mybatis知识总结
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mybatis知识总结相关的知识,希望对你有一定的参考价值。
基于昨天的mybatis入门详解,今天我们再来看看mybatis稍微高深些的知识点.
1.解决Model属性和数据库字段不一致的问题
1),开启驼峰命名
2),使用resultMap进行映射,

<!-- 映射 --> <resultMap id="userMap" type="User"> <result column="id" property="id" /> <result column="user_name" property="userName" /> <result column="name" property="name" /> <result column="age" property="age" /> <result column="sex" property="sex" /> <result column="password" property="password" /> </resultMap> <!-- 这里使用的是resultMap,而不是resultType, id要保持一致; --> <select id="queryUserByUserName" resultMap="userMap"> SELECT *, user_name userName FROM tb_user WHERE user_name = #{userName} </select> <!-- <select id="queryUserByUserName" resultType="com.j1.jdbc.Model.User"> --> <!-- SELECT *, user_name userName FROM tb_user WHERE user_name = #{userName} --> <!-hui- </select> -->
映射的初步应用就讲完了,接下来,我们看下mybatis的缓存机制,以及它与hibernate的区别(重要,面试会用到哦)
缓存机制,在我的另一篇博客里有专门的博客介绍,在这里我再巩固一下.
mybatis的缓存:
一级缓存:
作用域是session,当sqlSession.openSession()后开始执行,当参数,和sql语句相同时,会在控制台打印一条sql,再次执行的时候,或从缓存中命中,控制台不会再打印sql语句,当参数,sql,活着session关闭时,会重新打印一条新的sql语句.
注意,在insert,update,delete时会刷新sql.
原理:
Mybatis执行查询时首先去缓存区命中,如果命中直接返回,没有命中则执行SQL,从数据库中查询。
使用session.clearCache()强制查询不缓存。
二级缓存:
作用域是mapper的namespace,同一个namespace中查询sql可以从缓存中命中的,
二级缓存是可以跨session的,在mapper.xml中加入<cache/>表示开启二级缓存.
如何关闭二级缓存呢?
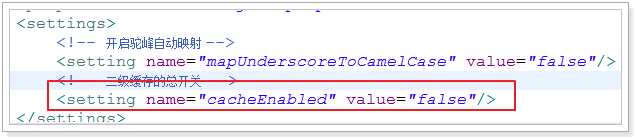
默认是开启的;
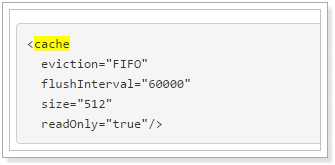
1.1.1. 二级缓存的高级配置

至此,mybatis的缓存机制就讲完了,下面,我们来讨论一下,
mybatis与hibernate的区别:
第一方面:开发速度的对比
就开发速度而言,Hibernate的真正掌握要比Mybatis来得难些。Mybatis框架相对简单很容易上手,但也相对简陋些。个人觉得要用好Mybatis还是首先要先理解好Hibernate。
比起两者的开发速度,不仅仅要考虑到两者的特性及性能,更要根据项目需求去考虑究竟哪一个更适合项目开发,比如:一个项目中用到的复杂查询基本没有,就是简单的增删改查,这样选择hibernate效率就很快了,因为基本的sql语句已经被封装好了,根本不需要你去写sql语句,这就节省了大量的时间,但是对于一个大型项目,复杂语句较多,这样再去选择hibernate就不是一个太好的选择,选择mybatis就会加快许多,而且语句的管理也比较方便。
第二方面:开发工作量的对比
Hibernate和MyBatis都有相应的代码生成工具。可以生成简单基本的DAO层方法。针对高级查询,Mybatis需要手动编写SQL语句,以及ResultMap。而Hibernate有良好的映射机制,开发者无需关心SQL的生成与结果映射,可以更专注于业务流程。
第三方面:sql优化方面
Hibernate的查询会将表中的所有字段查询出来,这一点会有性能消耗。Hibernate也可以自己写SQL来指定需要查询的字段,但这样就破坏了Hibernate开发的简洁性。而Mybatis的SQL是手动编写的,所以可以按需求指定查询的字段。
