没有获取到连接,就打印日志然后重新尝试获取
- poolMaximumLocalBadConnectionTolerance : 就是如果当前的线程从连接池中获取到了一个坏的连接,数据源会允许他重新获取一次,但是重新尝试的次数不能超过 poolMaximumIdleConnections 与 poolMaximumLocalBadConnectionTolerance 之和。 默认值:3 (新增于 3.4.5)
- poolPingQuery: 用来检验连接是否正常工作并准备接受请求。默认是“NO PING QUERY SET”,这会导致多数数据库驱动失败时带有一个恰当的错误消息
- poolPingEnabled: 是否启用侦测查询。若开启,需要设置 poolPingQuery 属性为一个可执行的 SQL 语句(最好是一个速度非常快的 SQL 语句),默认值:false。
- poolPingConnectionsNotUsedFor : 配置 poolPingQuery 的频率。可以被设置为和数据库连接超时时间一样,来避免不必要的侦测,默认值:0(即所有连接每一时刻都被侦测 — 当然仅当 poolPingEnabled 为 true 时适用)。
它的实现类是PooledDataSource, 看下它的继承体系图如下,它实现javax.sql的接口规范
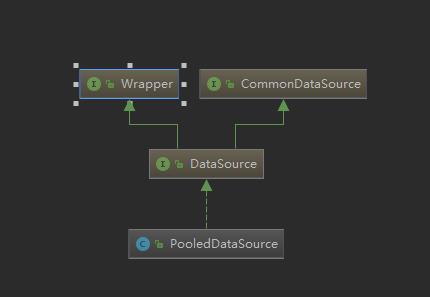
我们看下它的获取连接的实现代码如下: 可以看到,从他里面获取新的连接,不是无脑new, 而是受到最大连接数,空闲连接数,当前活跃数,工作连接数等因素的限制
private PooledConnection popConnection(String username, String password) throws SQLException {
boolean countedWait = false;
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
while (conn == null) {
// 通过同步代码块保证了线程的安全性,因为现实环境中,多用户并发请求获取连接
synchronized (state) {
// 如果空闲的连接数不为空,就使用从空闲池中往外拿连接
if (!state.idleConnections.isEmpty()) {
// Pool has available connection
conn = state.idleConnections.remove(0);
if (log.isDebugEnabled()) {
log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
}
} else {
// 没有空闲
// Pool does not have available connection
if (state.activeConnections.size() < poolMaximumActiveConnections) {
// 活动的连接池的最大数量 比 预先设置的最大连接数小, 就创建新的连接
// Can create new connection
conn = new PooledConnection(dataSource.getConnection(), this);
if (log.isDebugEnabled()) {
log.debug("Created connection " + conn.getRealHashCode() + ".");
}
} else {
// 判断最先进入 活跃池中的连接,设置新的参数然后返回出去
// Cannot create new connection
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
if (longestCheckoutTime > poolMaximumCheckoutTime) {
// Can claim overdue connection
state.claimedOverdueConnectionCount++;
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
state.activeConnections.remove(oldestActiveConnection);
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
try {
oldestActiveConnection.getRealConnection().rollback();
} catch (SQLException e) {
log.debug("Bad connection. Could not roll back");
}
}
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
oldestActiveConnection.invalidate();
if (log.isDebugEnabled()) {
log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
}
} else {
// Must wait
try {
if (!countedWait) {
state.hadToWaitCount++;
countedWait = true;
}
if (log.isDebugEnabled()) {
log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
}
long wt = System.currentTimeMillis();
state.wait(poolTimeToWait);
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
} catch (InterruptedException e) {
break;
}
}
}
}
if (conn != null) {
// ping to server and check the connection is valid or not
if (conn.isValid()) {
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
} else {
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
}
state.badConnectionCount++;
localBadConnectionCount++;
conn = null;
if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Could not get a good connection to the database.");
}
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
}
}
return conn;
}UNPOOLED#
这个数据源的实现只是每次被请求时打开和关闭连接。虽然有点慢,但对于在数据库连接可用性方面没有太高要求的简单应用程序来说,是一个很好的选择。 不同的数据库在性能方面的表现也是不一样的,对于某些数据库来说,使用连接池并不重要,这个配置就很适合这种情形。UNPOOLED 类型的数据源具有以下属性。
它存在如下的配置信息
- driver – 这是 JDBC 驱动的 Java 类的完全限定名(并不是 JDBC 驱动中可能包含的数据源类)。
- url – 这是数据库的 JDBC URL 地址。
- username – 登录数据库的用户名。
- password – 登录数据库的密码。
- defaultTransactionIsolationLevel – 默认的连接事务隔离级别。
- defaultNetworkTimeout – The default network timeout value in milliseconds to wait for the database operation to complete. See the API documentation of java.sql.Connection#setNetworkTimeout() for details.
