java-es理论
Posted bug修复中
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java-es理论相关的知识,希望对你有一定的参考价值。
导读:
第一节:原理与过程
1:底层
2:过程
第二节:集群策略与搭建
1:分发策略
2:搭建
第三节:对比
1:对比solr
2:对比数据库
第四节:操作
1:rest,curl
2:java操作
第一节:原理与过程
1、底层(基于luceue框架)
Luceue:
倒排索引
对数据进行分词处理,信息存储(位置,数量,偏移量)
例子:
我是中国人。
中国是全球人口最多的国家,中国人也最多(2)
1:我 (1:1){0}(第一行,有一个,索引0)
2:中国 (1:1) {2},(2:2){0,15} (第一行,有一个,索引2)(第二行,有两个,索引0和15位置)
正排索引:
对数据进行分词处理,生成索引。
缺点:数量太大
Document:存储的基本单位,类似java类,以json格式存数据
包含:
context:内容
Size:大小
Path:数据来源
2、过程
数据
--->document的形式
---->对document中的context进行分词处理(ik分词器)
---->对分词进行倒排索引
---->是否保存之前的document
---->强制生成新的ducument(索引的)
新的document可选择的保存需要的:
唯一ID:倒排索引之后的ID
Path:(必选)
Size::(选存)
Context:(选存,列表中的简要提示用)
3、单机所能承载的数据峰值,速度,依据企业的业务量
第二节:集群策略与搭建
1、分发策略
Master 是去中心化的,很淡化了。
在一个服务器上启动一个执行代理,即master,进行数据的请求及数据统一回收等
分发策略(hashcode%lucenu主片个数)hashcode是document的ID的hash
一个节点放多个lucene主片,所以可以采用多个lucene主片分发到各个节点。这样如果需要扩充,只需要给片迁移就可以了。
2、搭建:
2.1 不能用root用户:es有远程执行脚本的功能,容易中木马。
创建普通用户
Useradd 名字
Passwd 名字
切换用户
Su 名字 switch user
修改权限
Chown 用户:用户 -R 文件夹 change own
2.2 下载安装目录包:
Yum install unzip
unzip elasticsearch-6.4.1.zip -d /opt/sxt/es
2.3 修改配置文件:
Cluster.name //集群名称
Node.name 别名
Network.host //服务器IP
http.host 9200 //与网页的通讯端口
防脑裂
discovery.zen.ping.multicast.enabled: false //多重广播,来一台自动加进一台到集群,这里手动,否则容易脑裂
discovery.zen.ping.unicast.hosts: ["192.168.133.6","192.168.133.7", "192.168.133.8"]
discovery.zen.ping_timeout: 120s
client.transport.ping_timeout: 60s
2.4 可视化插件:
原因:本身是json格式的显示,用这个插件让es的运行状况可视化
操作:资料/附件 中的plugins 导入到es路径下,修改权限,也可以不修改
2.5 启动:要每一台都启动
./elasticsearch
2.6 测试插件效果:plugin插件
http://ip:9200/_plugin/head 即:http://192.168.133.6:9200/_plugin/head?pretty
第三节:对比
1、与solr的对比:
Solr是静态数据,即先将数据存进来
Es是动态数据,不断有新数据进来
Es速度比solr也快
2、对比:

第四节:操作
1、Rest:操作es数据库的架构风格,类似于接口,给用户来进行增删改查操作
Get 获取
Put 修改(ID存在的是修改,不存在的是新建)
Post 新建
Delete 删除
Head 头信息
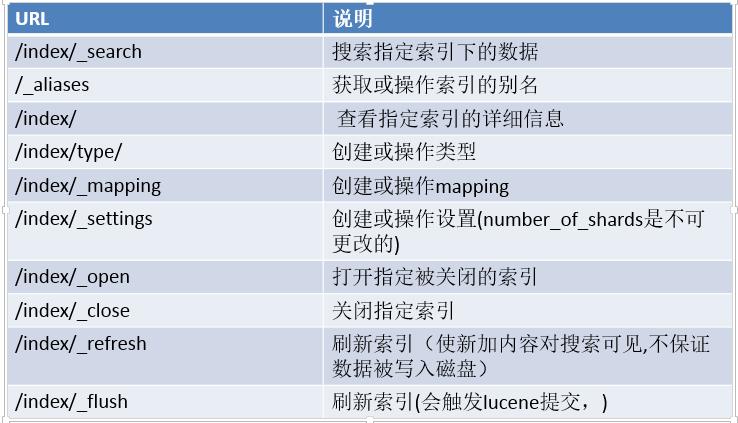
实际操作:
Curl操作:
curl -XPUT http://192.168.133.6:9200/test/ //创建库
Curl -XDELETE ... //删除库
//在test(index)下的employee(type)中建立一个doc {...doc内容}
//也可以像PUT一样指定id,与put中相同,所以POST更加灵活,不需要用put,post就都可以搞定了
curl -XPOST http://192.168.133.6:9200/test/employee -d \' //test相当于库。employee相当于表。
{ //相当于一行数据
"first_name" : "bin", //字段
"age" : 33,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}\'
//put形式:需要定义id,例子中的111(如果是id已经存在的会更新数据,非创建)
curl -XPUT http://192.168.133.6:9200/test/employee/111 -d \'
{
"first_name" : "god bin",
"last_name" : "pang",
"age" : 42,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}\'
//查询,pretty是显示格式化
curl -XGET http://192.168.133.6:9200/test/employee/1?pretty
//查找first_name字段下所有含有’bin’的
curl -XGET http://192.168.133.6:9200/test/employee/_search?q=first_name="bin"
//规范的查询,同上的查询
curl -XGET http://192.168.133.6:9200/test/employee/_search?pretty -d \'
{
"query":
{"match":
{"first_name":"bin"}
}
}\'
//多个field查询,last_name 和first_name中都含有’bin’的
curl -XGET http://192.168.133.6:9200/test/employee/_search?pretty -d \'
{
"query":
{"multi_match":
{
"query":"bin",
"fields":["last_name","first_name"],
"operator":"and"
}
}
}\'
//多个term对多个field发起查询:bool(boolean)
//组合查询,must,must_not,should
//must : 必须满足
//must_not :必须不能满足
//should+should : 并集
curl -XGET http://192.168.133.6:9200/test/employee/_search?pretty -d \'
{
"query":
{"bool" :
{
"must" :
{"match":
{"first_name":"bin"}
},
"must" :
{"match":
{"age":33}
}
}
}
}\'
//修改配置
//创建test2库,这个库里有2个从
curl -XPUT \'http://192.168.133.6:9200/test2/\' -d\'{"settings":{"number_of_replicas":2}}\'
//创建test3库,这个库有3个主,3个从(主是分布在各个节点,从放在非主的其它节点,所以从的个数要小于集群节点个数)
curl -XPUT \'http://192.168.133.6:9200/test3/\' -d\'{"settings":{"number_of_shards":3,"number_of_replicas":3}}\'
2、java操作(在java-es的其他随笔中有详细写出)
3、分词器(ik) 及配置文件修改、分发(es与ik之间有相互的对应版本)
版本 文件 安装
在es的plugins下创建目录,解压ik在这个下面。
修改配置:
elasticsearch.version //版本对应上
以上是关于java-es理论的主要内容,如果未能解决你的问题,请参考以下文章