Hibernate HQL语句的调优需要将SQL打印出来,而Hibernate的SQL被很多人嫌弃因为太丑了。MyBatis的SQL是自己手动写的所以调整方便。但Hibernate具有自己的日志统计。Mybatis本身不带日志统计,使用Log4j进行日志记录。
第四方面:对象管理的对比
Hibernate 是完整的对象/关系映射解决方案,它提供了对象状态管理(state management)的功能,使开发者不再需要理会底层数据库系统的细节。也就是说,相对于常见的 JDBC/SQL 持久层方案中需要管理 SQL 语句,Hibernate采用了更自然的面向对象的视角来持久化 Java 应用中的数据。
换句话说,使用 Hibernate 的开发者应该总是关注对象的状态(state),不必考虑 SQL 语句的执行。这部分细节已经由 Hibernate 掌管妥当,只有开发者在进行系统性能调优的时候才需要进行了解。而MyBatis在这一块没有文档说明,用户需要对对象自己进行详细的管理。
第五方面:缓存机制
Hibernate缓存
Hibernate一级缓存是Session缓存,利用好一级缓存就需要对Session的生命周期进行管理好。建议在一个Action操作中使用一个Session。一级缓存需要对Session进行严格管理。
Hibernate二级缓存是SessionFactory级的缓存。 SessionFactory的缓存分为内置缓存和外置缓存。内置缓存中存放的是SessionFactory对象的一些集合属性包含的数据(映射元素据及预定SQL语句等),对于应用程序来说,它是只读的。外置缓存中存放的是数据库数据的副本,其作用和一级缓存类似.二级缓存除了以内存作为存储介质外,还可以选用硬盘等外部存储设备。二级缓存称为进程级缓存或SessionFactory级缓存,它可以被所有session共享,它的生命周期伴随着SessionFactory的生命周期存在和消亡。
MyBatis缓存
MyBatis 包含一个非常强大的查询缓存特性,它可以非常方便地配置和定制。MyBatis 3 中的缓存实现的很多改进都已经实现了,使得它更加强大而且易于配置。
默认情况下是没有开启缓存的,除了局部的 session 缓存,可以增强变现而且处理循环 依赖也是必须的。要开启二级缓存,你需要在你的 SQL 映射文件中添加一行: <cache/>
字面上看就是这样。这个简单语句的效果如下:
- 映射语句文件中的所有 select 语句将会被缓存。
- 映射语句文件中的所有 insert,update 和 delete 语句会刷新缓存。
- 缓存会使用 Least Recently Used(LRU,最近最少使用的)算法来收回。
- 根据时间表(比如 no Flush Interval,没有刷新间隔), 缓存不会以任何时间顺序 来刷新。
- 缓存会存储列表集合或对象(无论查询方法返回什么)的 1024 个引用。
- 缓存会被视为是 read/write(可读/可写)的缓存,意味着对象检索不是共享的,而 且可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
所有的这些属性都可以通过缓存元素的属性来修改。
比如: <cache eviction=”FIFO” flushInterval=”60000″ size=”512″ readOnly=”true”/>
这个更高级的配置创建了一个 FIFO 缓存,并每隔 60 秒刷新,存数结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此在不同线程中的调用者之间修改它们会 导致冲突。可用的收回策略有, 默认的是 LRU:
- LRU – 最近最少使用的:移除最长时间不被使用的对象。
- FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
- SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
- WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
flushInterval(刷新间隔)可以被设置为任意的正整数,而且它们代表一个合理的毫秒 形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的 可用内存资源数目。默认值是1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓 存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存 会返回缓存对象的拷贝(通过序列化) 。这会慢一些,但是安全,因此默认是 false。
相同点:Hibernate和Mybatis的二级缓存除了采用系统默认的缓存机制外,都可以通过实现你自己的缓存或为其他第三方缓存方案,创建适配器来完全覆盖缓存行为。