作为可选项,你也可以传递属性给数据库驱动。只需在属性名加上“driver.”前缀即可,例如:
driver.encoding=UTF8
这将通过 DriverManager.getConnection(url,driverProperties) 方法传递值为 UTF8 的 encoding 属性给数据库驱动。
它的实现类是UnpooledDataSource, 看下它的继承体系图如下,它实现javax.sql的接口规范

我们看下它对获取连接的实现代码如下: 每一次获取连接都使用jdk底层的加载驱动,创建新的连接给用户使用
private Connection doGetConnection(Properties properties) throws SQLException {
initializeDriver();
Connection connection = DriverManager.getConnection(url, properties);
configureConnection(connection);
return connection;
}
private synchronized void initializeDriver() throws SQLException {
if (!registeredDrivers.containsKey(driver)) {
Class<?> driverType;
try {
if (driverClassLoader != null) {
driverType = Class.forName(driver, true, driverClassLoader);
} else {
driverType = Resources.classForName(driver);
}
// DriverManager requires the driver to be loaded via the system ClassLoader.
// http://www.kfu.com/~nsayer/Java/dyn-jdbc.html
Driver driverInstance = (Driver)driverType.newInstance();
DriverManager.registerDriver(new DriverProxy(driverInstance));
registeredDrivers.put(driver, driverInstance);
} catch (Exception e) {
throw new SQLException("Error setting driver on UnpooledDataSource. Cause: " + e);
}
}
}JNDI#
作为了解吧,这个数据源的实现是为了能在如 EJB 或应用服务器这类容器中使用,容器可以集中或在外部配置数据源,然后放置一个 JNDI 上下文的引用.
MyBatis中的事务管理器#
MyBatis中存在两种事务管理器如下:
JDBC#
xml配置
<transactionManager type="JDBC">
<property name="closeConnection" value="false"/>
</transactionManager>这个配置就是直接使用了 JDBC 的提交和回滚设置,它依赖于从数据源得到的连接来管理事务作用域。
相关编码的实现: 它通过sqlSession对象的commit方法,和rollback方法实现事务的提交和回滚
设置自动提交,使用openSession()重载的方法
// 1. 读取配置文件
InputStream resourceAsStream = Resources.getResourceAsStream("SqlMapConfig.xml");
// 2. 创建SqlSessionFactory工厂
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(resourceAsStream);
// 3. 创建sqlSession
SqlSession sqlSession = factory.openSession(true);MANAGED#
这个配置几乎没做什么。它从来不提交或回滚一个连接,而是让容器来管理事务的整个生命周期,默认情况下它会关闭连接,然而一些容器并不希望这样,因此需要将 closeConnection 属性设置为 false 来阻止它默认的关闭行为
<transactionManager type="MANAGED">
<property name="closeConnection" value="false"/>
</transactionManager>如果你正在使用 Spring + MyBatis,则没有必要配置事务管理器, 因为 Spring 模块会使用自带的管理器来覆盖前面的配置
动态SQL#
MyBatis的动态sql为我们提供了什么功能呢? 举一个相似的场景,就是用户提交了username password 两个字段的信息到后端, 后端进行下一步校验,然后后端的程序员可能就的通过自己拼接sql来完成这个功能 类似这样select * from user where username = + username + and password = +password ,一个两个没事, 这是一个痛苦的事, 例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号
动态sql解决了这个问题
虽然在以前使用动态 SQL 并非一件易事,但正是 MyBatis 提供了可以被用在任意 SQL 映射语句中的强大的动态 SQL 语言得以改进这种情形。
if#
最常用的一种是,将对象中满足if条件的字段当成sql中where的条件
举个例子,当用户名不为空时,按照用户名查找
<select id="findUserByCondition" resultType="com.changwu.pojo.User" parameterType="com.changwu.pojo.User">
select * from user where 1=1
<if test="userName != null">
and username = #{userName}
</if>
</select>choose (when, otherwise)前端开发必备!Emmet使用手册(转自 http://www.w3cplus.com/tools/emmet-cheat-sheet.html)
阿里首发272页MyBatis源码手册,看后发现差距不止一点