ES实战ES集群节点迁移与缩容
Posted 顧棟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ES实战ES集群节点迁移与缩容相关的知识,希望对你有一定的参考价值。
ES集群节点迁移与缩容
文章目录
master节点迁移
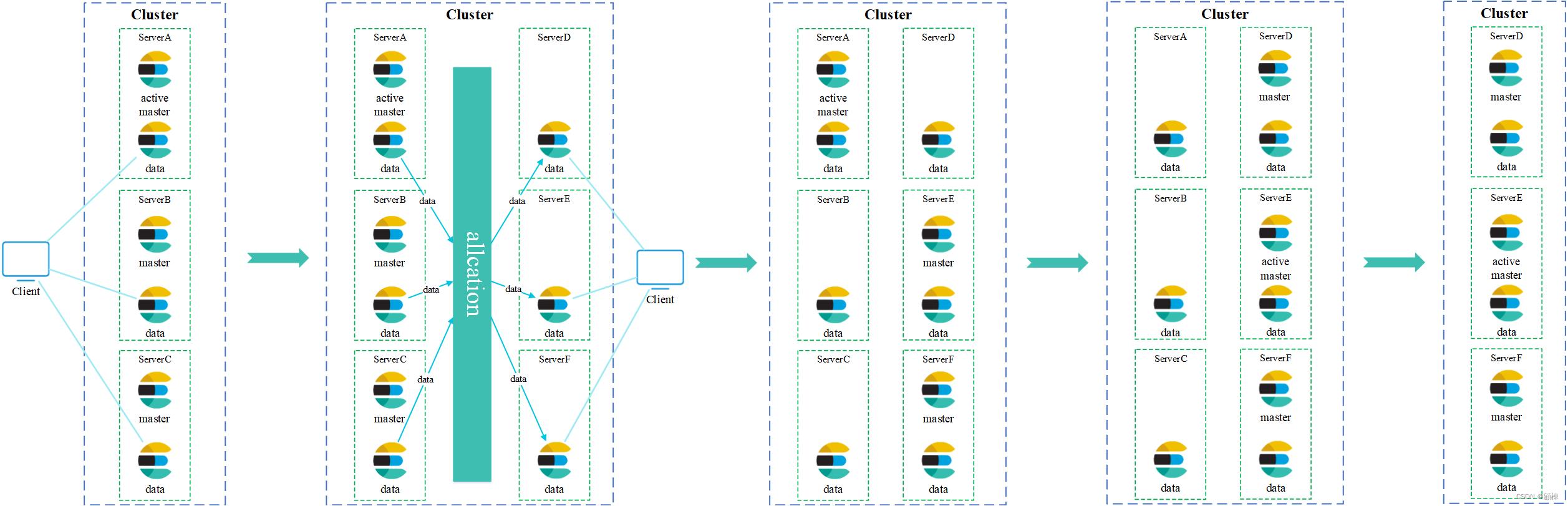
场景一
集群上的master部署情况,一台机器上同时部署了纯master角色和纯data角色的两个ES节点
- 申请新机器DEF,为新机器申请域名。
- 在新机器DEF上各自部署纯data角色的ES节点,将所有节点的配置文件
elasticsearch.yml中的配置项discovery.zen.ping.unicast.hosts修改为ABCDEF。 - 将数据迁移到DEF中的数据ES节点中。同时客户端修改链接地址为DEF。
- 数据迁移完毕后,关闭一个非active master的ES节点,在DEF中选择一个启动纯master角色的ES节点。
- 重复步骤4,直到只剩下非active master的ES节点未调整。
- 关闭active master的ES节点,启动新机器中的纯master角色的ES节点,新的active master会在DEF中选举产生。
- 确认用户客户端链接地址修改完毕后,下线ABC机器。将DEF中ES全部节点的配置文件
elasticsearch.yml中的配置项discovery.zen.ping.unicast.hosts修改为DEF。
场景二
集群上的master部署情况,机器上的master角色是与data角色混在一个ES节点中
- 申请新机器DEF,为新机器申请域名。
- 在新机器DEF上各自部署纯data角色的ES节点,将所有节点的配置文件
elasticsearch.yml中的配置项discovery.zen.ping.unicast.hosts修改为ABCDEF。 - 将数据迁移到DEF中的数据ES节点中。同时客户端修改链接地址为DEF。
- 数据迁移完毕后,关闭一个非active master的ES节点,在DEF中选择一个启动纯master角色的ES节点。
- 重复步骤4,直到只剩下非active master的ES节点未调整。
- 关闭active master的ES节点,启动新机器中的纯master角色的ES节点,新的active master会在DEF中选举产生。
- 确认用户客户端链接地址修改完毕后,下线ABC机器。将DEF中ES全部节点的配置文件
elasticsearch.yml中的配置项discovery.zen.ping.unicast.hosts修改为DEF。

场景三
集群上的master部署情况,纯master角色ES节点和纯Data角色ES节点部署在不同的服务器上
- 申请新机器GHIJ,为新机器申请域名。
- 在新机器GHIJ上各自部署纯data角色的ES节点,将所有节点的配置文件
elasticsearch.yml中的配置项discovery.zen.ping.unicast.hosts修改为DEFGHI。 - 将数据迁移到GHIJ中的dataES节点中。同时客户端修改链接地址为GHIJ。
- 数据迁移完毕后,关闭一个非active master的ES节点,在GHI中选择一个启动纯master角色的ES节点。
- 重复步骤4,直到只剩下非active master的ES节点未调整。
- 关闭active master的ES节点,启动新机器中的纯master角色的ES节点,新的active master会在GHI中选举产生。
- 确认用户客户端链接地址修改完毕后,下线ABCM机器。将GHIJ中ES全部节点的配置文件
elasticsearch.yml中的配置项discovery.zen.ping.unicast.hosts修改为GHI。

data节点迁移
- 申请新机器,为新机器申请域名。
- 在新机器各自部署纯data角色的ES节点。
- 检查是否需要更改ES客户端的链接地址。