不同点:Hibernate的二级缓存配置在SessionFactory生成的配置文件中进行详细配置,然后再在具体的表-对象映射中配置是那种缓存。
MyBatis的二级缓存配置都是在每个具体的表-对象映射中进行详细配置,这样针对不同的表可以自定义不同的缓存机制。并且Mybatis可以在命名空间中共享相同的缓存配置和实例,通过Cache-ref来实现。
两者比较:因为Hibernate对查询对象有着良好的管理机制,用户无需关心SQL。所以在使用二级缓存时如果出现脏数据,系统会报出错误并提示。
而MyBatis在这一方面,使用二级缓存时需要特别小心。如果不能完全确定数据更新操作的波及范围,避免Cache的盲目使用。否则,脏数据的出现会给系统的正常运行带来很大的隐患。
第六方面:总结
对于总结,大家可以到各大java论坛去看一看
相同点:Hibernate与MyBatis都可以是通过SessionFactoryBuider由XML配置文件生成SessionFactory,然后由SessionFactory 生成Session,最后由Session来开启执行事务和SQL语句。其中SessionFactoryBuider,SessionFactory,Session的生命周期都是差不多的。
- Hibernate和MyBatis都支持JDBC和JTA事务处理。
Mybatis优势
- MyBatis可以进行更为细致的SQL优化,可以减少查询字段。
- MyBatis容易掌握,而Hibernate门槛较高。
Hibernate优势
- Hibernate的DAO层开发比MyBatis简单,Mybatis需要维护SQL和结果映射。
- Hibernate对对象的维护和缓存要比MyBatis好,对增删改查的对象的维护要方便。
- Hibernate数据库移植性很好,MyBatis的数据库移植性不好,不同的数据库需要写不同SQL。
- Hibernate有更好的二级缓存机制,可以使用第三方缓存。MyBatis本身提供的缓存机制不佳。
他人总结
- Hibernate功能强大,数据库无关性好,O/R映射能力强,如果你对Hibernate相当精通,而且对Hibernate进行了适当的封装,那么你的项目整个持久层代码会相当简单,需要写的代码很少,开发速度很快,非常爽。
- Hibernate的缺点就是学习门槛不低,要精通门槛更高,而且怎么设计O/R映射,在性能和对象模型之间如何权衡取得平衡,以及怎样用好Hibernate方面需要你的经验和能力都很强才行。
- iBATIS入门简单,即学即用,提供了数据库查询的自动对象绑定功能,而且延续了很好的SQL使用经验,对于没有那么高的对象模型要求的项目来说,相当完美。
- iBATIS的缺点就是框架还是比较简陋,功能尚有缺失,虽然简化了数据绑定代码,但是整个底层数据库查询实际还是要自己写的,工作量也比较大,而且不太容易适应快速数据库修改。
mybatis的高级查询,为了能更好的说服问题,在此之前先贴上建表语句,
/* Navicat mysql Data Transfer Source Server : 127.0.0.1 Source Server Version : 50619 Source Host : 127.0.0.1:3306 Source Database : mybatis_test Target Server Type : MYSQL Target Server Version : 50619 File Encoding : 65001 Date: 2014-11-27 11:00:43 */ SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for tb_item -- ---------------------------- DROP TABLE IF EXISTS `tb_item`; CREATE TABLE `tb_item` ( `id` int(11) NOT NULL AUTO_INCREMENT, `item_name` varchar(32) NOT NULL COMMENT ‘商品名称‘, `item_price` float(6,1) NOT NULL COMMENT ‘商品价格‘, `item_detail` text COMMENT ‘商品描述‘, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of tb_item -- ---------------------------- INSERT INTO `tb_item` VALUES (‘1‘, ‘iPhone 6‘, ‘5288.0‘, ‘苹果公司新发布的手机产品。‘); INSERT INTO `tb_item` VALUES (‘2‘, ‘iPhone 6 plus‘, ‘6288.0‘, ‘苹果公司发布的新大屏手机。‘); -- ---------------------------- -- Table structure for tb_order -- ---------------------------- DROP TABLE IF EXISTS `tb_order`; CREATE TABLE `tb_order` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` bigint(20) NOT NULL, `order_number` varchar(20) NOT NULL COMMENT ‘订单号‘, PRIMARY KEY (`id`), KEY `FK_orders_1` (`user_id`), CONSTRAINT `FK_orders_1` FOREIGN KEY (`user_id`) REFERENCES `tb_user` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of tb_order -- ---------------------------- INSERT INTO `tb_order` VALUES (‘1‘, ‘1‘, ‘20140921001‘); INSERT INTO `tb_order` VALUES (‘2‘, ‘2‘, ‘20140921002‘); INSERT INTO `tb_order` VALUES (‘3‘, ‘1‘, ‘20140921003‘); -- ---------------------------- -- Table structure for tb_orderdetail -- ---------------------------- DROP TABLE IF EXISTS `tb_orderdetail`; CREATE TABLE `tb_orderdetail` ( `id` int(11) NOT NULL AUTO_INCREMENT, `order_id` int(32) DEFAULT NULL COMMENT ‘订单号‘, `item_id` int(32) DEFAULT NULL COMMENT ‘商品id‘, `total_price` double(20,0) DEFAULT NULL COMMENT ‘商品总价‘, `status` int(11) DEFAULT NULL COMMENT ‘状态‘, PRIMARY KEY (`id`), KEY `FK_orderdetail_1` (`order_id`), KEY `FK_orderdetail_2` (`item_id`), CONSTRAINT `FK_orderdetail_1` FOREIGN KEY (`order_id`) REFERENCES `tb_order` (`id`), CONSTRAINT `FK_orderdetail_2` FOREIGN KEY (`item_id`) REFERENCES `tb_item` (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of tb_orderdetail -- ---------------------------- INSERT INTO `tb_orderdetail` VALUES (‘1‘, ‘1‘, ‘1‘, ‘5288‘, ‘1‘); INSERT INTO `tb_orderdetail` VALUES (‘2‘, ‘1‘, ‘2‘, ‘6288‘, ‘1‘); INSERT INTO `tb_orderdetail` VALUES (‘3‘, ‘2‘, ‘2‘, ‘6288‘, ‘1‘); INSERT INTO `tb_orderdetail` VALUES (‘4‘, ‘3‘, ‘1‘, ‘5288‘, ‘1‘); -- ---------------------------- -- Table structure for tb_user -- ---------------------------- DROP TABLE IF EXISTS `tb_user`; CREATE TABLE `tb_user` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `user_name` varchar(100) DEFAULT NULL COMMENT ‘用户名‘, `password` varchar(100) DEFAULT NULL COMMENT ‘密码‘, `name` varchar(100) DEFAULT NULL COMMENT ‘姓名‘, `age` int(10) DEFAULT NULL COMMENT ‘年龄‘, `sex` tinyint(1) DEFAULT NULL COMMENT ‘性别,1男性,2女性‘, `birthday` date