- 将需要迁移data节点的所有索引数据迁移到新机器。
- 下线需要迁移的机器。
数据迁移操作
主要使用配置项cluster.routing.allocation.exclude._ip来实现数据迁移。
1、查询集群原来的配置
检查cluster.routing.allocation.exclude._ip配置项的值,如果没有,说明原来没有排除节点。
curl -X GET "http://ip:port/_cluster/settings?pretty"
2、清空节点数据
清空数据节点的数据,ip:集群任意节点IP,port:http服务端口号,ip1,ip2:需要排除数据的IP,将原来配置需要排除数据的节点IP加上本次排除数据的节点IP,以逗号分隔。
curl -X PUT "http://ip:port/_cluster/settings?pretty" -H 'Content-Type: application/json' -d'
"persistent" :
"cluster.routing.allocation.exclude._ip" : "ip1,ip2"
'
3、检查是否排空数据
检查数据节点上是否存在数据,结果中的IP列没有需要下线的IP,说明数据已经排尽,满足机器下线条件了。有的集群分片可能很多,可以将结果输出到文件查询。
curl -X GET "http://ip:port/_cat/shards?v&pretty&s=ip:desc"
index shard prirep state docs store ip node
config_s-20211108 1 r STARTED 0 130b 192.168.1.1 es03-prd
config_s-20211108 2 r STARTED 0 130b 192.168.1.1 es03-prd
config_s-20211108 0 p STARTED 0 130b 192.168.1.1 es03-prd
.monitoring-data-2 0 r STARTED 5 15.7kb 192.168.1.1 es03-prd
config_s-20211107 1 r STARTED 0 130b 192.168.1.1 es03-prd
config_s-20211107 2 r STARTED 0 130b 192.168.1.1 es03-prd
config_s-20211107 0 p STARTED 0 130b 192.168.1.1 es03-prd
迁移原则
- 清理集群中的过期索引与过期数据
- 优先扩容data角色的节点,迁移集群中的数据
- 确认客户端的链接地址不是要下线的机器
- 迁移非active的master角色的节点
- 切主,将active的master节点进行关闭,在新master角色的节点中完成新的active master选主。
- 刷新集群上的相关配置
- 在确认所有事项之后,才能下线旧机器
缩容前置检查项
-
index的副本分片数量的合理性
副本数 + 1 ≤ +1\\leq +1≤data角色的节点数
-
单个ES数据节点的分片数量的合理性
官方的默认值是每个数据节点的分片数 ≤ \\leq ≤ 1000,
https://www.elastic.co/guide/en/elasticsearch/reference/6.7/misc-cluster.html#cluster-shard-limit
-
大分片的数量
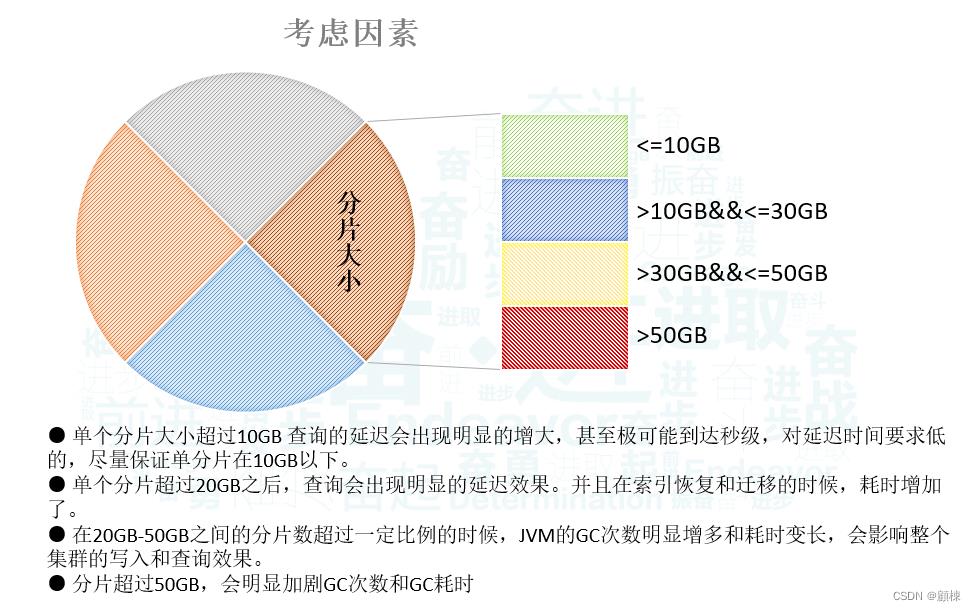
-
数据生命周期的调整
-
单机器多数据节点的
cluster.routing.allocation.same_shard.host配置的调整,最佳为true。允许执行检查,以防止基于主机名和主机地址在单个主机上分配同一分片的多个实例。 默认为false,表示默认情况下不执行任何检查。 仅当在同一台计算机上启动多个节点时,此设置才适用。
以上是关于ES实战ES集群节点迁移与缩容的主要内容,如果未能解决你的问题,请参考以下文章