DEFAULT NULL COMMENT ‘出生日期‘, `created` datetime DEFAULT NULL COMMENT ‘创建时间‘, `updated` datetime DEFAULT NULL COMMENT ‘更新时间‘, PRIMARY KEY (`id`), UNIQUE KEY `username` (`user_name`) ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of tb_user -- ---------------------------- INSERT INTO `tb_user` VALUES (‘1‘, ‘zhangsan‘, ‘123456‘, ‘张三‘, ‘30‘, ‘1‘, ‘1984-08-08‘, ‘2014-09-19 16:56:04‘, ‘2014-09-21 11:24:59‘); INSERT INTO `tb_user` VALUES (‘2‘, ‘lisi‘, ‘123456‘, ‘李四‘, ‘21‘, ‘2‘, ‘1991-01-01‘, ‘2014-09-19 16:56:04‘, ‘2014-09-19 16:56:04‘); INSERT INTO `tb_user` VALUES (‘3‘, ‘wangwu‘, ‘123456‘, ‘王五‘, ‘22‘, ‘2‘, ‘1989-01-01‘, ‘2014-09-19 16:56:04‘, ‘2014-09-19 16:56:04‘); INSERT INTO `tb_user` VALUES (‘4‘, ‘zhangwei‘, ‘123456‘, ‘张伟‘, ‘20‘, ‘1‘, ‘1988-09-01‘, ‘2014-09-19 16:56:04‘, ‘2014-09-19 16:56:04‘); INSERT INTO `tb_user` VALUES (‘5‘, ‘lina‘, ‘123456‘, ‘李娜‘, ‘28‘, ‘1‘, ‘1985-01-01‘, ‘2014-09-19 16:56:04‘, ‘2014-09-19 16:56:04‘); INSERT INTO `tb_user` VALUES (‘6‘, ‘lilei‘, ‘123456‘, ‘李磊‘, ‘23‘, ‘1‘, ‘1988-08-08‘, ‘2014-09-20 11:41:15‘, ‘2014-09-20 11:41:15‘);
需求 根据订单编号查询订单信息和用户名,年龄,先分析这个需求,如图所示
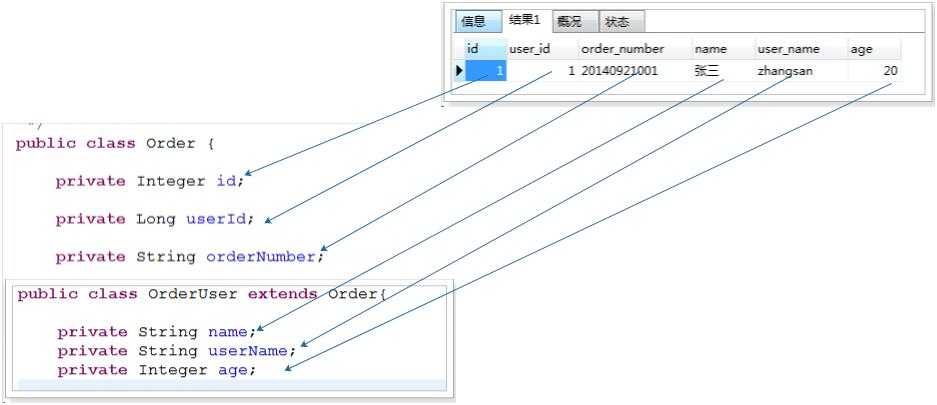
我们必须在去定义一个Model,去封装另外三个字段.(其实直接将多余的字段直接封装在Order中也是可以的)
package com.j1.mybatis.mapper; import com.j1.mybatis.pojo.OrderUser; public interface OrderMapper { /** * 根据订单编号查询订单信息和用户名,年龄 * @param orderNum * @return */ public OrderUser querOrderAndUserByOrderNum(String orderNum); }
package com.j1.mybatis.mapper; import static org.junit.Assert.*; import java.io.IOException; import java.io.InputStream; import org.apache.ibatis.io.Resources; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import org.junit.Before; import org.junit.Test; import com.j1.mybatis.pojo.OrderUser; public class OrderMapperTest { private OrderMapper orderMapper; @Before public void setUp() throws Exception { try { // 构造SqlSessionFactory // 定义配置文件路径 String resource = "mybatis-config.xml"; // 读取配置文件 InputStream inputStream = Resources.getResourceAsStream(resource); // 通过SqlSessionFactoryBuilder构建一个SqlSessionFactory SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); // this.userDAO = new UserDao(sqlSessionFactory); SqlSession sqlSession = sqlSessionFactory.openSession(true); this.orderMapper=sqlSession.getMapper(OrderMapper.class); } catch (IOException e) { e.printStackTrace(); } } @Test public void testQuerOrderAndUserByOrderNum() { OrderUser orderUser=orderMapper.querOrderAndUserByOrderNum("20140921002"); System.out.println(orderUser); } }
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.j1.mybatis.mapper.OrderMapper"> <select id="querOrderAndUserByOrderNum" resultType="OrderUser"> SELECT o.*, u.name, u.user_name, u.age FROM tb_order o LEFT JOIN tb_user u ON u.id = o.user_id WHERE o.order_number = #{orderNumber} </select> </mapper>
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <!-- 引入外部的配置文件 --> <properties resource="jdbc.properties"/> <settings> <!-- 开启驼峰自动映射 --> <setting name="mapUnderscoreToCamelCase" value="true"/> </settings> <typeAliases> <!-- 设置别名 --> <!-- <typeAlias type="com.j1.Model.User" alias="User"/> --> <package name="com.j1.mybatis.pojo"/> </typeAliases> <!-- 指定环境 --> <environments default="development"> <environment id="development"> <transactionManager type="JDBC" /> <dataSource type="POOLED"> <property name="driver" value="${jdbc.driver}" /> <property name="url" value="${jdbc.url}" /> <property name="username" value="${jdbc.username}" /> <property name="password" value="${jdbc.password}" /> </dataSource> </environment> <!-- <environment id="test"> <transactionManager type="JDBC" /> <dataSource type="POOLED"> <property name="driver" value="${jdbc.test.driver}" /> <property name="url" value="${jdbc.test.url}" /> <property name="username" value="${jdbc.test.username}" /> <property name="password" value="${jdbc.test.password}" /> </dataSource> </environment> --> </environments> <mappers> <!-- <mapper resource="UserMapper.xml" /> --> <!-- <mapper resource="UserMapper2.xml" /> --> <!-- <mapper class="com.j1.dao.IUser"/> --> <!-- 配置掃描包 --> <package name="com.j1.mybatis.mapper"/> </mappers> </configuration>
一对一的第二种查询:
@Test public void testQuerOrderAndUserByOrderNum2() { Order order=orderMapper.querOrderAndUserByOrderNum("20140921002"); System.out.println(order); }
<!-- 一对一的第二种查询方法,进行映射 <resultMap id="orderMap" type="User"> <result column="id" property="id" /> <result column="user_name" property="userName" /> <result column="name" property="name" /> <result column="age" property="age" /> <result column="sex" property="sex" /> <result column="password" property="password" /> </resultMap> --> <resultMap id="orderMap" type="Order" autoMapping="true">
<!--
property为Order的属性 user
javaType为属性的java类型User
-->
<association property="user" javaType="User"></association> </resultMap> <select id="querOrderAndUserByOrderNum2" resultMap="orderMap"> SELECT o.*, u.name, u.user_name, u.age FROM tb_order o LEFT JOIN tb_user u ON u.id = o.user_id WHERE o.order_number = #{orderNumber} </select>
一对多:
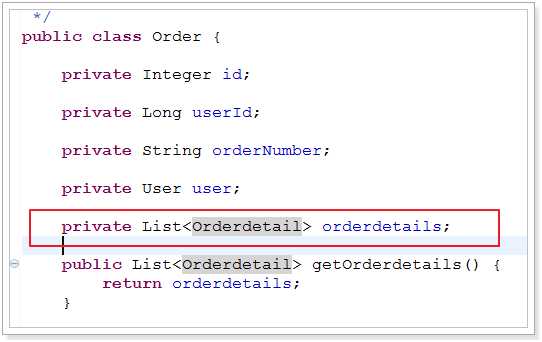
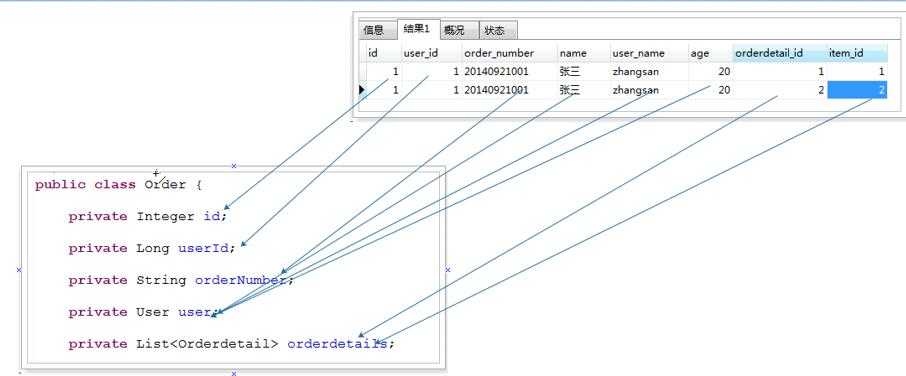
这里需要注意的是,不能像一对一那样扩充一个对象了,因为在查询的结果来看,其实还是一个订单数据,只是,一个订单里面有两个订单详情书局而已,所以只能扩充一个List
@Test public void queryOrderAndUserAndOrderDetailByOrderNumber() { Order order=orderMapper.queryOrderAndUserAndOrderDetailByOrderNumber("20140921002"); System.out.println(order); }
package com.j1.mybatis.mapper; import com.j1.mybatis.pojo.Order; import com.j1.mybatis.pojo.OrderUser; public interface OrderMapper { /** * 根据订单编号查询订单信息和用户名,年龄 * @param orderNum * @return */ public OrderUser querOrderAndUserByOrderNum(String orderNum); public Order querOrderAndUserByOrderNum2(String orderNum); public Order queryOrderAndUserAndOrderDetailByOrderNumber(String orderNum); }
<!-- 一对多 --> <resultMap type="Order" id="orderAndUserAndOrderDetailResultMap" autoMapping="true" extends="orderAndUserResultMap"> <!-- <id property="id" column="id"/> <association property="user" javaType="User" autoMapping="true"/> --> <!-- property: java对象中的属性名称 javaType: 集合类型 ofType: 集合中的元素的数据类型 --> <collection property="orderdetails" javaType="List" ofType="Orderdetail" autoMapping="true"> <id property="id" column="orderdetail_id"/> <!-- <result property="itemId" column="item_id"/> --> </collection> </resultMap> <select id="queryOrderAndUserAndOrderDetailByOrderNumber" resultMap="orderAndUserAndOrderDetailResultMap"> SELECT o.*, u.name, u.user_name, u.age, od.id orderdetail_id, od.item_id FROM tb_order o LEFT JOIN tb_user u ON u.id = o.user_id LEFT JOIN tb_orderdetail od ON od.order_id = o.id WHERE o.order_number = #{orderNumber} </select>
<resultMap type="Order" id="orderAndUserResultMap" autoMapping="true"> <id property="id" column="id"/> <!-- 映射对象 property : Order对象中的user属性名 javaType :属性的java类型 --> <association property="user" javaType="User" autoMapping="true"> <!-- <result property="name" column="name"/> <result property="userName" column="user_name"/> <result property="age" column="age"/> --> </association> </resultMap>
多对多:

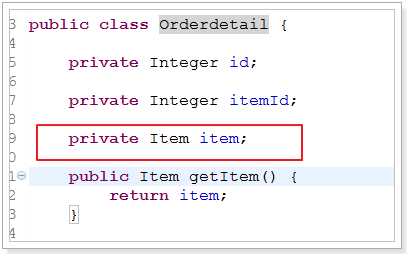
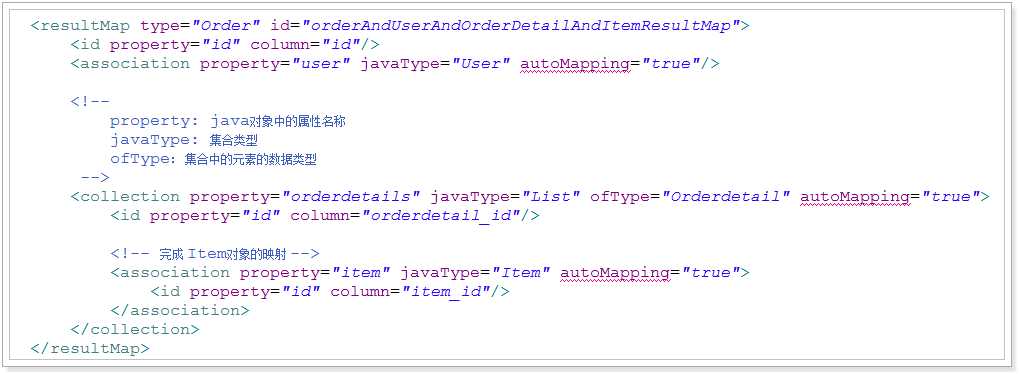
<!-- 多对多 --> <resultMap type="Order" id="orderAndUserAndOrderDetailAndItemResultMap"> <id property="id" column="id"/> <association property="user" javaType="User" autoMapping="true"/> <!-- property: java对象中的属性名称 javaType: 集合类型 ofType: 集合中的元素的数据类型 --> <collection property="orderdetails" javaType="List" ofType="Orderdetail" autoMapping="true"> <id property="id" column="orderdetail_id"/> <!-- 完成 Item对象的映射 --> <association property="item" javaType="Item" autoMapping="true"> <id property="id" column="item_id"/> </association> </collection> </resultMap> <select id="queryOrderAndUserAndOrderDetailAndItemByOrderNumber" resultMap="orderAndUserAndOrderDetailAndItemResultMap"> SELECT o.*, u.name, u.user_name, u.age, od.id orderdetail_id, od.item_id, i.item_detail, i.item_name, i.item_price FROM tb_order o LEFT JOIN tb_user u ON u.id = o.user_id LEFT JOIN tb_orderdetail od ON od.order_id = o.id LEFT JOIN tb_item i ON i.id = od.item_id WHERE o.order_number = #{orderNumber} </select>
/** * 多对多 * 查询订单,查询出下单人信息并且查询出订单详情中的商品数据。 * * @param orderNumber * @return */ public Order queryOrderAndUserAndOrderDetailAndItemByOrderNumber(String orderNum);
/** * 多对多 */ @Test public void testQueryOrderAndUserAndOrderDetailAndItemByOrderNumber() { Order order = this.orderMapper.queryOrderAndUserAndOrderDetailAndItemByOrderNumber("20140921001"); System.out.println(order); }
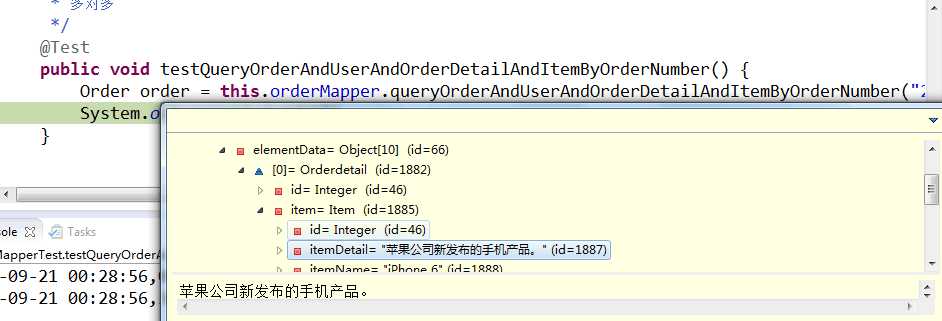
至此,mybatis的高级查询以及缓存机制就讲完了.代码亲测可行
以上是关于mybatis知识总结的主要内容,如果未能解决你的问题,请参考以下文章